MIT6.824-lab1-2022篇(万字推导思路及代码构建)
Posted 幸平xp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MIT6.824-lab1-2022篇(万字推导思路及代码构建)相关的知识,希望对你有一定的参考价值。
文章目录
前言
为了学这个lab1也是踩了很多坑…记录下此篇是希望让我自己的学习不只是走马观花一遍而过,也是给对Lab1一点头绪都没的小白提供一个理解的方式。希望后来者还是要有自己的思考,去完成这个lab1会对自己收获帮助比较大。对于完整代码文末提供了代码gitee地址。
一、背景知识
- 首先是对go语言的学习这里提供几个学习方式:
推荐先大概看一遍文档,然后韩顺平老师那部分主要看260多集管道并发那部分,讲的还是挺好的。
- 接着就是2004年那篇关于MapReduce第3节要看一遍,理解MapReduce的机制。这里对于读paper能力不好的提供一个中翻链接,以及b站学习视频。强推下方MapReduce的理解视频!!!简短且易懂
以及我认为课程开篇Introduction也是很重要的,在我看来已经有点相当于课上写的笔记+框架介绍,以及能让你对分布式的理解再加深一些。
二、搭建实验环境
因为go语言的插件编译需要,所以6.824的环境是需要在mac或者linux上完成。笔者是选择了ubuntu20.04在golang上进行。关于这个教程,可以看笔者写的另外一篇博客:2022-linux(ubuntu20.04)下go语言环境配置,以及goland安装。
最好使用sdk1.16,因为1.18差1.15是最多的,实验室用的是1.15,但是1.15不能进行调试,1.16才支持,选个相近的sdk以防导致插件导入等编译错误。
- 接着就是通过命令行终端,按照官方实验文档那样把实验拉下来:
git clone git://g.csail.mit.edu/6.824-golabs-2022 6.824
- 然后可以先通过命令行跑一遍一个提供的非并行版mrsequential.go:
cd 6.824
cd src/main
# 将wc.go编译成插件形式,生成wc.so
go build -race -buildmode=plugin ../mrapps/wc.go
rm mr-out*
# 进行并发检测,并将编译后生成的wc.so插件,以参数形式加入mrsequential.go,并运行
go run -race mrsequential.go wc.so pg*.txt
# 查看生成的文件
more mr-out-0
- 如果跑通的话会在命令行输出文本单词的出现次数。

当然我们既然搭建了goland,那么就可以好好利用下集成环境。
- 先在src/main 底下创建脚本sh文件:wc-build.sh

# 进行并发检测,并将编译后生成的wc.so插件,以参数形式加入mrsequential.go,并运行
go build -race -buildmode=plugin ../mrapps/wc.go
# 删除生成的mr-out*以免每次第二次运行得先删除
#rm mr-out*
- 然后配置mrsequential.go:
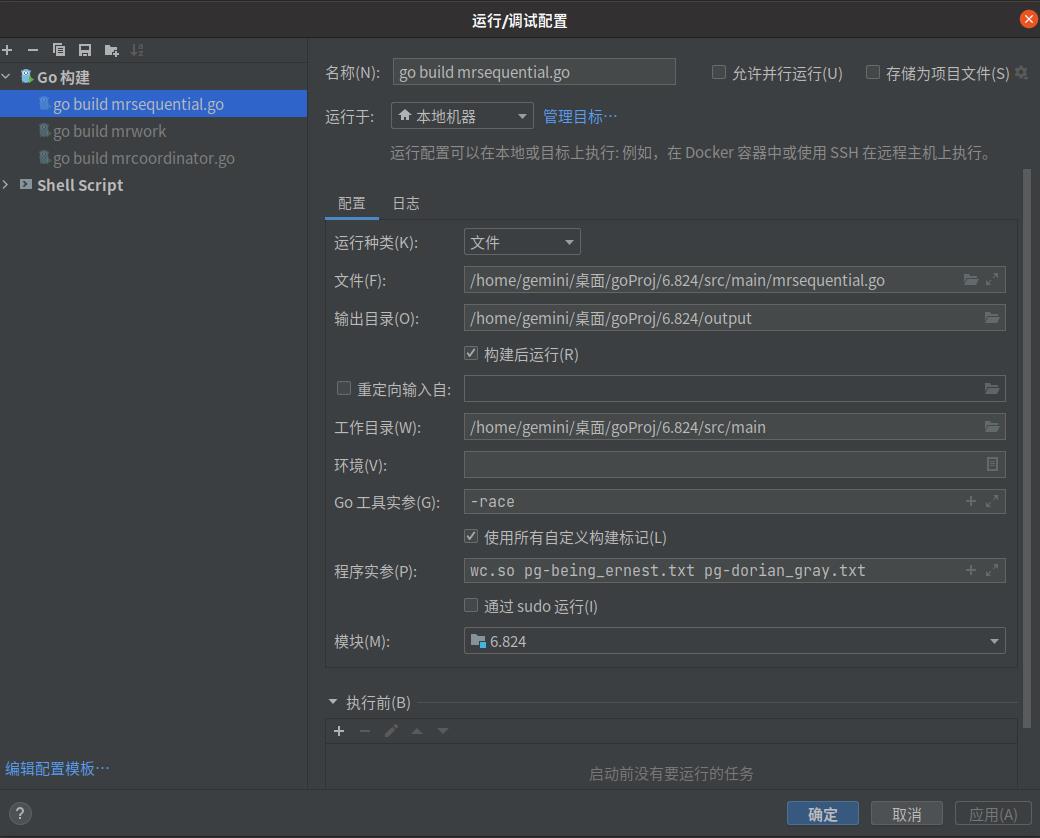
以后启动就可以先启动wc-build.sh,然后再运行mrsequential.go。当然也可以直接在红框部分直接提添加运行shell脚本,但是会有报插件运行错误的风险。这种情况就把生成的wc.so 以及结果文本文件都删了,重新来过,最稳的就是命令行运行。

要注意一点的是程序实参的传入的txt,不能是*这种的匹配符,以golang运行这种实参不会进行自动匹配。 所以参数mrcoordinator应该为以下文件名:
pg-being_ernest.txt pg-dorian_gray.txt pg-frankenstein.txt pg-grimm.txt pg-huckleberry_finn.txt pg-metamorphosis.txt pg-sherlock_holmes.txt pg-tom_sawyer.txt
-
mrcoordinator配置:
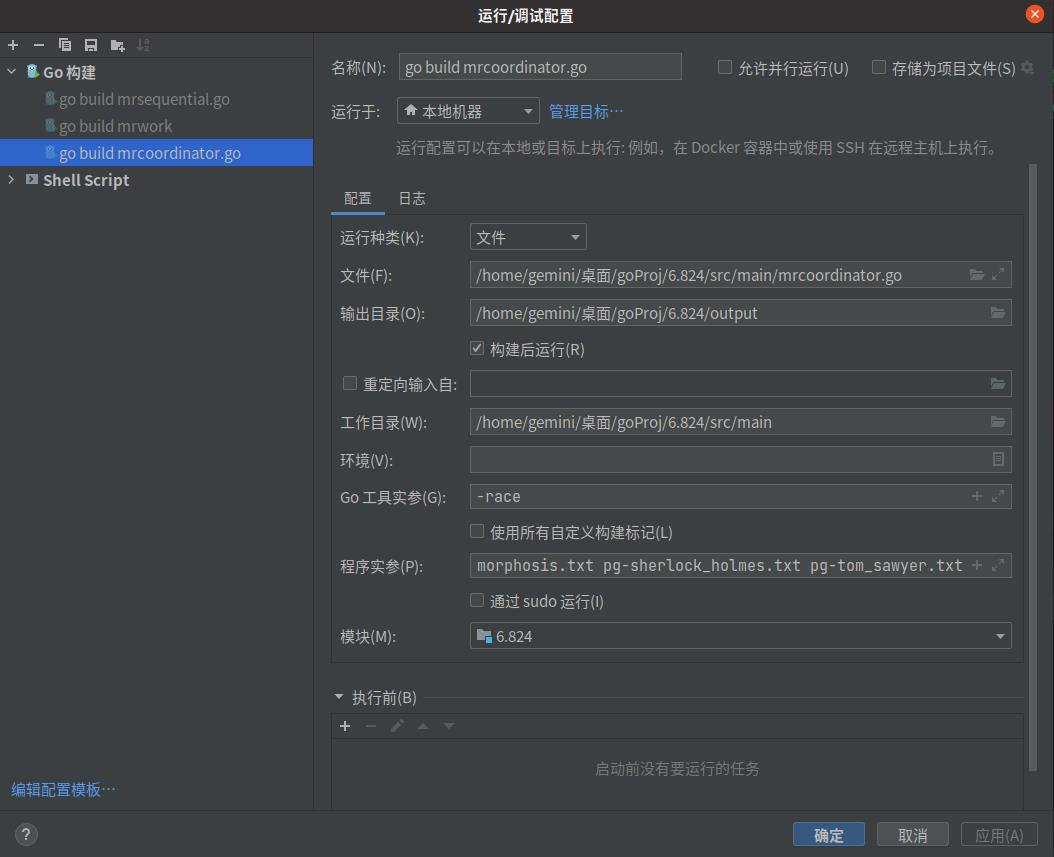
-
mrwork配置:

-
对于笔者来说一般是mrcoordinator通过golang运行或者调试,mrworker每次在命令行重现编译插件后运行,利用fmt打印输出体验较佳!!!(因为因为wc.go编译在golang中运行实在是给跪了orz…)
三、lab正文
1.提示
前置工作差不多就这些,然后给出一些官方文档以及自己觉得重要的提示:
- 对于调试最重要的还是fmt打印输出!!!!比golang调试方便的多(很重要再提一遍!!!)
- 每次变更mr包下代码的时候最好重新编译wc.go,以防编译报找不到插件。
- 对于调试不方便的,可以使用fmt库打印结果作为调试。
- mrsequential.go 代码可以借鉴。
- main/mrcoordinator.go期望mr/coordinator.go实现一个 Done()方法,该方法在 MapReduce 作业完全完成时返回 true;此时,mrcoordinator.go将退出。
- worker的map方法用json存储中间kv对,reduce再读回来,因为真正分布式worker都不在一个机器上,涉及网络传输,所以用json编码解码走个过场。
- worker的map可以用 worker.go里面的ihash(key)得到特定key的reduce任务号。
- 对于任务的并发可以实现chan,是个天然的并发安全队列,对于函数内的安全可以使用sync.Mutex 进行加锁并用defer在函数执行完后进行解锁,实现
并发安全本文的思路也是基于这个。

2.思路
首先来看Lab提供的论文中的图:

- 可以看出大致MapReduce的流程:启动一个Master(Coordinator协调者)分配多个任务给worker做Map任务。
- 然后Worker完成Map任务后返回中间值一组KV,接着协调者再将这些KV分发给后继的Worker根据KV进行Reduce任务,最后对Reduce进行一个总的处理进行返回。(如果还是不懂建议去看我上方所发的b站视频链接,讲的很透彻。)
3.实现
- 3.1 完成worker与Coordinator之间的交互,处理map任务
从实现来看我们可以先完成worker与Coordinator之间的交互,首先可以来看看给的Rpc例子:首先运行main/mrworker.go 会进入到 mr/Worker的这个方法中。可以在这个方法中调用RPC的例子方法:CallExample()。

然后CallExample()这个方法中会有一行:
ok := call("Coordinator.Example", &args, &reply)
调用Coordinator包的Example方法。(这里有个刚学go语言的同学不会注意到的小细节。就是方法名开头为大写的代表可以为外包所调用。至于为什么传方法传的是指针可以看我另外一篇写的博客:Golang指针的应用场景理解。)
然后得到传修改后的reply,得到rpc返回值。至此coordinator与worker完成了简单的交互。
- 看懂了简单的Rpc交互,现在我们可以自己来实现一个Rpc做Map任务。
在rpc包下定义类似于ExampleArg,reply的传参,rpc的改变都是通过参数改变,因此都是用指针。
// Task worker向coordinator获取task的结构体
type Task struct
TaskType TaskType // 任务类型判断到底是map还是reduce
TaskId int // 任务的id
ReducerNum int // 传入的reducer的数量,用于hash
Filename string // 输入文件
// TaskArgs rpc应该传入的参数,可实际上应该什么都不用传,因为只是worker获取一个任务
type TaskArgs struct
// TaskType 对于下方枚举任务的父类型
type TaskType int
// Phase 对于分配任务阶段的父类型
type Phase int
// State 任务的状态的父类型
type State int
// 枚举任务的类型
const (
MapTask TaskType = iota
ReduceTask
WaittingTask // Waittingen任务代表此时为任务都分发完了,但是任务还没完成,阶段未改变
ExitTask // exit
)
// 枚举阶段的类型
const (
MapPhase Phase = iota // 此阶段在分发MapTask
ReducePhase // 此阶段在分发ReduceTask
AllDone // 此阶段已完成
)
// 任务状态类型
const (
Working State = iota // 此阶段在工作
Waiting // 此阶段在等待执行
Done // 此阶段已经做完
)
-
接着我们就来worker里面构造发送请求rpc的方法,获取Map任务:(此处的代码都为当时笔者所写,与最终代码实现会有出入,忘后来者能有自己的斟酌考虑):
-
总的判断,获取的任务类型,后面reduce任务也直接加这里,笔者这里采用假任务(ExitTask)的方法退出,当然也可以通过RPC没有获取到task后再退出的方式,可以自己去试试。
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string)
//CallExample()
keepFlag := true
for keepFlag
task := GetTask()
switch task.TaskType
case MapTask:
DoMapTask(mapf, &task)
callDone()
case WaittingTask:
fmt.Println("All tasks are in progress, please wait...")
time.Sleep(time.Second)
case ExitTask:
fmt.Println("Task about :[", task.TaskId, "] is terminated...")
keepFlag = false
// uncomment to send the Example RPC to the coordinator.
接下来实现上方中的方法:
- 调用RPC拉取协调者的任务:
// GetTask 获取任务(需要知道是Map任务,还是Reduce)
func GetTask() Task
args := TaskArgs
reply := Task
ok := call("Coordinator.PollTask", &args, &reply)
if ok
fmt.Println(reply)
else
fmt.Printf("call failed!\\n")
return reply
- 参考给定的wc.go、mrsequential.go的map方法,编写属于自己 的map方法,这里简述下流程:插件编辑进来的mapf方法处理Map生成一组kv,然后写到temp文件中,temp命名我采用mr-tmp-taskId-ihash(kv.Key),调用的库为文档推荐的json库。至于为什么采用中间文件,其实也是为了后面crash有关,这个在后面crash部分再提。
func DoMapTask(mapf func(string, string) []KeyValue, response *Task)
var intermediate []KeyValue
filename := response.Filename
file, err := os.Open(filename)
if err != nil
log.Fatalf("cannot open %v", filename)
// 通过io工具包获取conten,作为mapf的参数
content, err := ioutil.ReadAll(file)
if err != nil
log.Fatalf("cannot read %v", filename)
file.Close()
// map返回一组KV结构体数组
intermediate = mapf(filename, string(content))
//initialize and loop over []KeyValue
rn := response.ReducerNum
// 创建一个长度为nReduce的二维切片
HashedKV := make([][]KeyValue, rn)
for _, kv := range intermediate
HashedKV[ihash(kv.Key)%rn] = append(HashedKV[ihash(kv.Key)%rn], kv)
for i := 0; i < rn; i++
oname := "mr-tmp-" + strconv.Itoa(response.TaskId) + "-" + strconv.Itoa(i)
ofile, _ := os.Create(oname)
enc := json.NewEncoder(ofile)
for _, kv := range HashedKV[i]
enc.Encode(kv)
ofile.Close()
- 做完任务也需要调用rpc在协调者中将任务状态为设为已完成,以方便协调者确认任务已完成,worker与协调者程序能正常退出。
// callDone Call RPC to mark the task as completed
func callDone() Task
args := Task
reply := Task
ok := call("Coordinator.MarkFinished", &args, &reply)
if ok
fmt.Println(reply)
else
fmt.Printf("call failed!\\n")
return reply
接下来去协调者完善方法:
- 协调者结构体定义:
type Coordinator struct
// Your definitions here.
ReducerNum int // 传入的参数决定需要多少个reducer
TaskId int // 用于生成task的特殊id
DistPhase Phase // 目前整个框架应该处于什么任务阶段
TaskChannelReduce chan *Task // 使用chan保证并发安全
TaskChannelMap chan *Task // 使用chan保证并发安全
taskMetaHolder TaskMetaHolder // 存着task
files []string // 传入的文件数组
其中taskMetaHolder为存放全部元信息(TaskMetaInfo)的map,当然用slice也行。
// TaskMetaHolder 保存全部任务的元数据
type TaskMetaHolder struct
MetaMap map[int]*TaskMetaInfo // 通过下标hash快速定位
- TaskMetaInfo结构体的定义:
// TaskMetaInfo 保存任务的元数据
type TaskMetaInfo struct
state State // 任务的状态
TaskAdr *Task // 传入任务的指针,为的是这个任务从通道中取出来后,还能通过地址标记这个任务已经完成
- mrcoordinator中初始协调者的方法(同worker)
// create a Coordinator.
// main/mrcoordinator.go calls this function.
// nReduce is the number of reduce tasks to use.
//
func MakeCoordinator(files []string, nReduce int) *Coordinator
c := Coordinator
files: files,
ReducerNum: nReduce,
DistPhase: MapPhase,
TaskChannelMap: make(chan *Task, len(files)),
TaskChannelReduce: make(chan *Task, nReduce),
taskMetaHolder: TaskMetaHolder
MetaMap: make(map[int]*TaskMetaInfo, len(files)+nReduce), // 任务的总数应该是files + Reducer的数量
,
c.makeMapTasks(files)
c.server()
return &c
- 实现上方的makeMapTasks:将Map任务放到Map管道中,taskMetaInfo放到taskMetaHolder中。
// 对map任务进行处理,初始化map任务
func (c *Coordinator) makeMapTasks(files []string)
for _, v := range files
id := c.generateTaskId()
task := Task
TaskType: MapTask,
TaskId: id,
ReducerNum: c.ReducerNum,
Filename: v,
// 保存任务的初始状态
taskMetaInfo := TaskMetaInfo
state: Waiting, // 任务等待被执行
TaskAdr: &task, // 保存任务的地址
c.taskMetaHolder.acceptMeta(&taskMetaInfo)
fmt.Println("make a map task :", &task)
c.TaskChannelMap <- &task
- 上方生成id的方法(其实就是主键自增方式):
// 通过结构体的TaskId自增来获取唯一的任务id
func (c *Coordinator) generateTaskId() int
res := c.TaskId
c.TaskId++
return res
- 将taskMetaInfo放到taskMetaHolder中的具体方法:
// 将接受taskMetaInfo储存进MetaHolder里
func (t *TaskMetaHolder) acceptMeta(TaskInfo *TaskMetaInfo) bool
taskId := TaskInfo.TaskAdr.TaskId
meta, _ := t.MetaMap[taskId]
if meta != nil
fmt.Println("meta contains task which id = ", taskId)
return false
else
t.MetaMap[taskId] = TaskInfo
return true
- 接下来实现worker中的一个调用协调者的一个rpc方法,也是我认为Coordinator比较核心的方法分配任务:将map任务管道中的任务取出,如果取不出来,说明任务已经取尽,那么此时任务要么就已经完成,要么就是正在进行。判断任务map任务是否先完成,如果完成那么应该进入下一个任务处理阶段(ReducePhase),因为此时我们先验证map则直接跳过reduce直接allDone全部完成。
// 分发任务
func (c *Coordinator) PollTask(args *TaskArgs, reply *Task) error
// 分发任务应该上锁,防止多个worker竞争,并用defer回退解锁
mu.Lock()
defer mu.Unlock()
// 判断任务类型存任务
switch c.DistPhase
case MapPhase:
if len(c.TaskChannelMap) > 0
*reply = *<-c.TaskChannelMap
if !c.taskMetaHolder.judgeState(reply.TaskId)
fmt.Printf("taskid[ %d ] is running\\n", reply.TaskId)
else
reply.TaskType = WaittingTask // 如果map任务被分发完了但是又没完成,此时就将任务设为Waitting
if c.taskMetaHolder.checkTaskDone()
c.toNextPhase()
return nil
default:
reply.TaskType = ExitTask
return nil
- 分配任务中转换阶段的实现:
func (c *Coordinator) toNextPhase()
if c.DistPhase == MapPhase
//c.makeReduceTasks()
// todo
c.DistPhase = AllDone
else if c.DistPhase == ReducePhase
c.DistPhase = AllDone
- 分配任务中检查任务是否完成的实现:
// 检查多少个任务做了包括(map、reduce),
func (t *TaskMetaHolder) checkTaskDone() bool
var (
mapDoneNum = 0
mapUnDoneNum = 0
reduceDoneNum = 0
reduceUnDoneNum = 0
)
// 遍历储存task信息的map
for _, v := range t.MetaMap
// 首先判断任务的类型
if v.TaskAdr.TaskType == MapTask
// 判断任务是否完成,下同
if v.state == Done
mapDoneNum++
else
mapUnDoneNum++
else if v.TaskAdr.TaskType == ReduceTask
if v.state == Done
reduceDoneNum++
else
reduceUnDoneNum++
//fmt.Printf("map tasks are finished %d/%d, reduce task are finished %d/%d \\n",
// mapDoneNum, mapDoneNum+mapUnDoneNum, reduceDoneNum, reduceDoneNum+reduceUnDoneNum)
// 如果某一个map或者reduce全部做完了,代表需要切换下一阶段,返回true
// R
if (mapDoneNum > 0 && mapUnDoneNum == 0) && (reduceDoneNum == 0 && reduceUnDoneNum == 0)
return true
else
if reduceDoneNum > 0 && reduceUnDoneNum == 0
return true
return false
- 分配任务中修改任务的状态方法:
// 判断给定任务是否在工作,并修正其目前任务信息状态
func (t *TaskMetaHolder) judgeState(taskId int) bool
taskInfo, ok := t.MetaMap[taskId]
if !ok || taskInfo.state != Waiting
return false
taskInfo.state = Working
return true
- 接着再来实现一个调用的rpc方法,将任务标记为完成:
func (c *Coordinator) MarkFinished(args *Task, reply *Task) error
mu.Lock()
defer mu.Unlock()
switch args.TaskType
case MapTask:
meta, ok := c.taskMetaHolder.MetaMap[args.TaskId]
//prevent a duplicated work which returned from another worker
if ok && meta.state == Working
meta.state = Done
fmt.Printf("Map task Id[%d] is finished.\\n", args.TaskId)
else
fmt.Printf("Map task Id[%d] is finished,already ! ! !\\n", args.TaskId)
break
default:
panic("The task type undefined ! ! !")
return nil
- 最后来实现在map阶段中最后一个事情:如果map任务全部实现完(暂且略过reduce)阶段为AllDone那么Done方法应该返回true,使协调者能够exit程序。
//Done 主函数mr调用,如果所有task完成mr会通过此方法退出
func (c *Coordinator) Done() bool
mu.Lock()
defer mu.Unlock()
if c.DistPhase == AllDone
fmt.Printf("All tasks are finished,the coordinator will be exit! !")
return true
else
return false
至此map阶段已经能暂且构成一个循环,先运行mrcoordinator.go、再运行mrworker查看效果。
mrcoordinator.go运行效果(笔者为了测试效果只传入了两个文件):

mrworker.go运行效果:
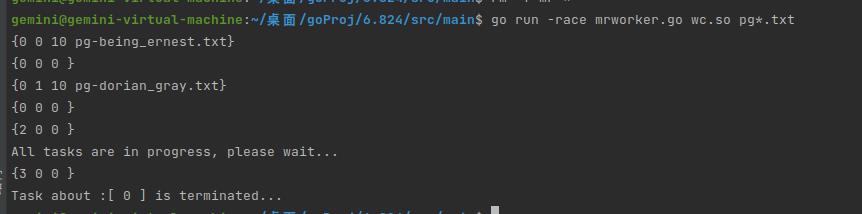
再去查看生成的文件:

-
3.2 在map阶段上补充reduce阶段,并处理
-
有过大概一个流程写reduce阶段还是挺快,大部分逻辑其实和map阶段是相同的的,先继续初始写reduce方法:
func (c *Coordinator) makeReduceTasks()
for i := 0; i < c.ReducerNum; i++
id := c.generateTaskId()
task := Task
TaskId: id,
TaskType: ReduceTask,
FileSlice: selectReduceName(i),
// 保存任务的初始状态
taskMetaInfo := TaskMetaInfo
state: Waiting, // 任务等待被执行
TaskAdr: &task, // 保存任务的地址
c.taskMetaHolder.acceptMeta(&taskMetaInfo)
//fmt.Println("make a reduce task :", &task)
c.ReduceTaskChannel <- &task
这里要注意的是我把原来Task结构字段做出了一个改变,由Filename变为了一个文件切片数组。
// Task worker向coordinator获取task的结构体
以上是关于MIT6.824-lab1-2022篇(万字推导思路及代码构建)的主要内容,如果未能解决你的问题,请参考以下文章