人工智能系列 之机器学习DBSCAN聚类算法
Posted 琅晓琳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能系列 之机器学习DBSCAN聚类算法相关的知识,希望对你有一定的参考价值。
1 介绍
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个出现得比较早(1996年),比较有代表性的基于密度的聚类算法。DBSCAN能够将足够高密度的区域划分成簇,并能在具有噪声的空间数据库中发现任意形状的簇。聚类的时候不需要预先指定簇的个数,最终簇的个数不确定。
DBScan需要二个参数: 扫描半径 (Eps)和最小包含点数(MinPts)。
DBSCAN算法将数据点分为三类:
(1)、核心点:在半径Eps内含有超过MinPts数目的点;
(2)、边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内的点;
(3)、噪音点:既不是核心点也不是边界点的点。
2 DBSCAN密度聚类思想
由密度可达关系导出的最大密度相连的样本集合,即为我们最终聚类的一个类别,或者说一个簇。
这个DBSCAN的簇里面可以有一个或者多个核心对象。如果只有一个核心对象,则簇里其他的非核心对象样本都在这个核心对象的ϵ-邻域里;如果有多个核心对象,则簇里的任意一个核心对象的ϵ-邻域中一定有一个其他的核心对象,否则这两个核心对象无法密度可达。这些核心对象的ϵ-邻域里所有的样本的集合组成的一个DBSCAN聚类簇。
DBSCAN使用的方法很简单,它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇。一直运行到所有核心对象都有类别为止。
3 DBSCAN优缺点总结
优点:
相比K-Means,DBSCAN不需要预先声明聚类数量;
K-means使用簇的基于原型的概念,而DBSCAN使用基于密度的概念;
K-means只能用于具有明确定义的质心(如均值)的数据。DBSCAN要求密度定义(基于传统的欧几里得密度概念)对于数据是有意义的;
K-means需要指定簇的个数作为参数,DBSCAN不需要事先知道要形成的簇类的数量,DBSCAN自动确定簇个数;
与K-means方法相比,DBSCAN可以发现任意形状的簇类。DBSCAN可以处理不同大小和不同形状的簇,K-means很难处理非球形的簇和不同形状的簇;
K-means可以用于稀疏的高纬数据,如文档数据。DBSCAN则不能很好反映高维数据;
K-means可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇。
可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集;
通俗的讲,就是数据集D中任意两点的连线上的点,也在数据集D内,那么数据集D就是一个凸集。
如下图,左边非凸,右边为凸
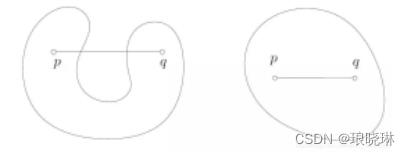
可以在聚类的同时发现异常点,对数据集中的异常点不敏感;
聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
缺点:
当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差,因为这种情况下参数MinPts和Eps选取困难;
如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进;
调参相对于传统的K-Means之类的聚类算法稍复杂,主要需对距离阈值eps,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
4 Java实现(已知经纬度利用聚类算法聚类)
参考算法链接:
https://blog.csdn.net/qq_38567039/article/details/118671550
https://www.cnblogs.com/zlazm/p/9273067.html
5 Python实现(SkLearn中DBSCAN实现经纬度聚类)
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from math import pi, cos, sin, atan2, sqrt
def get_centroid(cluster):
x = y = z = 0
coord_num = len(cluster)
for coord in cluster:
lat = coord[0] * pi / 180
lon = coord[1] * pi / 180
a = cos(lat) * cos(lon)
b = cos(lat) * sin(lon)
c = sin(lat)
x += a
y += b
z += c
x /= coord_num
y /= coord_num
z /= coord_num
lon = atan2(y, x)
hyp = sqrt(x * x + y * y)
lat = atan2(z, hyp)
return [lat * 180 / pi, lon * 180 / pi]
df = pd.read_excel("经纬度.xlsx")
hotel_df = df[['latitude', 'longitude']]
hotel_df = hotel_df.dropna(axis=0, how='any')
hotel_coord = hotel_df.values
R = 6370996.8 # 地球半径
hotel_cluster = DBSCAN(eps=2500 / R, min_samples=int(len(hotel_df) / 70), algorithm='ball_tree',
metric='haversine').fit(np.radians(hotel_coord))
hotel_df['labels'] = hotel_cluster.labels_
cluster_list = hotel_df['labels'].value_counts(dropna=False)
center_coords = []
for index, item_count in cluster_list.iteritems():
if index != -1:
df_cluster = hotel_df[hotel_df['labels'] == index]
center_coord = get_centroid(df_cluster[["latitude", "longitude"]].values)
center_lat = center_coord[0]
center_lon = center_coord[1]
center_coords.append(center_coord)
center_coords = pd.DataFrame(center_coords, columns=['latitude', 'longitude'])
# 可视化
fig, ax = plt.subplots(figsize=[12, 12])
facility_scatter = ax.scatter(hotel_df['longitude'], hotel_df['latitude'], c=hotel_df['labels'], cmap=cm.Dark2,
edgecolor='None',
alpha=0.7, s=120)
centroid_scatter = ax.scatter(center_coords['longitude'], center_coords['latitude'], marker='x', linewidths=2,
c='k', s=50)
ax.set_title('Facility Clusters & Facility Centroid', fontsize=30)
ax.set_xlabel('Longitude', fontsize=24)
ax.set_ylabel('Latitude', fontsize=24)
ax.set_xlim(120.2, 121.4)
ax.set_ylim(30.5, 32.5)
ax.legend([facility_scatter, centroid_scatter], ['Facilities', 'Facility Cluster Centroid'], loc='upper right',
fontsize=20)
plt.show()
参考资料:
https://blog.csdn.net/m0_46297891/article/details/107579135 DBSCAN聚类算法
https://zhuanlan.zhihu.com/p/23504573 聚类算法第三篇-密度聚类算法DBSCAN
https://www.biaodianfu.com/dbscan.html 机器学习聚类算法之DBSCAN
https://www.cnblogs.com/pinard/p/6208966.html DBSCAN密度聚类算法
https://www.cnblogs.com/8335IT/p/5635965.html 邗影
Java实现聚类算法k-means
https://www.cnblogs.com/Allen-win/p/8298181.html java实现K-means聚类算法
https://www.cnblogs.com/xjx199403/p/11046067.html?ivk_sa=1024320u java 实现DBScan聚类算法
https://blog.csdn.net/u012848304/article/details/108710864 Python实现经纬度空间点DBSCAN聚类
以上是关于人工智能系列 之机器学习DBSCAN聚类算法的主要内容,如果未能解决你的问题,请参考以下文章