生产者发送消息分析
Posted lisin-lee-cooper
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生产者发送消息分析相关的知识,希望对你有一定的参考价值。
一.生产者发送消息
生产者实例代码
public class KafkaProducerClient
public static final String brokers = "localhost:9092";
public static final String topic = "topic-demo";
public static Properties initConfig()
Properties props = new Properties();
props.put("bootstrap.servers", brokers);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("client.id", "producer.client.id.demo");
return props;
public static void main(String[] args)
Properties props = initConfig();
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record =
new ProducerRecord<>(topic, "Hello, Kafka!");
try
producer.send(record);
catch (Exception e)
e.printStackTrace();
参数解析
bootstrap.servers:该参数用来指定生产者客户端连接 Kafka 集群所需的 broker 地址清单,具体的内容格式为 host1:port1,host2:port2,可以设置一个或多个地址,中间以逗号隔开;
key.serializer 和 value.serializer:broker 端接收的消息必须以字节数组(byte[])的形式存在。代码清单3-1中生产者使用的 KafkaProducer<String, String>和 ProducerRecord<String, String> 中的泛型 <String, String> 对应的就是消息中 key 和 value 的类型,生产者客户端使用这种方式可以让代码具有良好的可读性,不过在发往 broker 之前需要将消息中对应的 key 和 value 做相应的序列化操作来转换成字节数组。key.serializer 和 value.serializer 这两个参数分别用来指定 key 和 value 序列化操作的序列化器,这两个参数无默认值。注意这里必须填写序列化器的全限定名;
生产者消息对象解析
public class ProducerRecord<K, V>
private final String topic; //主题
private final Integer partition; //分区号
private final Headers headers; //消息头部
private final K key; //键
private final V value; //值
private final Long timestamp; //消息的时间戳
发送消息方法
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)
this(topic, partition, timestamp, key, value, (Iterable)null);
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers)
this(topic, partition, (Long)null, key, value, headers);
public ProducerRecord(String topic, Integer partition, K key, V value)
this(topic, partition, (Long)null, key, value, (Iterable)null);
public ProducerRecord(String topic, K key, V value)
this(topic, (Integer)null, (Long)null, key, value, (Iterable)null);
public ProducerRecord(String topic, V value)
this(topic, (Integer)null, (Long)null, (Object)null, value, (Iterable)null);
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers)
if (topic == null)
throw new IllegalArgumentException("Topic cannot be null.");
else if (timestamp != null && timestamp < 0L)
throw new IllegalArgumentException(String.format("Invalid timestamp: %d. Timestamp should always be non-negative or null.", timestamp));
else if (partition != null && partition < 0)
throw new IllegalArgumentException(String.format("Invalid partition: %d. Partition number should always be non-negative or null.", partition));
else
this.topic = topic;
this.partition = partition;
this.key = key;
this.value = value;
this.timestamp = timestamp;
this.headers = new RecordHeaders(headers);
发送消息的三种模式:
发后即忘(fire-and-forget) send()、同步(sync) send().get()及异步(async)send(record, new Callback()
二.原理分析
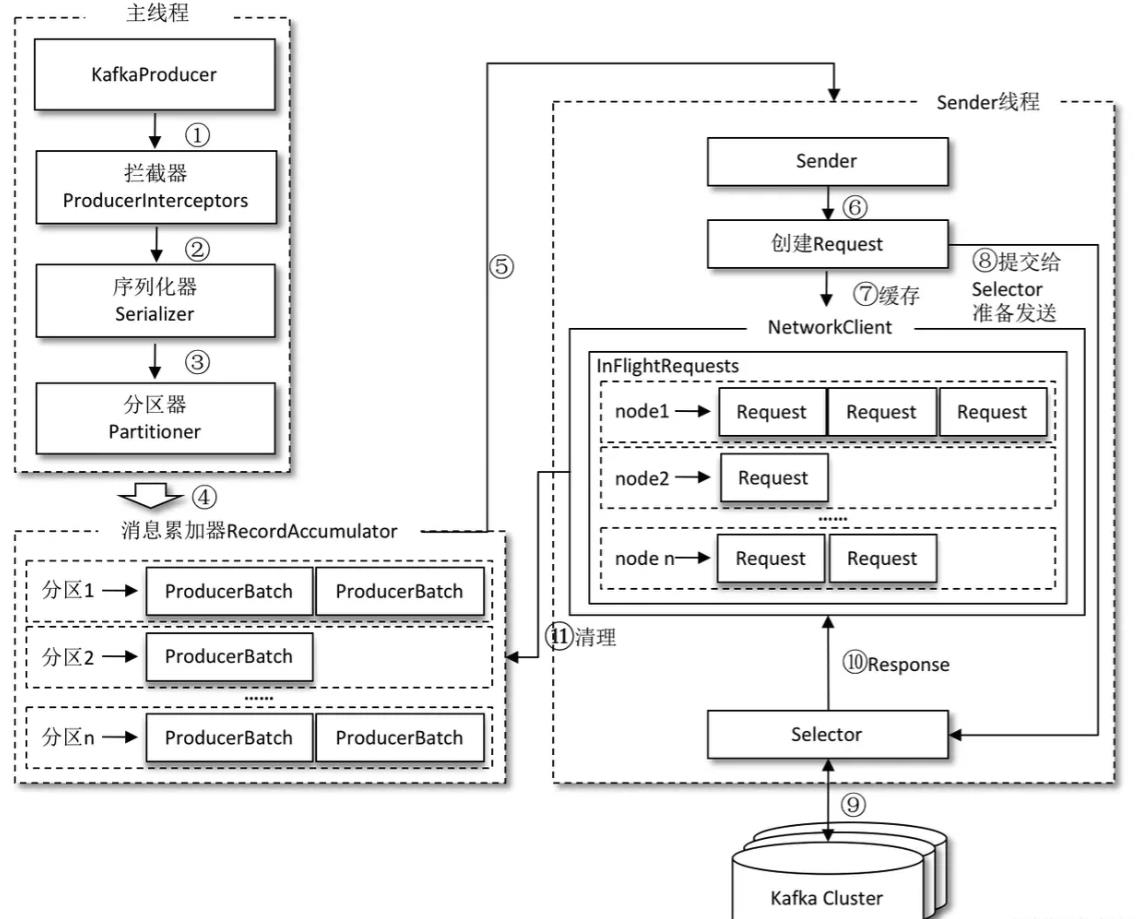
生产者客户端由两个线程协调运行,主线程和 Sender 线程
主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中;
Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中;
主线程中发送过来的消息都会被追加到 RecordAccumulator 的某个双端队列(Deque)中,在 RecordAccumulator 的内部为每个分区都维护了一个双端队列,队列中的内容就是 ProducerBatch,即 Deque。消息写入缓存时,追加到双端队列的尾部;Sender 读取消息时,从双端队列的头部读取。
生产者参数
1.acks
acks = 0,不需要等待任何服务端的响应,吞吐量最高,但最不可靠;
acks=1 , 只要分区的 leader 副本成功写入消息,那么它就会收到来自服务端的成功响应;
acks = -1 ,需要等待 ISR 中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应,可靠性最高但吞吐量最低。
2.retries和retry.backoff.ms
retries 参数用来配置生产者重试的次数,默认值为0,
retry.backoff.ms 这个参数的默认值为100,它用来设定两次重试之间的时间间隔;
以上是关于生产者发送消息分析的主要内容,如果未能解决你的问题,请参考以下文章