大规模分布式爬虫系统中Kafka和rabbitMQ消息中间件的技术实践分享
Posted 思通数科x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大规模分布式爬虫系统中Kafka和rabbitMQ消息中间件的技术实践分享相关的知识,希望对你有一定的参考价值。
一、背景描述
目前后端数据引擎系统中 使用了24个节点的 Elasticsearch 集群,存储每天采集1.7亿条上下的数据量,具体的网页原始数据存储在 Cassandra 集群中。一个月下来抓取的数据量超过2T,同时要保证每天450台爬虫机器同时抓取数据稳定运行,这么大的数据采集量当然需要一个可靠的爬虫系统。在这个爬虫系统中抓取任务和数据处理分发的稳定中间件必不可少。在多种MQ消息中间件里面,我们经过反复的试验和论证,最后选择了Kafka和rabbitMQ两种消息中间件,在分布式爬虫系统作为不同的用途使用,rabbitMQ做爬虫抓取压力分载,Kafka并行对一条数据多种状态处理。
备注:将来还会用一篇文章来阐述为什么我们要放弃使用MongoDB 转向 Cassandra。
二、rabbitMQ使用场景
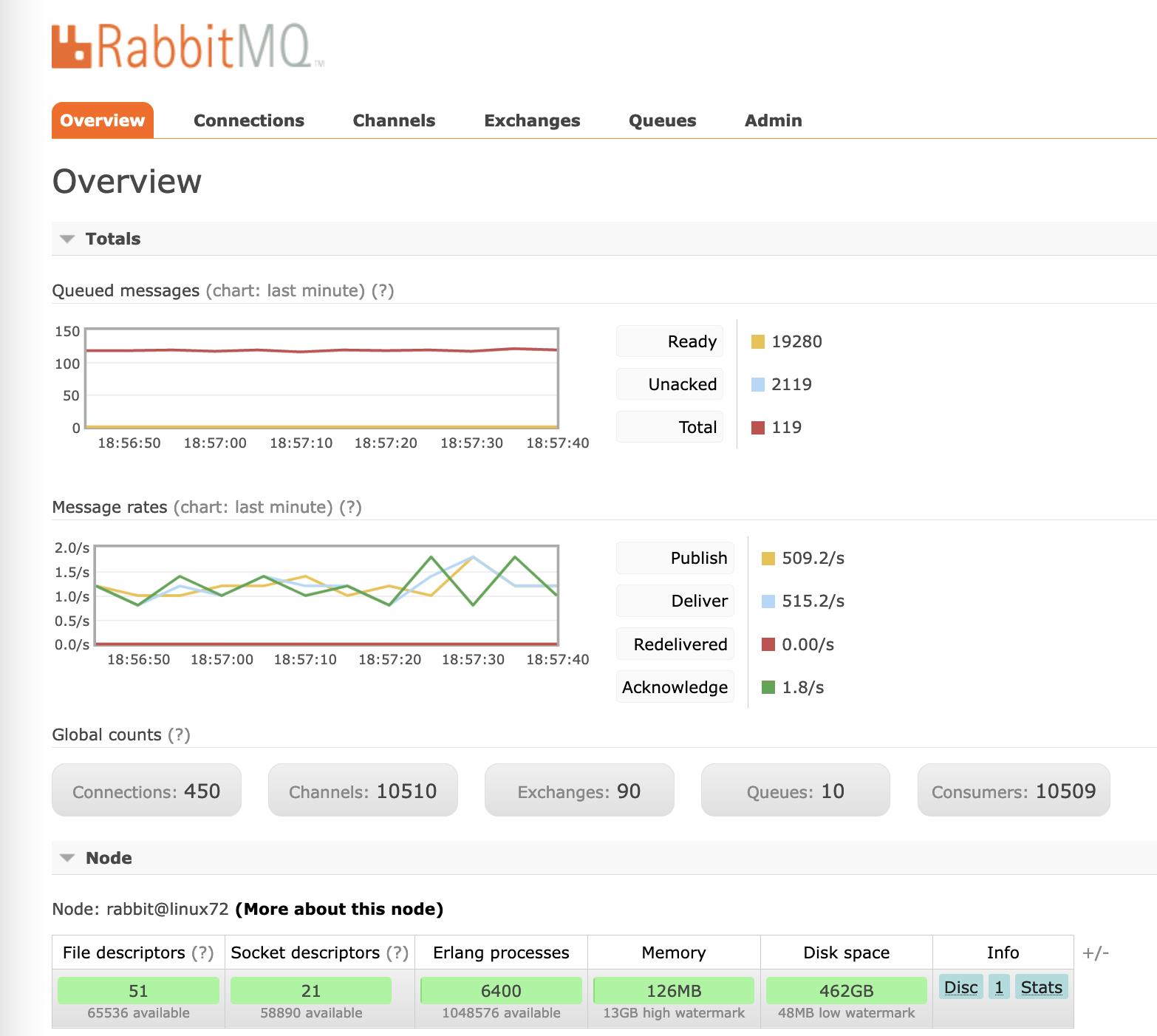
rabbitMQ在系统与分布式爬虫配合,首先从redis种子仓库里将有效的URL地址提取出来,将URL种子地址和爬虫采集模板匹配组装成rabbitMQ消息,通过消息发送端给rabbitMQ消息中间件,450个爬虫worker节点作为rabbitMQ消息接收端去不同的网站对数据进行采集数据。
三、Kafka使用场景
Kafka在系统扮演者并行数据处理的工作,例如:数据清洗、数据标记、情感分析、数据删除 等多个数据处理过程,中间有同步处理的数据,也是异步的处理数据流程,最终再将处理完成的数据组装起来,将摘要检索字段存储在 Elasticsearch中,原始网页存储在 Cassandra。
使用 rabbitMQ 是为了能让爬虫机器快速的扩展,因为 rabbitMQ中有queue消息队列的属性, 可以将压力自动分发到各个爬虫采集端。使用 Kafka 主要是因为性能卓越,一台廉价的服务器都可以支持百万级并发处理,特别是用于并行对一条数据同时多种处理。因此,我们采用了2种类型的消息中间件来构建我们的系统。
开源项目地址:
目前我们已经将上述技术实践开源,请关注我们发布的开源项目。
开源免费舆情监测网络监控系统: 思通舆情 是一款开源免费的舆情系统,支持本地化部署。支持对海量的舆情数据进行交叉分析和深度挖掘,为用户提供全面的舆情数据,专业的舆情分析,快速的舆情处理等服务,提升企业品牌价值和风控能力。#舆情系统#舆情监测#网络舆情#开源舆情#免费舆情#舆情分析 https://gitee.com/stonedtx/yuqing
https://gitee.com/stonedtx/yuqing
以上是关于大规模分布式爬虫系统中Kafka和rabbitMQ消息中间件的技术实践分享的主要内容,如果未能解决你的问题,请参考以下文章