多线程基础篇 - JavaEE初阶 - 细节狂魔
Posted Dark And Grey
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程基础篇 - JavaEE初阶 - 细节狂魔相关的知识,希望对你有一定的参考价值。
文章目录
- 前言
- 线程是什么?
- Java中执行多线程编程
- Thread 类创建线程的写法
- 多线程的优势
- Thread 类常见方法
- 线程等待
- 获取当前线程引用
- 线程休眠
- 线程的状态
- 线程安全问题 - 重中之重
- 重点解析 - synchronized 关键字 - 监视器锁 monitor lock
- Java标准库中的线程安全类
- volatile 关键字
- wait 和 notify :等待 和 通知
- 小结
- 关于多线程的案例
- 本文结束
前言
建议看一下上篇博客开头篇:计算机是如何工作的中 关于PCB【Process Control block - 进程控制块】 属性的那一部分。
线程是什么?
谈到线程,就不得不说一下进程【进程包含线程】。
思考一个问题:为什么要有进程?
这是因为我们的操作系统支持多任务。程序员也就需要“并发编程”。【这里并发是宏观的,包含了并发和并行】
通过多进程,是完全可以实现并发编程的。
但是存在问题:如果需要频繁的 创建 / 销毁 进程,这个事情成本是比较高的!同时如果频繁的调度进程,这个事情的成本也是比较高的!
一个线程就是一个 “执行流”. 每个线程之间都可以按照顺序执行自己的代码. 多个线程之间 “同时” 执行着多份代码.

Java中执行多线程编程
在 Java 标准库中,就提供了一个 Thread 类,来 表示 / 操作 线程。
Thread 类也可以视为是 Java 标准库提供的 API(API:Thread 类提供的方法 和 类)。
当我们创建好 Thread 实例 / 对象,其实和 操作系统中的线程是一一对应的关系。
换句话来说:
如果我们想要创建一个线程,就得先创建出一个 Thread 类 的 对象。
创建10个线程,就需要创建出 10 个 Thread 类的对象。
进一步来说:操作系统提供了一组关于线程的API【C语言风格】。
Java对于这组API 进一步封装了一下,就成了 Thread 类。
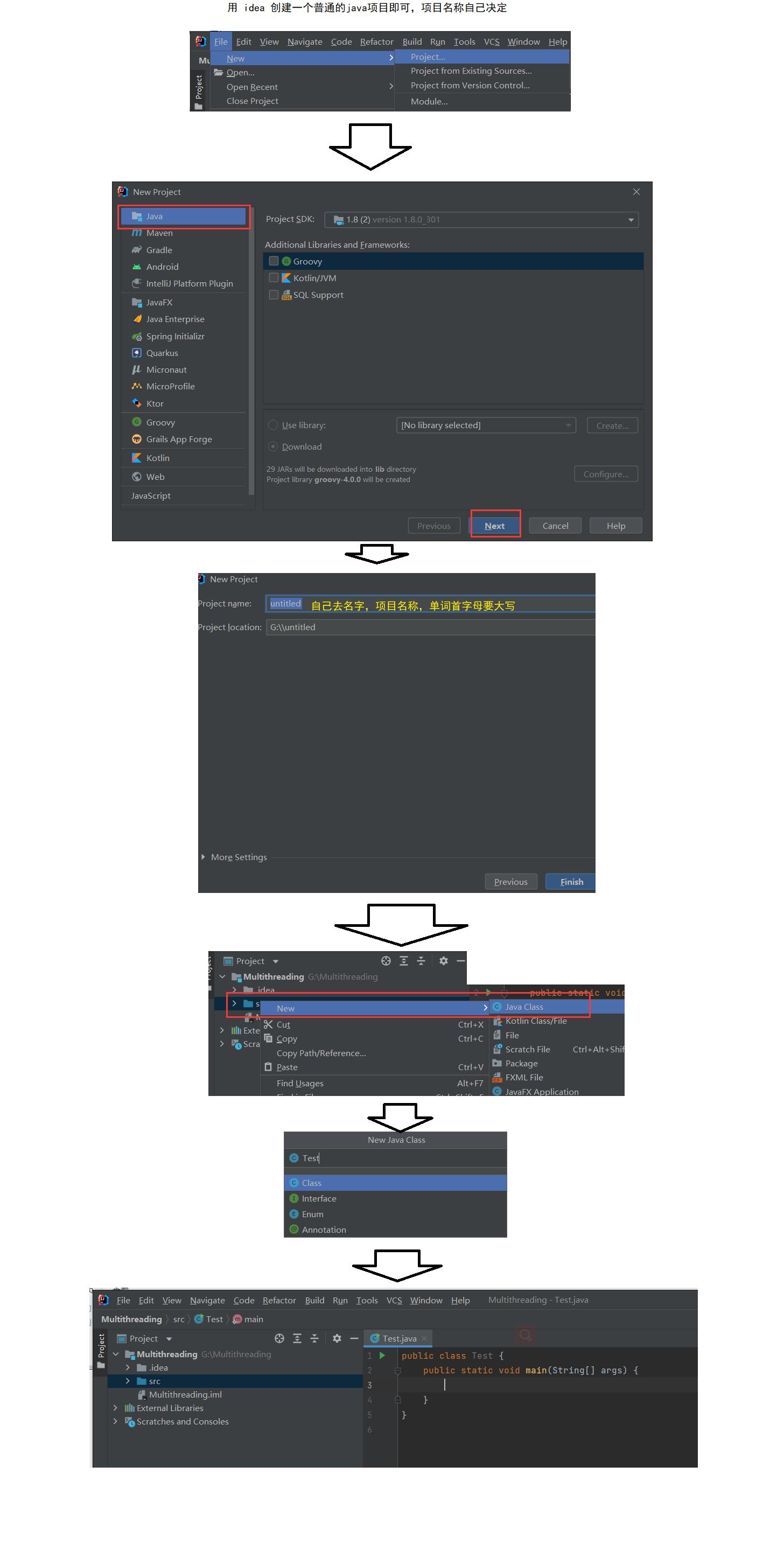
下面我们在 idea 中实践
准备工作 : 在 idea中 创建一个 Java 项目
Thread 类的基本方法
通过 Thread 类创建线程,写法 有很多中。
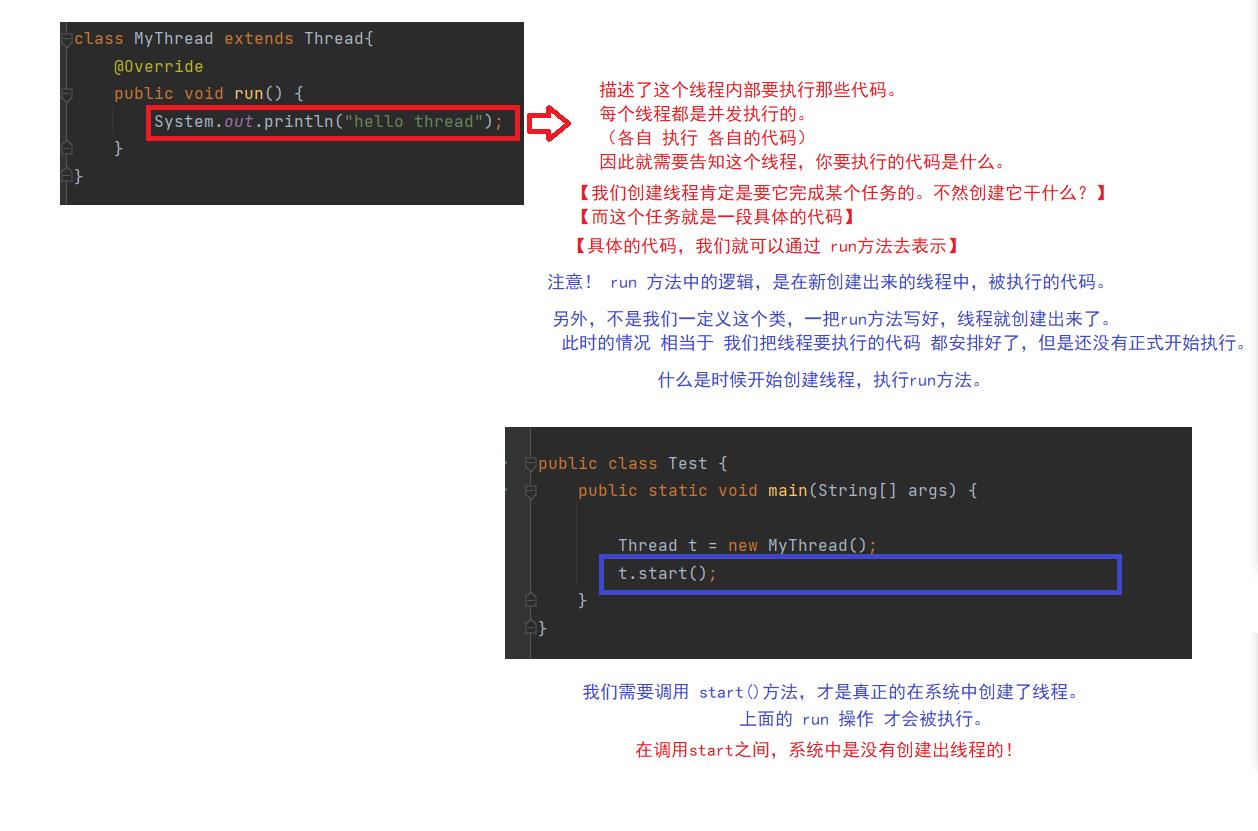
其中最简单的做法,创建子类,继承自 Thread,并且重写 run 方法。
另外,这里创建的线程,都是在同一个进程内部创建的。其实很好理解,假设进程是一个厂,线程是一条流水线。
我想新增一条流水线,不可能建在别人厂里,人家又不傻。
肯定是建在自己的厂里。
而且由于独立性,进程之间是不能相互干扰的。

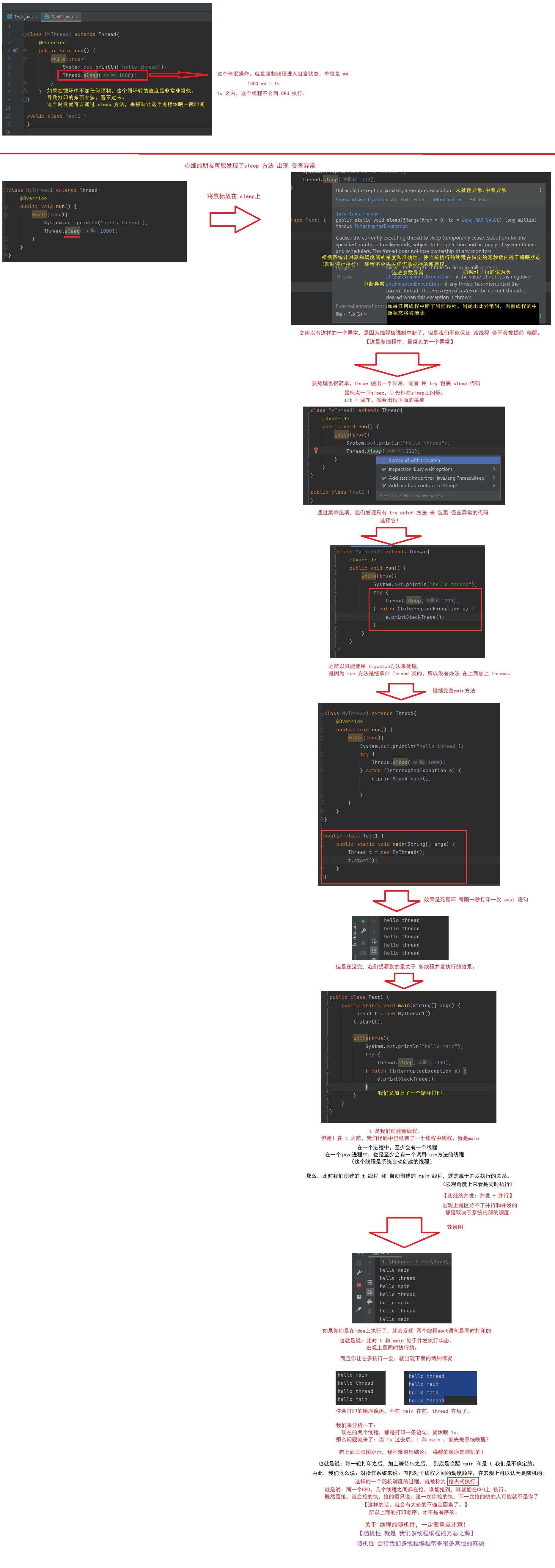
另外,其实我们这个例子打印出效果是不太理想的。
因为 线程之间 是 并发执行的,而我们从上面示例是看不出来的。
下面我们重新创建一个 Class 类 来表达 线程之间的并发执行。
知识点:异常
拓展
有的人可能会有疑问:为什么 Thread 没有导入包 也能用。
这是因为:但凡是 java.lang 包里的类,都不用手动导入包,类似还有String类。
sleep 方法 参数的单位是 ms的情况,时间的精确度就没有那么高了。
也就是说:sleep(1000) 并不是正好在 1000ms 之后就上CPU,可能是 998,又或者是 1003上CPU执行的。
又或者说CPU正处理其它事情,没空搭理你,导致拖延一些时间。
Thread 类创建线程的写法
1、最基本的创建线程的办法
这个写法就是上面举个例子。【创建子类,继承自 Thread,并且重写 run 方法。】
// 最基本的创建线程的办法
class MyThread extends Thread
@Override
public void run()
System.out.println("hello thread");
public class Test
public static void main(String[] args)
Thread t = new MyThread();
t.start();
2、创建 一个类 实现 Runnable 接口,再创建Runnable实例 传给 Thread 实例
通过 Runnable 来描述任务的内容
进一步的再把描述好的任务交给 Thread 实例
// 这里面的 Runnable 就是在描述一个 “任务”
class MyRunnable implements Runnable
@Override
public void run()
System.out.println("hello");
public class Test2
public static void main(String[] args)
// 需要注意的是 这里 我们实例化是 Thread 类本身,
// 只不过构造方法里给指定了 MyRunnable 实例
Thread t = new Thread(new MyRunnable());
t.start();
写法 3 和 写法 4 :就是上面两种写法的翻版 - 使用了匿名内部类。
写法3
创建了一个匿名内部类,继承自 Thread 类。
同时重写 run 方法 和 new 了
同时再 new 了 个 匿名内部类的实例。
【也就是 t 所指向的实例】
public class Test3
public static void main(String[] args)
Thread t = new Thread()
@Override
public void run()
System.out.println("hello thread");
;
t.start();// 此处仍然是调用 start 来开启线程
写法4
这一次,我们是针对 Runnable 接口 创建的 匿名内部类(这个匿名内部类实现了Runnable 接口)。
同时 将创建出的实例 作为 参数 传给了 Thread 的构造方法
public class Test4
public static void main(String[] args)
Thread t = new Thread(new Runnable()
@Override
public void run()
System.out.println("hello thread");
);
t.start();
小结
通过上面的四种写法,我们认识 Thread 方法 和 Runnable 方法。
那么这两种方法,哪一个更好?
通常 认为 Runnable 这种方法更好一点!
它能够做到让 线程 和 线程 执行的任务,更好的进行解耦(解除耦合)。
我们写代码一般希望:高内聚(同一类功能的代码放在一起),低耦合(不同的功能模块之间,没有关联关系)。
其实,我们在使用 Runable 方式 来创建线程的时候,就把当前的线程要执行的任务 与 整个线程的概念给分开了。
换句话说: Runnable 只是单纯的描述了一个任务,至于这个任务是要通过一个进程来执行,还是线程来执行,还是线程池来执行,还是协程来执行,都无所谓!
Runnable 本身并不关心,Runnable 里面的代码也不关心。就好像通缉令悬赏一个罪犯,是谁抓住的不重要,重要的是内容是否 被 完成 / 执行。
写法五
相当于 第 4 种写法的延伸 》》 进一步简化 - lambda表达式
说白了:使用 lambda 表达式 代替 Runnable。
public class Test5
public static void main(String[] args)
//() 表示无参数的run 方法(Runnable 的 run 方法)
// -> 表示 这是一个lambda 表达式
// lambda 表达式里面 具体内容
Thread t = new Thread(()->
System.out.println("hello thread");
);
t.start();
多线程的优势
多线程能够提高任务完成的效率。
为了证明 多线程的完成任务的效率。
我们下面一起来实践一下
假设:
现有两个整数变量,分别要对这辆变量,进行自增 10 亿次。
分别使用一个线程 和 两个线程。
我们通过这种方式来体现多线程的效率
总程序
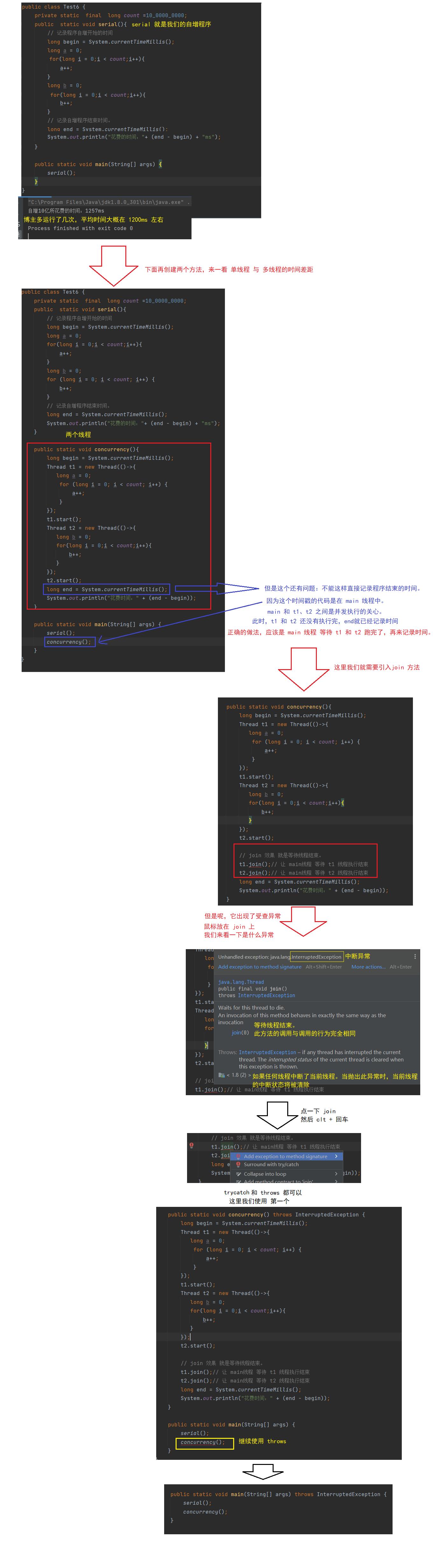
public class Test6
private static final long count =10_0000_0000;
public static void serial()
// 记录程序自增开始的时间
long begin = System.currentTimeMillis();
long a = 0;
for(long i = 0;i < count;i++)
a++;
long b = 0;
for (long i = 0; i < count; i++)
b++;
// 记录自增程序结束时间。
long end = System.currentTimeMillis();
System.out.println("花费的时间:"+ (end - begin) + "ms");
public static void concurrency() throws InterruptedException
long begin = System.currentTimeMillis();
Thread t1 = new Thread(()->
long a = 0;
for (long i = 0; i < count; i++)
a++;
);
t1.start();
Thread t2 = new Thread(()->
long b = 0;
for(long i = 0;i < count;i++)
b++;
);
t2.start();
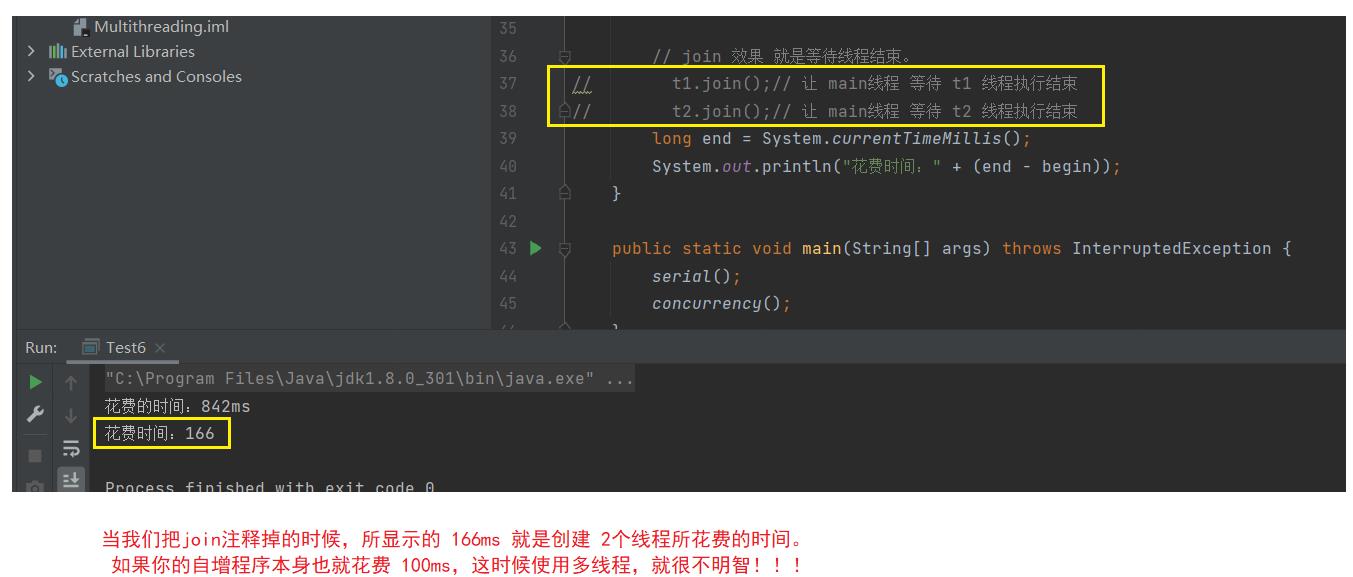
// join 效果 就是等待线程结束。
t1.join();// 让 main线程 等待 t1 线程执行结束
t2.join();// 让 main线程 等待 t2 线程执行结束
long end = System.currentTimeMillis();
System.out.println("花费时间:" + (end - begin));
public static void main(String[] args) throws InterruptedException
serial();
concurrency();

很明显 多线程 比 单线程 效率 大概高出了 3 分之 1.【数据量更大的话,效果更明显】
多线程 与 单线程 的效率差距 还是特别明显的!
但是! t1 和 t2 在底层中,是 并发执行, 还是并行执行。是不确定的!
多线程在真正并行执行的时候,效率才会有显著的提升!
另外,多线程在数据量庞大的情况下,效率的提升才是最明显!反而数据量很少的情况下,效率还会有所降低。因为创建线程也是有开销的。
所以讲到这,大家一定要明白一件事。
就是 多线程,它不是万能良药,不是说使用了多线程,代码的执行效率就一定能提高!还需要看使用场景!!!!
多线程特适合那种 CPU 密集型的程序:程序需要进行大量的计算,使用多线程就可以更充分的CPU的多核资源。
换句话来说,
我们使用多线程来提升程序的效率的前提是:这个任务是由CPU来完成的,并且我们需要进行大量的计算,让计算机的所有核心都工作起来。
Thread 类常见方法
Thread 的常见构造方法
z只讲解一些主要的方法
| 方法 | 说明 |
|---|---|
| Thread() | 创建线程对象 |
| Thread(Runnable target) | 使用 Runnable 对象创建线程对象 |
| Thread(String name) | 创建线程对象,并命名 |
| Thread(Runnable target, String name) | 使用 Runnable 对象创建线程对象,并命名 |
| 【了解】Thread(ThreadGroup group,Runnable target) | 线程可以被用来分组管理,分好的组即为线程组,这个目前我们了解即可 |
Thread(String name) - 创建线程对象,并命名
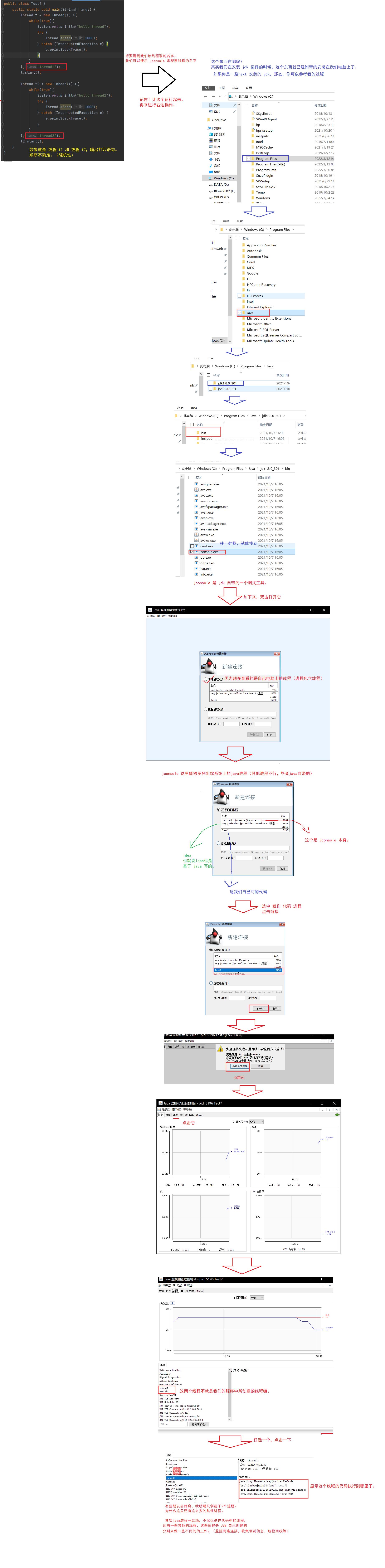
这个构造方法是给线程(thread 对象)起一个名字。
需要注意的是:起一个什么样子的名字,不影响线程的本身的执行。
取得名字要贴合使用场景,不能瞎取名字。
因为乱取线程名字,会影响到 程序员 对 代码 的 后续调试。
因为程序员在调试的时候,可以借助一些工具看到每个线程以及名字,很容易在调式中对线程做出区分。
Thread 的几个常见属性
| 属性 | 获取方法 |
|---|---|
| ID(身份标识) | getId() |
| 名称(就是我们上面构成方法给新城指定的名字) | getName() |
| 状态(线程程的状态) | getState() |
| 优先级 | (线程的优先级) getPriority() |
| 是否后台线程 | isDaemon() |
| 是否存活 | isAlive() |
| 是否被中断 | isInterrupted() |
是否后台线程 - isDaemon()
如果线程是后台线程,就不影响进程退出;
如果线程是前台线程,就会影响到进程退出。
【我们刚才在程序中创建的t1 和 t2 就是前台线程】
即使main 方法执行完,进程也不能退出,得等 t1 和 t2 都执行完。
整个程序才能退出!!!!
如果 t1 和 t2 是 后台线程,此时如果main执行完毕,整个进程就直接退出,
t1 和 t2 就被强行终止。
是否存活 - isAlive()
判断 操作系统中对应的编程是否正常运行。
Thread t 对象的生命周期 和 内核中对应的线程,生命周期并不完全一至。
因为创建出 t 对象之后,在调用 start之前,系统中是是没有对应线程的。
进一步来说,在 run 方法执行完了之后,系统中的线程就销毁了,但是 t 这个 对象 可能 还存在。
所以我们就可以通过 isAlive 来 判断 当前系统的线程的运行情况。
如果 调用 start 之后,run执行完之前,isAlive 就返回 true
入股 调用 start 之前,或者run执行完之后,isAlive 就返回 false
Thread 中的一些重要方法
start 方法 - 启动线程
start 决定了系统中是不是真的创建出线程。

经典面试题: start 与 run方法 的区别
start 操作就是在创建新的线程,run 就是一个普通方法 描述一个任务的内容。
中断一个线程
一般通过 Tread 来创建的线程,想让一个线程停下来的关键,就是要让线程对应 run 方法 执行完。【这是中断线程的关键】
还有一个特殊的,就是main这个线程。
对于 main线程 来说,必须要等到 main 方法执行完,线程才能结束。
让线程结束有以下几个方法:
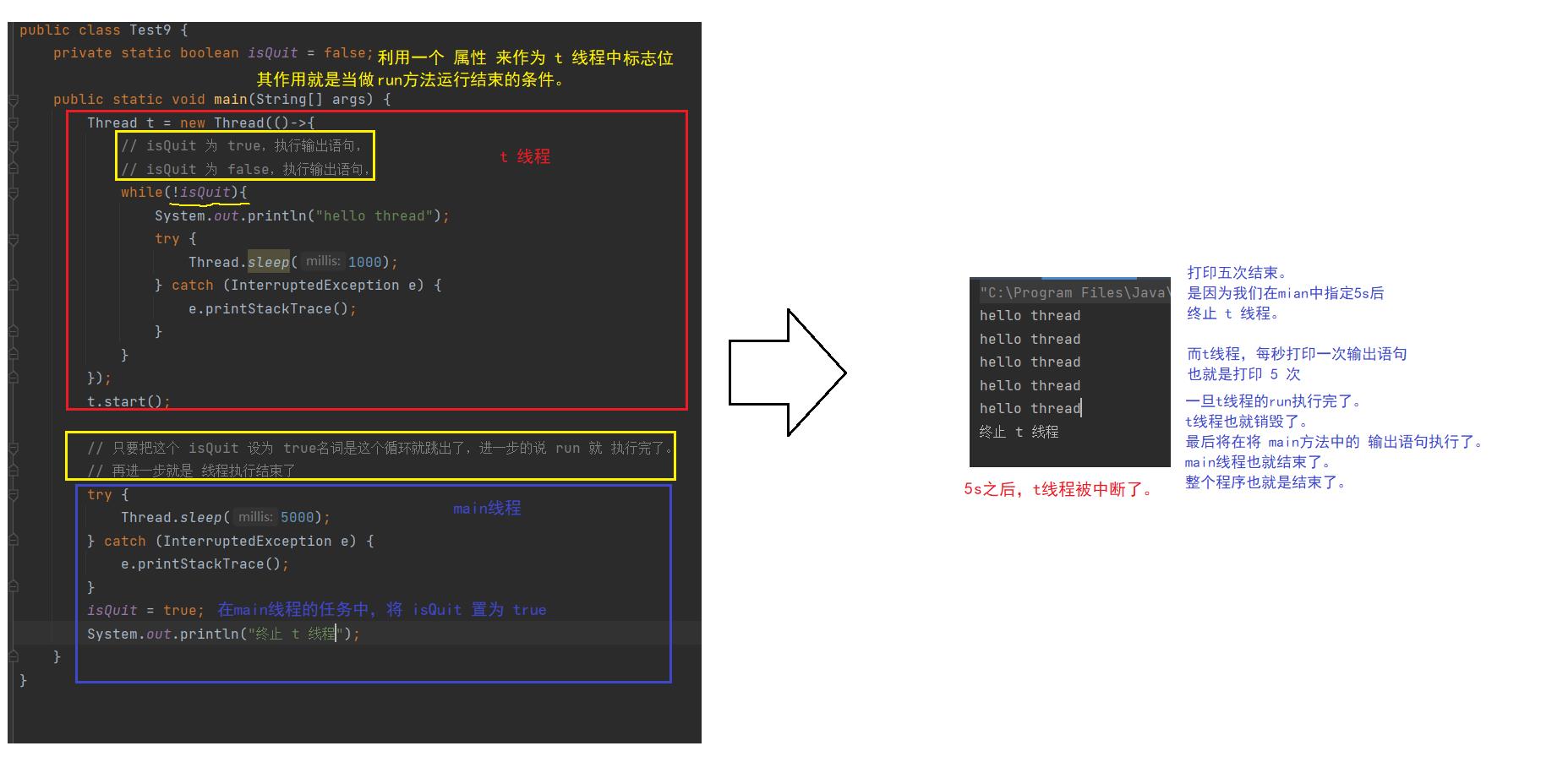
1、可以手动的设置一个标志位(自己创建一个变量,boolean 和 int 类型都行),来控制线程是否要执行的结果。
结论:在其它线程中控制某个标志位,就能影响对应线程的运行的状态(提前中止该线程的运行)。
另外,此处因为多个线程共用一个虚拟地址空间!
因此,main 线程 修改的 isQuit 和 t 线程判定 的 isQuit 是同一个值。
但是,如果是在进程的那种情况下,在不同的虚拟地址的情况下,这种写法就会失效。
2、使用 Thread 中内置的一个标志位来进行判断来进行判定(比第一种方法更好)
上面那种写法其实还存在着一个问题:标志位的写法,还不够严谨,存在某些问题。
这样写,只能保证 在上面的程序中运行,可能在其他程序中就没有效果了。
这时候,我们就需要使用 第二种方法:使用 Thread 中内置的一个标志位来进行判断来进行判定:
1、Thread.interrupted(); 【这是一个静态方法】
2、Thread currentThread().isInterrupted() 【这是一个实例方法,其中 currentThread 能够获取当前线程的实例】
推荐使用第二种方法!!

public class Test10
public static void main(String[] args)
Thread t = new Thread(()->
// Thread.currentThread() 获取目前所在线程 t
// isInterrupted() 判断 线程 t 是否中断
// 中断返回 true,再根据 !取反,为 false,跳出循环,从而结束 run任务,致使线程t中断结束执行
// 执行中返回 false,,再根据 !取反,为 true,执行 run 的 输出语句。
while(!Thread.currentThread().isInterrupted())
System.out.println("hello thread");
try
Thread.sleep(1000);
catch (InterruptedException e)
e.printStackTrace();
);
t.start();
try
Thread.sleep(5000);// 在main线程中,5s之后,执行下面 代码t.interrupt()
catch (InterruptedException e)
e.printStackTrace();
// 在主线程中,调用 interrupt 方块,来中断这个线程
// t.interrupt 的 意思是: t线程被中断
t.interrupt();
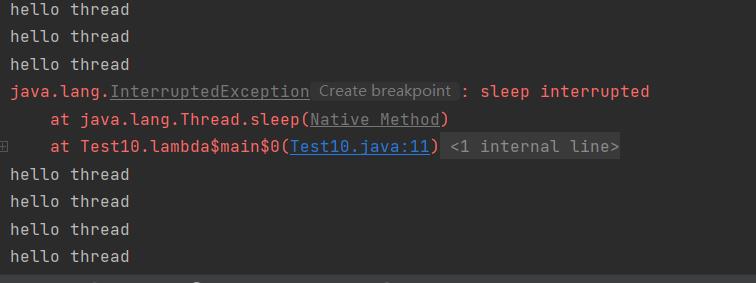
但是呢!运行的结果 与我们想象的不同!
期望:在 5s之后,线程 t 被中断
实际:5s之后,编译器报出一个异常,线程 t 继续执行,线程t还没有终止。
也就是说: t.interrupt() 不仅仅是针对 while循环的条件(标记位) 进行操作,它还可能触发一个异常。
需要注意的是:在使用 interrupt 方法的时候,我们的interrupt可能会有两种情况,而这两种情况都是需要考虑到的。
如果我们线程中没有什么代码导致线程进入阻塞状态的操作,直接一个循环判断就是够了。
如果有,我们就需要借助 catch代码块(处理异常),在里面进行添加相应的操作。
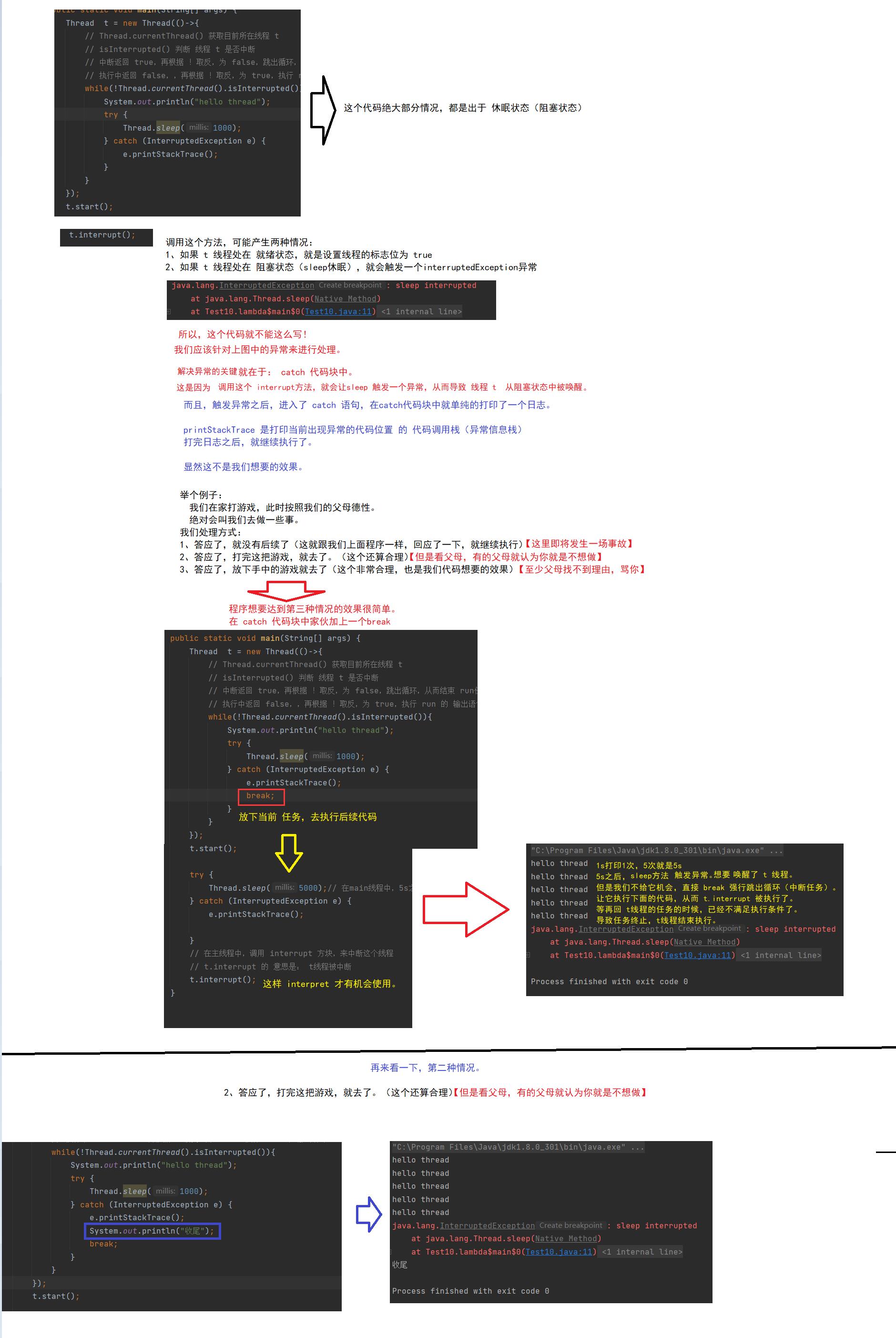
Thread 内部包含了一个 boolean 类型的变量作为线程是否被中断的标记.:
public boolean isInterrupted() :判断对象关联的线程的标志位是否设置,调用后不清除标志位.【第三个方法,这个实际开发中 常用的 写法】
【我们上面while循环调用 interrupted方法是第三个,线程 t. interrupt 是 第一个】
毕竟一个代码中的线程有很多个,随时哪个线程都可能会终止
Thread.interrupted() 这个方法判定的标志位置是 Thread 的 static 成员。
又因为 一个程序中只有一个标志位,很显然这么多的线程,一个标志位怎么够用。
Thread.currentThread().isinterrupted() 这个方法判定的标志位 是 Thread 的 普通成员,每个示例都有自己的标志位。【一般无脑用这个方法即可】

线程等待
前面说到:多个线程之间,调度的顺序是不确定的。(顺序取决于系统)
但是这样的不确定性 并不好。有的时候,我们是需要让线程有明确顺序的。
换个说法:
线程之间的执行是按照调度器来安排的,这个过程可以视为是“无序,随机”。
这样不太好,有时候,我们需要能够控制线程之间的顺序。
线程等待就是其中一种,控制线程执行顺序的手段
此处的线程等待,主要是控制线程结束的先后顺序。
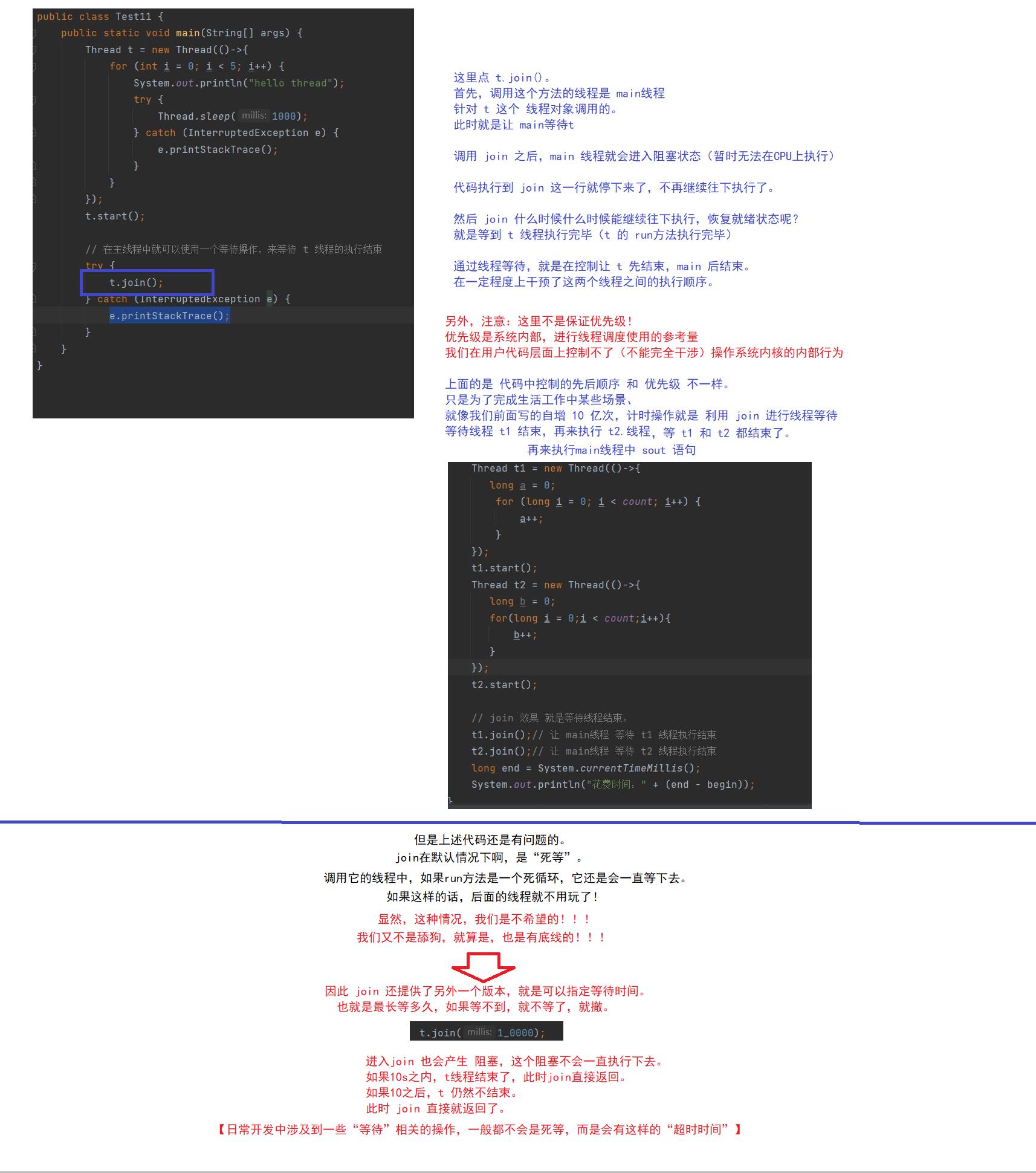
其实 join 也是其中的一种
调用 join 的时候,哪个线程调用的 join,那个线程就会阻塞等待。
等到对应的线程执行完毕为止(对应线程的 run 执行完)
获取当前线程引用
| 方法 | 说明 |
|---|---|
| public static Thread currentThread(); | 返回当前线程对象的引用(Thread 实例的引用) |
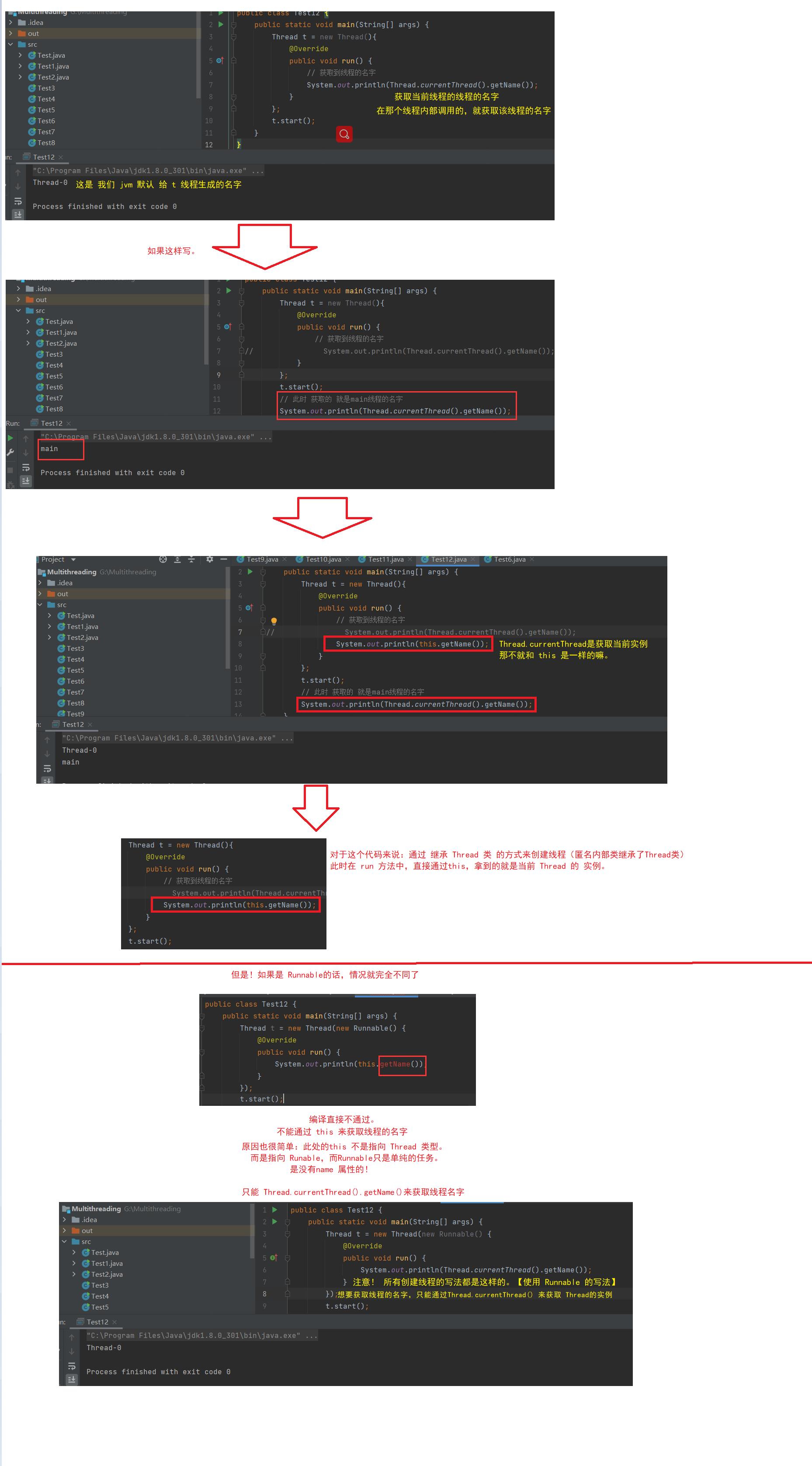
哪个线程调用的这个currentThread,就获取到哪个线程的实例。
线程休眠
就是 sleep,前面也用了很多。
这里,我们进一步的解析它。
所谓的 线程休眠的具体作用是什么?
回顾
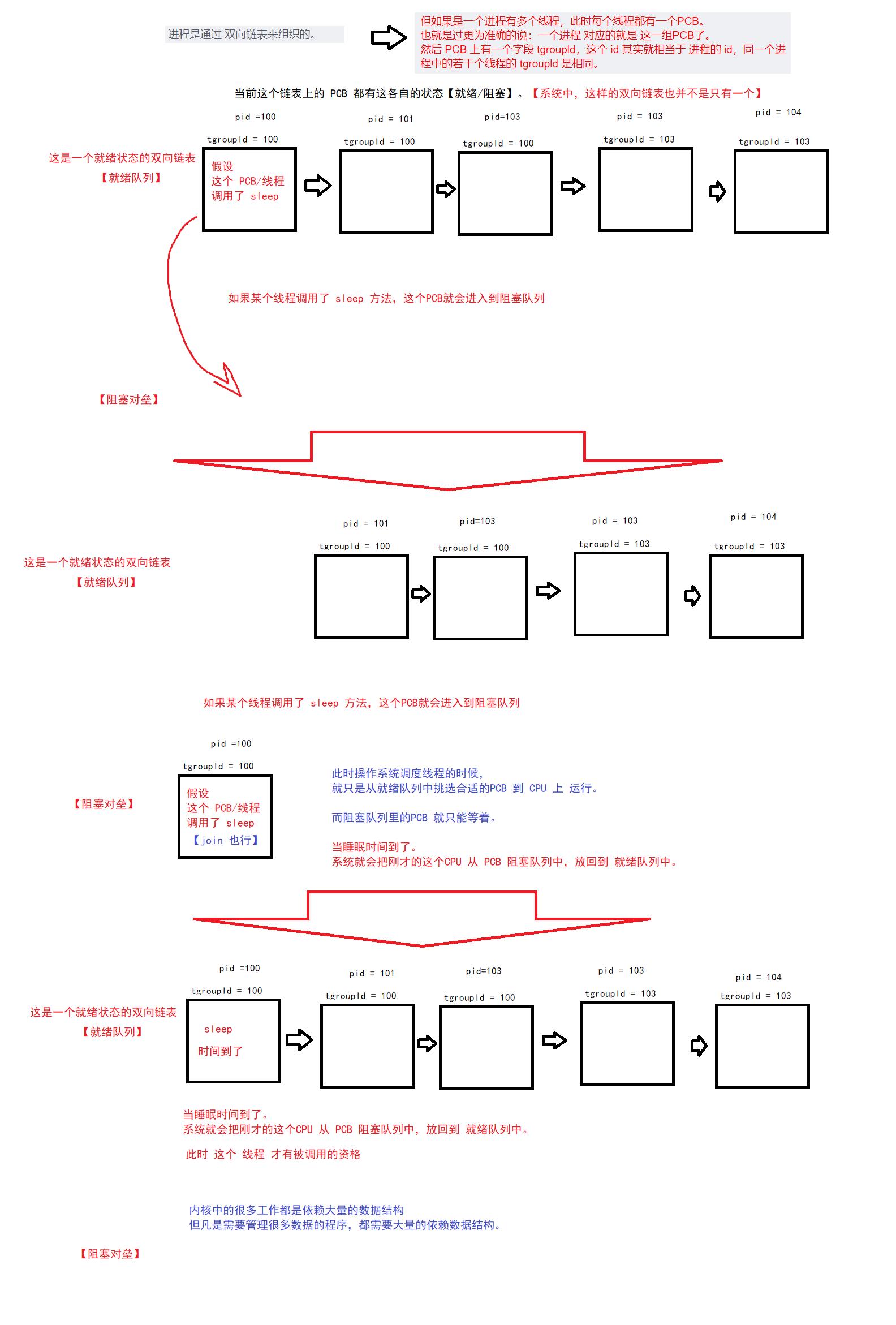
进程是通过 PCB 来描述。
进程是通过 双向链表来组织的。
前面的说法是针对只有一个线程的进程,是这种情况。
但如果是一个进程有多个线程,此时每个线程都有一个PCB。
也就是过更为准确的说:一个进程 对应的就是 这一组PCB了。
然后 PCB 上有一个字段 tgroupld,这个 id 其实就相当于 进程的 id,同一个进程中的若干个线程的 tgroupld 是相同。
那么 PCB - process control block 进程控制块 和 线程有什么关系?
其实在linux系统中 内核是不缺分进程和线程。
只是程序员在写应用程序代码的时候,弄出来的词。
实际上 linux 内黑 指认 PCB!!!
在内核里 linux 把 线程 称为 轻量级进程。
线程的状态
主要就介绍两个状态:
1、就绪
2、阻塞
前面所讲的进程状态,其实都是指的是系统按照“什么样子的态度”来调度这个进程
但是!这种说法并不是很严谨!
上面的说法时针对一个进程中只有一个线程的情况。
更常见的情况:一个进程包含多个线程。
所谓的状态其实是绑定在线程上。【前面讲的例子都在透露这个信息】
与线程休眠想表达出的意思一样:Linux 中认为 PCB 和 线程一一对应,一个进程对应一组PCB。
状态本来就是 PCB 的 一个属性,现在正好每个线程都有着各自的PCB,也就说每个线程都有属于自己的状态。
因此,我们系统在调用线程的时候,就可以根据每个线程不同的状态,来确定 是否调度该线程。
并且我们还可以通过状态来更好的区分线程。
上面说的 “就绪” 和 “阻塞” 都是针对系统层面上的线程的状态【PCB的状态】。
在Java中,尤其是在 thread 类中,又对线程的状态进行了进一步的细化。
1、NEW: 安排了工作, 还未开始行动
把 Thread 对象创建好了,但是没有调用start方法。
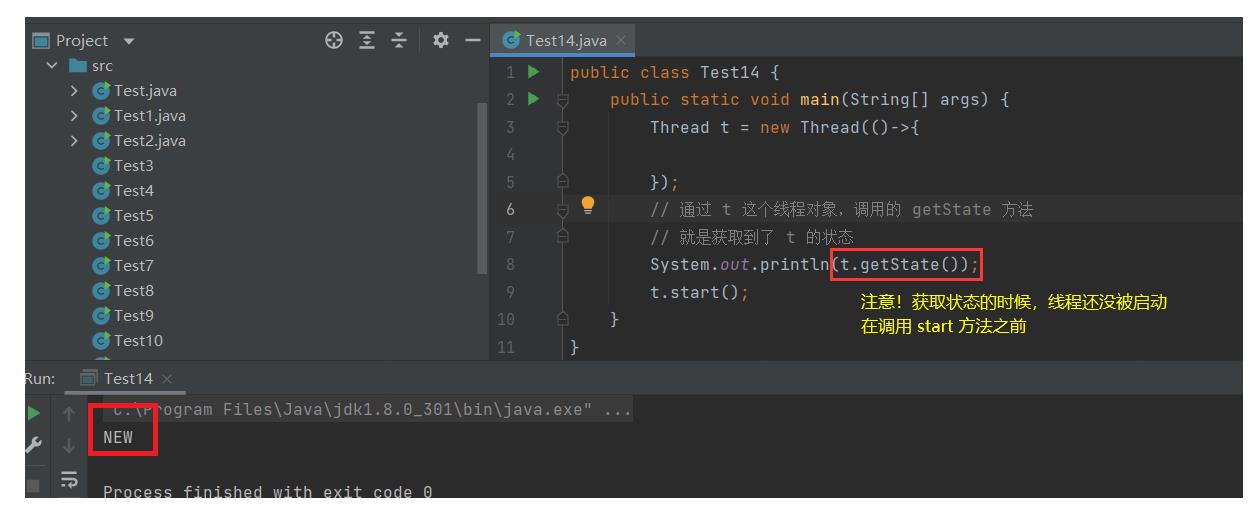
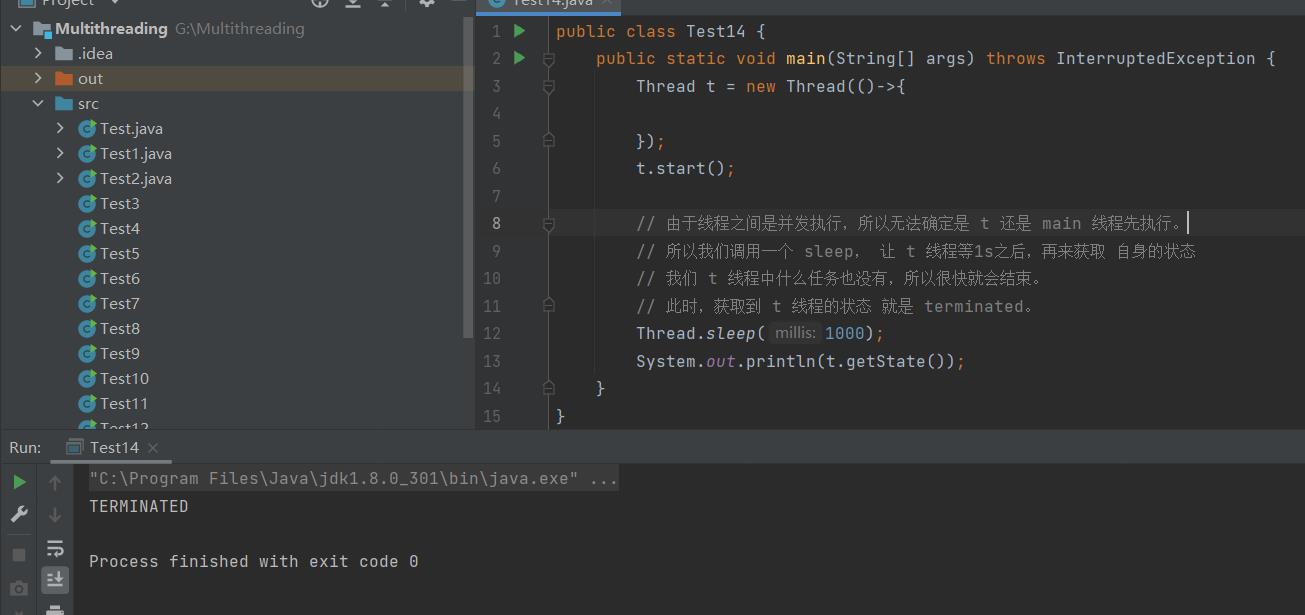
2、TERMINATED: 工作完成了.
操作系统中的线程已经执行完毕,销毁了。
但是 Thread 对象还在,此时获取的状态就是 terminated。
小结

3、RUNNABLE: 可工作的. 又可以分成正在工作中和即将开始工作.
RUNNABLE 就是 我们常说的就绪状态。
处于这个状态的线程,就是在 就绪队列中。
随时可以被被调度到 CPU 上。
对 就绪状态 的线程,有两种情况:
1、正在被执行
2、还没有执行,但是随时可以调度它。
如果以上是关于多线程基础篇 - JavaEE初阶 - 细节狂魔的主要内容,如果未能解决你的问题,请参考以下文章