PyTorch常用代码段合集
Posted Wang_AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch常用代码段合集相关的知识,希望对你有一定的参考价值。
作者丨Jack Stark@知乎
来源丨https://zhuanlan.zhihu.com/p/104019160
导读
本文是PyTorch常用代码段合集,涵盖基本配置、张量处理、模型定义与操作、数据处理、模型训练与测试等5个方面,还给出了多个值得注意的Tips,内容非常全面。
PyTorch最好的资料是官方文档。本文是PyTorch常用代码段,在参考资料[1](张皓:PyTorch Cookbook)的基础上做了一些修补,方便使用时查阅。
1. 基本配置
导入包和版本查询

可复现性
在硬件设备(CPU、GPU)不同时,完全的可复现性无法保证,即使随机种子相同。但是,在同一个设备上,应该保证可复现性。具体做法是,在程序开始的时候固定torch的随机种子,同时也把numpy的随机种子固定。

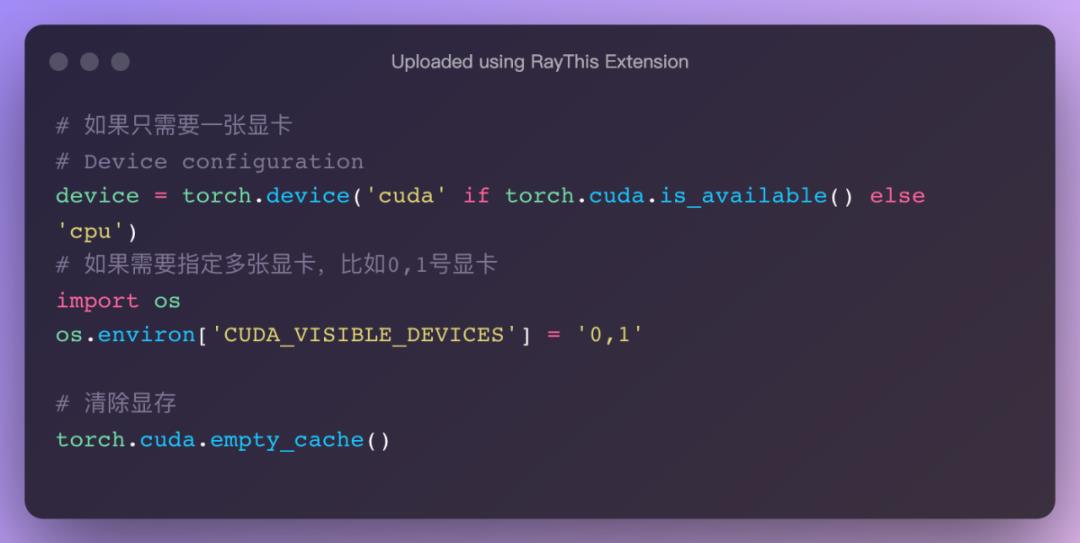
显卡设置
2. 张量(Tensor)处理
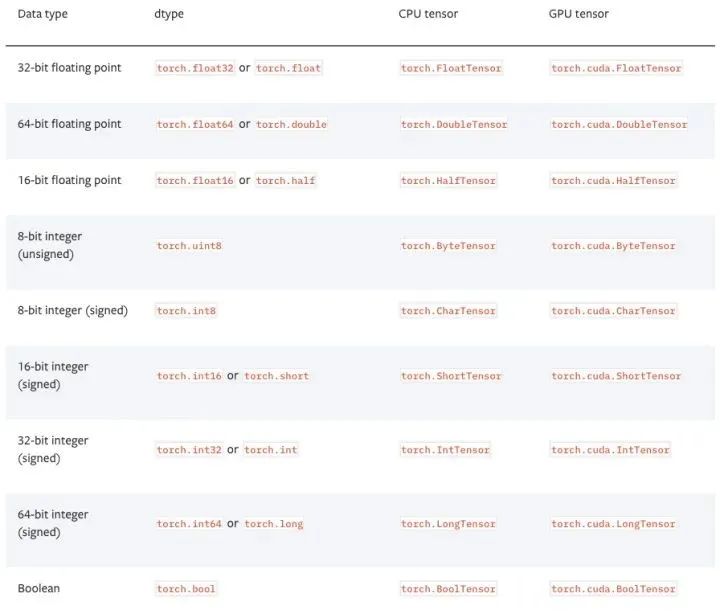
张量的数据类型
PyTorch有9种CPU张量类型和9种GPU张量类型。
张量基本信息

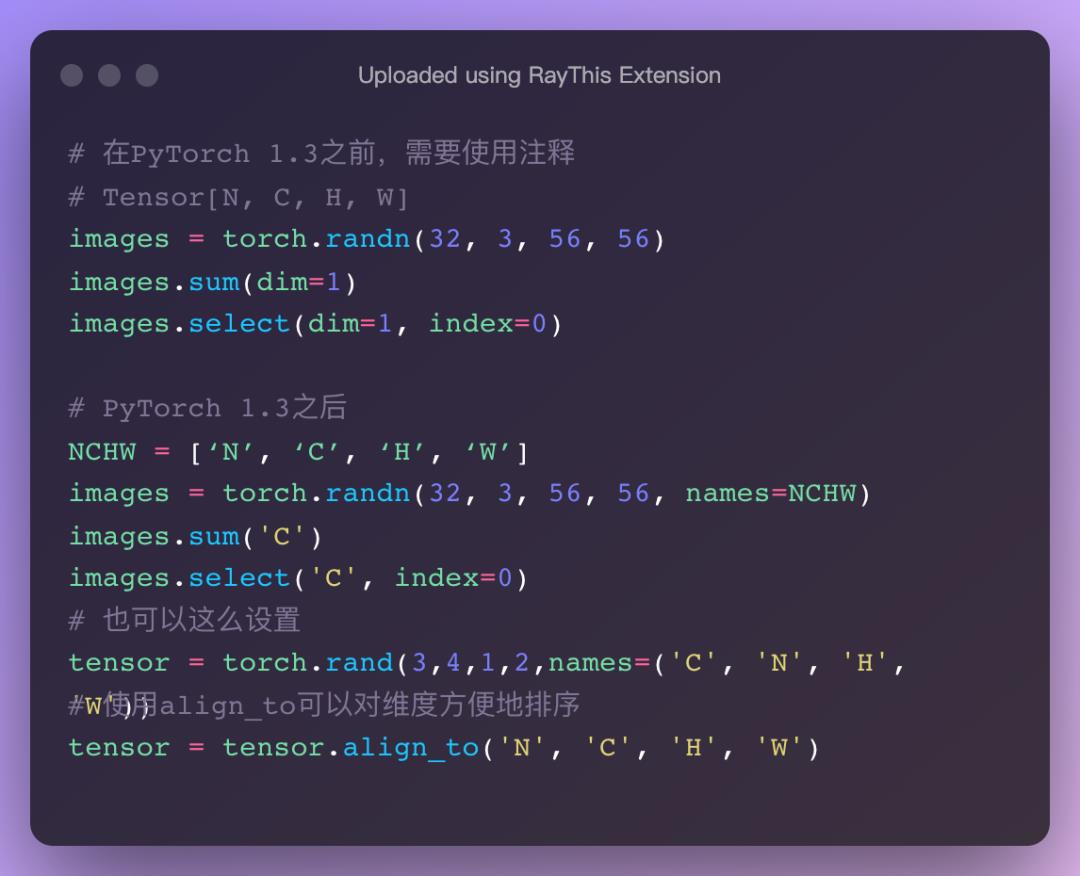
命名张量
张量命名是一个非常有用的方法,这样可以方便地使用维度的名字来做索引或其他操作,大大提高了可读性、易用性,防止出错。
数据类型转换

torch.Tensor与np.ndarray转换
除了CharTensor,其他所有CPU上的张量都支持转换为numpy格式然后再转换回来。

Torch.tensor与PIL.Image转换
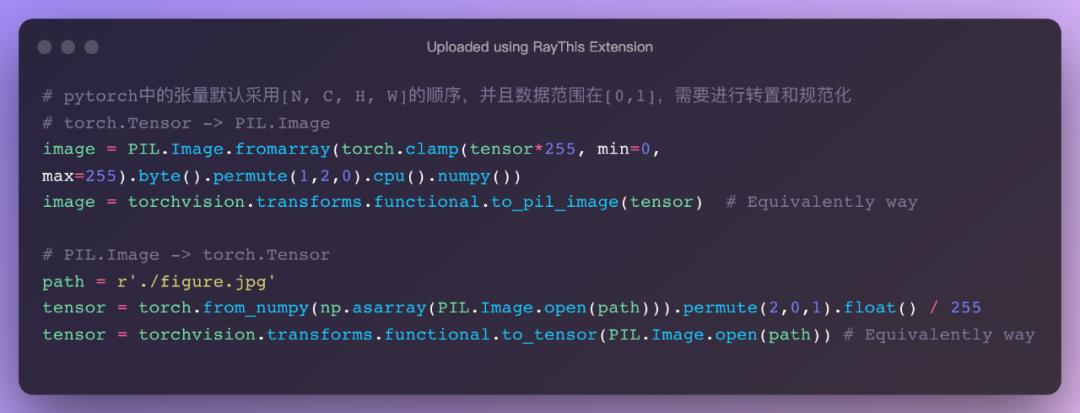
np.ndarray与PIL.Image的转换

从只包含一个元素的张量中提取值

张量形变

打乱顺序

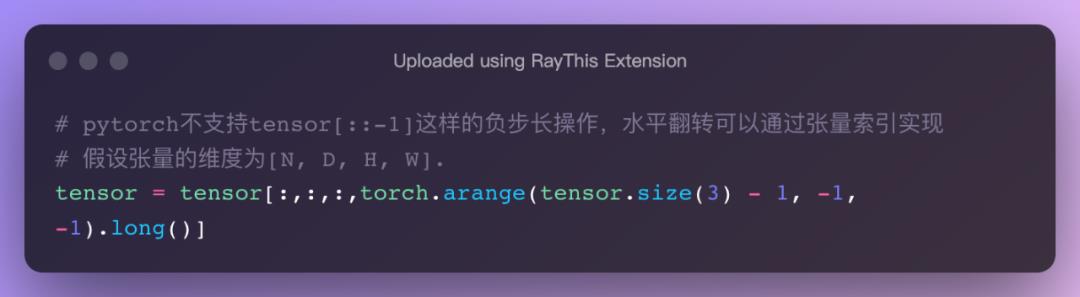
水平翻转
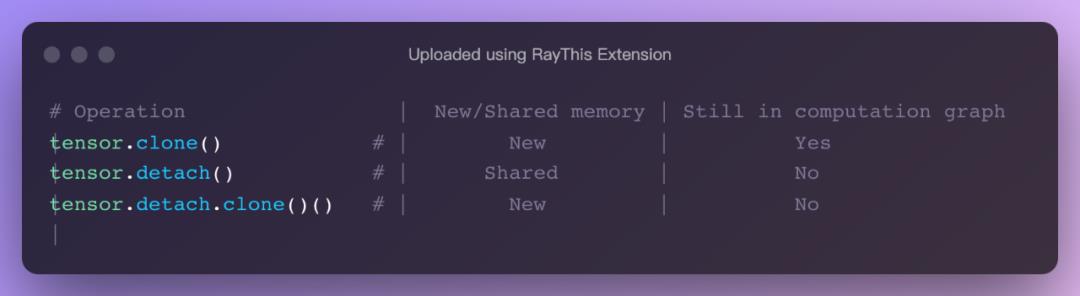
复制张量
张量拼接

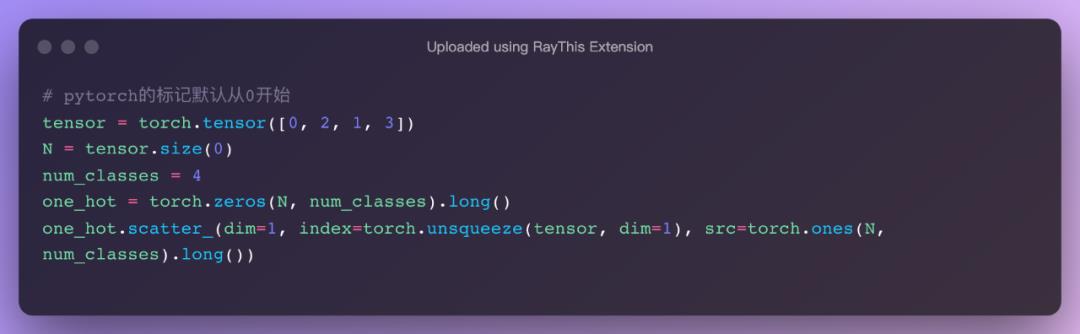
将整数标签转为one-hot编码
得到非零元素

判断两个张量相等

张量扩展

矩阵乘法

计算两组数据之间的两两欧式距离
利用broadcast机制

3. 模型定义和操作
一个简单两层卷积网络的示例

卷积层的计算和展示可以用这个网站辅助。
双线性汇合(bilinear pooling)

多卡同步 BN(Batch normalization)
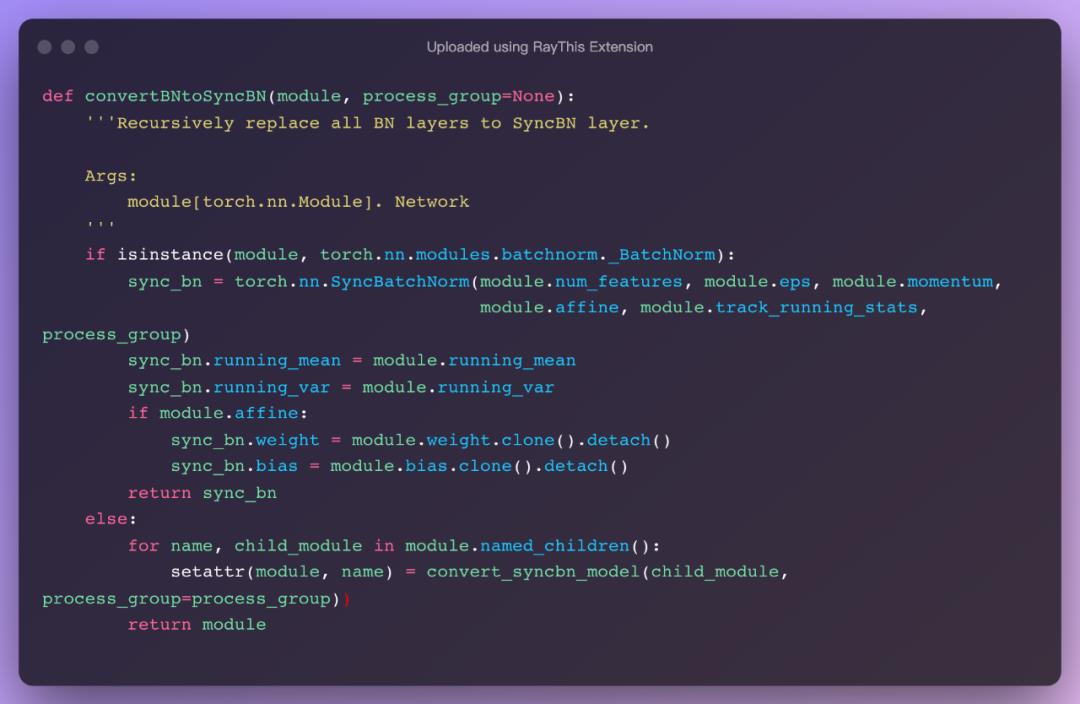
当使用 torch.nn.DataParallel 将代码运行在多张 GPU 卡上时,PyTorch 的 BN 层默认操作是各卡上数据独立地计算均值和标准差,同步 BN 使用所有卡上的数据一起计算 BN 层的均值和标准差,缓解了当批量大小(batch size)比较小时对均值和标准差估计不准的情况,是在目标检测等任务中一个有效的提升性能的技巧。

将已有网络的所有BN层改为同步BN层
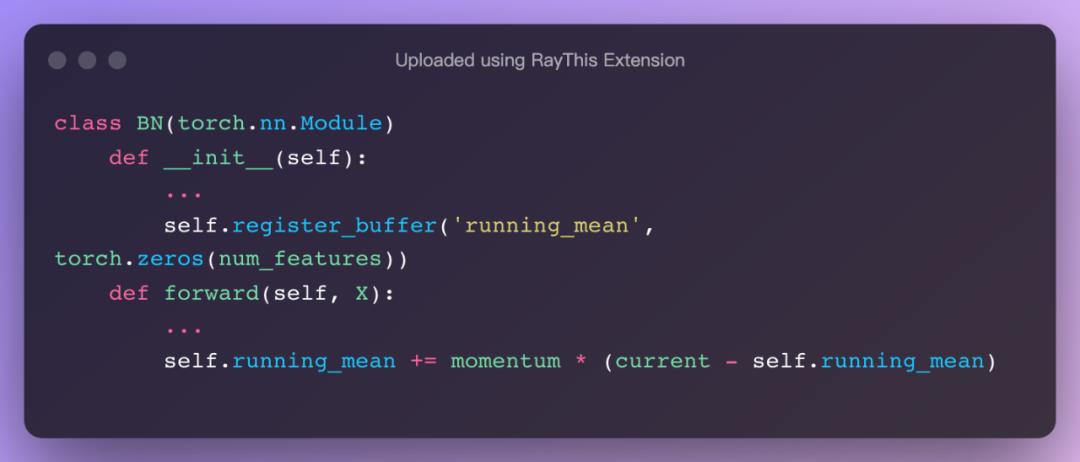
类似 BN 滑动平均
如果要实现类似 BN 滑动平均的操作,在 forward 函数中要使用原地(inplace)操作给滑动平均赋值。
计算模型整体参数量

查看网络中的参数
可以通过model.state_dict()或者model.named_parameters()函数查看现在的全部可训练参数(包括通过继承得到的父类中的参数)

模型可视化(使用pytorchviz)
szagoruyko/pytorchvizgithub.com
类似 Keras 的 model.summary() 输出模型信息,使用pytorch-summary
sksq96/pytorch-summarygithub.com
模型权重初始化
注意 model.modules() 和 model.children() 的区别:model.modules() 会迭代地遍历模型的所有子层,而 model.children() 只会遍历模型下的一层。

提取模型中的某一层
modules()会返回模型中所有模块的迭代器,它能够访问到最内层,比如self.layer1.conv1这个模块,还有一个与它们相对应的是name_children()属性以及named_modules(),这两个不仅会返回模块的迭代器,还会返回网络层的名字。

部分层使用预训练模型
注意如果保存的模型是 torch.nn.DataParallel,则当前的模型也需要是

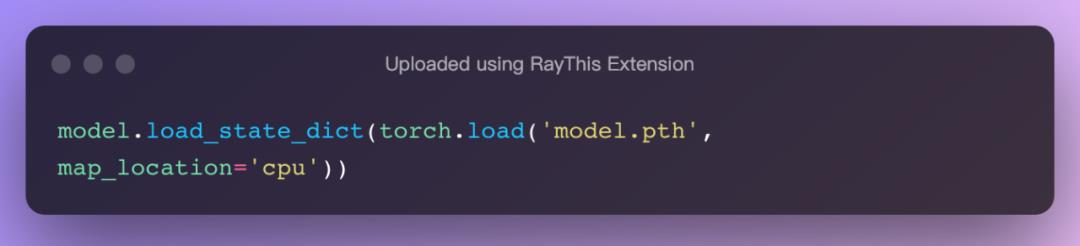
将在 GPU 保存的模型加载到 CPU
导入另一个模型的相同部分到新的模型
模型导入参数时,如果两个模型结构不一致,则直接导入参数会报错。用下面方法可以把另一个模型的相同的部分导入到新的模型中。

4. 数据处理
计算数据集的均值和标准差

得到视频数据基本信息

TSN 每段(segment)采样一帧视频

常用训练和验证数据预处理
其中 ToTensor 操作会将 PIL.Image 或形状为 H×W×D,数值范围为 [0, 255] 的 np.ndarray 转换为形状为 D×H×W,数值范围为 [0.0, 1.0] 的 torch.Tensor。

5. 模型训练和测试
分类模型训练代码

分类模型测试代码

自定义loss
继承torch.nn.Module类写自己的loss。

标签平滑(label smoothing)
写一个label_smoothing.py的文件,然后在训练代码里引用,用LSR代替交叉熵损失即可。label_smoothing.py内容如下:

或者直接在训练文件里做label smoothing

Mixup训练

L1 正则化

不对偏置项进行权重衰减(weight decay)
pytorch里的weight decay相当于l2正则

梯度裁剪(gradient clipping)

得到当前学习率

另一种方法,在一个batch训练代码里,当前的lr是optimizer.param_groups[0]['lr']
学习率衰减

优化器链式更新
从1.4版本开始,torch.optim.lr_scheduler 支持链式更新(chaining),即用户可以定义两个 schedulers,并交替在训练中使用。

模型训练可视化
PyTorch可以使用tensorboard来可视化训练过程。
安装和运行TensorBoard。
pip install tensorboard
tensorboard --logdir=runs使用SummaryWriter类来收集和可视化相应的数据,放了方便查看,可以使用不同的文件夹,比如'Loss/train'和'Loss/test'。

保存与加载断点
注意为了能够恢复训练,我们需要同时保存模型和优化器的状态,以及当前的训练轮数。

提取 ImageNet 预训练模型某层的卷积特征

提取 ImageNet 预训练模型多层的卷积特征

微调全连接层

以较大学习率微调全连接层,较小学习率微调卷积层

6. 其他注意事项
不要使用太大的线性层。因为nn.Linear(m,n)使用的是的内存,线性层太大很容易超出现有显存。
不要在太长的序列上使用RNN。因为RNN反向传播使用的是BPTT算法,其需要的内存和输入序列的长度呈线性关系。
model(x) 前用 model.train() 和 model.eval() 切换网络状态。
不需要计算梯度的代码块用 with torch.no_grad() 包含起来。
model.eval() 和 torch.no_grad() 的区别在于,model.eval() 是将网络切换为测试状态,例如 BN 和dropout在训练和测试阶段使用不同的计算方法。torch.no_grad() 是关闭 PyTorch 张量的自动求导机制,以减少存储使用和加速计算,得到的结果无法进行 loss.backward()。
model.zero_grad()会把整个模型的参数的梯度都归零, 而optimizer.zero_grad()只会把传入其中的参数的梯度归零.
torch.nn.CrossEntropyLoss 的输入不需要经过 Softmax。torch.nn.CrossEntropyLoss 等价于 torch.nn.functional.log_softmax + torch.nn.NLLLoss。
loss.backward() 前用 optimizer.zero_grad() 清除累积梯度。
torch.utils.data.DataLoader 中尽量设置 pin_memory=True,对特别小的数据集如 MNIST 设置 pin_memory=False 反而更快一些。num_workers 的设置需要在实验中找到最快的取值。
用 del 及时删除不用的中间变量,节约 GPU 存储。
使用 inplace 操作可节约 GPU 存储,如

减少 CPU 和 GPU 之间的数据传输。例如如果你想知道一个 epoch 中每个 mini-batch 的 loss 和准确率,先将它们累积在 GPU 中等一个 epoch 结束之后一起传输回 CPU 会比每个 mini-batch 都进行一次 GPU 到 CPU 的传输更快。
使用半精度浮点数 half() 会有一定的速度提升,具体效率依赖于 GPU 型号。需要小心数值精度过低带来的稳定性问题。
时常使用 assert tensor.size() == (N, D, H, W) 作为调试手段,确保张量维度和你设想中一致。
除了标记 y 外,尽量少使用一维张量,使用 n*1 的二维张量代替,可以避免一些意想不到的一维张量计算结果。
统计代码各部分耗时

使用TorchSnooper来调试PyTorch代码,程序在执行的时候,就会自动 print 出来每一行的执行结果的 tensor 的形状、数据类型、设备、是否需要梯度的信息。

https://github.com/zasdfgbnm/TorchSnoopergithub.com
模型可解释性,使用captum库:https://captum.ai/captum.ai
参考资料
张皓:PyTorch Cookbook(常用代码段整理合集),https://zhuanlan.zhihu.com/p/59205847?
PyTorch官方文档和示例
https://pytorch.org/docs/stable/notes/faq.html
https://github.com/szagoruyko/pytorchviz
https://github.com/sksq96/pytorch-summary
其他
觉得还不错就给我一个小小的鼓励吧!以上是关于PyTorch常用代码段合集的主要内容,如果未能解决你的问题,请参考以下文章