Spark机器学习实战-使用Spark进行数据处理和数据转换
Posted 纯洁の小黄瓜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark机器学习实战-使用Spark进行数据处理和数据转换相关的知识,希望对你有一定的参考价值。
系列文章目录
文章目录
前言
本文主要根据可以公开访问的数据来讲解利用Spark进行数据处理、转换以及转换成机器学习算法所接受的格式所涉及的基本步骤。
一、获取公开数据集
商业敏感数据往往是难以获取的,但是我们可以访问到一些有用的公开数据。它们中的不少常用来作为特定机器学习问题的基准测试数据。常见的有如下几个。
- UCL机器学习知识库:包括近300个不同大小和类型的数据集,可用于分类、回归、聚类和推荐系统任务。数据集列表位于:https://archive.ics.uci.edu/ml/index.php
- Amazon AWS公开数据集:包含的通常是大型数据集,可通过Amazon S3访问。这些数据集包括最新的COVID19新冠肺炎数据集、癌症基因组图谱、Common Crawl网页语料库、维基百科数据和Google Books Ngrams。相关信息可参见:https://registry.opendata.aws/。
- Kaggle:这里集合了Kaggle举行的各种机器学习竞赛所用的数据集。它们覆盖分类、回归、排名、推荐系统以及图像分析领域,可从Competitions区域下载:https://www.kaggle.com/datasets
- KDnuggets:这里包含一个详细的公开数据集列表,其中一些上面提到过的。该列表位于:https://www.kdnuggets.com/datasets/index.html

二、数据探索及预处理
1.下载数据集:Housing Data
在此,我们将使用加州住房数据集。当然,请注意,这实际上是“小”数据,在这种情况下使用 Spark 可能有点杀鸡用牛刀了;我们选用这个数据集旨在让了解如何使用 PySpark 来实现在Spark上数据的获取、处理等操作。
2. 理解数据
加州住房数据集出现在 1997 年由 Pace、R. Kelley 和 Ronald Barry 撰写并发表在 Statistics and Probability Letters 杂志上的题为 Sparse Spatial Autoregressions 的论文中。研究人员使用 1990 年加州人口普查数据构建了这个数据集。
数据集中每一行是由人口普查街区构成。街区是美国人口普查局发布样本数据的最小地理单位(街区的人口通常为 600 到 3,000 人)。在这个样本中,一个街区平均包括 1425.5 个人。
这些数据包含20640个房价观测值,每个方价都对应9个经济变量:
Longitude:代表每个街区的经度
Latitude:代表每个街区的维度
Housing Median Age:每个街区里人的年龄中位数。请注意,中位数是位于观测值频率分布中点的值
Total Rooms:每个街区包含的房屋数量
Total Bedrooms:每个街区包含的卧室数量
Population:每个街区中的居民数
Households:每个街区中家庭个数
Median Income:每个街区中人的收入中位数
Median House Value:每个街区中的房价中位数
3.读入数据
注意::文章中只会对重点代码进行讲解,完整版的code请移步github:https://github.com/shawshany/SparkML
在将数据加载到 DataFrame 时指定数据的类型将提供比类型推断更好的性能。
HOUSING_DATA = './CaliforniaHousing/cal_housing.data'
# define the schema, corresponding to a line in the csv data file.
schema = StructType([
StructField("long", FloatType(), nullable=True),
StructField("lat", FloatType(), nullable=True),
StructField("medage", FloatType(), nullable=True),
StructField("totrooms", FloatType(), nullable=True),
StructField("totbdrms", FloatType(), nullable=True),
StructField("pop", FloatType(), nullable=True),
StructField("houshlds", FloatType(), nullable=True),
StructField("medinc", FloatType(), nullable=True),
StructField("medhv", FloatType(), nullable=True)]
)
读取数据 dataframe
housing_df = spark.read.csv(path=HOUSING_DATA, schema=schema).cache()
显示spark dataframe前五行
# Show first five rows
housing_df.show(5)
显示spark dataframe的列名
# show the dataframe columns
housing_df.columns
显示dataframe数据结构信息
# show the schema of the dataframe
housing_df.printSchema()
4.探索数据
通过spark选取指定列,并展示前10行数据
# run a sample selection
housing_df.select('pop','totbdrms').show(10)
接下来看下居住在该街区人的中位数年龄分布情况
# group by housingmedianage and see the distribution
result_df = housing_df.groupBy("medage").count().sort("medage", ascending=False)
result_df.toPandas().plot.bar(x='medage',figsize=(14, 6))
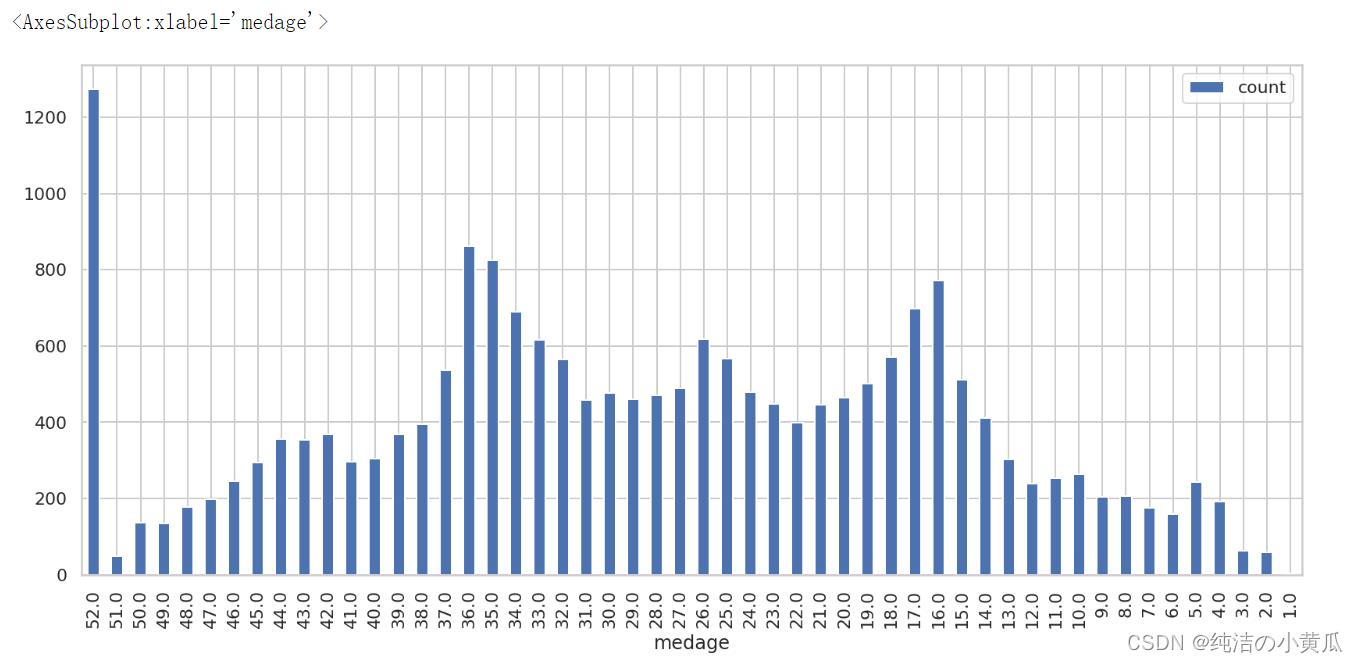
从上图中我们发现大多数居民要么在年轻时,要么在晚年定居在这里。
Spark DataFrames 包含一些用于统计处理的内置函数。 describe() 函数对所有数值列执行汇总统计计算,并将它们作为 DataFrame 返回。
(housing_df.describe().select(
"summary",
F.round("medage", 4).alias("medage"),
F.round("totrooms", 4).alias("totrooms"),
F.round("totbdrms", 4).alias("totbdrms"),
F.round("pop", 4).alias("pop"),
F.round("houshlds", 4).alias("houshlds"),
F.round("medinc", 4).alias("medinc"),
F.round("medhv", 4).alias("medhv"))
.show())
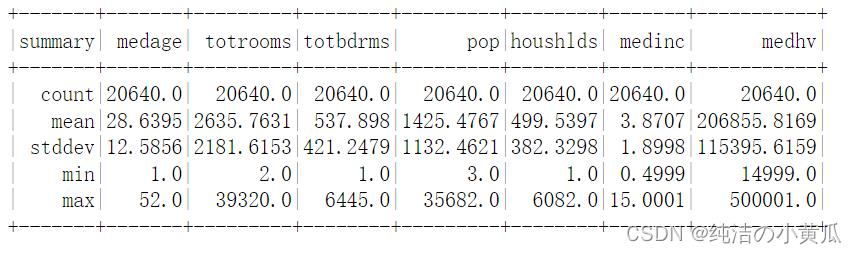
从上面的统计结果中,我们可以看到所有数据的最小值和最大值。这些数据范围很大,因此我们需要标准化这个数据集。
5.数据预处理
通过从小型探索性数据分析中,我们收集到如下信息:
- 上面步骤中,我们并没有对缺失值进行处理,这是因为在这个数据集中所有零值都已从数据集中排除。
- 我们可能应该标准化我们的数据,因为我们已经看到最小值和最大值的范围非常大。
- 我们可能还可以添加一些额外的属性,例如记录每个房间的卧室数量或每个家庭的房间数量的特征。
- 我们的目标变量也很大;为了让我们的处理更轻松,我们也需要稍微调整这些值。
在上面的信息中,我们提到缺失值的处理。一般来说,现实中的数据会存在信息不规整、数据点缺失和异常值的问题。理想情况下,我们会修复非规整数据,例如销量预测的缺货拟合。但是很多数据都源于一些难以重现的收集过程(比如网络活动数据和传感器数据),故实际上会难以修复。值缺失和异常也很常见,且处理方式可与处理非规整信息类似。总的来说,大致的处理方法如下。
- 过滤掉或删除非规整或有值缺失的数据:这种方法有的时候会损失这些数据中那些好的信息。
- 填充非规整或缺失的数据:这类方法主要包括用零值、均值或中值来填充,或者根据相邻或类似的数据点来做插值(通常针对时序数据)等。选择正确的填充方式并不容易,它往往因数据、应用场景和个人经验而不同。
- 对异常值做鲁棒处理:异常值首先最大的问题是甄别异常,因为即使是极值它也不一定是错误的。异常值可以被剔除或者替换,可以通过一些统计技术(如鲁棒回归)来处理异常值或极值。
- 对可能的异常值进行转换:对于那些可能存在异常或值域覆盖过大的特征,利用如对数或高斯核对其转换。这类转换有助于降低变量存在的值跳跃的影响,并将非线性关系变为线性的。
接下来我们在housing data数据集上,演示下如何进行数据的预处,首先,让我们从变量 medianHouseValue 开始。为了方便我们处理目标值,我们将以 100,000 为单位表示房屋价值。这意味着像 452600.000000 应该变成 4.526:
# Adjust the values of `medianHouseValue`
housing_df = housing_df.withColumn("medhv", col("medhv")/100000)
# Show the first 2 lines of `df`
housing_df.show(2)

如上图所示,这些数值已经被缩小了。接着,我们将新增一些特征到数据集中:
- rmsperhh:每户房间数,指每个街区的住户房间数
- popperhh:每户人口,这基本上可以告诉我们每个街区有多少人生活在家庭中
- bdrmsperrm:卧室占比,这将使我们了解每个街区有多少房间是卧室
# Add the new columns to `df`
housing_df = (housing_df.withColumn("rmsperhh", F.round(col("totrooms")/col("houshlds"), 2))
.withColumn("popperhh", F.round(col("pop")/col("houshlds"), 2))
.withColumn("bdrmsperrm", F.round(col("totbdrms")/col("totrooms"), 2)))
# Inspect the result
housing_df.show(5)
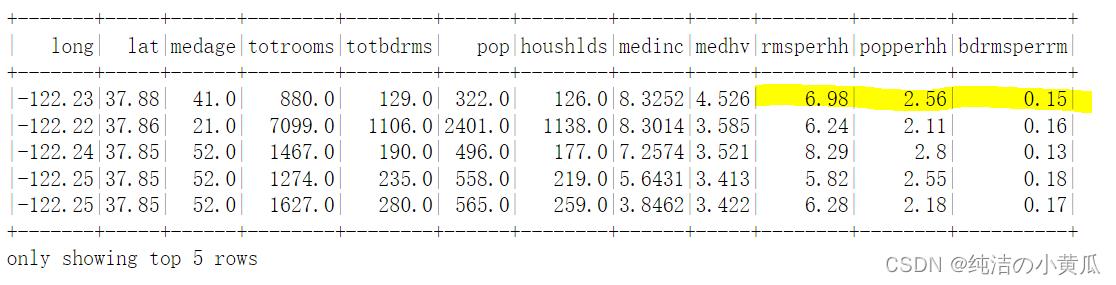
从上图第一行数据中,我们可以发现,每户人家大约有6.98个room,每个家庭大约有2.56口人,其中卧室占比很低只有0.15。
由于我们不一定要标准化我们的target,因此我们要确保在我们的特征中排除这些值,以免信息泄露。还要注意,对于某些变量往往是冗余信息,无需分析,因此在特征选择时我们丢弃了诸如 longitude、latitude、housingMedianAge 和 totalRooms 等变量。
我们将使用 select() 方法并以更合适的顺序梳理列名。在这种情况下,目标变量 medianHouseValue 放在第一位,这样就不会受到标准化的影响。
# Re-order and select columns
housing_df = housing_df.select("medhv",
"totbdrms",
"pop",
"houshlds",
"medinc",
"rmsperhh",
"popperhh",
"bdrmsperrm")
既然我们已经对数据进行了重新排序,我们就可以对数据进行规范化了。我们将选择要归一化的特征。
featureCols = ["totbdrms", "pop", "houshlds", "medinc", "rmsperhh", "popperhh", "bdrmsperrm"]
使用 VectorAssembler 将特征放入特征向量列:
# put features into a feature vector column
assembler = VectorAssembler(inputCols=featureCols, outputCol="features")
assembled_df = assembler.transform(housing_df)
assembled_df.show(10, truncate=False)
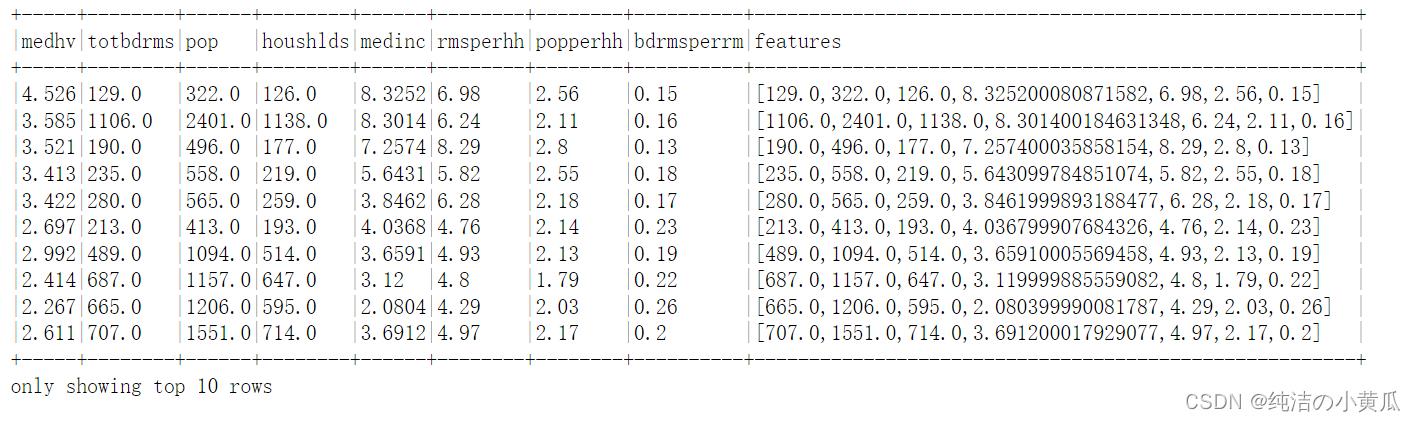
如上图所示,所有的特征都变成了一个密集向量features。
6.标准化
接下来,我们终于可以使用 StandardScaler 缩放数据了。输入列是特征,将输出列将命名为"features_scaled":
# Initialize the `standardScaler`
standardScaler = StandardScaler(inputCol="features", outputCol="features_scaled")
# Fit the DataFrame to the scaler
scaled_df = standardScaler.fit(assembled_df).transform(assembled_df)
# Inspect the result
scaled_df.select("features", "features_scaled").show(10, truncate=False)

在上面特征处理中,我们使用了标准化,那是因为我们用到的特征都是数值特征,但是在有些数据集中还会有类别类特征、文本特征、以及其他特征。
其中,类别特征,它们的取值只能是可能状态集合中的某一种。比如说用户性别、职业等便是这类。当类别特征处于原始形式的时候,其取值来自所有可能构成的集合而不是一个数字,故不能作为输入。因此我们需要把类别变量进过编码处理。
文本特征的处理方法有很多,最简单且标准的方法就是词袋法(bag-of-word)。该方法将一段文本视为由其中的文本或数字组成的集合,其处理过程一版分为:分词、删除停用词、提取词干、向量化等步骤。
关于类别类、文本类变量的处理方法细节,我们会在后面遇到具体问题时,详细讲解。
总结
本文首先介绍了几种常见公开数据集,然后以加州住房数据集为例,分别介绍了数据的下载、读取、探索分析、预处理、标准化等操作,最后简单总结了下不同类型的数据如何进行处理并转换成特征向量以供模型训练的方法。
以上是关于Spark机器学习实战-使用Spark进行数据处理和数据转换的主要内容,如果未能解决你的问题,请参考以下文章