阿里开源自研工业级稀疏模型高性能训练框架 PAI-HybridBackend
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里开源自研工业级稀疏模型高性能训练框架 PAI-HybridBackend相关的知识,希望对你有一定的参考价值。
简介:近年来,随着稀疏模型对算力日益增长的需求, CPU集群必须不断扩大集群规模来满足训练的时效需求,这同时也带来了不断上升的资源成本以及实验的调试成本。为了解决这一问题,阿里云机器学习PAI平台开源了稀疏模型高性能同步训练框架HybridBackend,使得在同成本下GPU集群训练吞吐较CPU集群提升至5倍,大幅降低调试成本。那么HybridBackend背后的技术框架如何设计?未来有哪些规划?本文将和大家一起来深入了解。

作者 | 石浪、满神
来源 | 阿里开发者公众号
近年来,随着稀疏模型对算力日益增长的需求, CPU集群必须不断扩大集群规模来满足训练的时效需求,这同时也带来了不断上升的资源成本以及实验的调试成本。
为了解决这一问题,阿里云机器学习PAI平台开源了稀疏模型高性能同步训练框架HybridBackend,使得在同成本下GPU集群训练吞吐较CPU集群提升至5倍,大幅降低调试成本,同时 HybridBackend 相关论文 《PICASSO: Unleashing the Potential of GPU-centric Training for Wide-and-deep Recommender Systems》也被 ICDE 22' 所收录。HybridBackend背后的技术框架如何设计?未来有哪些规划?今天一起来深入了解。
一 HybridBackend是什么
HybridBackend是阿里云机器学习平台PAI自研的、面向稀疏模型训练的高性能同步训练框架,核心能力是大幅提升GPU集群单位成本下的训练吞吐性能。目前HybridBackend已经在阿里巴巴集团内部有多个业务落地,将阿里妈妈智能引擎训练引擎团队的定向广告业务年数据训练任务时间由1个月缩短至2天,同时HybridBackend在公有云多个头部互联网企业中也有成功应用。
二 项目背景
以搜索、推荐、广告业务为主要应用的稀疏模型训练系统一直是学界和业界研究的热点之一。相比于计算机视觉(CV)和自然语言处理(NLP)为代表的稠密模型训练,稀疏模型针对离散型特征(以 categorical ID 作为训练数据)使用Embedding特征表达有着百GB至数十TB级别的内存占用消耗(比普通的CV、NLP模型参数高出一到两个数量级),从而突破了单机的内存容量限制,需要基于分布式系统的训练方案。
早期的此类分布式任务由于模型结构相对简单并且更新迭代缓慢,往往采用定制化的参数服务器(Parameter Server,PS)系统在大规模的CPU集群上进行训练。随着TensorFlow为代表的通用机器学习编程框架的出现,以及深度神经网络(DNN)在推荐类模型上的流行(deep recommender systems),业界逐渐转向基于通用机器学习编程框架(TensorFlow、PyTorch等)进行模型的端到端训练和推理,但是此时依然以参数服务器(PS)和大规模CPU集群作为训练的范式和基础设施。
三 面临挑战
随着稀疏模型对算力日益增长的需求(比如Attention等结构的加入),CPU集群必须不断扩大集群规模来满足训练的时效需求,这同时也带来了不断上升的资源成本以及实验的调试成本。
以NVIDIA GPU为代表的加速器(accelerator)弥补了CPU设备单位成本算力低下的劣势,在CV、NLP等算力需求大的训练任务上的应用已经成为行业共识。然而实践证明,如只是简单地将PS训练范式中的worker从CPU设备替换为GPU设备,并不能有效地提升训练任务的吞吐,通过 profiling GPU 的使用率,发现大量的GPU算力资源被闲置浪费。这说明,相比于CV、NLP类任务,稀疏模型训练有着自身的模型结构和训练数据的特性,使得传统的PS训练范式不能有效地发挥出GPU设备的优势。以深度推荐系统经典的 Wide and Deep 模型结构和TensorFlow框架为例,我们分析并总结了在PS架构下使用GPU设备训练的两个问题。
1 变化的硬件资源瓶颈

从上图的 Wide and Deep 模型结构可以看出,稀疏训练主要由Embedding阶段、特征交叉(feature interation)阶段和多层感知器(MLP)阶段组成,Embedding阶段在PS范式的训练下占据了至少50%以上的训练时间。经过分析发现,Embedding阶段的算子主要以访存密集型(memory access intensive)和通信密集型的算子(communication intensive)为主,主要需要的硬件资源是内存和网络的带宽,而后两个阶段的算子则是计算密集型的算子占主导,需要的资源是算力。这意味着在PS的范式训练下,任何一个阶段都有可能存在某一种硬件资源成为瓶颈而其他硬件资源被浪费的现象。以GPU的算力资源为例,我们观察GPU使用率(SM Util)在不同的训练阶段之间呈现脉冲式变化(pulse)。
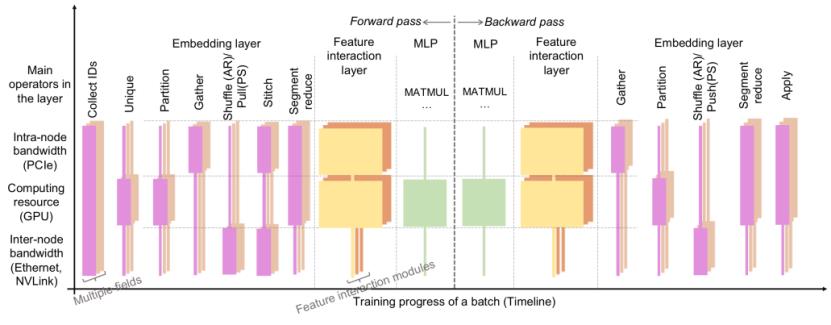
2 算子细碎化(fragmentation)
生产实际中的模型往往拥有上百路的Embedding特征查询,每一路的特征查询在TensorFlow内都会调用数十个算子操作(operations)。TensorFlow的引擎在调度上千级别的大量的算子操作需要额外的CPU线程开销;对于GPU设备来说,过多的 CUDA kernel 提交到流处理器上(TensorFlow下每个GPU设备只有一个stream抽象)带来了GPU Stream Multiprocessor (SM)的调度开销,同时每个算子处理数据的并发度又不高,从而很难打满GPU的计算单元。
类似的问题在CV、NLP等稠密模型的训练中也有涉及,一般采用基于编译技术的优化手段进行算子合并。在 Wide and Deep 模型这样的稀疏场景下,Embedding阶段的这些算子又往往具有 dynamic shape 的特点,在TensorFlow静态构图阶段无法获取准确的算子尺寸进行优化,导致类似TensorFlow-XLA等技术在此类场景下没有明显的收益。
这些问题说明,想要发挥出GPU等高性能硬件资源的极致性价比,提高单位成本下的训练吞吐,就必须设计新的训练框架。据我们了解,拥有大型搜索、广告、推荐业务的国内外企业以及硬件厂商都在着手进行新框架的研发,比如NVIDIA的Merlin-HugeCTR[1]等,然而阿里巴巴集团内云上集群普遍部署的是通用计算节点,且集群上需要执行多种异构的任务,换用专用硬件是很昂贵且不切实际的。
基于这种实际需求,我们推出了HybridBackend,能够同时适应集团内多元化且不断演进的稀疏模型技术。下文中我们将简要介绍HybridBackend的系统架构设计和技术亮点。
四 HybridBackend的系统架构
传统的参数服务器(PS)训练范式体现的是通过扩展硬件数量来适应模型训练规模的思路。我们的系统则是同时考虑到了硬件和软件(模型)两个层面的特点,并做到协同设计。高性能GPU集群的硬件特性决定了基本的训练范式,而稀疏模型本身的结构特点和数据分布带来的问题则通过更精细的系统优化手段来解决。
1 利用大 Batch Size 进行同步训练
因为GPU设备相对于CPU带来的巨大的算力提升,以往需要上百台CPU节点的集群可以用几十台机器的GPU集群来代替。要保持相同的总训练规模,同时提升单个GPU节点上的资源利用率,提升单个 GPU worker 上的 batch size 成为必然的选项。同时,因为集群规模的缩小,可以通过同步训练的方式有效避免过期梯度(staleness),从而提升模型训练的精度。
相对于CPU设备之间通过PCIe以及TCP进行网络通信,高性能的GPU集群在单个节点内的多个GPU设备之间往往配备了高速的网络互连(NVLink、NVSwitch),这些高速连接的带宽通常是TCP网络带宽的数百倍(第一代NVLINK标定达到300GB/s),而在多个机器节点之间也可以配备基于RDMA技术的高速网络设备,达到100-200Gbps的带宽。
选择同步训练的第二个好处是,可以使用高性能集合通信算子库(NVIDIA NCCL、阿里自研的ACCL等)来有效利用硬件机器的网络拓扑结构,从而提升通信的性能。上述通信库已经在CV、NLP之类的基于数据并行的同步训练任务上取得了很好的效果。
2 使用资源异构而角色同构的训练单元
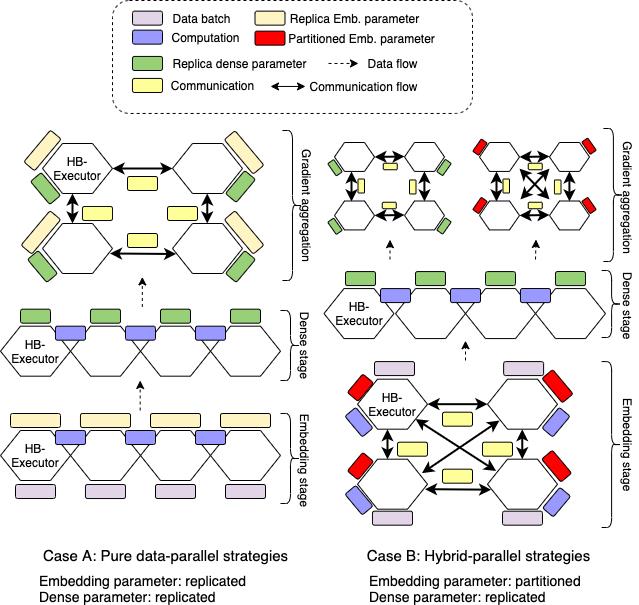
PS训练范式在系统的逻辑层面会指定不同的训练角色,比如server、worker、evaluator等。server节点一般分配具有大内存的CPU机器,而worker节点则会被分配到高主频的计算型CPU硬件上。这样形成了训练单元-任务角色-同构资源的耦合,通过增加训练单元数量来水平扩展(scale out)训练的规模。
而在高性能的GPU集群上,一个物理的机器节点往往包括多种异构的硬件资源,如CPU、GPU处理器、GPU之间的高速互连、DRAM(动态随机存取内存)、Non-volatile Memory(非易失性内存)等。这样,除了水平扩展节点数量外,还可以通过垂直扩展利用多种异构硬件资源来达到扩大训练规模的目标。
针对这种硬件架构,我们的系统设计中只保留统一的训练执行单元(Executor),每个Executor通过内部的异构硬件资源来执行不同的训练任务角色。一方面,Executor内部任务执行时,可以有效地利用底层硬件资源之间的locality加速训练;另一方面,Executor内部的硬件资源可以同时满足不同的分布式训练范式所需要的硬件资源,以方便我们在模型结构的不同部分进行混合并行训练策略。
五 深入优化:HybridBackend的技术亮点
因为稀疏模型结构和训练数据本身的特性, 变化的硬件资源瓶颈和算子细碎化,上述的系统架构在实际任务中还是会存在一些影响GPU等硬件设备使用率的问题。
举例来说,同步训练范式下,所有Executor通过集合通信进行embedding的shuffle时,网络带宽资源成为瓶颈,而GPU的计算资源被闲置。一种解决思路是对硬件资源进行定制化,比如增加网络带宽资源来消除通信瓶颈,但是这样的做法会使得硬件的资源配置和特定的模型结构耦合,是专用推荐系统的老思路。
我们的目标还是希望系统可以架构在云服务上可得的,数量容易水平扩展的通用硬件配置之上(commodity hardware)。某些硬件厂商也尝试通过 Huge kernel 的形式(将Embedding层所有的计算手工融合到一个kernel内)来解决算子细碎化的问题,这样的做法也很难支持模型结构快速迭代的需求,背离了通用编程架构的设计初衷。
据此,我们从软硬协同的思路出发,设计了如下的几个系统优化手段:
1 基于数据和算子感知的合并
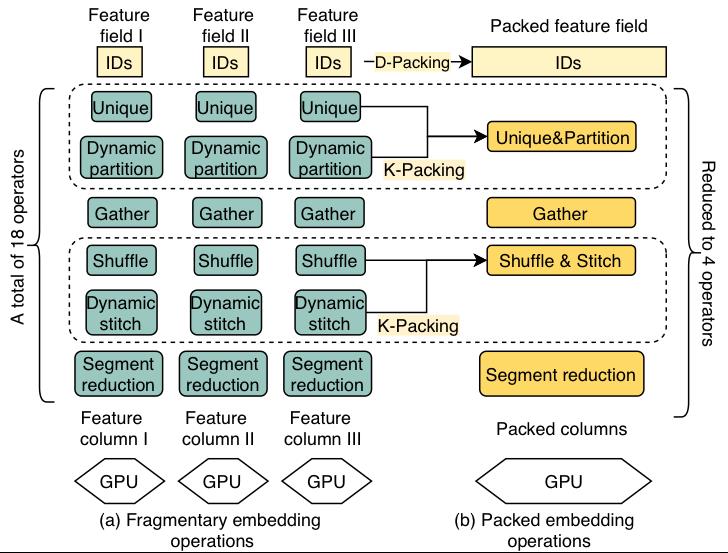
根据稀疏模型的结构特点,大部分细碎的算子来源于庞大的Embedding特征查询(lookup)数量,我们设计了D-Packing这一优化技术。
对于每一路查询,尽管输入的训练数据不同,但使用的算子组合是相同的。对于这种具有数据并行特点的模式,具有相同属性(维度、初始化器、标定特征组等)的Embedding表将被合并为一张新的Embedding表,而后续的访存查询算子也可以被合并为一个新的大算子。合并算子可以用多线程的方式有序查询Embedding,相对于乱序查询或分成若干小表查询,能有显著的性能提升。查询完毕后,再依原有代码需要进行反去重和归位,真正做到了对用户透明。
此外,通过分析特征查询阶段各个算子在分布式环境下的语义,我们将部分的kernel进行融合K-Packing,比如通过融合shuffle和stitch算子来消除冗余的数据拷贝。
通过数据和算子两个维度的基于语义的融合,我们既减少了总体的算子数量,降低fragmentation,同时又避免了所有算子融合在一起而丢失了通过算子间穿插遮掩来提升硬件利用率的优化机会。
2 基于硬件资源瓶颈感知的交错执行

为了消除同时执行相同硬件资源需求的算子而造成的瓶颈, 我们设计了两种算子穿插遮掩执行(interleaving)的优化手段。
其一,D-Interleaving是通过对训练数据batch的切分利用pipeline的机制来调度穿插不同资源类型的算子,这样可以在训练的任何阶段缓解某一种资源的瓶颈。比如在大batch size的训练场景下,稀疏模型的MLP阶段也会产生很高的feature map显存占用,通过D-Interleaving就可以有效降低单个GPU设备上的峰值显存占用,从而使得更大的batch size训练成为可能。
其二,K-Interleaving是在Embedding Layer内部不同的特征查询路数之间做算子的穿插和遮掩,比如将通信密集的Shuffle操作和内存访问密集的Gather进行遮掩,可以有效提升这两种资源的使用率。
3 基于数据频次感知的参数缓存

在解决Executor内部多个级别的存储(GPU显存、DRAM等)之间的带宽和延迟问题上,我们针对稀疏模型训练数据的分布特点,提出了一种感知数据访问频次分布的caching机制。通过统计训练数据的ID,将最热的访问数据缓存到GPU的显存中,而冷数据以及哈希表结构则存放在主内存中,主内存中的数据将根据ID的访问频率变化,定期将top-k的高频ID对应的embeddings刷新到GPU显存上的缓存中。这样的混合存储可以同时结合GPU显存的高带宽和DRAM的大容量,后续,这套混合存储的设计还可以扩展到使用 Intel Persistent Memory、Non-volatile Memory 等更多的硬件设备上。
六 应用场景
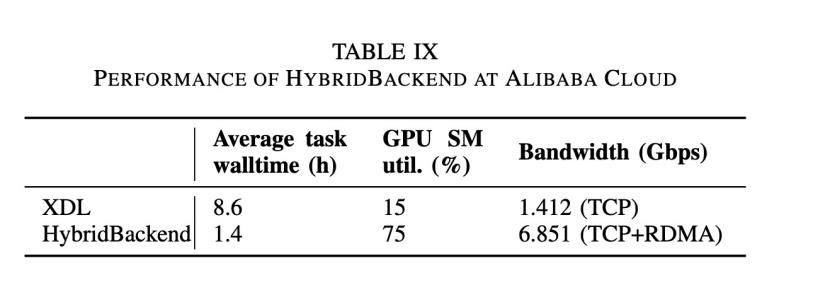
HybridBackend已经成功在阿里妈妈智能引擎训练引擎团队定向广告业务有了落地。在阿里妈妈CAN模型下HybridBackend相对于上一代的XDL训练框架具有明显的性能优势,在下表中可以看到其在训练时长等多个指标下获得的显著提升。
同时,我们还基于阿里妈妈定向广告一年累计的训练数据对模型规模增长下的HybridBackend性能表现做了测试,结果如下表所示。可以看到,在使用128张GPU进行千亿规模参数模型的训练时,同样是消费1年的数据量,高性能集群上的HybridBackend仅仅需要2天的时间就能完成训练任务,而普通集群上的XDL-PS模式则需要约1个月的时间。

七 Roadmap
后续我们计划定期发布Release版本。近期的Roadmap如下:
- v0.6.0 (2022年5月):支持端到端分布式同步训练与评估。
- v0.7.0 (2022年9月):优化 GPU 利用率与显存占用。
- v0.8.0 (2023年1月):进一步优化云上训练性能。
此外,中长期,我们将在训练策略的演进,新硬件的优化,服务化能力的支持等几个探索性方向上持续投入精力,也欢迎各种维度的反馈和改进建议以及技术讨论,同时我们十分欢迎和期待对开源社区建设感兴趣的同行一起参与共建。
参考文献
[1] Oldridge, Even, Julio Perez, Ben Frederickson, Nicolas Koumchatzky, Minseok Lee, Zehuan Wang, Lei Wu et al. "Merlin: A GPU Accelerated Recommendation Framework." In Proceedings of IRS . 2020.
本文为阿里云原创内容,未经允许不得转载。
以上是关于阿里开源自研工业级稀疏模型高性能训练框架 PAI-HybridBackend的主要内容,如果未能解决你的问题,请参考以下文章
华为开源自研AI框架昇思MindSpore入门体验:手写数字识别