38java的集合框架(容器框架)
Posted fesng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了38java的集合框架(容器框架)相关的知识,希望对你有一定的参考价值。
Collection接口
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。一些 Collection允许相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接继承自Collection的类,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个 Collection参数的构造函数用于创建一个新的Collection,这个新的Collection与传入的Collection有相同的元素。后 一个构造函数允许用户复制一个Collection。
Collection vs Collections:
首先,Collection 和 Collections 是两个不同的概念。之所以放在一起,是为了更好的比较。Collection是容器层次结构中根接口。而Collections是一个提供一些处理容器类静态方法的类。
所有容器的实现类(如ArrayList实现了List接口,HashSet实现了Set接口)提供了两个‘标准’的构造函数来实现:1、一个无参的构造方法(void)2、一个带有Collection类型单参数构造方法,用于创建一个具有其参数相同元素新的Collection及其实现类等。实际上:因为所有通用的容器类遵从Collection接口,用第二种构造方法是允许容器之间相互的复制。
Collection的类层次结构
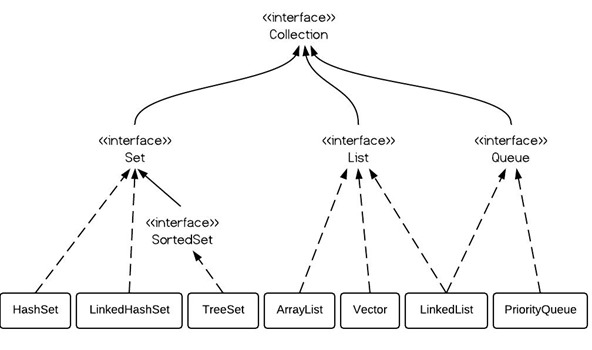
set介绍
一个不包括重复元素(包括可变对象)的Collection,是一种无序的集合。Set不包含满足 a.equals(b) 的元素对a和b,并且最多有一个null。实现Set的接口有:EnumSet、HashSet、TreeSet等。
HashSet,TreeSet 和 LinkedHashSet比较
一个不包括重复元素(包括可变对象)的Collection,是一种无序的集合。Set不包含满 a.equals(b) 的元素对a和b,并且最多有一个null。
1、不允许包含相同元素
2、判断对象是否相同,根据equals方法
HashSet
一个按着Hash算法来存储集合中的元素,其元素值可以是NULL。它不能保证元素的排列顺序。同样,HashSet是不同步的,如果需要多线程访问它的话,可以用 Collections.synchronizedSet 方法来包装它:
Set s = Collections.synchronizedSet(new HashSet(...));
同上一节一样,用迭代器的时候,也要注意 并发修改异常ConcurrentModificationException。
要注意的地方是,HashSet集合判断两个元素相等不单单是equals方法,并且必须hashCode()方法返回值也要相等。
LinkedHashSet
HashSet的子类,也同样有HashCode值来决定元素位置。但是它使用链表维护元素的次序。记住两个字:有序。
有序的妙用,复制。比如泥瓦匠实现一个HashSet无序添加,然后复制一个一样次序的HashSet来。代码如下:
package com.sedion.bysocket.collection;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
public class LinkedHashListTest
public static void main(String[] args)
/* 复制HashSet */
Set h1 = new HashSet<String>();
h1.add("List");
h1.add("Queue");
h1.add("Set");
h1.add("Map");
System.out.println("HashSet Elements:");
System.out.print("\\t" + h1 + "\\n");
Set h2 = copy(h1);
System.out.println("HashSet Elements After Copy:");
System.out.print("\\t" + h2 + "\\n");
@SuppressWarnings( "rawtypes", "unchecked" )
public static Set copy(Set set)
Set setCopy = new LinkedHashSet(set);
return setCopy;
输出:
HashSet Elements:
[Map, Queue, Set, List]
HashSet Elements After Copy:
[Map, Queue, Set, List]
TreeSet
TreeSet使用树结构实现(红黑树),集合中的元素进行排序,但是添加、删除和包含的算法复杂度为O(log(n))。
总结:
HashSet:equlas hashcode
LinkedHashSet:链式结构
TreeSet:比较,Comparable接口,性能较差
List:
一个有序的Collection(也称序列),元素可以重复。确切的讲,列表通常允许满足 e1.equals(e2) 的元素对 e1 和 e2,并且如果列表本身允许 null 元素的话,通常它们允许多个 null 元素。实现List的有:ArrayList、LinkedList、Vector、Stack等。
ArrayList 、LinkedList和Vector比较
序列(List),有序的Collection,正如它的名字一样,是一个有序的元素列表。确切的讲,列表通常允许满足 e1.equals(e2) 的元素对 e1 和 e2,并且如果列表本身允许 null 元素的话,通常它们允许多个 null 元素。实现List的有:ArrayList、LinkedList、Vector、Stack等。值得一提的是,Vector在JDK1.1的时候就有了,而List在JDK1.2的时候出现,待会我们会聊到ArrayList和Vector的区别。
ArrayList vs. Vector
ArrayList是一个可调整大小的数组实现的序列。随着元素增加,其大小会动态的增加。此类在Iterator或ListIterator迭代中,调用容器自身的remove和add方法进行修改,会抛出ConcurrentModificationException并发修改异常。
注意,此实现不是同步的。如果多个线程同时访问一个 ArrayList 实例,而其中至少一个线程从结构上修改了列表,那么它必须 保持外部同步。(结构上的修改是指任何添加或删除一个或多个元素的操作,或者显式调整底层数组的大小;仅仅设置元素的值不是结构上的修改。)这一般通过对自然封装该列表的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedList 方法将该列表“包装”起来。这最好在创建时完成,以防止意外对列表进行不同步的访问:
List list = Collections.synchronizedList(new ArrayList(...));
特别注意:
@SuppressWarnings( “unchecked”, “rawtypes” )
public static void iteratorTest()
List a1 = new ArrayList<String>();
a1.add(“List01″);
a1.add(“List02″);
a1.add(“List04″);
a1.add(“List05″);
Iterator i1 = a1.iterator();
while (i1.hasNext())
Object obj = i1.next();
if (obj.equals(“List02″))
a1.add(“List03″);
System.out.print(“集合:\\n\\t”+a1+”\\n”);
运行出错:
问题描述很清楚,在创建迭代器之后,除非通过迭代器自身的 remove 或 add 方法从结构上对列表进行修改,否则在任何时间以任何方式对列表进行修改,迭代器都会抛出 ConcurrentModificationException。
改为:
@SuppressWarnings( "unchecked", "rawtypes" )
public static void listIterator()
List a1 = new ArrayList<String>();
a1.add("List01");
a1.add("List");
a1.add("List03");
a1.add("List04");
ListIterator l1 = a1.listIterator();
while (l1.hasNext())
Object obj = l1.next();
if (obj.equals("List"))
l1.remove();
l1.add("List02");
System.out.print("集合:\\n\\t"+a1+"\\n");
Vector非常类似ArrayList。早在JDK1.1的时候就出现了,以前没有所谓的List接口,现在此类被改进为实现List接口。但与新的Collection不同的是,Vector是同步的。Vector在像查询的性能上会比ArrayList开销大。
从方法上看几乎没差别,同样注意的是:此接口的功能与 Iterator 接口的功能是重复的。此外,Iterator 接口添加了一个可选的移除操作,并使用较短的方法名。新的实现应该优先考虑使用 Iterator 接口而不是 Enumeration 接口。
LinkedList及其与ArrayList性能比
LinkedList与ArrayList一样实现List接口,LinkedList是List接口链表的实现。基于链表实现的方式使得LinkedList在插入和删除时更优于ArrayList,而随机访问则比ArrayList逊色些。LinkedList实现所有可选的列表操作,并允许所有的元素包括null。除了实现 List 接口外,LinkedList 类还为在列表的开头及结尾 get、remove 和 insert 元素提供了统一的命名方法。这些操作允许将链接列表用作堆栈、队列或双端队列。
LinkedList和ArrayList的方法时间复杂度总结如下图所示。
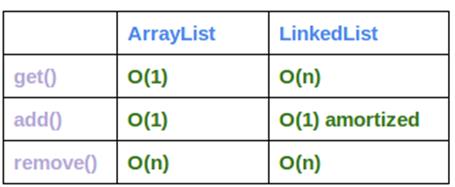
LinkedList介绍:
LinkedList相对ArrayList添加了更多的方法,这些方法也很好的为使用LinkedList实现队列、双向队列、栈等提供了很好的支持。
LinkedList底层使用双向链表实现,一个节点持有前一个节点的引用、需要保存的元素的引用和后一节点的引用。空的LinkedList中first和last都为null,只有一个元素(节点)的LinkedList中first->next==last、last.prev==first。
所有操作的底层就是对链表的操作,对链表实现了各种增删改查的方法,然后对外提供了更多操作行为,如队列的操作,栈的操作和普通List的操作,这些操作可能实际的实现是相同的,但是对外提供不同的接口以展示更多的行为。
LinkedList是一个很强大的工具。
虽然LinkedList提供了很多操作,诸如栈和队列的,但有时候我们任然希望一个功能更专一的栈或队列,下面就演示以代理模式通过LinkedList实现的栈和队列:
//LinkedList的使用
public class TestUse
public static void main(String[] args)
//栈
Stack<Integer> stack = new Stack<Integer>();
for(int i=0;i<10;i++)
stack.push(i);
System.out.println(stack.peek());
System.out.println(stack.peek());
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
Iterator<Integer> iterator = stack.iterator();
while(iterator.hasNext())
System.out.print(iterator.next());
System.out.println();
//队列
Queue<Integer> queue = new Queue<Integer>();
for(int i=0;i<10;i++)
queue.enqueue(i);
System.out.println(queue.peek());
System.out.println(queue.peek());
System.out.println(queue.dequeue());
System.out.println(queue.dequeue());
System.out.println(queue.dequeue());
iterator = queue.iterator();
while(iterator.hasNext())
System.out.print(iterator.next());
//很使用使用代理模式利用LinkedList实现一个栈
class Stack<T> implements Iterable<T>
private LinkedList<T> stack = new LinkedList<T>();
public T pop()//出栈,会删除栈顶元素
return stack.poll();
public T peek()//出栈,但不删除栈顶元素
return stack.peek();
public void push(T t)//入栈
stack.push(t);
@Override
public Iterator<T> iterator()
return stack.iterator();
//很使用使用代理模式利用LinkedList实现一个队列
class Queue<T> implements Iterable<T>
private LinkedList<T> queue = new LinkedList<T>();
public void enqueue(T t)
queue.offer(t);
public T dequeue()
return queue.poll();
public T peek()
return queue.peek();
@Override
public Iterator<T> iterator()
return queue.iterator();
关于List的总结:
首先LinkedList是双向链表,ArrayList和vertor是数组
Vector和ArrayList
1、vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。
2、记住并发修改异常 java.util.ConcurrentModificationException ,优先考虑ArrayList,除非你在使用多线程所需。
Aarraylist和Linkedlist
1、对于随机访问get和set,ArrayList觉得优于LinkedList,LinkedList要移动指针。
2、于新增和删除操作add和remove,LinedList比较占优势,ArrayList要移动数据。
3、
单条数据插入或删除,ArrayList的速度反而优于LinkedList.原因是:LinkedList的数据结构是三个对象,组大小恰当就会比链表快,直接赋值就完了,不用再设置前后指针的值。
若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
Queue:
一种队列则是双端队列,支持在头、尾两端插入和移除元素,主要包括:ArrayDeque、LinkedBlockingDeque、LinkedList。另一种是阻塞式队列,队列满了以后再插入元素则会抛出异常,主要包括ArrayBlockQueue、PriorityBlockingQueue、LinkedBlockingQueue。虽然接口并未定义阻塞方法,但是实现类扩展了此接口。
Map:
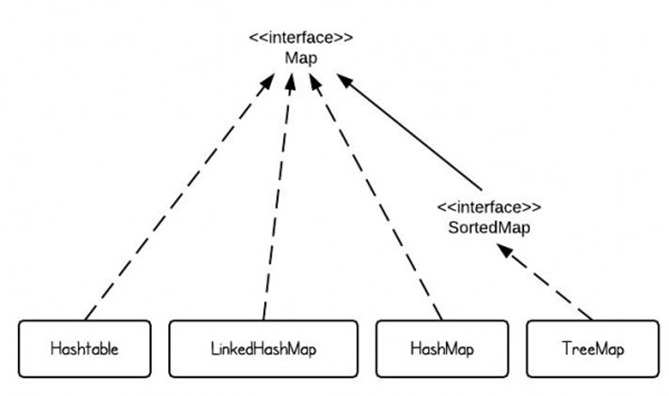
Map:
是一个键值对的集合。也就是说,一个映射不能包含重复的键,每个键最多映射到一个值。该接口取代了Dictionary抽象类。实现map的有:HashMap、TreeMap、HashTable、Properties、EnumMap。
HashMap 和 TreeMap
Map,又称映射表,是将键映射到值的对象。有四种实现Map接口并且经常使用的Map集合为:HashMap,TreeMap,Hashtable 和 LinkedHashMap.
1、一个映射不包含重复的键。
2、每个键最多只能映射到一个值。
HashMap
HashMap是基于哈希表的Map接口的实现。其对键进行散列,散列函数只能作用于键。
HaspMap的键必须唯一,同样其同一个键不能存放两个值,如果对同一个键两次调用put方法,第二个值会取代第一个值。同样是允许使用 null 值和 null 键。
下面有三点是HashMap重要之处:
1、HashMap的构造函数
HaspMap构造函数涉及两个参数:初始容量和加载因子。初试容量是哈希表创建时的其中桶的含量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。这两个参数都是影响HashMap的性能。默认构造一个具有默认初始容量 (16) 和默认加载因子 (0.75)。默认加载因子 (.75) 在时间和空间成本上是一种折衷的考虑。
2、和上次总结的Set都差不多,这个HashMap线程是不安全不同步的。如果想防止意外发生,则设置成同步即可:
Map m = Collections.synchronizedMap(new HashMap(...));
3、不同步的话,意味着存在快速失败导致的并发修改异常。
TreeMap
reeMap使用树结构实现(红黑树),集合中的元素进行排序,但是添加、删除和包含的算法复杂度为O(log(n))。
1、TreeMap实现了SortedMap,顾名思义,其表示为有排序的集合。
2、同样其同一个键不能存放两个值,如果对同一个键两次调用put方法,第二个值会取代第一个值。
总结:
1. HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。集合框架”提供两种常规的Map实现:HashMap和TreeMap (TreeMap实现SortedMap接口)。
2. 2.在Map 中插入、删除和定位元素,HashMap 是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。 这个TreeMap没有调优选项,因为该树总处于平衡状态。
接口总结:
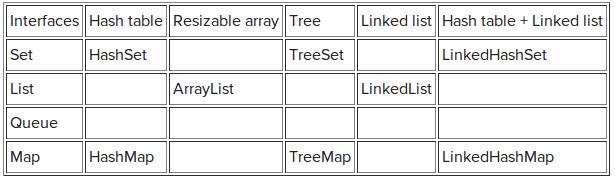
总结:
Vector和ArrayList
1,vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高。
2,如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度的50%.如过在集合中使用数据量比较大的数据,用vector有一定的优势。
3,如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,都是0(1),这个时候使用vector和arraylist都可以。而如果移动一个指定位置的数据花费的时间为0(n-i)n为总长度,这个时候就应该考虑到使用linklist,因为它移动一个指定位置的数据所花费的时间为0(1),而查询一个指定位置的数据时花费的时间为0(i)。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要设计到数组元素移动等内存操作,所以索引数据快插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快!
Aarraylist和Linkedlist
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
HashMap与TreeMap
1、HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。HashMap中元素的排列顺序是不固定的)。
2、 HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。集合框架”提供两种常规的Map实现:HashMap和TreeMap (TreeMap实现SortedMap接口)。
3、在Map 中插入、删除和定位元素,HashMap 是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。 这个TreeMap没有调优选项,因为该树总处于平衡状态。
hashtable与hashmap
1、历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现 。
2、同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的 。
3、值:只有HashMap可以让你将空值作为一个表的条目的key或value 。
参考博客:
主要参考泥瓦匠的博客还有其他的两篇博客,链接如下:
http://www.bysocket.com/?p=424
http://anxpp.com/index.php/archives/656/
http://blog.csdn.net/softwave/article/details/4166598
以上是关于38java的集合框架(容器框架)的主要内容,如果未能解决你的问题,请参考以下文章