客快物流大数据项目(六十八):工作流调度
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了客快物流大数据项目(六十八):工作流调度相关的知识,希望对你有一定的参考价值。

文章目录
工作流调度
一、工作流产生背景
工作流(Workflow),指“业务过程的部分或整体在计算机应用环境下的自动化”。是对工作流程及其各操作步骤之间业务规则的抽象、概括描述。工作流解决的主要问题是:为了实现某个业务目标,利用计算机软件在多个参与者之间按某种预定规则自动传递文档、信息或者任务。
一个完整的数据分析系统通常都是由多个前后依赖的模块组合构成的:数据采集、数据预处理、数据分析、数据展示等。各个模块单元之间存在时间先后依赖关系,且存在着周期性重复。
为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。

二、工作流调度实现方式
1、简单的任务调度
crontab
使用linux的crontab来定义调度,但是缺点比较明显,无法设置依赖复杂任务调度。且需要编写相关shell脚本。
2、复杂的任务调度
当下企业两种选择,
- 自主开发工作流调度系统
- 使用开源调度系统,比如azkaban、Apache Oozie、Cascading、Hamake等。
知名度比较高的是Apache Oozie,但是其配置工作流的过程是编写大量的XML配置,而且代码复杂度比较高,不易于二次开发。
三、工作流调度工具之间对比
下面的表格对四种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考。
| 特性 | Hamake | Oozie | Azkaban | Cascading |
| 工作流描述语言 | XML | XML (xPDL based) | text file with key/value pairs | Java API |
| 依赖机制 | data-driven | explicit | explicit | explicit |
| 是否要web容器 | No | Yes | Yes | No |
| 进度跟踪 | console/log messages | web page | web page | Java API |
| Hadoop job调度支持 | no | yes | yes | yes |
| 运行模式 | command line utility | daemon | daemon | API |
| Pig支持 | yes | yes | yes | yes |
| 事件通知 | no | no | no | yes |
| 需要安装 | no | yes | yes | no |
| 支持的hadoop版本 | 0.18+ | 0.20+ | currently unknown | 0.18+ |
| 重试支持 | no | workflownode evel | yes | yes |
| 运行任意命令 | yes | yes | yes | yes |
| Amazon EMR支持 | yes | no | currently unknown | yes |
四、调度器
1、Azkaban介绍
Azkaban是由linkedin(领英)公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。
Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
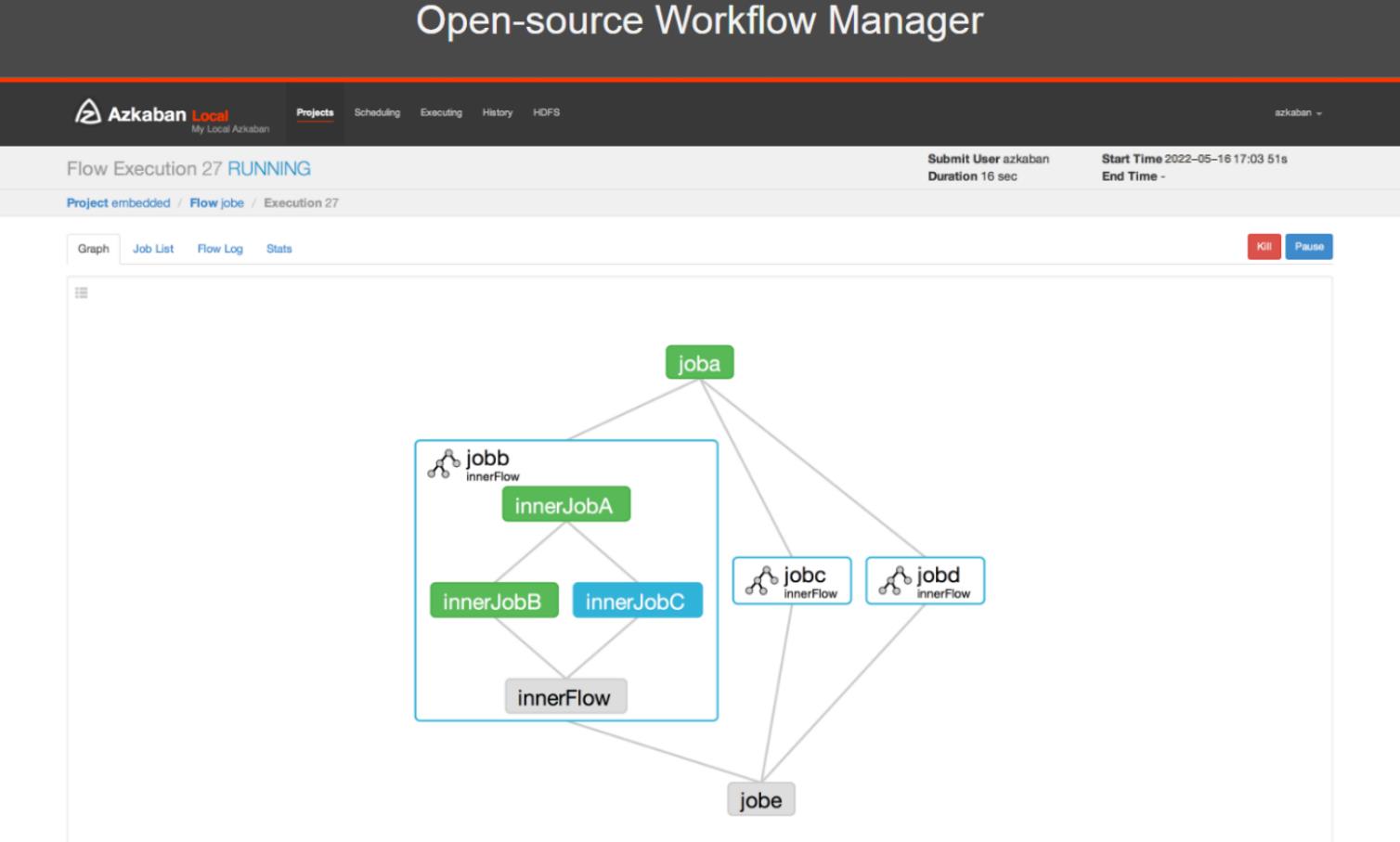
Azkaban功能特点:
- 提供功能清晰,简单易用的Web UI界面
- 提供job配置文件快速建立任务和任务之间的依赖关系
- 提供模块化和可插拔的插件机制,原生支持command、Java、Hive、Pig、Hadoop
- 基于Java开发,代码结构清晰,易于二次开发
2、Azkaban原理架构
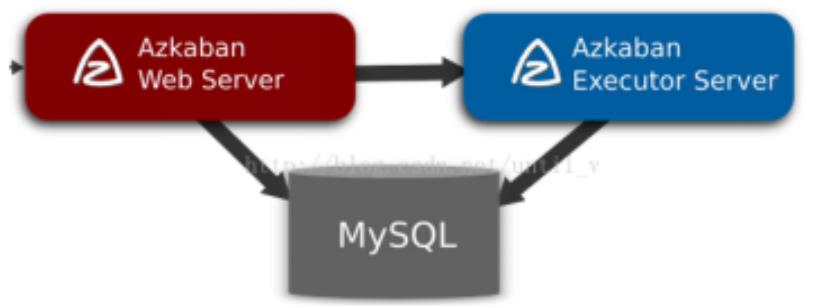
- mysql服务器: 存储元数据,如项目名称、项目描述、项目权限、任务状态、SLA规则等
- AzkabanWebServer:对外提供web服务,使用户可以通过web页面管理。职责包括项目管理、权限授权、任务调度、监控executor。
- AzkabanExecutorServer:负责具体的工作流的提交、执行。
3、Azkaban三种部署模式
3.1、solo server mode
该模式中webServer和executorServer运行在同一个进程中,进程名是AzkabanSingleServer。使用自带的H2数据库。这种模式包含Azkaban的所有特性,但一般用来学习和测试。
3.2、two-server mode
该模式使用MySQL数据库, Web Server和Executor Server运行在不同的进程中。
3.3、multiple-executor mode
该模式使用MySQL数据库, Web Server和Executor Server运行在不同的机器中。且有多个Executor Server。该模式适用于大规模应用。
五、Azkaban初体验
1、启动zakaban
- 进入azkaban安装目录:cd /export/services/azkaban
- 启动脚本:./bin/start-solo.sh
2、登录web页面
访问Web Server=>http://node2:8081/ 默认用户名密码azkaban
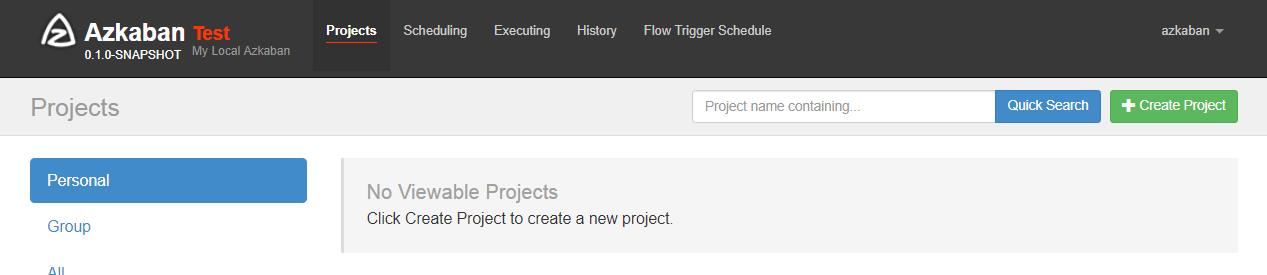
3、初体验测试
http://node2:8081/index登录=>Create Project=>Upload zip包 =>execute flow执行一步步操作即可。
创建两个文件one.job two.job,内容如下,打包成zip包。
cat one.job
type=command
command=echo "this is job one"
cat two.job
type=command
dependencies=one
command=echo "this is job two"
创建工程:
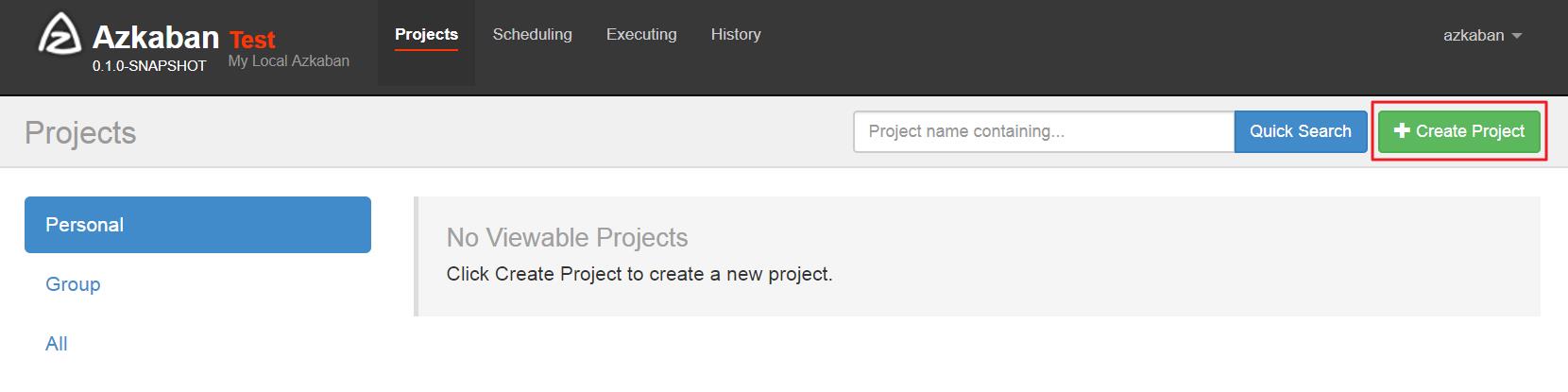
上传zip压缩包:

execute执行:
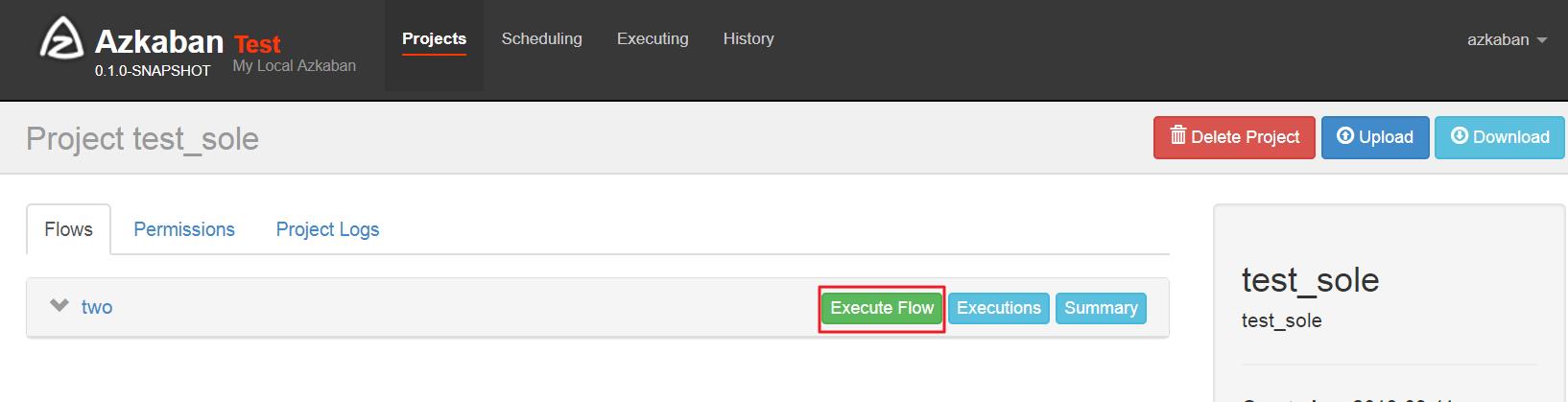
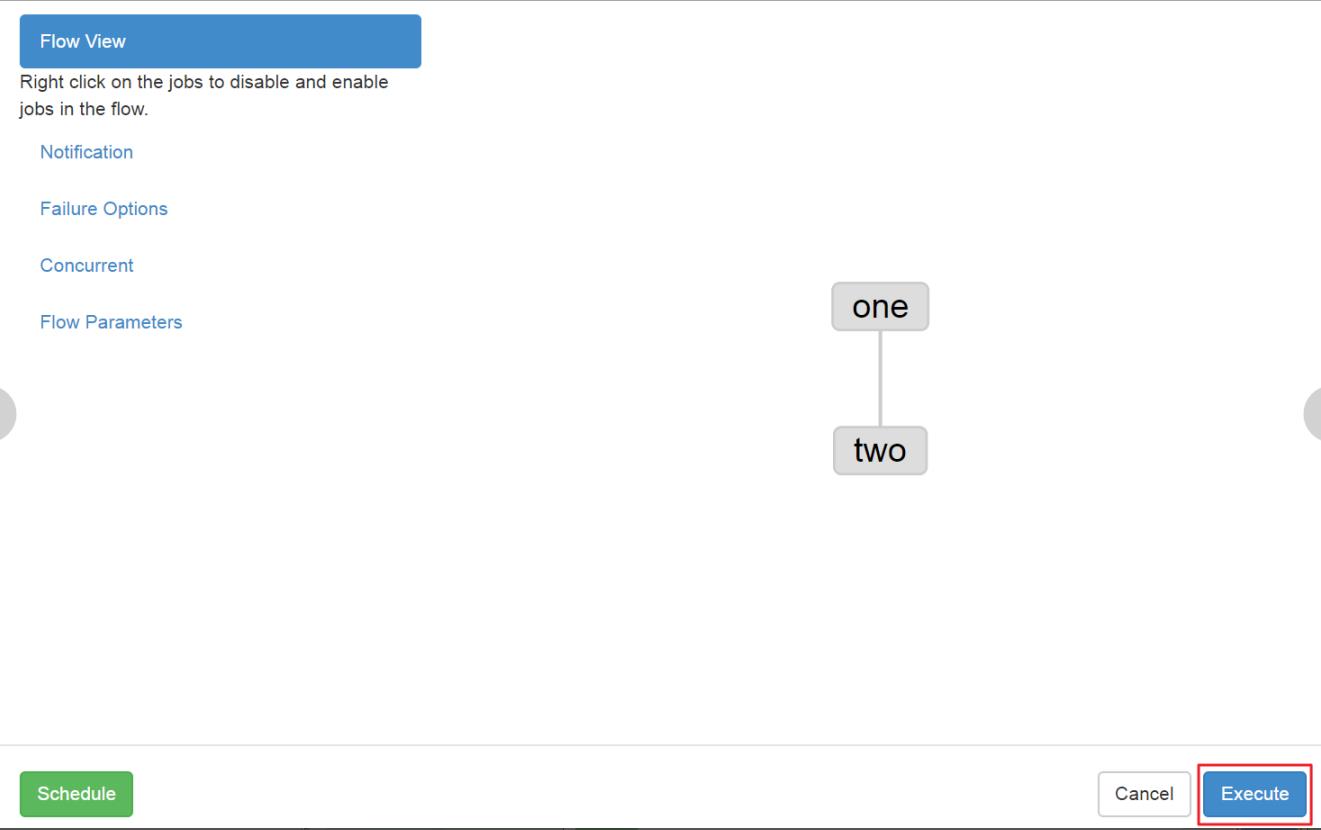
执行页面:
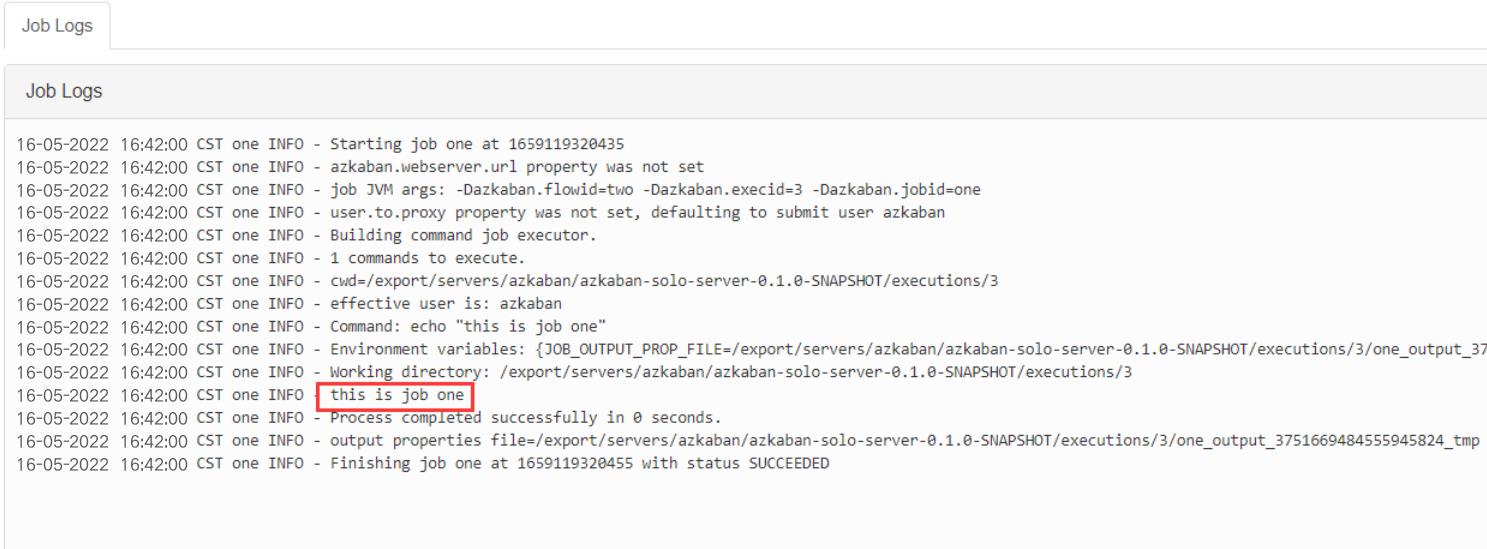
执行结果查看:

六、Azkaban使用实战
1、shell command调度
- 创建job描述文件
vi command.job#command.job
type=command
command=echo 'hello'
- 将job资源文件打包成zip文件
zip command.job - 通过azkaban的web管理平台创建project并上传job压缩包
- 首先创建Project
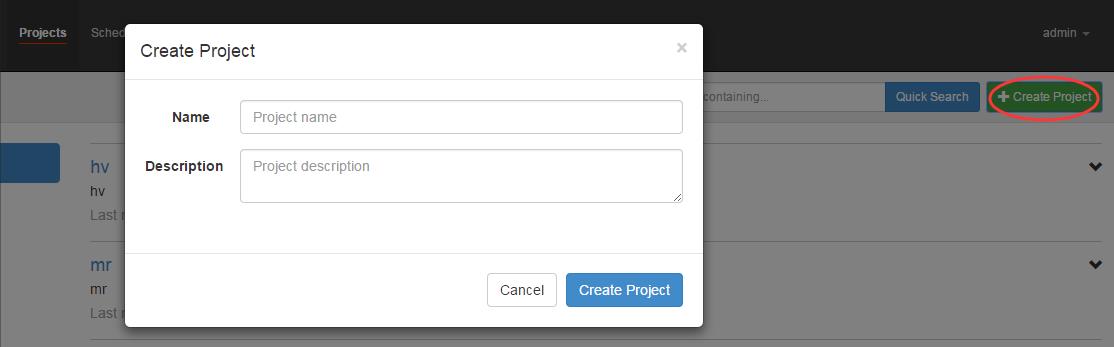
- 上传zip包

- 启动执行该job

2、job依赖调度
- 创建有依赖关系的多个job描述
- 第一个job:foo.job
# foo.job
type=command
command=echo foo
- 第二个job:bar.job依赖foo.job
# bar.job
type=command
dependencies=foo
command=echo bar
- 将所有job资源文件打到一个zip包中

- 在azkaban的web管理界面创建工程并上传zip包
- 启动工作流flow
3、HDFS任务调度
- 创建job描述文件
# fs.job
type=command
command=hadoop fs -mkdir /azaz
- 将job资源文件打包成zip文件
- 通过azkaban的web管理平台创建project并上传job压缩包
- 启动执行该job
4、定时任务调度
除了手动立即执行工作流任务外,azkaban也支持配置定时任务调度。开启方式如下:
首页选择待处理的project
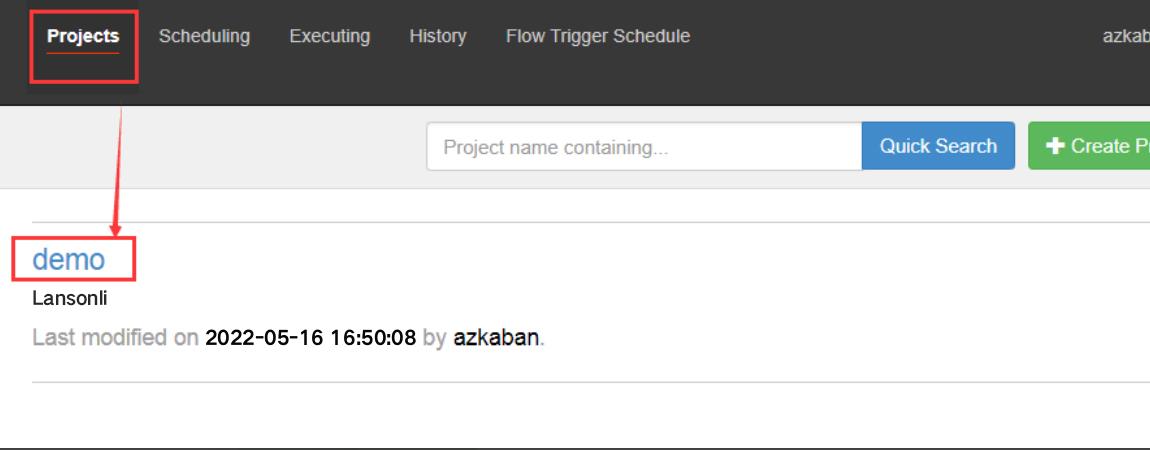
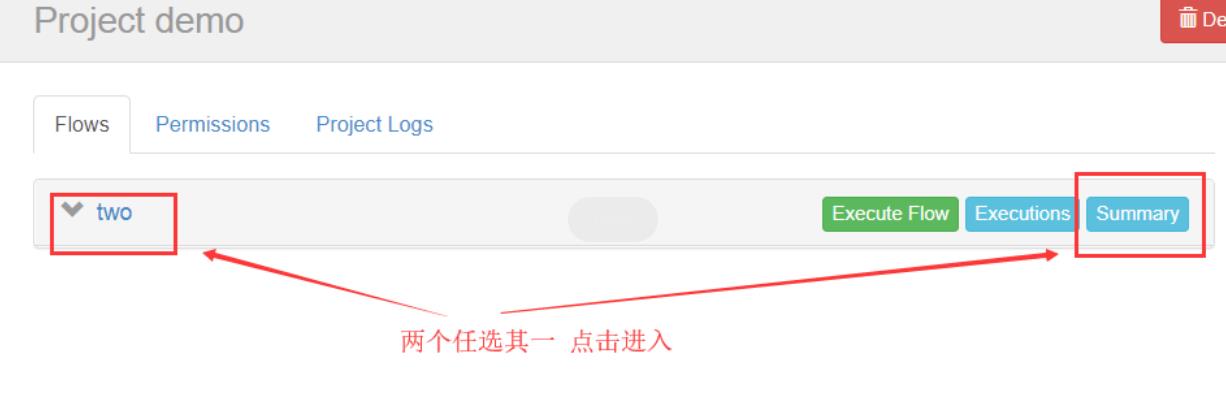
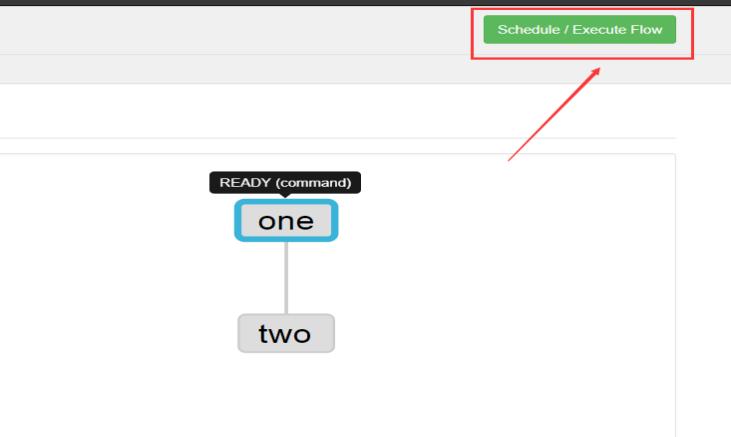
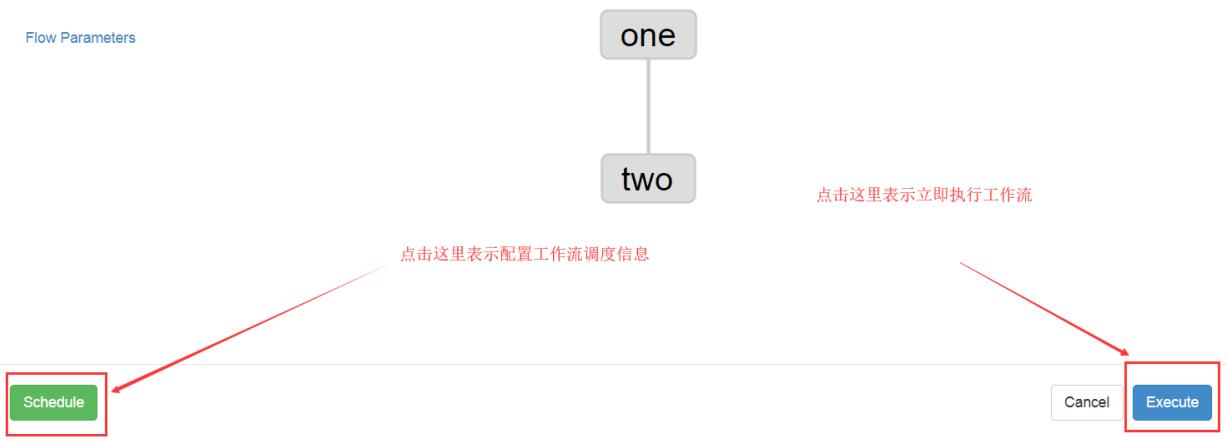
上述图片中,选择左边schedule表示配置定时调度信息,选择右边execute表示立即执行工作流任务。

七、Azkaban进行主题及指标业务调度开发
1、数据同步调度
shell脚本(scheduler.sh)
#!/bin/sh
cls=$1
flag=0
clsDwd=cn.it.logistics.offline.dwd.$clsDWD
clsDws=cn.it.logistics.offline.dws.$clsDWS
baseDir=/export/services/logistics/lib/
if [[ $cls = "Customer" || $cls = "ExpressBill" || $cls = "TransportTool" || $cls = "Warehouse" || $cls = "Waybill" ]]; then
echo -e "\\e[32m==== MainClass is: "$clsDwd" and "$clsDws"\\e[0m"
flag=1
else
echo -e "\\e[31mUsage : \\n\\tExpressBill\\n\\tCustomer\\n\\tTransportTool\\n\\tWarehouse\\n\\tWaybill\\e[0m"
fi
if [[ $flag = 1 ]]; then
echo -e "\\e[32m==== builder spark commands ====\\e[0m"
cmd1="spark-submit --packages org.apache.kudu:kudu-spark2_2.11:1.9.0-cdh6.2.1 --class $clsDwd --master yarn --deploy-mode cluster --driver-memory 512m --executor-cores 1 --executor-memory 512m --queue default --verbose $baseDirlogistics-offline-1.0-SNAPSHOT.jar"
cmd2="spark-submit --packages org.apache.kudu:kudu-spark2_2.11:1.9.0-cdh6.2.1 --class $clsDws --master yarn --deploy-mode cluster --driver-memory 512m --executor-cores 1 --executor-memory 512m --queue default --verbose $baseDirlogistics-offline-1.0-SNAPSHOT.jar"
echo -e "\\e[32m==== CMD1 is: $cmd1 ====\\e[0m"
echo -e "\\e[32m==== CMD2 is: $cmd2 ====\\e[0m"
fi
if [[ $flag = 1 && `ls -A $baseDir|wc -w` = 1 ]]; then
echo -e "\\e[32m==== start execute $clsDwd ====\\e[0m"
sh $cmd1
echo -e "\\e[32m==== start execute $clsDws ====\\e[0m"
sh $cmd2
else
echo -e "\\e[31m==== The jar package in $baseDir directory does not exist! ====\\e[0m"
echo -e "\\e[31m==== Plase upload logistics-common.jar,logistics-etl.jar,logistics-generate.jar ====\\e[0m"
fi2、job编写
- 快递单主题Job(schedulerExpressBill.job)
#command
type=command
command=sh /export/services/logistics/bin/scheduler.sh ExpressBill- 运单主题Job(schedulerWaybill.job)
#command
type=command
command=sh /export/services/logistics/bin/scheduler.sh Waybill- 仓库主题Job(schedulerWarehouse.job)
#command
type=command
command=sh /export/services/logistics/bin/scheduler.sh Warehouse- 车辆主题Job(schedulerTransportTool.job)
#command
type=command
command=sh /export/services/logistics/bin/scheduler.sh TransportTool- 客户主题Job(schedulerCustomer.job)
#command
type=command
command=sh /export/services/logistics/bin/scheduler.sh Customer3、操作步骤
- 将项目打成jar包
- 在Azkaban的WebUI创建一个Project(例如Waybill运单ETL)
- 点击“Waybill运单ETL”项目进去,然后再点击右上角上传按钮上传schedulerWaybill.zip(将schedulerWaybill打进压缩包,压缩包名为schedulerWaybill.zip)
- 设置该调度程序的触发周期为:0 1 0 * * *(每天0点01分执行)
- 提交运行,Azkaban会等时间到了就开始运行
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于客快物流大数据项目(六十八):工作流调度的主要内容,如果未能解决你的问题,请参考以下文章