认识机器学习和MLlib
Posted 婷婷来了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了认识机器学习和MLlib相关的知识,希望对你有一定的参考价值。
§能力目标
- 能够描述机器学习工作过程
- 能够创建本地向量、标注点、本地矩阵
- 能够使用Spark Mllib进行基本统计
文章目录
前言
提示:以下是本篇文章正文内容,下面案例可供参考
一、认识机器学习
1.什么是机器学习?
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,专门研究计算机如何模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习是一种能够赋予机器进行自主学习,不依靠人工进行自主判断的技术,它和人类对历史经验归纳的过程有着相似之处。
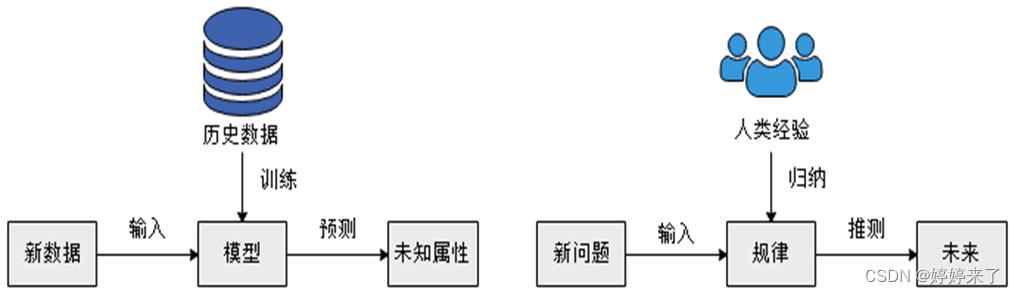
机器学习是对人类思考过程一个抽象,由于机器学习不是通过编程的形式得出结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关结论。
在机器学习领域中,按照学习方式分类,可以让研究人员在建模和算法选择的时候,考虑根据输入数据来选择合适的算法从而得到更好的效果,通常机器学习可以分为有监督学习和无监督学习两种。
2.有监督学习
通过已有的训练样本(即已知数据以及其对应的输出)训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。例如分类、回归和推荐算法都属于有监督学习。
3.无监督学习
根据类别未知(没有被标记)的训练样本,而需要直接对数据进行建模,我们无法知道要预测的答案。例如聚类、降维和文本处理的某些特征提取都属于无监督学习。
4.机器学习的应用
(1)电子商务:机器学习在电商领域的应用主要涉及搜索、广告、推荐三个方面。
(2)医疗:普通医疗体系并不能永远保持精准且快速的诊断,在目前研究阶段中,技术人员利用机器学习对上百万个病例数据库的医学影像进行图像识别分析数据,并训练模型,帮助医生做出更精准高效的诊断。
(3)金融:机器学习正在对金融行业产生重大的影响,例如在金融领域最常见的应用是过程自动化,该技术可以替代体力劳动,从而提高生产力,例如摩根大通推出了利用自然语言处理技术的智能合同的解决方案,该解决方案可以从文件合同中提取重要数据,大大节省了人工体力劳动成本;机器学习还可以应用于风控领域,银行通过大数据技术,监控账户的交易参数,分析持卡人的用户行为,从而判断该持卡人信用级别。
二、认识MLlib
1.基本原理
MLlib是Spark提供的可扩展的机器学习库,其中封装了一些通用机器学习算法和工具类,包括分类、回归、聚类、降维等,开发人员在开发过程中只需要关注数据,而不需要关注算法本身,只需要传递参数和调试参数。
Spark中的机器学习流程大致分为三个阶段,即数据准备阶段、训练模型评估阶段以及部署预测阶段。
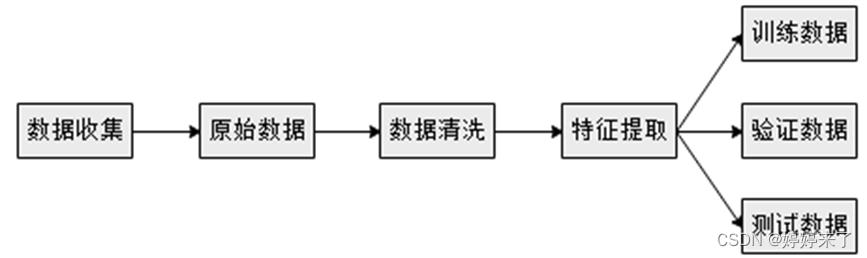
2.数据准备阶段
在数据准备阶段,将数据收集系统采集的原始数据进行预处理,清洗后的数据便于提取特征字段与标签字段,从而生产机器学习所需的数据格式,然后将数据随机分为3个部分,即训练数据模块、验证数据模块和测试数据模块。
3.训练模型评估阶段
通过Spark MLlib库中的函数将训练数据转换为一种适合机器学习模型的表现形式,然后使用验证数据集对模型进行测试来判断准确率,这个过程需要重复许多次,才能得出最佳模型,最后使用测试数据集再次检验最佳模型,以避免过渡拟合的问题。
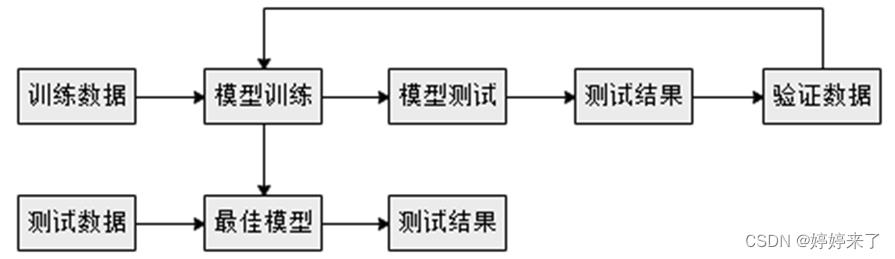
4.部署预测阶段
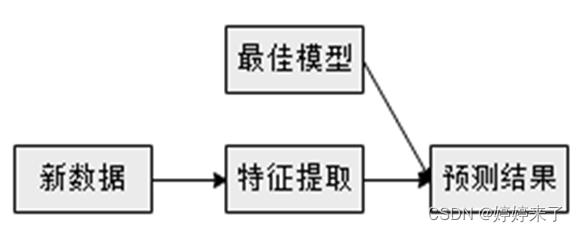
通过多次训练测试得到最佳模型后,就可以部署到生产系统中,在该阶段的生产系统数据,经过特征提取产生数据特征,使用最佳模型进行预测,最终得到预测结果。这个过程也是重复检验最佳模型的阶段,可以使生产系统环境下的预测更加准确。
三、Mllib 操作
Mllib的主要数据类型:本地向量、标注点、本地矩阵
1.本地向量
密集向量(Dense)
密集向量是由Double类型的数组支持,例如,向量(1.0,0.0,3.0)的密集向量表示的格式为[1.0,0.0,3.0]。
导包
import org.apache.spark.mllib.linalg.Vector,Vectors
创建一个密集本地向量
val dv:Vector=Vectors.dense(1,0,0.0,3.0)
稀疏向量(Sparse)
稀疏向量是由两个并列的数组支持,例如向量(1.0,0.0,3.0)的稀疏向量表示的格式为(3,[0,2],[1.0,3.0]),其中3是向量(1.0,0.0,3.0)的长度,[0,2]是向量中非0维度的索引值,即向量索引0和2的位置为非0元素,[1.0,3.0]是按索引排列的数组元素值。
创建一个稀疏本地向量
val sv1:Vector=Vectors.sparse(3,Array(0,2),Array(1.0,3.0)
通过指定非零项目,创建稀疏本地向量
val sv1:Vector=Vectors.sparse(3,Array(0,2),Array(1.0,3.0)
标注点
标注点是一种带有标签的本地向量,标注点通常用于监督学习算法中,MLlib使用Double数据类型存储标签,因此可以在回归和分类中使用标记点。
标注点实现类org.apache.spark.mllib.regression.LabeledPoint
导包
import org.apache.spark.mllib.linalg.Vector,Vectors
import org.apache.spark.mllib.regression.LabeledPoint
创建带有正标签和密集向量的标注点
val pos=LabeledPoint(1.0,Vectors.dense(1.0,0.0,3.0))
创建带有负标签和稀疏向量的标注点
val neg=LabeledPoint(0.0,Vectors.sparse(3,Array(0.2),Array(1.0,3.0)))
3.本地矩阵
密集矩阵
密集矩阵将所有元素的值存储在一个列优先的双精度数组中。
导包
import org.apache.spark.mllib.linalg.Matrix,Matrices
创建一个3行2列的密集矩阵
val dm:Matrix=Matrices.dense3,2,Array(1.0,3.0,5.0,2.0,4.0,6.0))
稀疏矩阵
稀疏矩阵则将以列优先的非零元素压缩到稀疏列(CSC)格式中。
创建一个3行2列的稀疏矩阵
val sm:Matrix=Matrices.sparse(3,2,Array(0,1,3),Array(0,2,1),Array(9,6,8))
Array(9,6,8)为非零值,Array(0,2,1)为非零值对应行号,Array(0,1,3)起始值固定为0,其中1为第1列非零个数,3为第2前所有列的非零个数之和的值(1+2)。
矩阵实际为:
9.0 0
0 8.0
0 6.0
四、使用Mllib的基本统计方法
MLlib提供了很多统计方法,包含摘要统计、相关统计、分层抽样、假设检验、随机数生成等统计方法,利用这些统计方法可帮助用户更好地对结果数据进行处理和分析
1.摘要统计
统计量的计算用到Statistics类,摘要统计主要方法如下所示。
| 方法名称 | 相关说明 |
|---|---|
| count | 列的大小 |
| mean | 每列的均值 |
| variance | 每列的方差 |
| max | 每列的最大值 |
| min | 每列的最小值 |
| numNonzeros | 每列非零向量的个数 |
摘要统计操作案例:

2.相关统计
相关系数是反应两个变量之间相关关系密切程度的统计指标,这也是统计学中常用的统计方式,MLlib提供了计算多个序列之间相关统计的方法,目前MLlib默认采用皮尔森相关系数计算方法。皮尔森相关系数也称皮尔森积矩相关系数,它是一种线性相关系数。
(1)其中 、 及 分别是对 样本的标准分数、样本平均值和样本标准差。
(2)n表示样本量,分别为两个变量的观测值和均值
(3)r表示相关系数,它描述的是变量间线性相关强弱的程度,取值范围介于-1到1之间;若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r的绝对值越大表明相关性越强,需要注意的是这里并不存在因果关系。若r=0,表明两个变量间不是线性相关,但有可能是其他方式的相关(比如曲线方式)
相关统计操作案例:


上述代码中,通过Statistics.corr(data, “pearson”)方法选择使用皮尔森相关系数算法获得数据的相关系数,但在Mllib中,还提供了斯皮尔曼等级相关系数方法,只需要在corr()方法中标注为“spearman”参数即可。
五、Spark Mllib统计方法:分层抽样
分层抽样法也叫类型抽样法,将总体按某种特征分为若干层级,再从每一层内进行独立取样,组成一个样本的统计学计算方法。
例如某手机厂家估算当地潜在用户,可以将当地居民消费水平作为分层基础,减少样本中的误差,如果不采取分层抽样,仅在消费水平较高的用户中做调查,是不能准确的估算出潜在的用户。
1.相关统计操作案例
创建键值对RDD
val data=sc.parallelize(
| Seq((1,'a'),(1,'b'),(2,'c'),(2,'d'),(2,'e'),(3,'f'))
| )
设定抽样格式
val fraction=Map(1->0.1,2->0.6,3->0.3)
从每层获取抽样样本
val approxSample=data.sampleByKey(withReplacement=false,fractions=fraction)
从每层获取精确样本
val exactSample=data.sampleByKeyExact(withReplacement=false,fractions=fraction)
打印抽样样本
approxSample.foreach(println)
打印精确样本
exactSample.foreach(println)
在上述代码中,用到了两种分层抽样方法,其中sampleByKey()方法需要作用于一个键值对数组,其中Key用于分类,Value可以是任意值。然后通过fration参数定义分类条件和采样概率。fractions参数被定义成一个Map类型,Key是键值对数组的分层条件,Value是满足Key条件的采样比例。1.0代表概率为100%,0.1代表概率为10%。withReplacement代表每次抽样是否有放回。
sampleByKeyExact()方法会对全量数据做采样计算。对于每个类别,都会产生(fk X nk)个样本,其中fk是键为fraction的Key的样本类别采样的比例,nk是Key所拥有的样本数。sampleByKeyExact采样的结果会更准确,有99. 99%的置信度,但耗费的计算资源也更多。
在上述代码中,用到了两种分层抽样方法,其中sampleByKey()方法需要作用于一个键值对数组,其中Key用于分类,Value可以是任意值。然后通过fration参数定义分类条件和采样概率。fractions参数被定义成一个Map类型,Key是键值对数组的分层条件,Value是满足Key条件的采样比例。1.0代表概率为100%,0.1代表概率为10%。withReplacement代表每次抽样是否有放回。
sampleByKeyExact()方法会对全量数据做采样计算。对于每个类别,都会产生(fk X nk)个样本,其中fk是键为fraction的Key的样本类别采样的比例,nk是Key所拥有的样本数。sampleByKeyExact采样的结果会更准确,有99. 99%的置信度,但耗费的计算资源也更多。
sampleByKey( )方法和sampleByKeyExact()方法的区别在于:
-
sampleByKey()方法每次都得通过给定的概率以一种类似于掷硬币的方式来决定这个观察值是否被放入样本,因此一遍就可以过滤完所有数据,最后得到一个近似大小的样本,但往往并不够准确。
-
sampleByKey()方法每次都得通过给定的概率以一种类似于掷硬币的方式来决定这个观察值是否被放入样本,因此一遍就可以过滤完所有数据,最后得到一个近似大小的样本,但往往并不够准确。
以上是关于认识机器学习和MLlib的主要内容,如果未能解决你的问题,请参考以下文章
学习笔记Spark—— Spark MLlib应用—— 机器学习简介Spark MLlib简介