加密流量分类任务的深度学习方法(一般框架总结)
Posted 迷人的派大星
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了加密流量分类任务的深度学习方法(一般框架总结)相关的知识,希望对你有一定的参考价值。
凭借出色的自动特征学习能力,深度学习(DL)成为加密流量分类任务中的一种非常理想的方法,下面介绍目前大多数相关工作中应对加密流量分类任务的一般化框架。总体结构图如下所示:
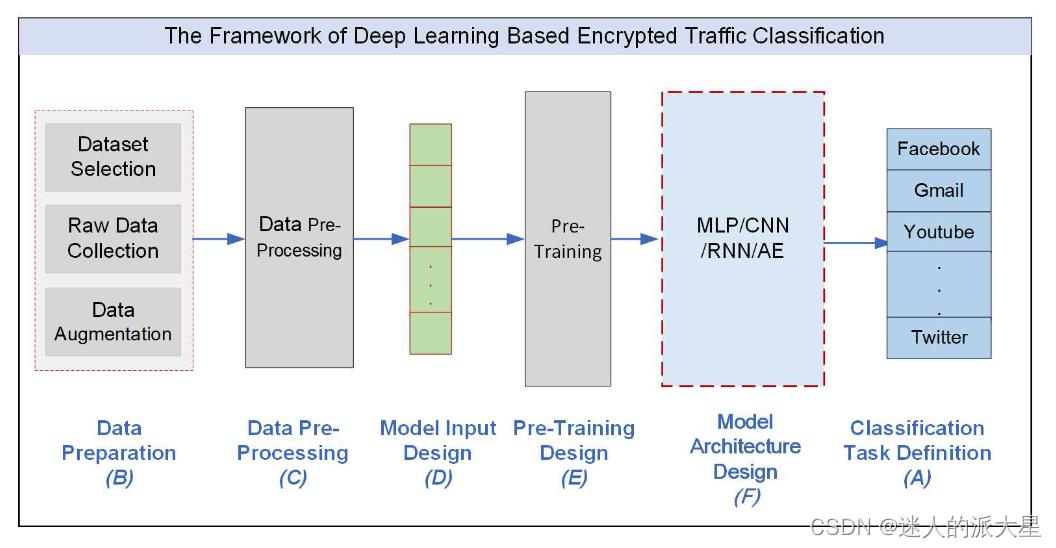
A 分类任务定义
显式定义分类任务是设计流量分类器之前的首要步骤。分类任务主要由目标、粒度和性能要求三部分组成。
A1 分类目标
一般而言,流量分类的目标总是包括网络管理、安全和个性化推荐三个部分。在网络管理相关场景中有网络资源调度、QoS 提供和基于内容的计费。入侵检测、恶意软件检测和僵尸网络检测是网络安全的典型场景。此外,网络服务提供商或内容提供商可以通过细粒度的流量分类,如互联网用户行为分析,根据订阅者的喜好推送自己的推荐。
A2 分类粒度
- 二进制分类(例如正常或异常,明文或加密,VPN或非VPN),主要用于入侵检测、恶意软件检测和僵尸网络检测。
- 协议(如TCP、UDP、HTTP或SMTP),主要用于网络资源调度、规划和分配。
- 服务组(例如流式传输、浏览或下载),同上。
- 应用程序(例如 Facebook、Youtube 或 Skype),同上。
- 主要用于基于互联网用户偏好分析进行推荐的网站(例如搜索引擎、电子购物或社交网络网站)。
- 应用程序中的用户特定行为(例如,将商品添加到 Amazon.com 的购物车、在 Twitter 上发布图片或在 Skype 中进行语音通话),与上述相同。
- 智能设备(例如 iPhone、iPad、TV Box),ISP 可以根据不同的智能设备提供特定的 QoS。
- 应用身份(如手机号码、Facebook账号名、推特用户名),主要用于安全审计和信息取证。
A3 分类性能要求
对于分类的性能要求,重要的是要考虑两个因素。
- 实时能力。从分类的实时性来看,分类器可以分为线上和线下两类。在线分类器总是用于实时场景,例如网络资源调度、入侵检测。相比之下,离线分类器通常用于用户行为分析,基于应用程序或内容的计费等。
- 轻量级能力。一些分类器在某些特定场景下应该是轻量级的,特别是在一些简单的硬件中,例如家庭网关或边缘路由器。显然,随着雾计算的飞速发展,轻量级分类器的出现越来越受到学术研究和网络运营的关注。
B 数据准备
训练深度学习模型以获取大型、平衡和有代表性的数据集至关重要。数据准备有三种方式,包括选择现有数据集、收集原始数据和生成合成样本。
B1 数据集选择
在下表中,总结了最近现有工作中使用的数据集。显然,大多数工作都选择了 ISCX2012 和 Moore 等公共数据集。此外,一些工作从 ISP 的网络或研究实验室收集原始数据,以创建自己的数据集,如 USTC-TFC2016 和 IMTD17。从样本数量来看,可以看到大部分工作选择了 70K-1500K 记录进行训练,其中大部分工作包括加密的流量样本。而大多数工作选择 5-17 个应用程序或协议作为他们的分类任务。此外,值得注意的是,现有工作中使用的一些数据集是不平衡的,这对分类任务的性能有一定的影响。
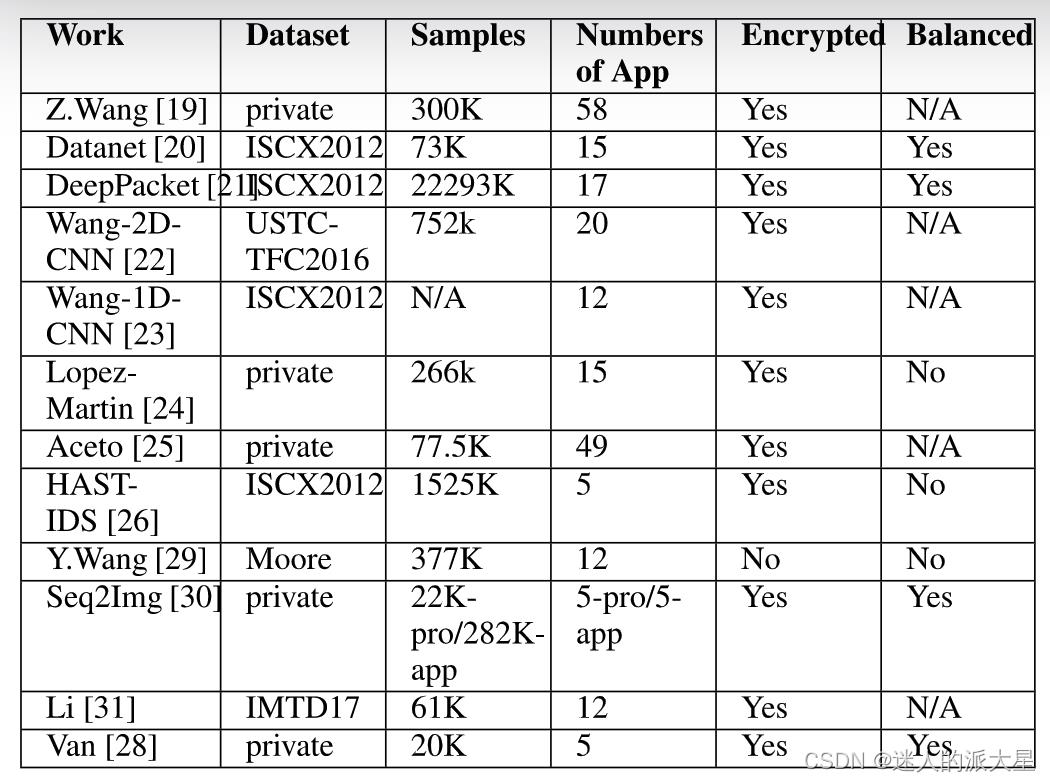
总之,由于以下原因,没有公开接受的数据集进行研究:
- 由于流量类型众多且应用程序更新频繁,没有数据集可以包含所有类型的应用程序流量。
- 覆盖宽带和无线接入、PC和移动设备接入等所有网络场景非常困难、耗时且成本高。
B2 原始数据收集
可以通过一些数据包捕获工具(如 Tcpdump)收集原始数据包,此外,一些工作使用流工具收集流量记录,如 NetFlow 。
B3 数据增强
在面对流量分类时,类不平衡是一个非常重要的问题。作为处理类平衡的一种有用方法,数据增强通常是指生成合成样本或者过采样、欠采样等以保持主要和次要类的样本平衡。
C 数据预处理
一般来说,数据集中的流量数据可以分为三种类型:原始数据包数据、PCAP 文件和统计特征。
前两类数据通常需要进行预处理,原因有三:
- 原始包数据中总是包含一些不相关的包,如ARP、DHCP、ICMP。
- 包级特征分布可能会因一些意想不到的网络条件而失真,例如重传包、乱序包等。
- PCAP 文件包含一些不必要的信息,如 PCAP 文件头。
因此,需要一些数据预处理措施,如数据包过滤、标头去除。在大多数原始数据包数据集的情况下,需要固定长度的零填充和截断,因为深度神经网络 (DNN) 总是提供固定大小的输入,而数据集的数据包的帧长度从 54 到 1514 变化很大(以 TCP 为例)。此外,数据归一化对于深度学习的性能至关重要,它总是将来自数据集的流量数据归一化为 [−1,+1] 或 [0,1] 范围内的值。这有助于分类任务在模型训练期间更快地收敛。
D 模型输入设计
作为一个重要的组成部分,深度学习模型的输入对模型在训练和测试过程中的性能有很大的影响。一般来说,基于深度学习的流量分类模型的输入可以分为三种类型:原始数据包数据、流量特征以及原始数据和特征的组合。
- 原始数据包数据。大多数工作选择原始数据包数据作为模型的输入。此时一般需要零填充和截断,补零和截断长度的范围通常在 700 到 1500字节之间。
- 流量特征。一般来说,流量特征可以分为三类:数据包级特征(如数据包长度和数据包到达间隔时间)、流级特征(如流持续时间、流中的总数据包)和统计特征(例如平均数据包长度和每秒发送或接收的平均字节数)。
- 结合原始数据和特征。
E 预训练设计
众所周知,深度学习在训练过程中需要大量的标记数据,但是,收集和标记大型数据集非常耗时且成本高昂。流量数据集无一例外,尤其是加密流量,因为目前的 DPI 等流量标注工具无法处理加密流量。相反,未标记的交通数据丰富且易于获得。因此,一些研究人员开始探索如何使用容易获得的未标记交通数据结合少量标记交通数据进行准确的交通分类。实际上,这是一种典型的半监督学习,通过它可以使用大量未标记的交通数据预训练模型 ,然后将其转移到新架构并使用重新训练模型。此外,预训练还可以用于降维,从而使模型变得轻量级,这在某些场景中非常重要。此外,大型数据集会消耗大量的计算和内存资源。
F 模型结构设计
模型架构是流量分类的最关键因素,目前深度学习常用模型有:
- MLP
- CNN
- RNN
- SAE
- VAE
- DAE
- GAN
参考文献
Wang P, Chen X, Ye F, et al. A survey of techniques for mobile service encrypted traffic classification using deep learning[J]. IEEE Access, 2019, 7: 54024-54033.
以上是关于加密流量分类任务的深度学习方法(一般框架总结)的主要内容,如果未能解决你的问题,请参考以下文章