python 期末复习笔记(持续更新)
Posted 温欣'
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 期末复习笔记(持续更新)相关的知识,希望对你有一定的参考价值。
文章目录
- 1、set
- 2、union
- 3、axis=0 与 axis=1
- 4、ascending=False 与 reverse=False
- 5、set_index和reset_index
- 6、json自定义函数提取数据
- 7、apply 与lambda
- 8、join
- 9、append
- 10、merge
- 11、combine_first
- 12、concatenate
- 13、concat
- 14、groupby
- 15、values()与itervalues()
- 16、value_counts
- 17、sort 与sort_values
- 18、open
- 19、read_cav与to_csv
- 20、remove
- 21、series
- 22、DF的表头columns和index
- 23、字典
- 24、字典函数values(),keys(),items()
- 25、切片loc和iloc
- 26、DataFrame
- 27、shape与reshape
- 28、替换函数strip(),replace(),sub()
- 29、toarray
- 30、unique
- 31、isnull和notnull
- 32、rename
- 33、linespace
- 34、日期转换
- 35、lambda 匿名函数
- 36、正则表达式
- 29、column_stack与hstack、vstack
- 30、contains
- 31、split
- 32、np.repeat
- 33、期末考会考题
- 34、Sklearn的train_test_split用法
- 34、过拟合与欠拟合
- 35、oversample 过采样和欠采样undersampling
- 36、分类阈值
- 37、超参数
- 38、随机森林
- 39、 cut和qcut的用法(分桶分箱)
- 40、随机森林 n_estimators参数 max_features参数
- 41、VarianceThreshold
- 42、fit_transform,fit,transform区别和作用
- 43、特征预处理的独热编码
- 44、ravel和flattern
1、set
set 是一个不允许内容重复的组合,而且set里的内容位置是随意的,所以不能用索引列出。可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。

创建一个空集合必须用 set() 而不是 ,因为 是用来创建一个空字典。

2、union
union 取并集,效果等同于 | ,重复元素只会出现一次,但是括号里可以是 list,tuple, 甚至是 dict


同样uninon也不能用索引列出:
#TypeError: 'set' object is not subscriptable
#表示把不具有下标操作的集合对象用成了对象[i]
genres_list=set() # 获取所有的电影风格
for i in moviesdf['genresls'].str.split(' '):
genres_list=set().union(i,genres_list)
# 集合(set)是一个无序的不重复元素序列。可以使用大括号 或者 set() 函数创建集合。
genres_list=list(genres_list)
genres_list
genres_list.remove('') # 去除空的元素
print(genres_list)
得到的结果:所有电影风格类型
['Movie', 'Documentary', 'Comedy', 'Crime', 'Fantasy', 'History', 'Drama', 'Horror', 'Action', 'War', 'Foreign', 'Thriller', 'Fiction', 'Animation', 'Science', 'Music', 'Western', 'Romance', 'Family', 'TV', 'Mystery', 'Adventure']
3、axis=0 与 axis=1

例子一:

例子二: 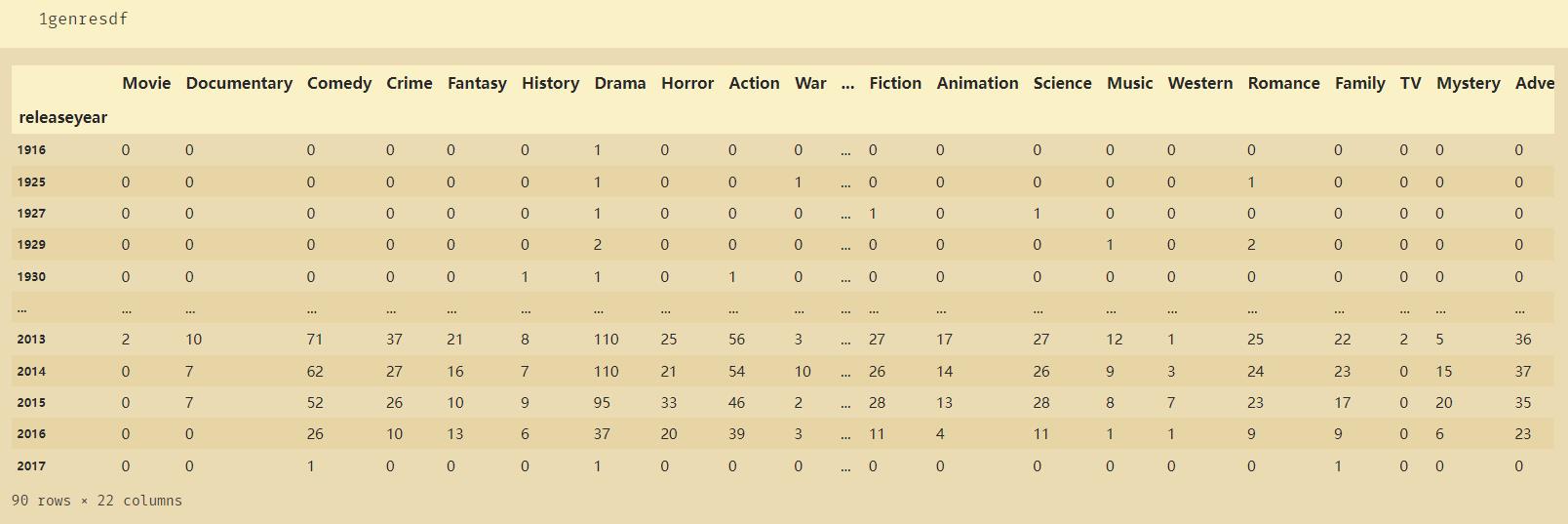


4、ascending=False 与 reverse=False
ascending与reverse刚好是相反的
ascending=False:降序
ascending=True:升序
reverse=False:升序
reverse=True:降序




5、set_index和reset_index
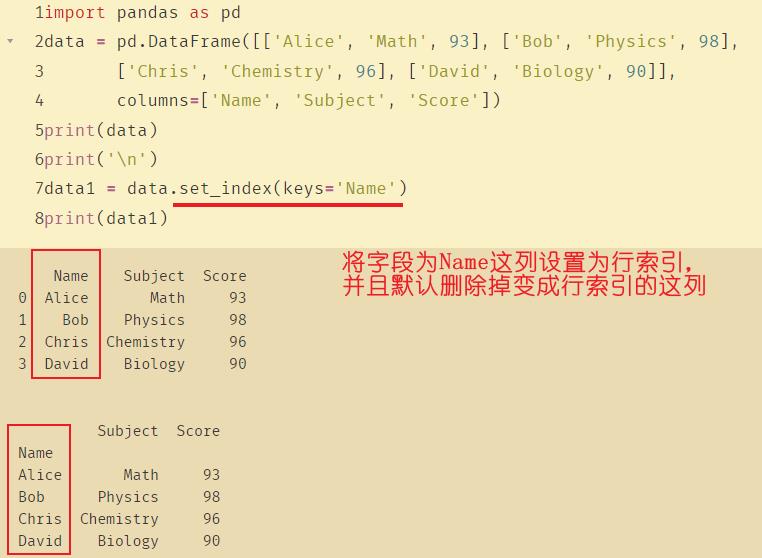
set_index( ) 将 DataFrame 中的指定的列转化为行索引。
- set_index( ) 将 DataFrame 中的列转化为行索引。
- keys : 要设置为索引的列名(如有多个应放在一个列表里)
- drop : 将设置为索引的列删除,默认为True
- append : 是否将新的索引追加到原索引后(即是否保留原索引),默认为False
- inplace : 是否在原DataFrame上修改,默认为False
- verify_integrity : 是否检查索引有无重复,默认为False
import pandas as pd
data = pd.DataFrame([['Alice', 'Math', 93], ['Bob', 'Physics', 98], ['Chris', 'Chemistry', 96], ['David', 'Biology', 90]],
columns=['Name', 'Subject', 'Score'])
print(data)
print('\\n')
data1 = data.set_index(keys='Name')
print(data1)
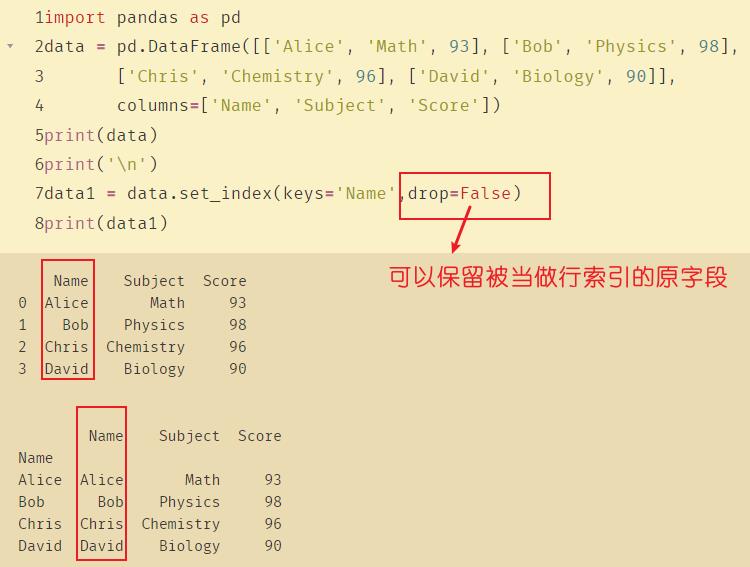
reset_index可以还原索引,从新变为默认的整型索引
6、json自定义函数提取数据
#对于json格式的数据进行分割提取,通过自定义函数
def decode(column):
z=[]
for i in column:
z.append(i['name'])
return ' '.join(z)
# 获取dict中第一个元素的name值
def decode1(column):
z=[]
for i in column:
z.append(i['name'])
return ''.join(z[0:1]) #切片,只输出第一个分隔
# 获取演员列表,中间使用逗号分隔
def decodeactors(column):
z=[]
for i in column:
z.append(i['name'])
return ','.join(z) #切片,只输出第一个分隔
# 获取演员列表的前两位
def decode2(column):
z=[]
for i in column:
z.append(i['name'])
return ','.join(z[0:2]) #切片,只输出第一个分隔
# 获取电影风格数据
moviesdf['genresls']=moviesdf['genreslist'].apply(decode)
# 获取演员列表
moviesdf['actorsls']=moviesdf['castlist'].apply(decodeactors)
# 获取前两位演员
moviesdf['actorsn0102']=moviesdf['castlist'].apply(decode2)
# 获取第一位演员
moviesdf['actorsn01']=moviesdf['castlist'].apply(decode1)
# 获取制片的第一个国家或者地区
moviesdf['region']=moviesdf['countries'].apply(decode1)
7、apply 与lambda
apply通常与lambda一起使用
lambda原型为:lambda 参数:操作(参数)
lambda函数也叫匿名函数,即没有具体名称的函数,它允许快速定义单行函数,可以用在任何需要函数的地方。这区别于def定义的函数。
lambda与def的区别:
1)def创建的方法是有名称的,而lambda没有。
2)lambda会返回一个函数对象,但这个对象不会赋给一个标识符,而def则会把函数对象赋值给一个变量(函数名)。
3)lambda只是一个表达式,而def则是一个语句。
4)lambda表达式后面,只能有一个表达式,def则可以有多个。
5)像if或for或print等语句不能用于lambda中,def可以。
6)lambda一般用来定义简单的函数,而def可以定义复杂的函数。
#单个参数的:
g = lambda x : x ** 2
print g(3)
"""
9
"""
#多个参数的:
g = lambda x, y, z : (x + y) ** z
print g(1,2,2)
"""
9
"""
例子二:
# 将一个 list 里的每个元素都平方:
map( lambda x: x*x, [y for y in range(10)] )
这个写法要好过:
def sq(x):
return x * x
map(sq, [y for y in range(10)])
8、join
9、append
10、merge
pandas.merge的报错:MergeError: No common columns to perform merge on.
原因:没有共同的列来进行融合,则会报错
因为merge函数默认需要提供相同的列来进行融合,如果没有的话可以通过设置left_index和right_index=True来融合所有的列
解决:指定让两个df的索引相同来进行融合df.merge(s,left_index=True,right_index=True)
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
left:拼接的左侧DataFrame对象right:拼接的右侧DataFrame对象on:用于连接的列名。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。left_on:左侧DataFrame中用于连接键的列。right_on:左侧DataFrame中用于连接键的列。left_index:左侧DataFrame中行索引作为连接键right_index:右侧DataFrame中行索引作为连接键how:有五种参数(inner,left,right,outer,cross) 默认inner。inner是取交集,outer取并集。left是包含左边的全部数据,如果右边没有相应的数据则使用NAN填充。right是包含右边的全部数据,如果左边没有则使用NAN值填充。cross表示将左右两个DataFrame进行笛卡尔积。两个数据框的数据交叉匹配,行数为两者相乘,列数为两者相加。sort:按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。suffixes:修改重复列名。(可指定我们自己想要的后缀)
import pandas as pd
price=pd.DataFrame('fruit':['apple','grape','orange','orange'],'price':[8,7,9,11])
amount=pd.DataFrame('fruit':['apple','grape','orange','banana'],'amount':[1,2,2,3])
display(price,amount,pd.merge(price,amount))
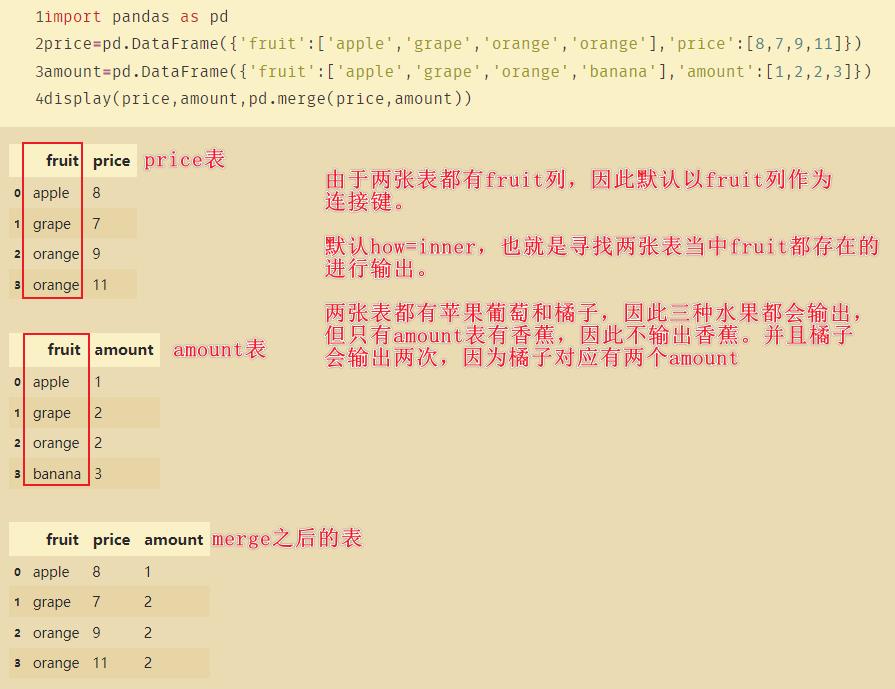
pd.merge(price,amount)等价于pd.merge(price,amount,on='fruit',how='inner')

import pandas as pd
df1=pd.DataFrame('name1':['小1','小2','小3','小4'],'age':[25,28,39,35])
df2=pd.DataFrame('name2':['小1','小2','小4'],'score':[70,60,90])
display(df1,df2,pd.merge(df1,df2))
上面这段代码报错:
原因在于df1使用的是name1,df2使用的是name2。两张表当中没有相同的字段。这种情况下就必须指定left_on,和right_on。
MergeError: No common columns to perform merge on. Merge options: left_on=None, right_on=None, left_index=False, right_index=False




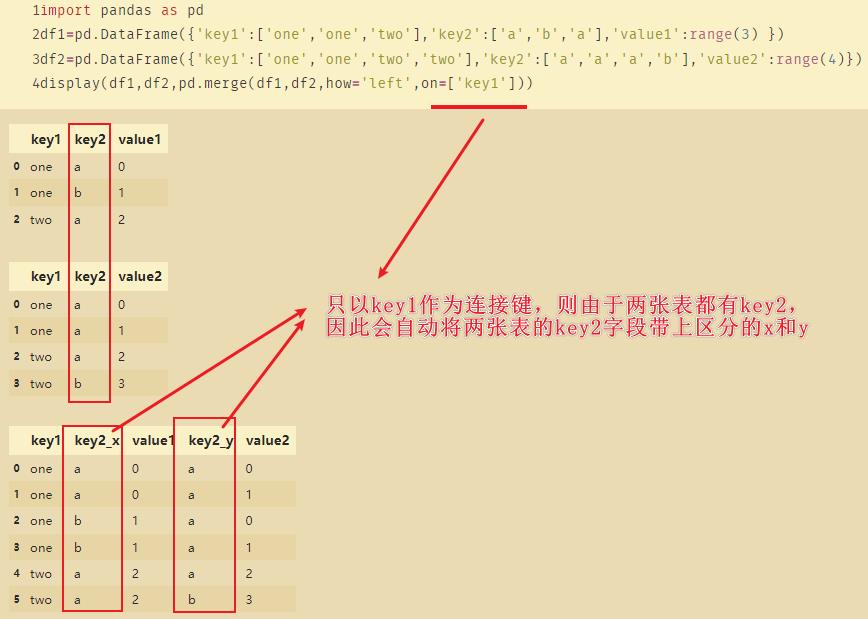

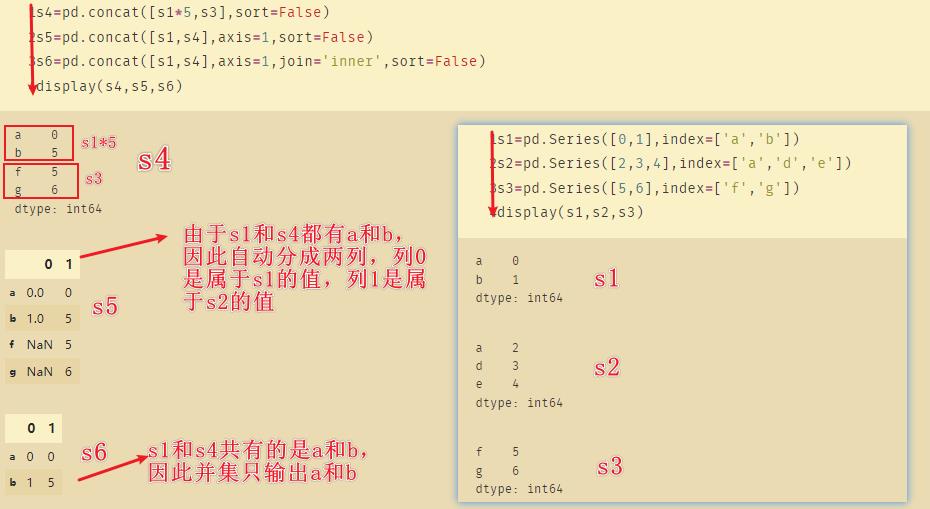
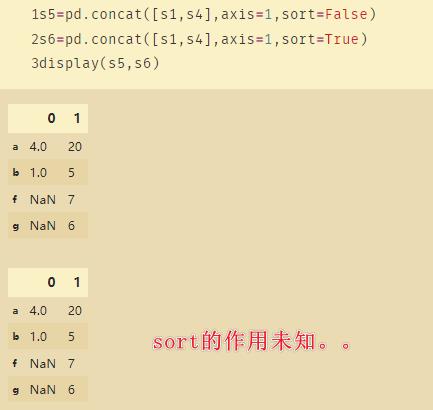
11、combine_first

如上图是S5和S6,两者存在重复的索引f和g,此时使用merge和concat都无法正确的合并,因此使用combine_first。

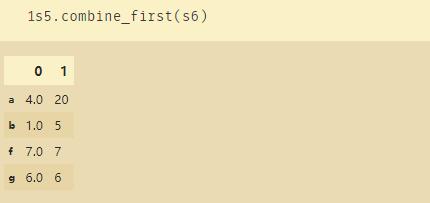
如上图combine_first可以去除重复的索引值,原因在于s5.combine_first(s6)表示的是使用s6去填充s5的缺失值。
12、concatenate
numpy提供了numpy.concatenate((a1,a2,…), axis=0)函数。能够一次完成多个数组的拼接。其中a1,a2,…是数组类型的参数
>>> a=np.array([1,2,3])
>>> b=np.array([11,22,33])
>>> c=np.array([44,55,66])
>>> np.concatenate((a,b,c),axis=0) # 默认情况下,axis=0可以不写
array([ 1, 2, 3, 11, 22, 33, 44, 55, 66]) #对于一维数组拼接,axis的值不影响最后的结果
>>> a=np.array([[1,2,3],[4,5,6]])
>>> b=np.array([[11,21,31],[7,8,9]])
>>> np.concatenate((a,b),axis=0)
array([[ 1, 2, 3],
[ 4, 5, 6],
[11, 21, 31],
[ 7, 8, 9]])
>>> np.concatenate((a,b),axis=1) #axis=1表示对应行的数组进行拼接
array([[ 1, 2, 3, 11, 21, 31],
[ 4, 5, 6, 7, 8, 9]])
numpy.append()和numpy.concatenate()相比,concatenate()效率更高,适合大规模的数据拼接
13、concat
如果要合并的DataFrame之间没有连接键,就无法使用merge方法,此时可以使用concat方法,把两个完全无关的数据拼起来。
concat方法相当于数据库中的全连接(UNION ALL),可以指定按某个轴进行连接,也可以指定连接的方式join(outer,inner 只有这两种)。
与数据库不同的是concat不会去重,要达到去重的效果可以使用drop_duplicates方法
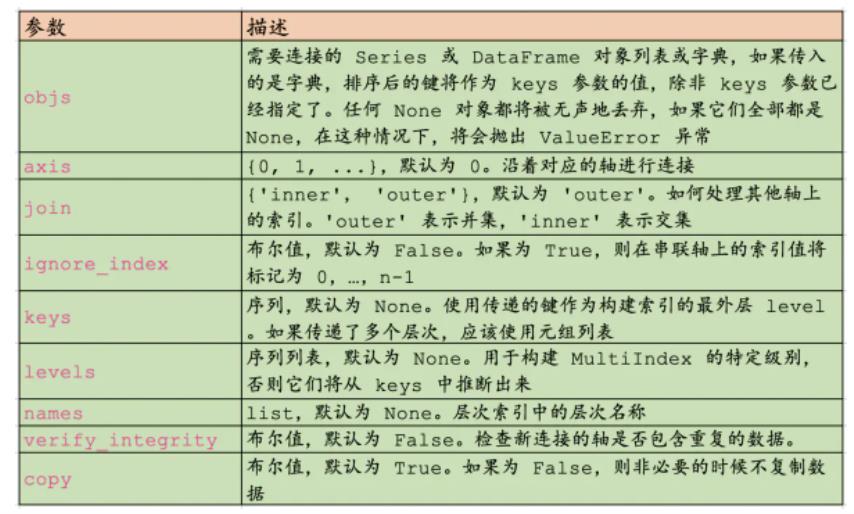
concat(
objs, axis=0, join='outer', join_axes=None,
ignore_index=False, keys=None, levels=None, names=None,
verify_integrity=False, copy=True
)
df1 = DataFrame('a1': ['Chicago', 'San Francisco', 'New York City'], 'rank': range(1, 4))
df2 = DataFrame('a2': ['Chicago', 'Boston', 'Los Angeles'], 'rank': [1, 4, 5])
pd.concat([df1,df2])
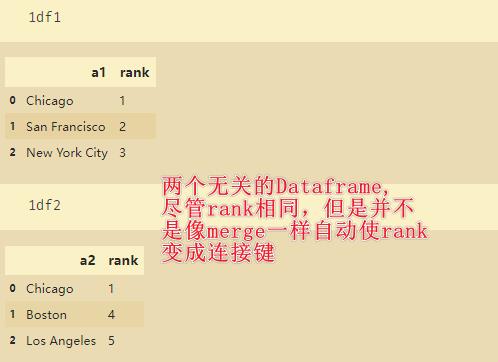

从上面的结果可以看出,concat的连接方式是外连接(并集),通过传入join=‘inner’可以实现内连接。

winedf=pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
14、groupby
groupby:可以根据索引或字段对数据进行分组。
DataFrame.groupby(by=None,axis=0,level=None,as_index=True,sort=True,group_keys=True,squeeze=False)
| by | 可以传入函数、字典、Series等,用于确定分组的依据 |
|---|---|
| axis | 接收int,表示操作的轴方向,默认为0 |
| level | 接收int或索引名,代表标签所在级别,默认为None |
| as_index | 接收boolean,表示聚合后的聚合标签是否以 DataFrame索引输出 |
| sort | 接收boolean,表示对分组依据和分组标签排序,默认为True |
| group_keys | 接收boolean,表示是否显示分组标签的名称,默认为True |
| squeeze | 接收boolean ,表示是否在允许情况下对返回数据降维,默认为False |
对于by,如果传入的是一个函数,则对索引进行计算并分组;如果传入的是字典或者Series,则用字典或者Series的值作为分组的依据;如果传入的是numpy数组,则用数据元素作为分组依据‘如果传入的是字符串或者字符串列表,则用这些字符串所代表的字段作为分组依据。


15、values()与itervalues()
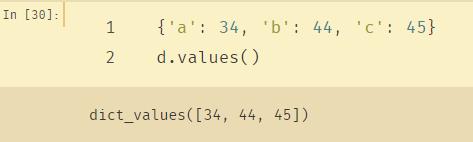
1、values():
python内置的values()函数返回一个字典中所有的值。
即只返回key0:value0,key1:value1中的value0、value1……
并且重复值都会返回


- values() 方法把一个 dict 转换成了包含 value 的list。
- itervalues() 方法不会转换,它会在迭代过程中依次从 dict 中取出 value,所以 itervalues() 方法比 values() 方法节省了生成 list 所需的内存。
- 打印 itervalues() 发现它返回一个对象,这说明在Python中,for 循环可作用的迭代对象远不止 list,tuple,str,unicode,dict等,任何可迭代对象都可以作用于for循环,而内部如何迭代我们通常并不用关心。
16、value_counts
pandas 的value_counts()函数可以对Series里面的每个值进行计数并且排序。
如果我们想知道,每个区域出现了多少次,可以简单如下:

每个区域都被计数,并且默认从最高到最低做降序排列。
如果想用升序排列,可以加参数ascending=True:

如果想得出的计数占比,可以加参数normalize=True:
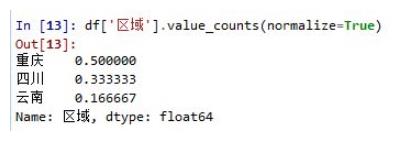
空值是默认剔除掉的。value_counts()返回的结果是一个Series数组,可以跟别的数组进行运算。
例子二:结合分桶函数cut
ages = [20,22,25,27,21,23,37,31,61,45,41,32]
#将所有的ages进行分组
bins = [18,25,35,60,100]
#使用pandas中的cut对年龄数据进行分组
cats = pd.cut(ages,bins)
print(cats)
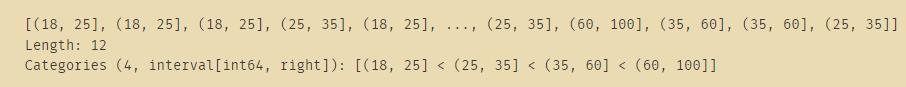
#调用pd.value_counts方法统计每个区间的个数
number=pd.value_counts(cats)
print(pd.value_counts(cats))

17、sort 与sort_values
sorted(iterable[, cmp[, key[, reverse]]])
iterable.sort(cmp[, key[, reverse]])
参数解释:
(1)iterable指定要排序的list或者iterable,不用多说;
(2)cmp为函数,指定排序时进行比较的函数,可以指定一个函数或者lambda函数,如:
students为类对象的list,每个成员有三个域,用sorted进行比较时可以自己定cmp函数,例如这里要通过比较第三个数据成员来排序,代码可以这样写:
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
sorted(students, key=lambda student : student[2])

(3)key为函数,指定取待排序元素的哪一项进行排序,函数用上面的例子来说明,代码如下:
sorted(students, key=lambda student : student[2])
key指定的lambda函数功能是去元素student的第三个域(即:student[2]),因此sorted排序时,会以students所有元素的第三个域来进行排序。

18、open
open(file, mode='r')
以上是关于python 期末复习笔记(持续更新)的主要内容,如果未能解决你的问题,请参考以下文章