带你整理面试过程中关于数据库范式,事务,并发策略和锁的相关知识点
Posted 南淮北安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你整理面试过程中关于数据库范式,事务,并发策略和锁的相关知识点相关的知识,希望对你有一定的参考价值。
文章目录
一、数据库三范式
范式是具有最小冗余的表结构
1. 第一范式
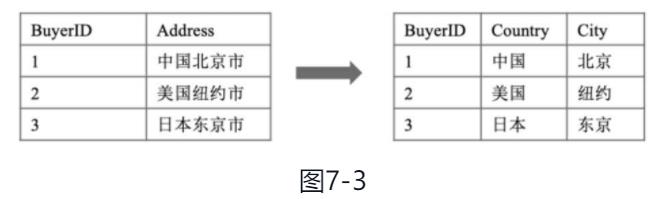
如果每列都是不可再分的最小数据单元(也叫作最小的原子单元),则满足第一范式,第一范式的目标是确保每列的原子性
如图7-3所示,其中的Address列违背了第一范式列不可再分的原则,要满足第一范式,就需要将Address列拆分为Country列和City列。
2. 第二范式
第二范式在第一范式的基础上,规定表中的非主键列不存在对主键的部分依赖,即第二范式要求每个表只描述一件事情。
如图7-4所示,Orders表既包含订单信息,也包含产品信息,需要将其拆分为两个单独的表。

3. 第三范式
第三范式的定义为:满足第一范式和第二范式,并且表中的列不存在对非主键列的传递依赖。
如图7-5所示,除了主键的订单编号,顾客姓名依赖于非主键的顾客编号,因此需要将该列去除。

二、数据库事务
1. 数据库四大特性
数据库事务执行一系列基本操作,这些基本操作组成一个逻辑工作单元一起向数据库提交,要么都执行,要么都不执行。
事务是一个不可分割的工作逻辑单元。事务必须具备以下4个属性,简称ACID属性。
原子性: 原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。失败回滚的操作事务,将不能对事物有任何影响。
原子性是基于 undo log 实现的
一致性: 一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
一致性:是依靠原子性、隔离性、持久性实现的,也就是原子性、隔离性、持久性是手段,一致性是目的
隔离性: 隔离性是指当多个用户并发访问数据库时,比如同时访问一张表,数据库每一个用户开启的事务,不能被其他事务所做的操作干扰,多个并发事务之间,应当相互隔离。
隔离性是基于undo log实现的,具体是依赖于 MVCC
持久性: 持久性是指事务的操作,一旦提交,对于数据库中数据的改变是永久性的,即使数据库发生故障也不能丢失已提交事务所完成的改变。
持久性是依赖于 redo log 实现的
2. 数据库并发操作可能会引起的问题
- 脏读:脏读是指一个事务读取了未提交事务执行过程中的数据。
当一个事务的操作正在多次修改数据,而在事务还未提交的时候,另外一个并发事务来读取了数据,就会导致读取到的数据并非是最终持久化之后的数据,这个数据就是脏读的数据。
- 不可重复读:不可重复读是指对于数据库中的某个数据,一个事务执行过程中多次查询返回不同查询结果,这就是在事务执行过程中,数据被其他事务提交修改了。
不可重复读同脏读的区别在于,脏读是一个事务读取了另一未完成的事务执行过程中的数据,而不可重复读是一个事务执行过程中,另一事务提交并修改了当前事务正在读取的数据。
- 虚读(幻读):幻读是事务非独立执行时发生的一种现象,例如事务T1批量对一个表中某一列列值为1的数据修改为2的变更,但是在这时,事务T2对这张表插入了一条列值为1的数据,并完成提交。此时,如果事务T1查看刚刚完成操作的数据,发现还有一条列值为1的数据没有进行修改,而这条数据其实是T2刚刚提交插入的,这就是幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点同脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
3. 数据库的隔离机制
在mysql的众多存储引擎中,只有InnoDB支持事务,所有这里说的事务隔离级别指的是InnoDB下的事务隔离级别。
在MySQL中,默认的隔离级别是REPEATABLE-READ(可重复读),mysql的默认隔离级别解决了脏读、幻读、不可重复读问题。
(1)未提交读(Read Uncommitted)
自定义名称:修改级别隔离(只要修改了数据,则其他事务就可以看到)
可以理解为:A事务只要修改了数据,无论有没有提交,其他事务都能够读取到A事务修改后的结果。
潜在问题【对于同一记录进行修改操作】:A事务修改之后未提交,B事务读取到修改之后的数据,然后在这个基础上进行操作修改并提交。然后A提交失败,数据回滚,则数据就出现异常。这就是所谓的脏读。
解决方案:A事务提交之后B事务才能读取到A修改之后的数据,不让读取修改但未提交的数据
(2)提交读(Read Committed)
自定义名称:提交级别隔离(只有成功提交事务,则其他事务才能够看到)
可以理解为:A事务成功commit之后,其他事务才能够读取到A提交事务之后的最新数据,否则只能读取到A提交之前的原始数据。这样就解决了脏读问题。
潜在问题【对于同一记录进行修改操作】:A事务开启第一次读取数据,然后B事务开启对数据进行了修改并提交成功, 此时A事务还没有结束,又进行了一次读操作,然后便发现A事务中的两次读取的数据不一致。这就是所谓的不可重复读。同一个事务中两次读取的数据不一样。
解决方案:在一个事务对该行数据进行操作的时候,其他事务不允许进行修改。可以理解为添加一个行级别的锁
(3)可重复读(Repeatable Read):
自定义名称:事务级别隔离(一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的)
可以理解为:事务启动的时候就 “拍了个快照”,这样之后的获取数据都是根据这个快照来获取。但是也存在一个问题,就是无法看到其他事务之后对已有记录的更新。对于此隔离机制无法解决这个问题,需要使用行级锁来进行处理。
具体的实现是通过MVCC(多版本并发控制),为每行记录添加了一个版本号,每当修改数据时,版本号加一。在读取事务时,系统会给事务一个当前版本号,事务会读取版本号小于等于当前版本号的数据,这时就算另一个事务插入一个数据,并立马提交,新插入的这条数据的版本号会比读取事务的版本号高,因此读取事务读的数据还是不会变。
总结:快照机制+版本链
潜在问题【对于同表进行插入或删除操作】:A事务插入/删除了一条记录,但是B事务中却查询不到插入的新记录/依旧能查到删除的记录。这就是所谓的幻读。幻读是对于记录条数而言的,不是针对于某一条记录的数据而言的。这里需要注意!
解决方案:在有事务对该表进行操作的时候,不允许其他事务操作该表。添加表级锁。
(4)串行读(Serializable):
自定义名称:表级别隔离(不允许同时有多个事务操作该表)
可以理解为:所有的事务串行操作该数据表。这样就可以解决幻读操作。
潜在问题:数据安全了 但是操作效率降低了。
三 、数据库的并发策略
数据库的并发控制一般采用三种方法实现,分别是乐观锁、悲观锁及时间戳。
1. 乐观锁
乐观锁,如它的名字那样,总是认为别人不会去修改,只有在提交更新的时候去检查数据的状态。通常是给数据增加一个字段来标识数据的版本。
2. 悲观锁
悲观锁指在其修改某条数据时,不允许别人读取该数据,直到自己的整个事务都提交并释放锁,其他用户才能访问该数据。悲观锁又可分为排它锁(写锁)和共享锁(读锁)。
3. 时间戳
版本号
时间戳指在数据库表中额外加一个时间戳列TimeStamp。每次读数据时,都把时间戳也读出来,在更新数据时把时间戳加1,在提交之前跟数据库的该字段比较一次,如果比数据库的值大,就允许保存,否则不允许保存。这种处理方法虽然不使用数据库系统提供的锁机制,但是可以大大提高数据库处理的并发量。
四、数据库锁
1. 为什么要引入数据库锁?
多个用户同时对数据库的并发操作时会带来以下数据不一致的问题:
-
丢失更新 :A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统
-
脏读 :A用户修改了数据,随后B用户又读出该数据,但A用户因为某些原因取消了对数据的修改,数据恢复原值,此时B得到的数据就与数据库内的数据产生了不一致
-
不可重复读 :A用户读取数据,随后B用户读出该数据并修改,此时A用户再读取数据时发现前后两次的值不一致
并发控制的主要方法是封锁,锁就是在一段时间内禁止用户做某些操作以避免产生数据不一致
2. 行级锁
行级锁指对某行数据加锁,是一种排他锁,防止其他事务修改此行。在执行以下数据库操作时,数据库会自动应用行级锁。

3. 表级锁
表级锁指对当前操作的整张表加锁,它的实现简单,资源消耗较少,被大部分存储引擎支持。最常使用的MyISAM与InnoDB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
4. 页级锁
页级锁的锁定粒度介于行级锁和表级锁之间。表级锁的加锁速度快,但冲突多,行级冲突少,但加锁速度慢。页级锁在二者之间做了平衡,一次锁定相邻的一组记录。
六、面试题
- SQL 了解吗?SQL 里面的锁?(华为)
- 数据库的隔离机制?(华为)
- 对数据库了解吗?(华为)
- 数据库如何保证并发安全?(阿里)
 阅读世界,共赴山海
阅读世界,共赴山海
 423全民读书节,邀你共读
423全民读书节,邀你共读
以上是关于带你整理面试过程中关于数据库范式,事务,并发策略和锁的相关知识点的主要内容,如果未能解决你的问题,请参考以下文章