称霸Kaggle的十大深度学习技巧!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了称霸Kaggle的十大深度学习技巧!相关的知识,希望对你有一定的参考价值。
Datawhale赛事
作者:Samuel Lynn-Evans,来源:量子位
是什么秘诀让新手们在短期内快速掌握并能构建最先进的DL算法?一位名叫塞缪尔(Samuel Lynn-Evans)的法国学员总结了十条经验。

他这篇文章发表在FloydHub官方博客上,因为除了来自Fast.ai的技巧之外,他还用了FloydHub的免设置深度学习GPU云平台。
接下来,我们看看他从fast.ai学来的十大技艺:
1. 使用Fast.ai库
这一条最为简单直接。
from fast.ai import *Fast.ai库是一个新手友好型的深度学习工具箱,而且是目前复现最新算法的首要之选。
每当Fast.ai团队及AI研究者发现一篇有趣论文时,会在各种数据集上进行测试,并确定合适的调优方法。他们会把效果较好的模型实现加入到这个函数库中,用户可以快速载入这些模型。
于是,Fast.ai库成了一个功能强大的工具箱,能够快速载入一些当前最新的算法实现,如带重启的随机梯度下降算法、差分学习率和测试时增强等等,这里不逐一提及了。
下面会分别介绍这些技术,并展示如何使用Fast.ai库来快速使用它们。
这个函数库是基于PyTorch构建,构建模型时可以流畅地使用。
Fast.ai库地址:
https://github.com/fastai/fastai
2. 使用多个而不是单一学习率
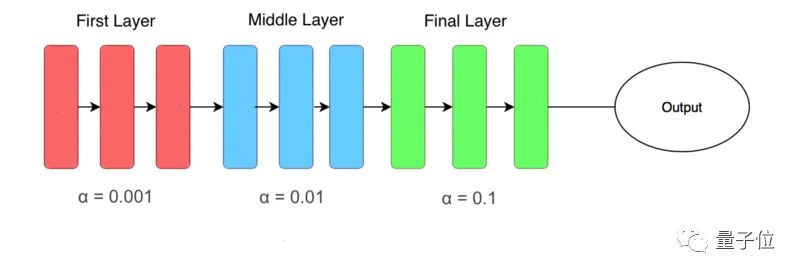
差分学习率(Differential Learning rates)意味着在训练时变换网络层比提高网络深度更重要。
基于已有模型来训练深度学习网络,这是一种被验证过很可靠的方法,可以在计算机视觉任务中得到更好的效果。
大部分已有网络(如Resnet、VGG和Inception等)都是在ImageNet数据集训练的,因此我们要根据所用数据集与ImageNet图像的相似性,来适当改变网络权重。
在修改这些权重时,我们通常要对模型的最后几层进行修改,因为这些层被用于检测基本特征(如边缘和轮廓),不同数据集有着不同基本特征。
首先,要使用Fast.ai库来获得预训练的模型,代码如下:
from fastai.conv_learner import *
# import library for creating learning object for convolutional #networks
model = VVG16()
# assign model to resnet, vgg, or even your own custom model
PATH = './folder_containing_images'
data = ImageClassifierData.from_paths(PATH)
# create fast ai data object, in this method we use from_paths where
# inside PATH each image class is separated into different folders
learn = ConvLearner.pretrained(model, data, precompute=True)
# create a learn object to quickly utilise state of the art
# techniques from the fast ai library创建学习对象之后(learn object),通过快速冻结前面网络层并微调后面网络层来解决问题:
learn.freeze()
# freeze layers up to the last one, so weights will not be updated.
learning_rate = 0.1
learn.fit(learning_rate, epochs=3)
# train only the last layer for a few epochs当后面网络层产生了良好效果,我们会应用差分学习率来改变前面网络层。在实际中,一般将学习率的缩小倍数设置为10倍:
learn.unfreeze()
# set requires_grads to be True for all layers, so they can be updated
learning_rate = [0.001, 0.01, 0.1]
# learning rate is set so that deepest third of layers have a rate of 0.001, # middle layers have a rate of 0.01, and final layers 0.1.
learn.fit(learning_rate, epochs=3)
# train model for three epoch with using differential learning rates3. 如何找到合适的学习率
学习率是神经网络训练中最重要的超参数,没有之一,但之前在实际应用中很难为神经网络选择最佳的学习率。
Leslie Smith的一篇周期性学习率论文发现了答案,这是一个相对不知名的发现,直到它被Fast.ai课程推广后才逐渐被广泛使用。
这篇论文是:Cyclical Learning Rates for Training Neural Networks
https://arxiv.org/abs/1506.01186
在这种方法中,我们尝试使用较低学习率来训练神经网络,但是在每个批次中以指数形式增加,相应代码如下:
learn.lr_find()
# run on learn object where learning rate is increased exponentially
learn.sched.plot_lr()
# plot graph of learning rate against iterations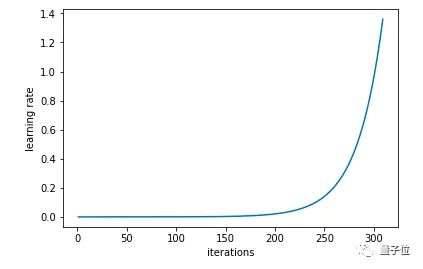
同时,记录每个学习率对应的Loss值,然后画出学习率和Loss值的关系图:
learn.sched.plot()
# plots the loss against the learning rate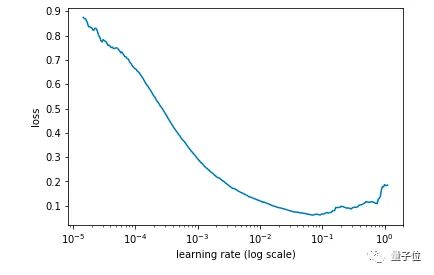
通过找出学习率最高且Loss值仍在下降的值来确定最佳学习率。在上述情况中,该值将为0.01。
4. 余弦退火
在采用批次随机梯度下降算法时,神经网络应该越来越接近Loss值的全局最小值。当它逐渐接近这个最小值时,学习率应该变得更小来使得模型不会超调且尽可能接近这一点。
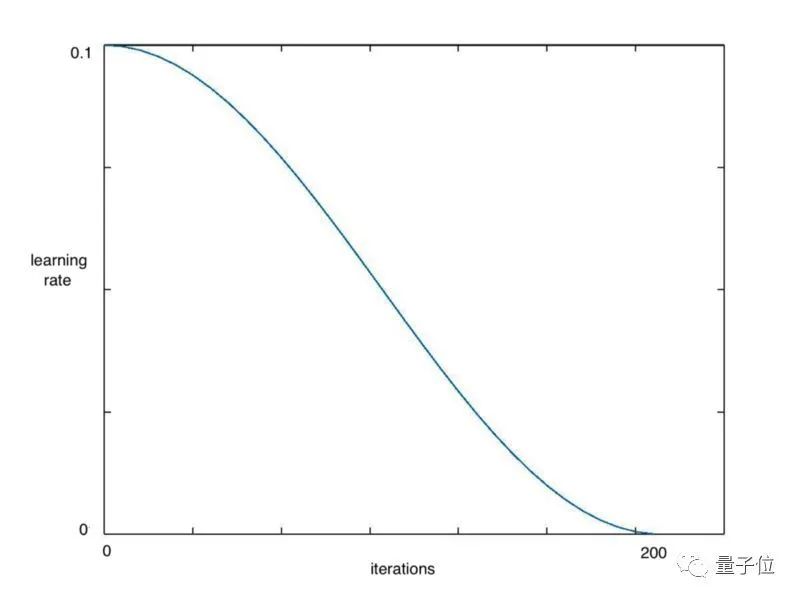
余弦退火(Cosine annealing)利用余弦函数来降低学习率,进而解决这个问题,如下图所示:
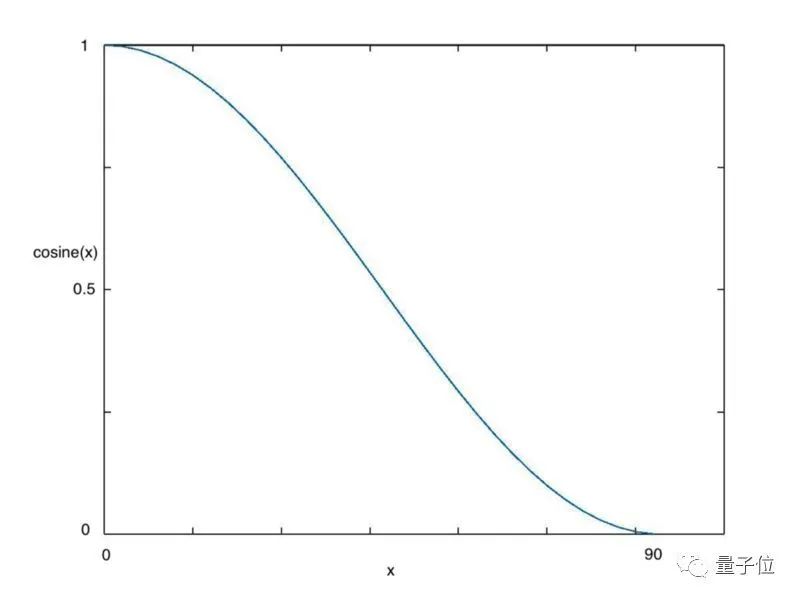
从上图可以看出,随着x的增加,余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
learn.fit(0.1, 1)
# Calling learn fit automatically takes advantage of cosine annealing我们可以用Fast.ai库中的**learn.fit()**函数,来快速实现这个算法,在整个周期中不断降低学习率,如下图所示:
同时,在这种方法基础上,我们可以进一步引入重启机制。
5. 带重启的SGD算法
在训练时,梯度下降算法可能陷入局部最小值,而不是全局最小值。
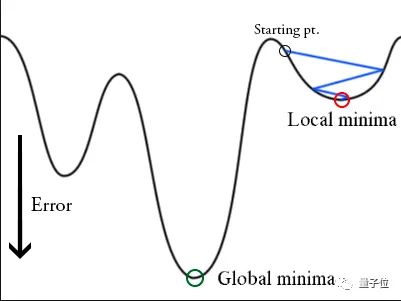
梯度下降算法可以通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。这种方式称为带重启的随机梯度下降方法(stochastic gradient descent with restarts, SGDR),这个方法在Loshchilov和Hutter的ICLR论文中展示出了很好的效果。
这篇论文是:SGDR: Stochastic Gradient Descent with Warm Restarts
https://arxiv.org/abs/1608.03983
用Fast.ai库可以快速导入SGDR算法。当调用learn.fit(learning_rate, epochs)函数时,学习率在每个周期开始时重置为参数输入时的初始值,然后像上面余弦退火部分描述的那样,逐渐减小。
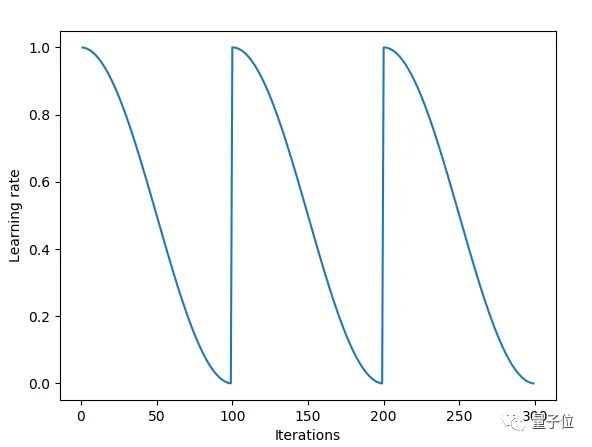
每当学习率下降到最小点,在上图中为每100次迭代,我们称为一个循环。
cycle_len = 1
# decide how many epochs it takes for the learning rate to fall to
# its minimum point. In this case, 1 epoch
cycle_mult=2
# at the end of each cycle, multiply the cycle_len value by 2
learn.fit(0.1, 3, cycle_len=2, cycle_mult=2)
# in this case there will be three restarts. The first time with
# cycle_len of 1, so it will take 1 epoch to complete the cycle.
# cycle_mult=2 so the next cycle with have a length of two epochs,
# and the next four.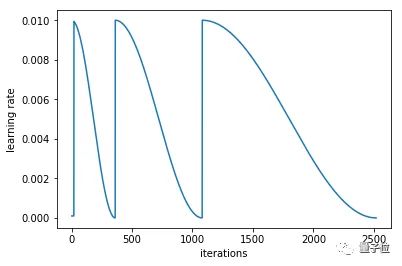
利用这些参数,和使用差分学习率,这些技巧是Fast.ai用户在图像分类问题上取得良好效果的关键。
Fast.ai论坛有个帖子专门讨论Cycle_mult和cycle_len函数,地址在这里:
http://forums.fast.ai/t/understanding-cycle-len-and-cycle-mult/9413/8
更多关于学习率的详细内容可参考这个Fast.ai课程:
http://course.fast.ai/lessons/lesson2.html
6. 人格化你的激活函数
Softmax只喜欢选择一样东西;
Sigmoid想知道你在[-1, 1]区间上的位置,并不关心你超出这些值后的增加量;
Relu是一名俱乐部保镖,要将负数拒之门外。
……
以这种思路对待激活函数,看起来很愚蠢,但是安排一个角色后能确保把他们用到正确任务中。
正如fast.ai创始人Jeremy Howard指出,不少学术论文中也把Softmax函数用在多分类问题中。在DL学习过程中,我也看到它在论文和博客中多次使用不当。
7. 迁移学习在NLP问题中非常有效
正如预训练好的模型在计算机视觉任务中很有效一样,已有研究表明,自然语言处理(NLP)模型也可以从这种方法中受益。
在Fast.ai第4课中,Jeremy Howard用迁移学习方法建立了一个模型,来判断IMDB上的电影评论是积极的还是消极的。
这种方法的效果立竿见影,他所达到的准确率超过了Salesforce论文中展示的所有先前模型:
https://einstein.ai/research/learned-in-translation-contextualized-word-vectors。

这个模型的关键在于先训练模型来获得对语言的一些理解,然后再使用这种预训练好的模型作为新模型的一部分来分析情绪。
为了创建第一个模型,我们训练了一个循环神经网络(RNN)来预测文本序列中的下个单词,这称为语言建模。当训练后网络的准确率达到一定值,它对每个单词的编码模式就会传递给用于情感分析的新模型。
在上面的例子中,我们看到这个语言模型与另一个模型集成后用于情感分析,但是这种方法可以应用到其他任何NLP任务中,包括翻译和数据提取。
而且,计算机视觉中的一些技巧,也同样适用于此,如上面提到的冻结网络层和使用差分学习率,在这里也能取得更好的效果。
这种方法在NLP任务上的使用涉及很多细节,这里就不贴出代码了,可访问相应课程和代码。
课程:
http://course.fast.ai/lessons/lesson4.html
代码:https://github.com/fastai/fastai/blob/master/courses/dl1/lesson4-imdb.ipynb
8. 深度学习在处理结构化数据上的优势
Fast.ai课程中展示了深度学习在处理结构化数据上的突出表现,且无需借助特征工程以及领域内的特定知识。
这个库充分利用了PyTorch中embedding函数,允许将分类变量快速转换为嵌入矩阵。
他们展示出的技术比较简单直接,只需将分类变量转换为数字,然后为每个值分配嵌入向量:
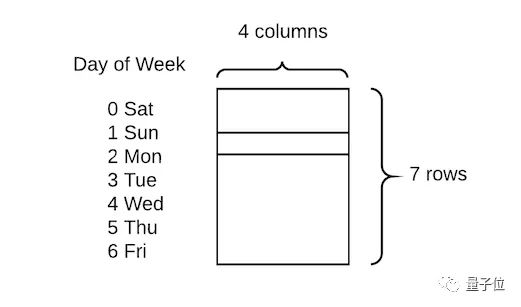
在这类任务上,传统做法是创建虚拟变量,即进行一次热编码。与之相比,这种方式的优点是用四个数值代替一个数值来描述每一天,因此可获得更高的数据维度和更丰富的关系。
这种方法在Rossman Kaggle比赛中获得第三名,惜败于两位利用专业知识来创建许多额外特征的领域专家。
相关课程:
http://course.fast.ai/lessons/lesson4.html
代码:
https://github.com/fastai/fastai/blob/master/courses/dl1/lesson3-rossman.ipynb
这种用深度学习来减少对特征工程依赖的思路,也被Pinterest证实过。他也提到过,他们正努力通过深度学习模型,期望用更少的工作量来获得更好的效果。
9. 更多内置函数:Dropout层、尺寸设置、TTA
4月30日,Fast.ai团队在斯坦福大学举办的DAWNBench竞赛中,赢得了基于Imagenet和CIFAR10的分类任务。在Jeremy的夺冠总结中,他将这次成功归功于fast.ai库中的一些额外函数。
其中之一是Dropout层,由Geoffrey Hinton两年前在一篇开创性的论文中提出。它最初很受欢迎,但在最近的计算机视觉论文中似乎有所忽略。这篇论文是:
Dropout: A Simple Way to Prevent Neural Networks from Overfitting:
https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
然而,PyTorch库使它的实现变得很简单,用Fast.ai库加载它就更容易了。

Dropout函数能减弱过拟合效应,因此要在CIFAR-10这样一个相对较小的数据集上取胜,这点很重要。在创建learn对象时,Fast.ai库会自动加入dropout函数,同时可使用ps变量来修改参数,如下所示:
learn = ConvLearner.pretrained(model, data, ps=0.5, precompute=True)
# creates a dropout of 0.5 (i.e. half the activations) on test dataset.
# This is automatically turned off for the validation set有一种很简单有效的方法,经常用来处理过拟合效应和提高准确性,它就是训练小尺寸图像,然后增大尺寸并再次训练相同模型。
# create a data object with images of sz * sz pixels
def get_data(sz):
tmfs = tfms_from_model(model, sz)
# tells what size images should be, additional transformations such
# image flips and zooms can easily be added here too
data = ImageClassifierData.from_paths(PATH, tfms=tfms)
# creates fastai data object of create size
return data
learn.set_data(get_data(299))
# changes the data in the learn object to be images of size 299
# without changing the model.
learn.fit(0.1, 3)
# train for a few epochs on larger versions of images, avoiding overfitting还有一种先进技巧,可将准确率提高若干个百分点,它就是测试时增强(test time augmentation, TTA)。这里会为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中;然后对多个版本进行计算得到平均输出,作为图像的最终输出分数,可调用learn.TTA()来使用该算法。
preds, target = learn.TTA()这种技术很有效,因为原始图像显示的区域可能会缺少一些重要特征,在模型中输入图像的多个版本并取平均值,能解决上述问题。
10. 创新力很关键
在DAWNBench比赛中,Fast.ai团队提出的模型不仅速度最快,而且计算成本低。要明白,要构建成功的DL应用,不只是一个利用大量GPU资源的计算任务,而应该是一个需要创造力、直觉和创新力的问题。
本文中讨论的一些突破,包括Dropout层、余弦退火和带重启的SGD方法等,实际上是研究者针对一些问题想到的不同解决方式。与简单地增大训练数据集相比,能更好地提升准确率。
硅谷的很多大公司有大量GPU资源,但是,不要认为他们的先进效果遥不可及,你也能靠创新力提出一些新思路,来挑战效果排行榜。
事实上,有时计算力的局限也是一种机会,因为需求是创新的动力源泉。
关于作者
Samuel Lynn-Evans过去10年一直在教授生命科学课程,注意到机器学习在科学研究中的巨大潜力后,他开始在巴黎42学校学习人工智能,想将NLP技术应用到生物学和医学问题中。
原文:https://blog.floydhub.com/ten-techniques-from-fast-ai/
 干货学习,点赞三连↓
干货学习,点赞三连↓
以上是关于称霸Kaggle的十大深度学习技巧!的主要内容,如果未能解决你的问题,请参考以下文章
深度学习实战Kaggle比赛:房价预测(kaggle-house-price)
遇事不决,XGBoost,梯度提升比深度学习更容易赢得Kaggle竞赛
实战 Kaggle 比赛:图像分类(CIFAR-10) 动手学深度学习v2