Spark基础学习笔记24:Spark SQL数据源
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark基础学习笔记24:Spark SQL数据源相关的知识,希望对你有一定的参考价值。
文章目录
零、本讲学习目标
- 学会使用默认数据源
- 学会手动指定数据源
- 理解数据写入模式
- 掌握分区自动推断
Spark SQL支持通过DataFrame接口对各种数据源进行操作。DataFrame可以使用相关转换算子进行操作,也可以用于创建临时视图。将DataFrame注册为临时视图可以对其中的数据使用SQL查询。
一、基本操作
- Spark SQL提供了两个常用的加载数据和写入数据的方法:
load()方法和save()方法。load()方法可以加载外部数据源为一个DataFrame,save()方法可以将一个DataFrame写入指定的数据源。
(一)默认数据源
1、默认数据源Parquet
- 默认情况下,load()方法和save()方法只支持Parquet格式的文件,Parquet文件是以二进制方式存储数据的,因此不可以直接读取,文件中包括该文件的实际数据和Schema信息,也可以在配置文件中通过参数
spark.sql.sources.default对默认文件格式进行更改。Spark SQL可以很容易地读取Parquet文件并将其数据转为DataFrame数据集。
2、案例演示读取Parquet文件
- 将数据文件
users.parquet上传到master虚拟机/home
- 将数据文件
users.parquet上传到HDFS的/input目录

(1)在Spark Shell中演示
- 启动Spark Shell
- 加载parquet文件,返回数据帧
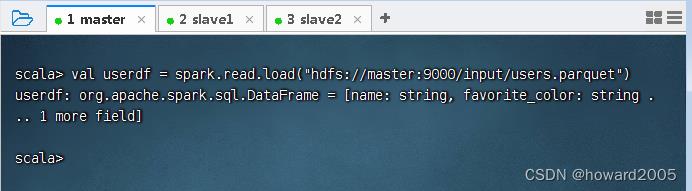
- 执行命令:
val userdf = spark.read.load("hdfs://master:9000/input/users.parquet")
- 执行命令:
userdf.show(),查看数据帧内容
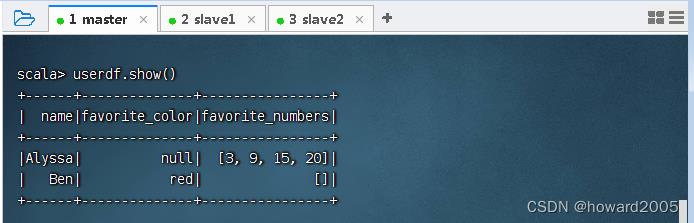
- 执行命令:
userdf.select("name", "favorite_color").write.save("hdfs://master:9000/result"),对数据帧指定列进行查询,查询结果依然是数据帧,然后通过save()方法写入HDFS指定目录
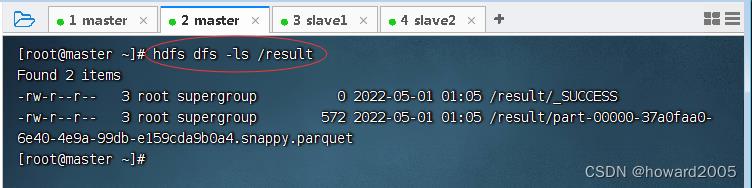
- 查看HDFS上的输出结果
- 除了使用select()方法查询外,也可以使用SparkSession对象的sql()方法执行SQL语句进行查询,该方法的返回结果仍然是一个DataFrame。
- 基于数据帧创建临时视图,执行命令:
userdf.createTempView("t_user")
- 执行SQL查询,将结果写入HDFS,执行命令:
spark.sql("select name, favorite_color from t_user").write.save("hdfs://master:9000/result2")
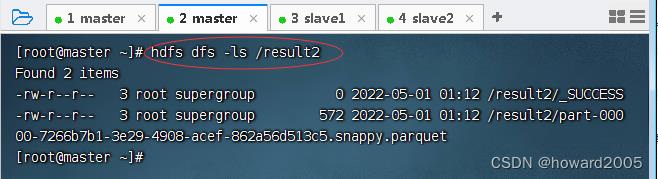
- 查看HDFS上的输出结果
(2)通过Scala程序演示
- 创建Maven项目 - SparkSQLDemo
- 在pom.xml文件里添加依赖与插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.hw.sparksql</groupId>
<artifactId>SparkSQLDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 创建
net.hw.sparksql包,在包里创建ReadParquet对象
package net.hw.sparksql
import org.apache.spark.sql.SparkSession
/**
* 功能:Parquet数据源
* 作者:华卫
* 日期:2022年05月01日
*/
object ReadParquet
def main(args: Array[String]): Unit =
// 本地调试必须设置,否则会报Permission Denied错误
System.setProperty("HADOOP_USER_NAME", "root")
// 创建或得到SparkSession
val spark = SparkSession.builder()
.appName("ReadParquet")
.master("local[*]")
.getOrCreate()
// 加载parquet文件,返回数据帧
val usersdf = spark.read.load("hdfs://master:9000/input/users.parquet")
// 显示数据帧内容
usersdf.show()
// 查询DataFrame中指定列,结果写入HDFS
usersdf.select("name","favorite_color")
.write.save("hdfs://master:9000/result3")
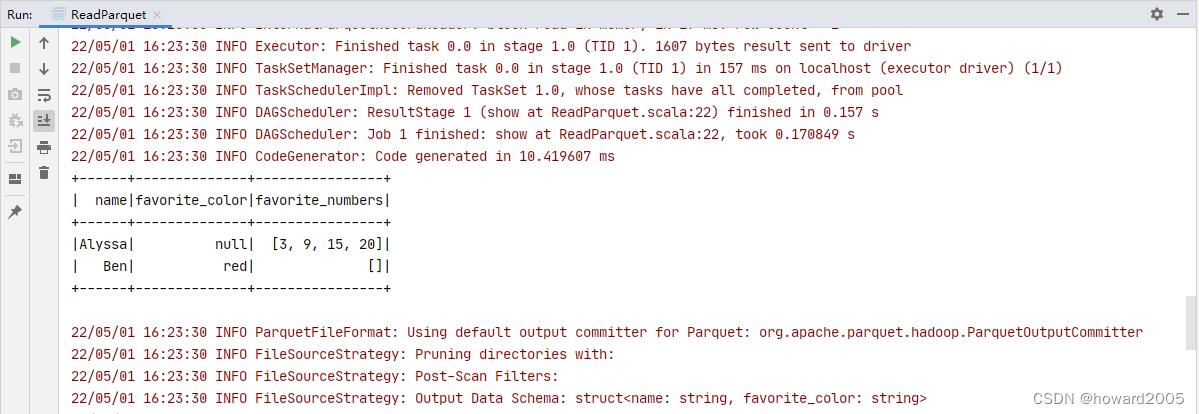
- 运行程序,查看控制台结果
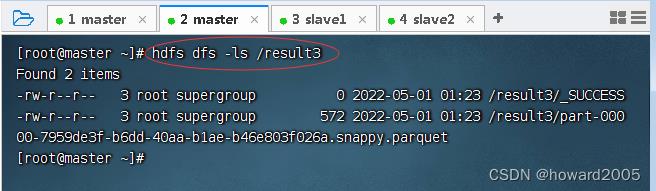
- 在HDFS查看输出结果
(二)手动指定数据源
1、format()与option()方法概述
- 使用
format()方法可以手动指定数据源。数据源需要使用完全限定名(例如org.apache.spark.sql.parquet),但对于Spark SQL的内置数据源,也可以使用它们的缩写名(JSON、Parquet、JDBC、ORC、Libsvm、CSV、Text)。 - 通过手动指定数据源,可以将DataFrame数据集保存为不同的文件格式或者在不同的文件格式之间转换。
- 在指定数据源的同时,可以使用option()方法向指定的数据源传递所需参数。例如,向JDBC数据源传递账号、密码等参数。
2、案例演示
(1)读取房源csv文件
- 查看HDFS上
/input目录里的house.csv文件
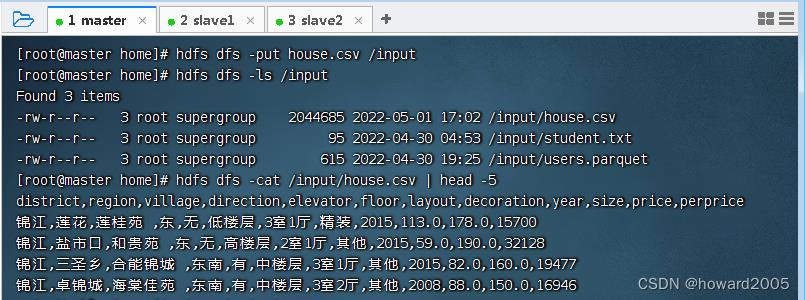
- 在spark shell里,执行命令:
val house_csv_df = spark.read.format("csv").load("hdfs://master:9000/input/house.csv"),读取房源csv文件,得到房源数据帧

- 执行命令:
house_csv_df.show(),查看房源数据帧内容
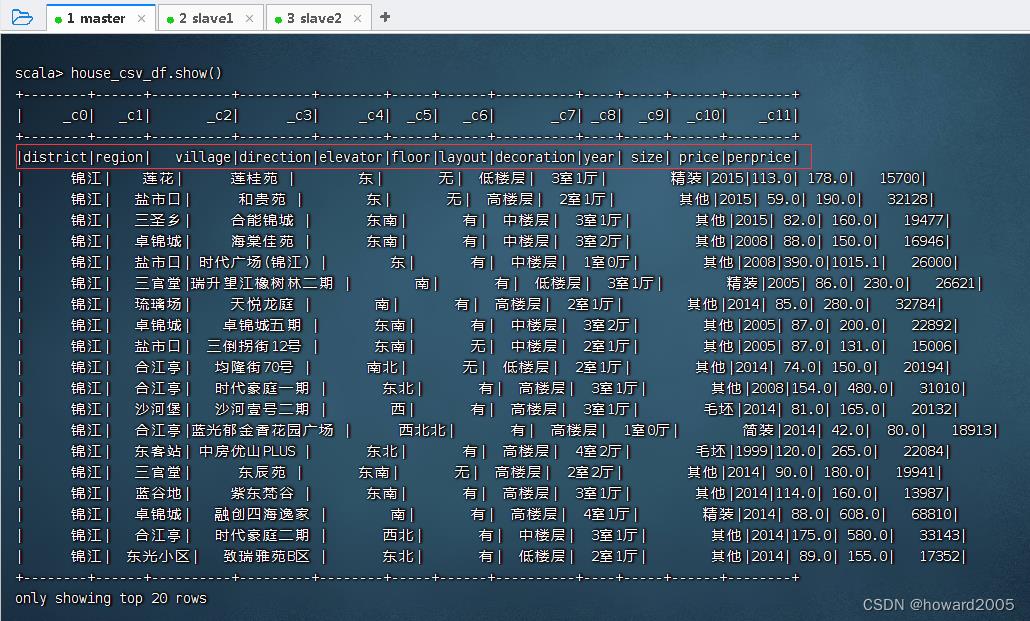
- 大家可以看到,
house.csv文件第一行是字段名列表,但是转成数据帧之后,却成了第一条记录,这样显然是不合理的,怎么办呢?就需要用到option()方法来传递参数,告诉Spark第一行是表头header,而不是表记录。 - 执行命令:
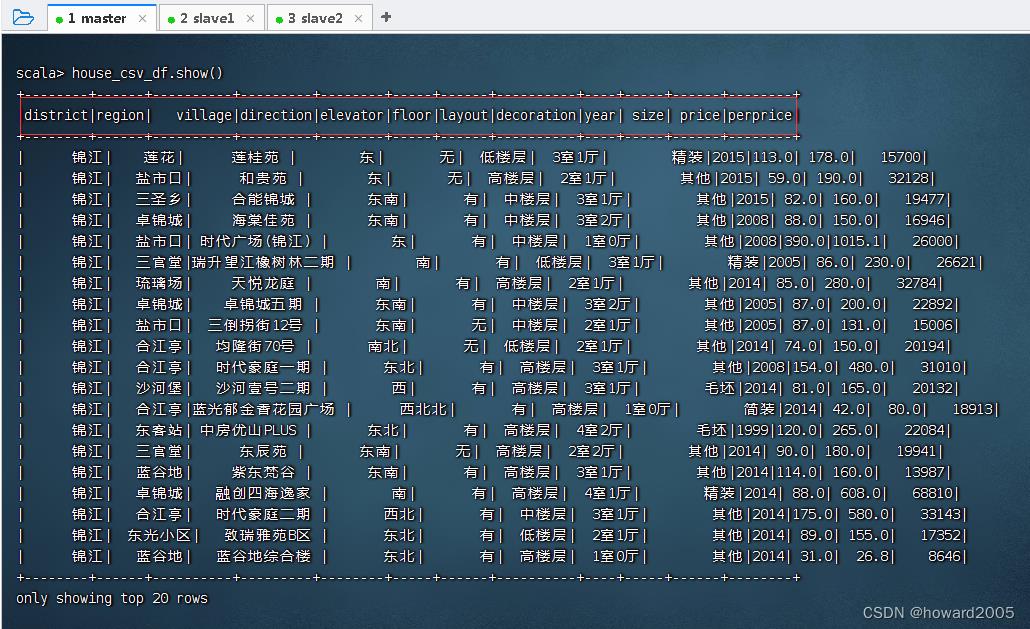
val house_csv_df = spark.read.format("csv").option("header", "true").load("hdfs://master:9000/input/house.csv")

- 执行命令:
house_csv_df.show(),查看房源数据帧内容
(2)格式转换 - 读取json,保存为parquet
以上是关于Spark基础学习笔记24:Spark SQL数据源的主要内容,如果未能解决你的问题,请参考以下文章
学习笔记Spark—— Spark SQL应用—— Spark DataFrame基础操作
Spark基础学习笔记28:Spark SQL数据源 - JDBC
Spark基础学习笔记25:Spark SQL数据源 - Parquet文件
学习笔记Spark—— Spark SQL应用—— Spark DataSet基础操作