Hadoop从入门到入土(第三天)
Posted 南城守护
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop从入门到入土(第三天)相关的知识,希望对你有一定的参考价值。
(今天学习的时候把hadoop的环境变量配置错了,然后所有命令就运行不了,被迫重开)
目录
一、安装hadoop
打开Xshell7连接hadoop102>cd /opt/software>ll>tar -zxvf hadoop文件名 -C /opt/module/>cd ..>cd madule>cd hadoop-3.1.3(自己hadoop的文件名)\\ll>pwd(复制下面的连接)>sudo vim /etc/profile.d/my_env.sh>在里面添加:#HADOOP_HOME 回车 export HADOOP_HOME=粘贴刚刚复制的内容 回车 export PATH=$PATH:$HADOOP_HOME/bin 回车 export PATH=$PATH:$HADOOP_HOME/sbin 输入完成后保存>source /etc/profile(有时候可以省略这一步)>hadoop(显示就成功);配置好后用ll查看里面有那些内容。
(注:修改系统文件:要么登陆管理员账户要么用sudo。)
二、本地运行模式
本地:数据存储在linux本地(测试时用)
伪分布式:数据存储在HDFS多台服务器工作(公司比较差钱用这个)
完全分布式:数据存储在HDFS/多台服务器工作(企业大量使用)
本地配置:在cd hadoop-3.1.3文件中>mkdir wccinput >ll>cd wcinput/>ll>vim word.txt(在里面写ss ss 换行 cls cls 换行 banzhang 换行 bobo 换行 yangge)>cd ..>ll>pwd>cd bin/>ll>cd ..>ll(如果对路径不熟悉的话)>bin/hadoop jar share/(按tab键)>hadoop/(tab键)>mapreduce/(按tab建两次)>h(tab)>e(tab)>wordcount(后续所有的mapreduce程序都必须指定输入路径和输出路径,并且输出路径不能存在)空格加两次tab>wcinput/ ./wcoutput(这个可以自己取名,文件夹不能存在) >回车执行>ll >cd wcoutput>ll>cat 文件名(查看数据);成功案例:
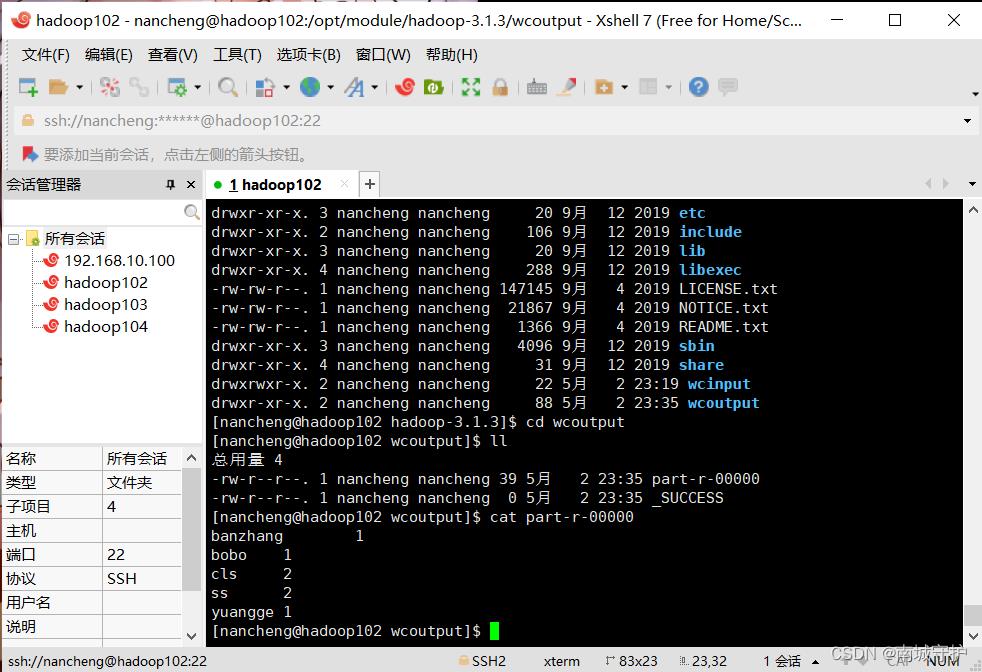
今日份学习笔记:

以上是关于Hadoop从入门到入土(第三天)的主要内容,如果未能解决你的问题,请参考以下文章