深度学习中的优化算法之带Momentum的SGD
Posted fengbingchun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习中的优化算法之带Momentum的SGD相关的知识,希望对你有一定的参考价值。
之前在https://blog.csdn.net/fengbingchun/article/details/123955067介绍过SGD(Mini-Batch Gradient Descent(MBGD),有时提到SGD的时候,其实指的是MBGD)。这里介绍下带动量(Momentum)的SGD。
SGD(Stochastic Gradient Descent)难以导航沟壑(SGD has trouble navigating ravines),即SGD在遇到沟壑时容易陷入震荡。
Momentum是一种有助于在相关方向上加速SGD收敛(加速学习)并抑制振荡的方法。Momentum具有抑制梯度变化的效果,进而抑制搜索空间中每个新点的步长。如下图所示,截图来自:https://arxiv.org/pdf/1609.04747.pdf

Momentum是梯度下降优化算法的扩展,通常称为带动量的梯度下降。它旨在加速优化过程,例如减少达到最优值所需的函数评估次数,或提高优化算法的能力,例如从而获得更好的最终结果(It is designed to accelerate the optimization process, e.g. decrease the number of function evaluations required to reach the optima, or to improve the capability of the optimization algorithm, e.g. result in a better final result)。
Momentum涉及添加一个额外的超参数mu,该参数控制梯度下降更新方程中的历史量(动量)。超参数mu的值定义在0.0到1.0的范围内,并且通常具有接近1.0的值,例如0.8、0.9或0.99。0.0的动量与没有动量的梯度下降相同。较大的mu(如0.9)将意味着更新受到先前更新的影响较大,而较小的mu(如0.2)将意味着影响较小。
Momentum在目标函数具有大曲率(例如变化很大)的优化问题中最有用,这意味着梯度可能在搜索空间的相对较小区域内发生很大变化(Momentum is most useful in optimization problems where the objective function has a large amount of curvature (e.g. changes a lot), meaning that the gradient may change a lot over relatively small regions of the search space)。当搜索空间平坦或接近平坦时,动量很有帮助,例如零梯度。动量允许搜索与平坦点之前相同的方法进行,并有助于穿过平坦区域。
加入动量的SGD,其参数更新方向不仅由当前的梯度决定,也与此前累积的梯度下降方向有关。若当前的梯度方向与累积的历史梯度方向一致,则当前的梯度会被加强,从而这一步下降的幅度更大。若当前的梯度方向与累积的梯度方向不一致,则会减弱当前下降的梯度幅度。由此产生了加速收敛和减少震荡的效果。
以上内容主要参考:
1. https://machinelearningmastery.com/gradient-descent-with-momentum-from-scratch/
以下是与SGD不同的代码片段:
1. 在原有枚举类Optimization的基础上新增SGD_Momentum:
enum class Optimization
BGD, // Batch Gradient Descent
SGD, // Stochastic Gradient Descent
MBGD, // Mini-batch Gradient Descent
SGD_Momentum // SGD with momentum
;2. 在原有LogisticRegression2类的基础上新增set_mu,用于设置动量项超参数mu:
void set_mu(float mu) mu_ = mu; 3. 为了每次运行与SGD产生的随机初始化权值相同,这里使用std::default_random_engine:
template<typename T>
void generator_real_random_number(T* data, int length, T a, T b, bool default_random)
// 每次产生固定的不同的值
std::default_random_engine generator;
std::uniform_real_distribution<T> distribution(a, b);
for (int i = 0; i < length; ++i)
data[i] = distribution(generator);
4. 为了对数据集每次执行shuffle时,结果一致,这里有std::random_shuffle调整为std::shuffle:
//std::srand(unsigned(std::time(0)));
//std::random_shuffle(random_shuffle_.begin(), random_shuffle_.end(), generate_random); // 每次执行后random_shuffle_结果不同
std::default_random_engine generator;
std::shuffle(random_shuffle_.begin(), random_shuffle_.end(), generator); // 每次执行后random_shuffle_结果相同5. calculate_gradient_descent函数:
void LogisticRegression2::calculate_gradient_descent(int start, int end)
switch (optim_)
case Optimization::SGD_Momentum:
int len = end - start;
std::vector<float> change(feature_length_, 0.);
std::vector<float> z(len, 0), dz(len, 0);
for (int i = start, x = 0; i < end; ++i, ++x)
z[x] = calculate_z(data_->samples[random_shuffle_[i]]);
dz[x] = calculate_loss_function_derivative(calculate_activation_function(z[x]), data_->labels[random_shuffle_[i]]);
for (int j = 0; j < feature_length_; ++j)
float new_change = mu_ * change[j] - alpha_ * (data_->samples[random_shuffle_[i]][j] * dz[x]);
w_[j] += new_change;
change[j] = new_change;
b_ -= (alpha_ * dz[x]);
break;
case Optimization::SGD:
case Optimization::MBGD:
int len = end - start;
std::vector<float> z(len, 0), dz(len, 0);
for (int i = start, x = 0; i < end; ++i, ++x)
z[x] = calculate_z(data_->samples[random_shuffle_[i]]);
dz[x] = calculate_loss_function_derivative(calculate_activation_function(z[x]), data_->labels[random_shuffle_[i]]);
for (int j = 0; j < feature_length_; ++j)
w_[j] = w_[j] - alpha_ * (data_->samples[random_shuffle_[i]][j] * dz[x]);
b_ -= (alpha_ * dz[x]);
break;
case Optimization::BGD:
default: // BGD
std::vector<float> z(m_, 0), dz(m_, 0);
float db = 0.;
std::vector<float> dw(feature_length_, 0.);
for (int i = 0; i < m_; ++i)
z[i] = calculate_z(data_->samples[i]);
o_[i] = calculate_activation_function(z[i]);
dz[i] = calculate_loss_function_derivative(o_[i], data_->labels[i]);
for (int j = 0; j < feature_length_; ++j)
dw[j] += data_->samples[i][j] * dz[i]; // dw(i)+=x(i)(j)*dz(i)
db += dz[i]; // db+=dz(i)
for (int j = 0; j < feature_length_; ++j)
dw[j] /= m_;
w_[j] -= alpha_ * dw[j];
b_ -= alpha_*(db/m_);
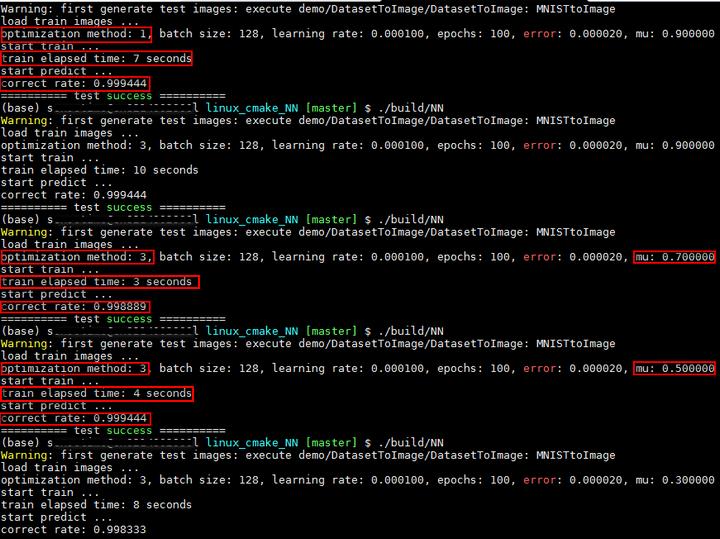
执行结果如下所示:测试函数为test_logistic_regression2_gradient_descent,多次执行每种配置,最终结果都相同。SGD耗时7秒,识别率为99.94%;mu值不同,带动量的SGD的耗时和识别率也不同,当mu为0.7时,耗时最少为3秒,识别率为99.89%,识别率比SGD略低;当mu为0.5时,耗时4秒,识别率与SGD相同。
GitHub:https://github.com/fengbingchun/NN_Test
以上是关于深度学习中的优化算法之带Momentum的SGD的主要内容,如果未能解决你的问题,请参考以下文章