单机爬虫简单demo
Posted 一只小鱼儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了单机爬虫简单demo相关的知识,希望对你有一定的参考价值。
爬虫简介:
在部门做爬虫需求的时候,每次来一个需求就需要写一个爬虫程序然后打包部署到服务器,制定脚本定时运行,所以有了这个爬虫,目的是为了尽可能简化现有的流程,之前从网页源码获取,到网页解析,到持久化都需要重新在程序里面重新写一遍,分析了这个过程,我们抽取出了网页源码获取,持久化成为两询这个阻塞队列,爬虫会不断往阻塞队列里面添加网页源码,主线程检测到队列连续10s为空则结个独立的类实现原有程序的解耦,然后剩下的也就是我们每次必须要自己手写的网页解析函数(这个过程是必不可少的,因为不同网页需要制定不同的解析规则),从而实现了每次爬虫需求只需要完成网页解析函数,就可以进行打包部署。另外通过传递给程序的参数控制http请求获取网页源码的线程数,加快爬取效率,也可以通过参数控制持久化的方式(文件,数据库),提高程序的复用性。动态加载的功能是用工厂模式来运行对应的Spider实例,实现只需要服务器上部署一个脚本,以后新的需求来了只需要调用同一个脚本传递不同的参数就能运行对应的spider实例。关于多线程爬取返回网页源码的问题,因为不可能等待所有的线程爬取完后网页源码才返回给主线程解析,一是数据量大时内存可能会溢出,而是主线程会一直阻塞,效率太低,主线程采用了一个阻塞队列来达到一个非阻塞的效果,主线程会不断轮束轮询。
关于代码的关键部分和说明我将在下面给出:
项目结构图如下:
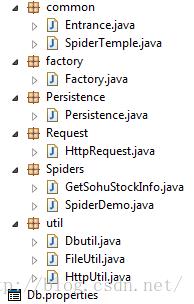
common包:
SpiderTemple类: 所有爬虫实例的父类,规定了爬虫实例的入口函数run,规定爬虫实例需要实现的函数parsehtml
public class SpiderTemple
protected Persistence persistence = new Persistence();
protected HttpRequest httpRequest = new HttpRequest();
public void run(Map<String, String> map) throws Exception
LinkedBlockingQueue<String> contents = new LinkedBlockingQueue<String>();
httpRequest.getContent(contents, map);
while(true)
String poll = contents.poll(5L, TimeUnit.SECONDS);
if(null!=poll)
System.err.println("poll获取成功,解析后"+parseHtml(poll));
persistence.save(map, parseHtml(poll) );
else
System.out.println("队列中无待解析内容");
break ;
public String parseHtml(String url) throws Exception
return null;
factory包:
factory类: 根据参数里的类名动态加载不同的爬虫实例进行调用
Rquest包:
httpRequest类:发送http请求获取网页源码,根据传递进来的参数决定是爬取一个url还是爬取文件里的一系列url
public class HttpRequest
protected HttpUtil httpUtil = new HttpUtil();
protected ExecutorService executor = Executors.newFixedThreadPool(50); // 创建固定容量大小的缓冲池
List<String> contents = new LinkedList<String>();
public void getContent(final LinkedBlockingQueue<String> contents,
final Map<String, String> map) throws Exception
String uri = map.get("uri");
if (null != uri && uri.contains("http")) // uri代表网址
try
String content = httpUtil.getUrlAsString(uri);
System.err.println("add content");
contents.add(content);
catch (Exception e)
System.err.println("爬起url出错,请检查网络问题");
else if (null != uri && !uri.contains("http")) // uri代表文件
final List<String> urlList = new ArrayList<String>();
BufferedReader bufferedReader = new BufferedReader(new FileReader(uri));
String name = null;
while ((name = bufferedReader.readLine()) != null)
urlList.add(name);
new Thread(new Runnable() // 默认开启一个线程
@Override
public void run()
// TODO Auto-generated method stub
for (final String url : urlList)
if (null == map.get("thread"))
try
String content = httpUtil.getUrlAsString("http://" + url);
contents.add(content);
catch (Exception e)
System.err.println("爬起url出错,请检查网络问题");
else if ("true".equals(map.get("thread")))
// 针对每个Ur均开启一个线程进行爬取
executor.execute(new Runnable() // 缓冲池最多开启50个线程
@Override
public void run()
String content;
try
System.out.println(Thread.currentThread()+" is running");
content = httpUtil.getUrlAsString("http://"+ url);
contents.add(content);
catch (Exception e)
e.printStackTrace();
);
).start();
Spiders包:
SpiderDemo类:为Spider实例提供一个Demo,以后的Spider实例只需要按这个规范写即可以,
public class SpiderDemo extends SpiderTemple implements Entrance
@Override
public String parseHtml(String content) throws Exception
Document doc = Jsoup.parse(content);
String title = doc.select("meta[name=Description]").attr("content");
String time = doc.select("span[class=pubTime article-time]").text();
String comment = doc.select("a[id=cmtNum]").text();
String text = doc.select("div[id=Cnt-Main-Article-QQ] span").text()
+ doc.select("div[id=Cnt-Main-Article-QQ] p").text();
// 这里要和数据库除了主键以外的字段数目一致,字段分隔符&&&
return title + time + comment + text;
Util包:
一些用于发送http请求,下载到文件或者db的工具
这个爬虫可以改进的地方还有很多,比如一些应对反爬措施等等,但是结合业务需求来看暂时是没必要做的,有句话说得好,“如无必要,勿增实体”,一些应对反爬措施我也会在后面的分布式爬虫提到,大家可以去参考一下
以上是关于单机爬虫简单demo的主要内容,如果未能解决你的问题,请参考以下文章