机器学习系列4 使用Python创建Scikit-Learn回归模型
Posted GISer Liu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习系列4 使用Python创建Scikit-Learn回归模型相关的知识,希望对你有一定的参考价值。
本文中包含的案例jupyter笔记本可在我的资源中免费下载:
图1 使用Python和Scikit-learn库实现回归模型

目录
三、创建你的第一个Scikit-learn Notebook
一、内容介绍
在本文中,我将会带你了解如何构建回归模型,但在构建模型之前,我们需要先搭建运行环境,确保读者能够复现本次练习。
在本文中,你将会学习到如何:
0 在本地计算机搭建机器学习环境
1 安装并使用Jupyter notebook
2 安装并使用Scikit-learn库
3 探索并实现线性回归
二、配置本地机器学习环境
1.安装python
确保你的计算机上安装了Python,博主的python版本是3.8,大家可以根据自己的情况选择合适的版本,但要保证是Python 3系列。


由于博主以及安装过,这里就借用一下知乎@呆呆的图片。选择自定义安装并勾选加入系统变量,选择安装位置,一路确定即可 。WIN+R输入cmd打开命令行,输入python,如下图所示表示安装成功。

2.安装jupyter notebook
确保电脑安装了Jupyter,jupyter notebook是一个基于Web的轻量级开发应用,是数据科学常用的工具,入门数据科学使用这个就足够,如果工作需要版本控制的话,可以安装Anaconda,这个软件可以在一台电脑上配置多个不同版本的python。
在Windows桌面按WIN + R,弹出运行窗口,输入cmd,打开命令行;输入:
pip install -i https://mirrors.aliyun.com/pypi/simple/ jupyter期间可能会出现pip版本过低导致安装失败,此时只需要更新pip后再次安装即可;
安装好以后输入:
cd D:\\ML\\ #转移到项目目录
若目录没有改变,可以再次输入项目目录所在位置的根目录,回车以后即可转移成功。
转移到项目所在目录后,输入jupyter notebook,稍等片刻,便会打开jupyter notebook,此时代表jupyter安装完成,可在里面创建文件,ipynb是jupyter的专用文件格式:
jupyter notebook

3.安装Scikit-learn
Scikit-learn是针对Python 编程语言的免费软件机器学习库 。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值等算法,并且常常与数值科学库NumPy和SciPy联合使用。 在本课程中,我将使用Scikit-learn和其他工具来构建传统机器学习模型。
在Windows桌面按WIN + R,弹出运行窗口,输入cmd,打开命令行;输入
pip install -U scikit-learn如果安装较慢,也可使用阿里或者清华的镜像源来安装;
pip install -i https://mirrors.aliyun.com/pypi/simple/ scikit-learn稍等一会儿后即可安装完成。同理,安装本文需要的matplotlib库以及numpy库。
Scikit-learn使构建模型并评估其使用变得简单明了。它主要侧重于使用数值数据,并包含几个现成的数据集,可用作学习工具。它还包括供学生尝试的预构建模型。
三、创建你的第一个Scikit-learn Notebook
在本文中,你将使用一个糖尿病的小型数据集,该数据集内置在Scikit-learn中,用于学习目的。想象一下,你想测试糖尿病患者的治疗方法。机器学习模型可能会根据变量组合,帮助您确定哪些患者对治疗反应更好。即使是非常基本的回归模型;当可视化数据时,显示有关变量隐藏的信息,这些信息将帮助您组织理论临床试验。
回归方法有很多种类型,选择哪一种取决于您正在寻找的答案。如果要预测给定年龄的人的可能身高,则可以使用线性回归,因为您正在寻找的数据是数值。如果问题是判断一种的美食是否应该被视为素食,那么你这是一个分类问题,因此您将使用逻辑回归。以后的文章中你将了解有关逻辑回归的详细信息。考虑一下你可以想到的一些问题,探索哪种方法更合适。
我们开始本次练习。
1.导入第三方库
对于本次练习,我们将导入下列库:
0 matplotlib 这是一个经典的绘图库,我们将用它来创建图表。
1 numpy 这是一个数值计算的python库,我们将用它处理数值数据。
2 sklearn 这是Scikit-learn的库名。
代码如下:
import matplotlib.pyplot as plt
import numpy as np from sklearn
import datasets,linear_model,model_selection以上库用于绘图,数据处理,数据集调用,模型构建等。
2.糖尿病数据集介绍
内置的糖尿病数据集包括442个糖尿病数据样本,该数据集包括10个特征变量,其中包括:
0 年龄 单位年
1 体重指数
2 血压 平均血压
该数据集包括“性别”的特征,作为对糖尿病研究很重要的特征变量。许多医学数据集都包含这种类型的二元分类。想想像这样的分类如何将某些人群排除在治疗之外,思考一下机器学习的公平性。
现在,加载输入变量X 和标签 Y 数据。因为线性回归是有监督学习,需要的标签样本数据Y。
在新的代码单元中,通过调用load_diabetes()函数加载糖尿病数据集,返回特征变量与标签。
通过print()函数查看输入数据X的结构与值;
X, Y = datasets.load_diabetes(return_X_y=True)
print(X.shape)
print(X[0])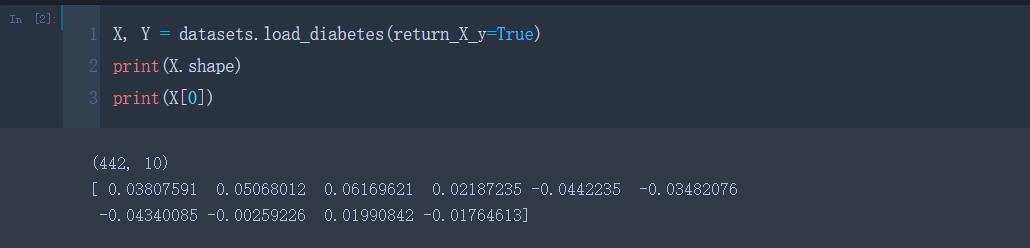
通过打印出的结果,我们得到了一个元组与一个列表,前者表示输入数据是442行10列。 可以看到此数据有 442 个样本,后者表示每个样本由10 个特征变量的数组形式组成:
大家可以思考一下特征变量X与回归标签Y之间的关系。
3.数据预处理
接下来,通过使用numpy库的函数将其转换成一个新数组以分割训练集与测试集。我们将使用线性回归函数基于它确定的模式在数据点之间生成一条回归线。
X = X[:, np.newaxis, 2] #取出每个样本中第3列的数据并单独形成一个1行1列的向量

打印数据以检查其结构。np.newaxis等价于None,作用是把X的类型从列向量变为行向量,方便后面的训练;
现在,我们已经准备好绘制数据,在此之前,我们需要将特征 (X) 和标签 (Y) 拆分为训练集和测试集。Scikit-learn有一个简单的方法来做到这一点;通过train_test_split()函数选择测试集比例来拆分测试数据。
X_train, X_test, Y_train, Y_test = model_selection.train_test_split(X, Y, test_size=0.33)#test_size=0.33 表示测试集占比33%,即训练集占67%4.模型训练
好耶!😆现在,我们可以训练模型了!加载线性回归模型,并使用model.fit()函数进行训练:
model = linear_model.LinearRegression() #调用线性模型中的线性回归函数
model.fit(X_train, Y_train) #输入训练集数据进行模型训练model.fit()是在许多机器学习库(如TensorFlow)中常见的函数,其用于模型训练。
5.模型预测
然后,调用predict()函数将测试数据输入训练好的线性模型中进行预测。并将预测结果赋予Y_pred,这个结果将用于回归线的绘制。
Y_pred = model.predict(X_test) #利用训练好的模型进行预测6.数据可视化
现在是时候在图中显示数据了。Matplotlib是执行此任务的非常有用的工具。创建所有 X 和Y测试数据的散点图,并使用预测值在模型的数据点之间的最合适位置绘制一条回归线。
plt.scatter(X_test, y_test, color='black') #基于测试集数据生成散点图
plt.plot(X_test, y_pred, color='blue', linewidth=3) #利用线性回归的结果绘制回归线 plt.xlabel('Scaled BMIs')
plt.ylabel('Disease Progression')
plt.title('A Graph Plot Showing Diabetes Progression Against BMI')
plt.show()显示糖尿病周围数据点的散点图:

想想这里发生了什么。一条直线穿过许多小数据点,但它到底在做什么呢?如何使用这条线来预测一个新的、看不见的数据点?试着用语言来表达这个模型的实际用途。
恭喜,我们在此构建了第一个线性回归模型,用它预测了结果,并将其显示在图表中!
四、结论
在本文中,我们学习了机器学习本地环境的配置过程,利用Scikit-learn库简单的走完了机器学习模型的基本流程,最终创建了一个线性回归模型。麻雀虽小,五脏俱全;读者需要从简单的线性回归练习开始慢慢培养自己的机器学习思维,一步步去理解机器学习的内涵。

“本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_45590504/category_11752103.html?spm=1001.2014.3001.5482百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。”
以上是关于机器学习系列4 使用Python创建Scikit-Learn回归模型的主要内容,如果未能解决你的问题,请参考以下文章