FCOS网络解析
Posted 太阳花的小绿豆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FCOS网络解析相关的知识,希望对你有一定的参考价值。
论文名称:FCOS: Fully Convolutional One-Stage Object Detection
论文下载地址:
- https://arxiv.org/abs/1904.01355
- https://arxiv.org/abs/2006.09214 (注:2020年更新后的版本,比如center-ness分支有些小改动)
文章目录
0 前言
在之前讲的一些目标检测网络中,比如Faster RCNN系列、SSD、YOLOv2~v5(注意YOLOv1不包括在内)都是基于Anchor进行预测的。即先在原图上生成一堆密密麻麻的Anchor Boxes,然后网络基于这些Anchor去预测它们的类别、中心点偏移量以及宽高缩放因子得到网络预测输出的目标,最后通过NMS即可得到最终预测目标。那基于Anchor的网络存在哪些问题呢,在FCOS论文的Introduction中,作者总结了四点:
- 检测器的性能和Anchor的size以及aspect ratio相关,比如在RetinaNet中改变Anchor(论文中说这是个超参数
hyper-parameters)能够产生约4%的AP变化。换句话说,Anchor要设置的合适才行。 - 一般Anchor的size和aspect ratio都是固定的,所以很难处理那些形状变化很大的目标(比如一本书横着放w远大于h,竖着放h远大于w,斜着放w可能等于h,很难设计出合适的Anchor)。而且迁移到其他任务中时,如果新的数据集目标和预训练数据集中的目标形状差异很大,一般需要重新设计Anchor。
- 为了达到更高的召回率(查全率),一般需要在图片中生成非常密集的Anchor Boxes尽可能保证每个目标都会有Anchor Boxes和它相交。比如说在FPN(Feature Pyramid Network)中会生成超过18万个Anchor Boxes(以输入图片最小边长800为例),那么在训练时绝大部分的Anchor Boxes都会被分为负样本,这样会导致正负样本极度不均。下图是我随手画的样例,红色的矩形框都是负样本,黄色的矩形框是正样本。
- Anchor的引入使得网络在训练过程中更加的繁琐,因为匹配正负样本时需要计算每个Anchor Boxes和每个GT BBoxes之间的IoU。

虽然基于Anchor的目标检测网络存在如上所述问题,但并不能否认它的有效性,比如现在非常常用的YOLO v3~v5,它们都是基于Anchor的网络。当然,今天的主角是Anchor-Free,现今有关Anchor-Free的网络也很多,比如DenseBox、YOLO v1、CornerNet、FCOS以及CenterNet等等,而我们今天要聊的网络是FCOS(它不仅是Anchor-Free还是One-Stage,FCN-base detector)。这是一篇发表在2019年CVPR上的文章,这篇文章的想法不仅简单而且很有效,它的思想是跳出Anchor的限制,在预测特征图的每个位置上直接去预测该点分别距离目标左侧(l: left),上侧(t:top),右侧(r: right)以及下侧(b:bottom)的距离,如下图所示。

1 FCOS网络结构
下面这幅图是原论文中给的FCOS网络结构,还是非常清晰的。注意:这张图是2020年发表的版本,和2019年发表的版本有些不同。区别在于Center-ness分支的位置,在2019年论文的图中是将Center-ness分支和Classification分支放在一起的,但在2020年论文的图中是将Center-ness分支和Regression分支放在一起。论文中也有解释,将Center-ness分支和Regression分支放在一起能够得到更好的结果:
it has been shown that positioning it on the regression branch can obtain better performance.
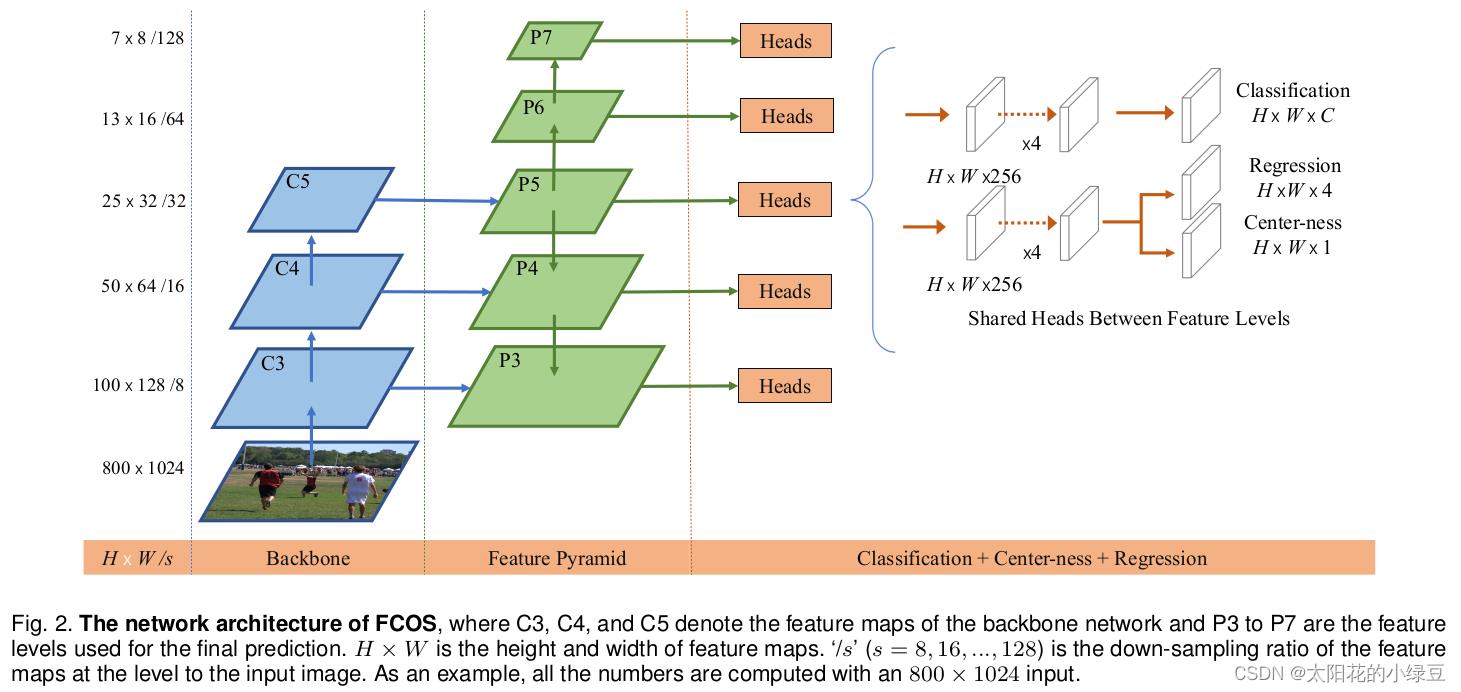
下面这张图是我结合Pytorch官方实现FCOS的源码绘制的更加详细的网络结构:

首先看上图左边的部分,Backbone是以ResNet50为例的,FPN是在Backbone输出的C3、C4和C5上先生成P3、P4和P5,接着在P5的基础上通过一个卷积核大小为3x3步距为2的卷积层得到P6,最后在P6的基础上再通过一个卷积核大小为3x3步距为2的卷积层得到P7。接着看右边的Head(注意这里的Head是共享的,即P3~P7都是共用一个Head),细分共有三个分支:Classification、Regression和Center-ness。其中Regression和Center-ness是同一个分支上的两个不同小分支。可以看到每个分支都会先通过4个Conv2d+GN+ReLU的组合模块,然后再通过一个卷积核大小为3x3步距为1的卷积层得到最终的预测结果。
对于Classification分支,在预测特征图的每个位置上都会预测80个score参数(MS COCO数据集目标检测任务的类别数为80)。
对于Regression分支,在预测特征图的每个位置上都会预测4个距离参数(距离目标左侧距离l,上侧距离t,右侧距离r以及下侧距离b,注意,这里预测的数值是相对特征图尺度上的)。假设对于预测特征图上某个点映射回原图的坐标是
(
c
x
,
c
y
)
(c_x, c_y)
(cx,cy),特征图相对原图的步距是s,那么网络预测该点对应的目标边界框坐标为:
x
m
i
n
=
c
x
−
l
⋅
s
,
y
m
i
n
=
c
y
−
t
⋅
s
x
m
a
x
=
c
x
+
r
⋅
s
,
y
m
a
x
=
c
y
+
b
⋅
s
x_min=c_x - l \\cdot s \\ , \\ \\ y_min=c_y - t \\cdot s \\\\ x_max=c_x + r \\cdot s \\ , \\ \\ y_max=c_y + b \\cdot s
xmin=cx−l⋅s , ymin=cy−t⋅sxmax=cx+r⋅s , ymax=cy+b⋅s
对于Center-ness分支,在预测特征图的每个位置上都会预测1个参数,center-ness反映的是该点(特征图上的某一点)距离目标中心的远近程度,它的值域在0~1之间,距离目标中心越近center-ness越接近于1,下面是center-ness真实标签的计算公式(计算损失时只考虑正样本,即预测点在目标内的情况,后续会详细讲解)。
c
e
n
t
e
r
n
e
s
s
∗
=
m
i
n
(
l
∗
,
r
∗
)
m
a
x
(
l
∗
,
r
∗
)
×
m
i
n
(
t
∗
,
b
∗
)
m
a
x
(
t
∗
,
b
∗
)
centerness^*=\\sqrt\\fracmin(l^*,r^*)max(l^*,r^*) \\times \\fracmin(t^*,b^*)max(t^*,b^*)
centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)
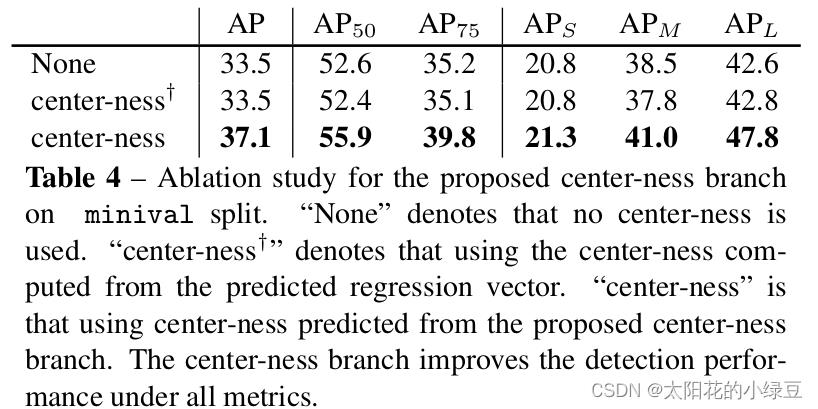
在网络后处理部分筛选高质量bbox时,会将预测的目标class score与center-ness相乘再开根,然后根据得到的结果对bbox进行排序,只保留分数较高的bbox,这样做的目的是筛掉那些目标class score低且预测点距离目标中心较远的bbox,最终保留下来的就是高质量的bbox。下表展示了使用和不使用center-ness对AP的影响,我们只看第一行和第三行,不使用center-ness时AP为33.5,使用center-ness后AP提升到37.1,说明center-ness对FCOS网络还是很有用的。
2 正负样本的匹配
在计算损失之前,我们需要进行正负样本的匹配。在基于Anchor的目标检测网络中,一般会通过计算每个Anchor Box与每个GT的IoU配合事先设定的IoU阈值去匹配。比如某个Anchor Box与某个GT的IoU大于0.7,那么我们就将该Anchor Box设置为正样本。但对于Anchor-Free的网络根本没有Anchor,那该如何匹配正负样本呢。在2020年版本的论文2.1章节中有这样一段话:
Specifically, location (x, y) is considered as a positive sample if it falls into the center area of any ground-truth box, by following [42]. The center area of a box centered at (cx , cy ) is defined as the sub-box (cx − rs, cy − rs, cx + rs, cy + rs) , where s is the total stride until the current feature maps and r is a hyper-parameter being 1.5 on COCO. The sub-box is clipped so that it is not beyond the original box. Note that this is different from our original conference version, where we consider the locations positive as long as they are in a ground-truth box.
最开始的一句话是说,对于特征图上的某一点
(
x
,
y
)
(x,y)
(x,y),只要它落入GT box中心区域,那么它就被视为正样本(其实在2019年的文章中,最开始说的是只要落入GT内就算正样本)。对应的参考文献[42]就是2019年发表的FCOS版本。但在2020年发表的FCOS版本中,新加了一条规则,在满足以上条件外,还需要满足点
(
x
,
y
)
(x,y)
(x,y)在
(
c
x
−
r
s
,
c
y
−
r
s
,
c
x
+
r
s
,
c
y
+
r
s
)
(c_x - rs, c_y - rs, c_x + rs, c_y + rs)
(cx−rs,cy−rs,cx+rs,cy+rs)这个sub-box范围内,其中
(
c
x
,
c
y
)
(c_x, c_y)
(cx,cy)是GT的中心点,s是特征图相对原图的步距,r是一个超参数控制距离GT中心的远近,在COCO数据集中r设置为1.5,关于r的消融实验可以看2020版论文的表6。换句话说点
(
x
,
y
)
(x,y)
(x,y)不仅要在GT的范围内,还要离GT的中心点
(
c
x
,
c
y
)
(c_x, c_y)
(cx,cy)足够近才能被视为正样本。
为了方便大家理解我画了下面这幅图,假设上面两个feature map对应的是同一个特征图,将特征图上的每个点映射回原图就是下面图片中黑色的圆点。根据2019年发表论文的匹配准则,只要落入GT box就算正样本,所以左侧的feature map中打勾的位置都被视为正样本。根据2020年的版本,不仅要落入GT Box还要在
(
c
x
−
r
s
,
c
y
−
r
s
,
c
x
+
r
s
,
c
y
+
r
s
)
(c_x - rs, c_y - rs, c_x + rs, c_y + rs)
(cx−rs,cy−rs,cx+rs,cy+rs)这个sub-box范围内,所以右侧的feature map中打勾的位置都被视为正样本。

这里肯定有人会问,如果feature map上的某个点同时落入两个GT Box内(即两个GT Box相交区域),那该点到底分配给哪个GT Box,这就是论文中提到的Ambiguity问题。如下图所示,橙色圆圈对应的点同时落入人和球拍两个GT Box中,此时默认将该点分配给面积Area最小的GT Box,即图中的球拍。其实引入FPN后能够减少这种情况,后面4.1章节会讲。

3 损失计算
在前面讲FCOS网络结构中有提到,Head总共有三个输出分支: 以上是关于FCOS网络解析的主要内容,如果未能解决你的问题,请参考以下文章Classification、Regression和Center-ness。故损失由分类损失
L
c
l
s
L_cls
Lcls、定位损失
L
r
e
g
L_reg
Lreg以及center-ness损失
L
c
t
r
n
e
s
s
L_ctrness
Lctrness三部分共同组成:
L
(
p
x
,
y
,
t
x
,
y
,
s
x
,
y
)
=
1
N
p
o
s
∑
x
,
y
L
c
l
s
(
p
x
,
y
,
c
x
,
y
∗
)
+
1
N
p
o
s
∑
x
,
y
1
c
x
,
y
∗
>
0
L
r
e
g
(
t
x
,
y
,
t
x
,
y
∗
)
+
1
N
p
o
s
∑
x
,
y
1
c
x
,
y
∗
>
0
L
c
t
r
n
e
s
s
(
s
x
,
y
,
s
x
,
y
∗
)
\\beginaligned L(\\p_x,y\\,\\t_x,y\\, \\s_x,y\\) & = \\frac1N_pos\\sum_x,yL_cls(p_x,y,c^*_x,y) \\\\ & + \\frac1N_pos\\sum_x,y 1_\\c^*_x,y>0\\L_reg(t_x,y,t^*_x,y) \\\\ & + \\frac1N_pos\\sum_x,y 1_\\c^*_x,y>0\\L_ctrness(s_x,y, s^*_x,y) \\endaligned