hdfs学习
Posted 捡黄金的少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hdfs学习相关的知识,希望对你有一定的参考价值。
1、hadoop生产环境版本选择
-
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
-
Apache版本最原始(最基础)的版本,对于入门学习最好。
-
Cloudera在大型互联网企业中用的较多。
-
Hortonworks文档较好。
-
-
mapr
-
Apache Hadoop
官网地址:Apache Hadoop
-
Cloudera Hadoop
官网地址:CDH Product Download
下载地址:http://archive.cloudera.com/cdh5/cdh/5/
-
2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
-
2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
-
CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
-
Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
-
Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
-
-
Hortonworks Hadoop
官网地址:Enterprise Data Management Platforms & Products | Cloudera
下载地址:Cloudera Enterprise Downloads
-
现cloudera与hortonworks已合并。
-
2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
-
公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
-
雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
-
Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
-
HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
-
Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
注意:Hortonworks已经与Cloudera公司合并
-
2、Hadoop由三个模块组成:
分布式存储HDFS、分布式计算MapReduce、资源调度引擎Yarn
1、HDFS文件分块存储&3副本
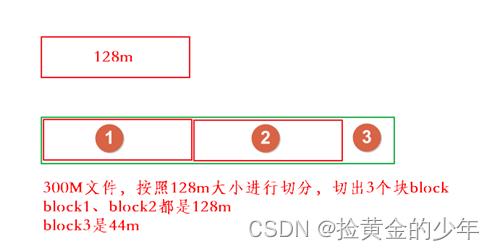
-
保存文件到HDFS时,会先默认按==128M==的大小对文件进行切分;效果如上图
-
数据以block块的形式进统一存储管理,每个block块默认最多可以存储128M的数据。
-
如果有一个文件大小为1KB,也是要占用一个block块,但是实际占用磁盘空间还是1KB大小,类似于有一个水桶可以装128斤的水,但是我只装了1斤的水,那么我的水桶里面水的重量就是1斤,而不是128斤
-
-
每个block块的元数据大小大概为150字节
-
所有的文件都是以block块的方式存放在HDFS文件系统当中,在hadoop1当中,文件的block块默认大小是64M,hadoop2当中,文件的block块大小默认是128M,block块的大小可以通过hdfs-site.xml当中的配置文件进行指定
<property>
<name>dfs.blocksize</name>
<value>块大小 以字节为单位</value><!-- 只写数值就可以 -->
</property>
-
为了保证block块的安全性,也就是数据的安全性,在hadoop2当中,文件默认保存==三个副本==,我们可以更改副本数以提高数据的安全性
-
在hdfs-site.xml当中修改以下配置属性,即可更改文件的副本数
-
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
2、HDFS抽象成数据块的好处
-
文件可能大于集群中任意一个磁盘 10T*3/128 = xxx块 2T,2T,2T 文件方式存—–>多个block块,这些block块属于一个文件。
-
使用块抽象而不是文件可以简化存储子系统
hdfs将所有的文件全部抽象成为block块来进行存储,不管文件大小,全部一视同仁都是以block块的形式进行存储,方便我们的分布式文件系统对文件的管理。
-
块非常适合用于数据备份;进而提供数据容错能力和可用性
3、hdfs架构
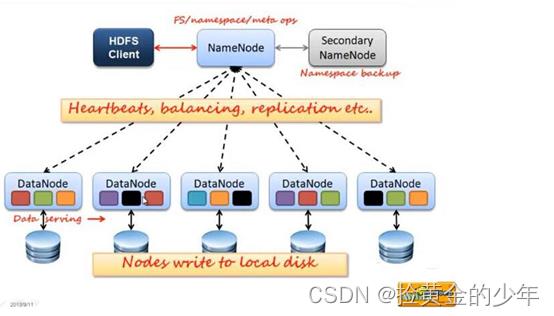
HDFS集群包括,NameNode和DataNode以及Secondary Namenode。
-
NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
-
DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
-
Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。最主要作用是辅助namenode管理元数据信
4、NameNode与Datanode的总结概述
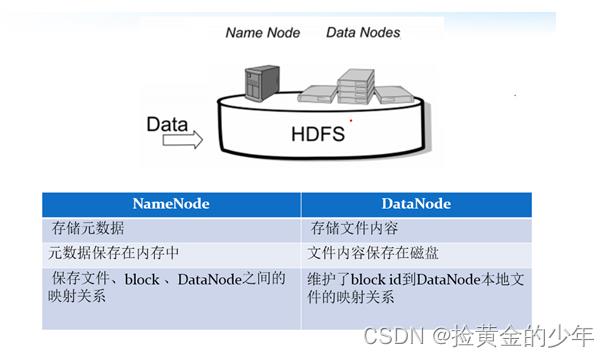
3、hdfs的shell命令操作
先要启动Hadoop集群,才能使用下面命令
脚本一键启动
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
启动集群
node01节点上执行以下命令
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver停止集群:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
浏览器查看启动页面
hdfs集群访问地址
http://192.168.52.100:50070/dfshealth.html#tab-overview
yarn集群访问地址
http://192.168.52.100:8088/cluster
jobhistory访问地址:
http://192.168.52.100:19888/jobhistory
1、如何查看hdfs或hadoop子命令的帮助信息,如ls子命令
hdfs dfs -help ls
hadoop fs -help ls #两个命令等价2、查看hdfs文件系统中指定目录的文件列表。对比linux命令ls
hdfs dfs -ls /
hadoop fs -ls /
hdfs dfs -ls -R /3、 在hdfs文件系统中创建文件
hdfs dfs -touchz /edits.txt
4、向HDFS文件中追加内容
hadoop fs -appendToFile edit1.xml /edits.txt #将本地磁盘当前目录的edit1.xml内容追加到HDFS根目录 的edits.txt文件
5、查看HDFS文件内容
hdfs dfs -cat /edits.txt
6、从本地路径上传文件至HDFS
#用法:hdfs dfs -put /本地路径 /hdfs路径
hdfs dfs -put /linux本地磁盘文件 /hdfs路径文件
hdfs dfs -copyFromLocal /linux本地磁盘文件 /hdfs路径文件 #跟put作用一样
hdfs dfs -moveFromLocal /linux本地磁盘文件 /hdfs路径文件 #跟put作用一样,只不过,源文件被拷贝成功后,会被删除
7、在hdfs文件系统中下载文件
hdfs dfs -get /hdfs路径 /本地路径
hdfs dfs -copyToLocal /hdfs路径 /本地路径 #根get作用一样
8、在hdfs文件系统中创建目录
hdfs dfs -mkdir /shell
9、在hdfs文件系统中删除文件
hdfs dfs -rm /edits.txt
将文件彻底删除(被删除文件不放到hdfs的垃圾桶里)
how?
hdfs dfs -rm -skipTrash /xcall
10、在hdfs文件系统中修改文件名称(也可以用来移动文件到目录)
hdfs dfs -mv /xcall.sh /call.sh hdfs dfs -mv /call.sh /shell
11、在hdfs中拷贝文件到目录
hdfs dfs -cp /xrsync.sh /shell
12、递归删除目录
hdfs dfs -rm -r /shell
13、列出本地文件的内容(默认是hdfs文件系统)
hdfs dfs -ls file:///home/hadoop/
14、查找文件
# linux find命令 find . -name 'edit*' # HDFS find命令 hadoop fs -find / -name part-r-00000 # 在HDFS根目录中,查找part-r-00000文件
15、总结
输入hadoop fs 或hdfs dfs,回车,查看所有的HDFS命令
许多命令与linux命令有很大的相似性,学会举一反三
有用的==help==,如查看ls命令的使用说明:hadoop fs -help ls
绝大多数的大数据框架的命令,也有类似的help信息
hdfs安全模式
-
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。
4、hdfs的java API开发
1、配置window电脑Hadoop环境
1、配置Hadoop环境
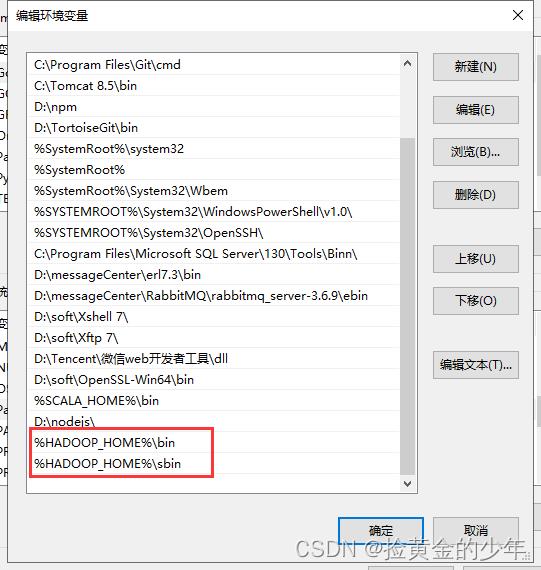
然后将下图中的hadoop.dll文件拷贝到C:\\Windows\\System32
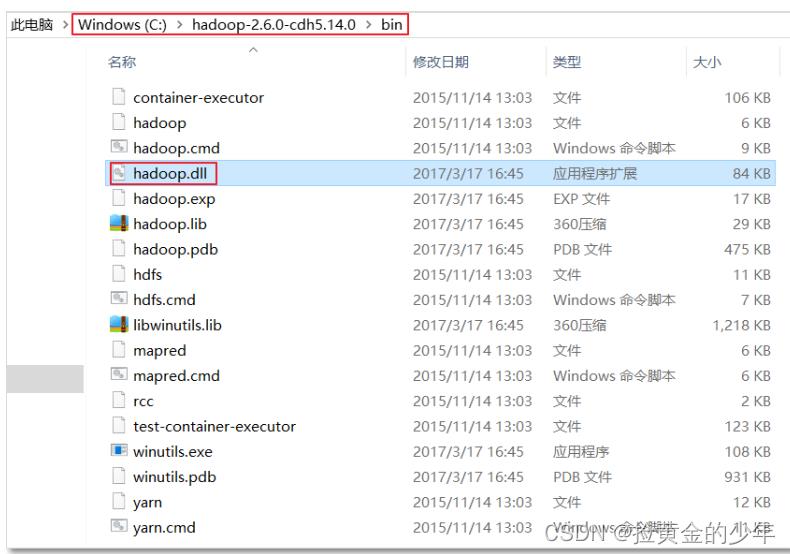
查看是否配置成功
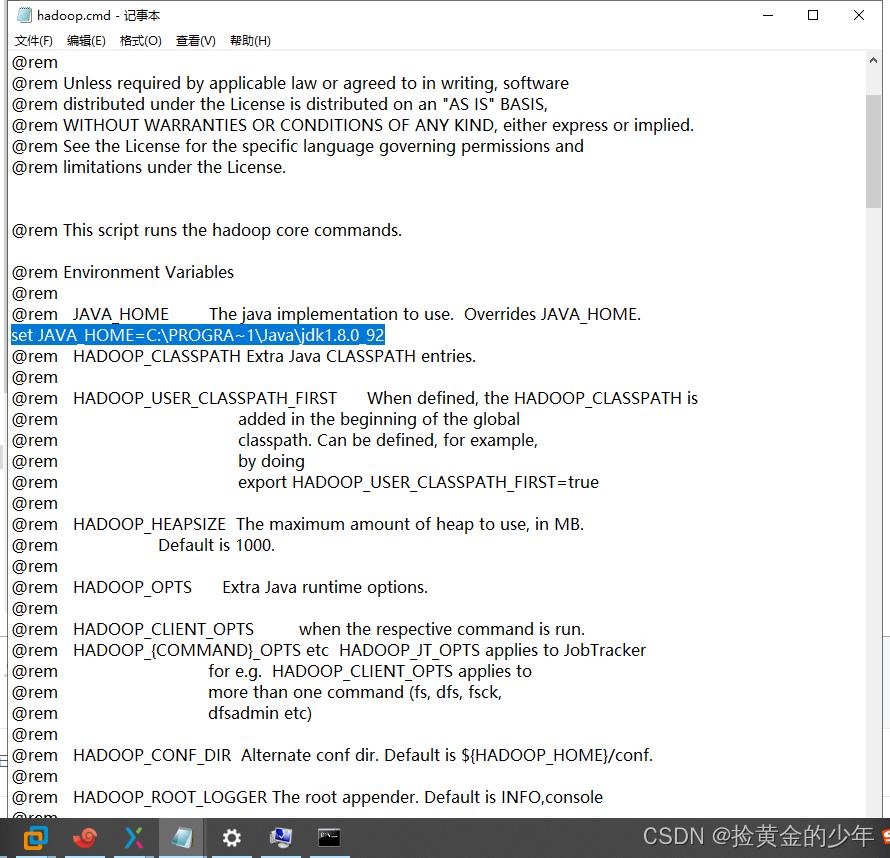
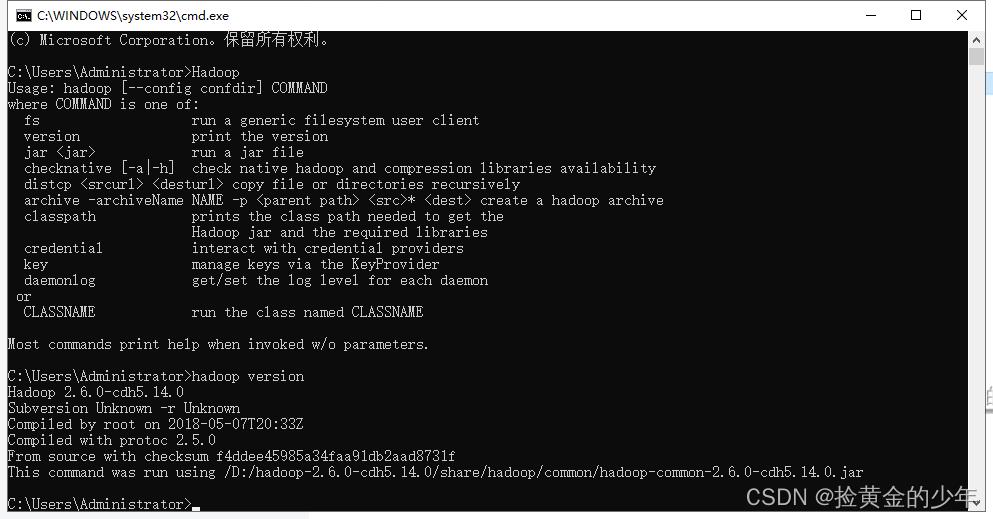 如果命令不能成功,可能你电脑的java的jdk安装到了C盘的Program Files目录下,Hadoop识别出现错误,则需指定目录
如果命令不能成功,可能你电脑的java的jdk安装到了C盘的Program Files目录下,Hadoop识别出现错误,则需指定目录
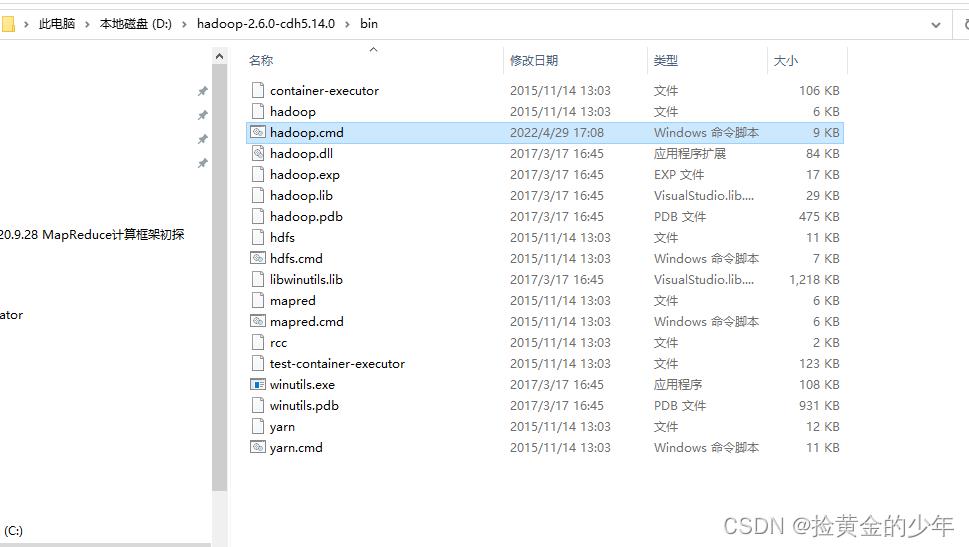
set JAVA_HOME=C:\\PROGRA~1\\Java\\jdk1.8.0_92
 2、修改host文件
2、修改host文件
host存放位置
C:\\Windows\\System32\\drivers\\etc
192.168.52.100 node01 node01.kaikeba.com
192.168.52.101 node02 node02.kaikeba.com
192.168.52.102 node03 node03.kaikeba.com

2、创建maven项目并引入jar包
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>1、创建文件夹
@Test
public void mkdirToHdfs() throws IOException
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.get(configuration);
fileSystem.mkdirs(new Path("/kaikeba/dir1"));//若目录已经存在,则创建失败,返回false
fileSystem.close();
2、创建权限文件夹
@Test
public void mkdir() throws IOException
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.get(configuration);
FsPermission fsPermission = new FsPermission(FsAction.ALL, FsAction.READ_WRITE, FsAction.NONE);
boolean mkdirs = fileSystem.mkdirs(new Path("/kaikeba/dir2"), fsPermission);
if (mkdirs)
System.out.println("目录创建成功");
//释放资源
fileSystem.close();
3、文件上传到指定目录
/**
* 文件上传
*
* @throws IOException
*/
@Test
public void uploadFile() throws IOException
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.get(configuration);
fileSystem.copyFromLocalFile(new Path("file:///d:\\\\1.png"), new Path("hdfs://node01:8020/kaikeba/dir1"));//hdfs路径也可以直接写成/kaikeba/dir1
fileSystem.close();
4、文件下载到指定目录
/**
* 文件下载
*/
@Test
public void downloadFile() throws IOException
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://node01:8020");
FileSystem fileSystem = FileSystem.get(configuration);
fileSystem.copyToLocalFile(new Path("hdfs://node01:8020/kaikeba/dir1/1.png"),new Path("file:///d:\\\\hello2.png"));//hdfs路径也可以直接写成/kaikeba/dir1
fileSystem.close();
5、循环遍历文件列表
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException
// 1获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://node01:8020"), configuration);
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext())
LocatedFileStatus status = listFiles.next();
// 输出详情
// 文件名称
System.out.println("文件名称:"+status.getPath().getName());
// 长度
System.out.println("文件长度:"+status.getLen());
// 权限
System.out.println("文件权限:"+status.getPermission());
// 分组
System.out.println("文件组:"+status.getGroup());
// 获取存储的块信息
BlockLocation[] blockLocations = status.getBlockLocations();
for (BlockLocation blockLocation : blockLocations)
// 获取块存储的主机节点
String[] hosts = blockLocation.getHosts();
for (String host : hosts)
System.out.println(host);
// 3 关闭资源
fs.close();
IO流操作hdfs文件
通过io流进行数据上传操作
@Test
public void putFileToHDFS() throws IOException, InterruptedException, URISyntaxException
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://node01:8020"), configuration);
// 2 创建输入流;路径前不需要加file:///,否则报错
FileInputStream fis = new FileInputStream(new File("e:\\\\hello.txt"));
// 3 获取输出流
FSDataOutputStream fos = fs.create(new Path("hdfs://node01:8020/outresult.txt"));
// 4 流对拷 org.apache.commons.io.IOUtils
IOUtils.copy(fis, fos);
// 5 关闭资源
IOUtils.closeQuietly(fos);
IOUtils.closeQuietly(fis);
fs.close();

以上是关于hdfs学习的主要内容,如果未能解决你的问题,请参考以下文章