ElasticSearch系列之索引机制学习笔记
Posted smileNicky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch系列之索引机制学习笔记相关的知识,希望对你有一定的参考价值。
前言
在上一章的学习,我们对ElasticSearch有了比较清晰的理解,然后本博客继续学习ES中比较重要的核心原理和具体实现。相对于mysql的索引机制,大部分是基于B+树的,需要我们进行手动创建索引,但是ES的索引是不需要手动创建的,默认是自动创建索引的。所以学习ES的倒排索引可以和MySQL的索引做一个对比,进行学习,思考一下为什么ES的倒排索引可以达到近实时(NRT)的查询效率
知识点
- 知道ES的倒排索引具体实现?
- 什么是FST和作用?
- 索引帧Frame Of Reference的实现原理
- Roaring Bitmaps 咆哮位图的作用
1、什么是倒排索引?
ES的宗旨就是“一切为了查询”,ES查询之所以快,其实就是主要因为index,也就是Inverted index,翻译过来过来是“倒排索引”。所以倒排索引是怎么样的?举个例子,有如下的数据需要进行保存
| ID | Name | Sex | Job |
|---|---|---|---|
| 1 | Tom | Man | driver |
| 2 | Jack | Man | driver |
| 3 | Alice | Female | actor |
Name:
| Term | Posting List |
|---|---|
| Tom | 1 |
| Jack | 2 |
| Alice | 3 |
Sex:
| Term | Posting List |
|---|---|
| Man | [1,2] |
| Female | 3 |
Job:
| Term | Posting List |
|---|---|
| driver | [1,2] |
| actor | 3 |
-
Posting List(倒排表)
ES会为每一个Field建立一个倒排索引。会对document数据进行分词,tom、man、driver这些叫term(分类索引),而[1,2]是Posting List(倒排表),Posting List存储了所有符合某个term的文档id。比如要查找job为driver的人员信息,马上就可以得出有ID为1和2的人员信息。但是如果有上千万数据,而且要通过name查找? -
Term Dictionary(词典)
为了通过上述所说的通过name查找的情况,ES会将所有term排个序,然后通过二分法查找term,所以查找效率是log(N),这种查找就像通过字典查找一样,这就是Term Dictionary。不过熟悉B/B+树的会知道,这好像和传统B/B+树的方式是一样的,MySQL的大部分索引也是直接用B+树建立索引词典指向被索引的数据 -
Term Index(词典索引)
相对于B/B+树的查找来说,ES的查询性能更进一步,ES希望将这个词典搬到内存中,当然直接将词典数据直接搬到内存也是不合理的,如果有大量的数据,内存估计都不够用。ES是通过一种建立词典索引(Term Index)的方式,只将占用空间比较小的词典索引放在内存就像,这个词典索引一般只保存词典的前缀或者后缀和对应关系,所以现在的关系可以用图表示:
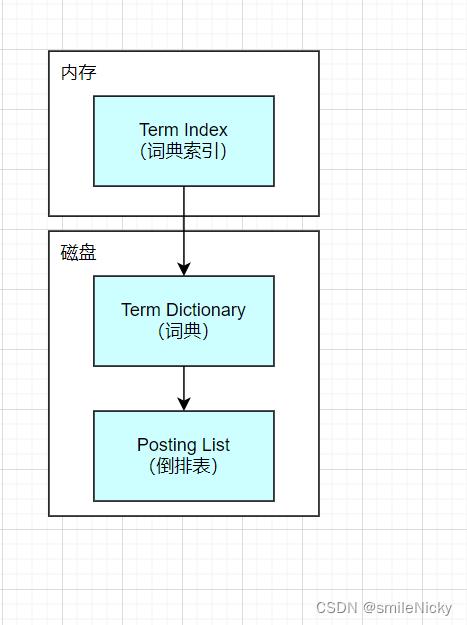
- B树是通过减少磁盘的寻道次数提高查询性能;
- B+树是尽量将随机读变成顺序读提高查询性能;
- ES更进一步,在倒排表和二分查找的基础上,在将词典索引搬到内存查找,所以查询效率会更快点
然后term index是怎么生成的?ES通过有穷状态转换器,简称FST技术生成Term Index,放到内存
2、Finite State Transducers(FST)
Finite State Transducers,简称FST,通常中文翻译为有穷状态转换器或者有限状态传感器
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
FST是一项将一个字节序列映射到block块的技术
假设有单词序列mop、moth、pop、star、stop和top,要映射到编号0…5,最简单的方法是定义一个Map<String,Integer>就可以,但是从内存占用少的角度考虑,有什么更好的方法,答案就是FST。
有排序好的单词mop、moth、pop、star、stop和top以及他们的顺序编号0,…,5,就可以生成如下的状态转换图:

遍历上面每一条边,比如输入pop的时候会经过p/2、o、p,相加得到的排序是2;而对于mop,得到的排序结果是0。
这棵树只保存term的前缀,通过这个前缀就可以找到磁盘对应的block,然后再通过block去找倒排表Posting List。为了压缩词典空间,比如mop和moth两个term,在都是以mo开头的block,那么在对应的词典里只会保存p和th,这样空间利用率提高了很多。FST有穷状态转换器可以节省很多内存空间,但是在查询时候需要更多的CPU资源。
维基百科的索引就是使用的FST,只使用了69MB的空间,只要花大约8秒钟,就为接近一千万个词条建立了索引,使用的堆空间不到256MB
通过FST,可以将词典索引放在内存中,并且占用很小的空间,通过词典索引就可以找到倒排表Posting List。但是还有一个问题,就是这些文档ID是会放在倒排表Posting List里的,如果有一亿个文档,每个文档10个字段,保存这个Posting List就需要花费10亿个integer的空间,磁盘占用也是比较大,所以ES采用了另外一种巧妙的方法来处理,这种技术是Frame of Reference
3、Frame of Reference
针对前面所说的文档ID占用太多磁盘空间,ES采用了一种压缩算法:Frame of Reference,可以翻译为“索引帧”
ES根据这种算法,会对倒排表
Posting List的文档进行delta-encoding(可以翻译为增量编码),然后分配为多个block,每个block正好包含256个文档,然后计算每一个block里面的数据最多需要占用多少位来保存这个文档ID,并将这个位数作为头信息放在每一个block前面,这个技术叫索引帧(Frame of Reference)
图来自https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps,这里进行中文翻译,注意,图例,假设每个block只有3个文件而不是256,实际情况应该是256的,这里还会进行增量编码,比如73+227=300 ,300+2=302,所以增量编码只会存储增量的值

这种压缩算法的原理是通过增量算法(delta-encoding),将原来的大数变成小数,仅存储增量值,再分为多个block,计算最多需要多少位(比如前面的图例327需要二进制的11111111,也是十进制的256,要8位才能存储),将计算总的,需要多少字节,加上header存的1位,转为字节存储,而不是用int(4个字节)存储,仅仅6个值就用了24字节
在返回结果的时候,其实也并不需要把所有的数据直接解压然后全部返回,可以直接返回一个迭代器iterator,直接通过迭代器的next方法逐一取出压缩的文档ID,通过这种方法极大的节省计算和内存开销
ES使用索引帧可以极大地节省posting list占用的磁盘空间和内存开销,同时ES为了提高filter过滤器查询的性能,也使用了缓存的方法,比如Roaring Bitmaps,可以翻译为咆哮位图
4、Roaring Bitmaps
ES使用Roaring Bitmaps缓存使用频率比较高的Filter查询, 原理是生成(fitler, segment数据空间)和ID列表的映射。
Roaring Bitmaps是由int数组和bitmap这两个数据结构改良过的成果,因为int数组速度虽然快,但是空间占用比较多;bitmap相对来说占用空间比较小,但是不管多少文档都需要12.5Mb的空间,即使只有一个文件也要
- Roaring Bitmaps根据每个id的高16位分配id到对应的block里面,比如第一个block里面id应
该都是在0到65535之间,第二个block的id在65536和131071之间,以此类推 - 然后对每一个block里面的数据,根据id数据选择short数组或者bitmap存储
- 如果数量小于4096,就用short数组存储
- 如果数量大于等于4096,就用bitmap保存
图来自https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps,这里进行中文翻译

5、倒排索引怎么做联合索引?
前面介绍的都是单个field的索引,如果是多个field索引的联合查询,倒排索引如何快速查询?
- 利用跳表(Skip List)的数据结构快速做“与”运算
- 利用bitset这种数据结构按位“与”运算
如图,跳表的数据结构:有一个有序链表Level0,挑出其中几个元素到level1和level2,每一个level越往上,选出来的指针元素就越少,查找时候从高level往低查找。比如查找45,先找到level2的25,然后往下查找到45,查找效率和level2相当,但是也是利用了一定的空间冗余来实现的

假如有下面的Posting List需要联合索引,如果使用跳表,对最短的Posting List中的每一个id,逐个在另外两个Posting list中查找看是否存在,最后得到交集的结果;
如果使用bitset,bitset是基于bitmap的,直接按位与,得到的结果就是最后的交集

6、ES索引使用注意事项
- ES默认是自动建索引的,不需要索引的字段,要明确定义出来
- 同样,对于string类型默认是会进行analysis(分词)的,不需要analysis的需要定义出来
- 文档的ID需要选择有规律的ID,随机性太大,比如UUID不利于查询
7、总结和思考
- ES之所以查询很快,主要是依赖于倒排索引的设计,尽量将数据放在内存,加上各种压缩算法和缓存算法。
- 由于索引数据量很大,不能直接将数据丢在内存,所以通过构建有序状态转换器FST放在内存中。
- 为了避免Posting List大量的文档ID占用太多磁盘空间,ES使用了索引帧(Frame of Reference)技术压缩posting list。
- ES还采用了Roaring Bitmap技术来缓存使用频率比较高的Filter搜索结果
8、参考资料
- https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps
- https://zhuanlan.zhihu.com/p/137574234
以上是关于ElasticSearch系列之索引机制学习笔记的主要内容,如果未能解决你的问题,请参考以下文章
ElasticsearchElasticsearch底层系列之Shard Allocation机制
Elasticsearch学习笔记ElasticSearch分布式机制