TeaTalk·Online 演讲实录 | 圆满完结 大数据+云原生,再度风云起
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TeaTalk·Online 演讲实录 | 圆满完结 大数据+云原生,再度风云起相关的知识,希望对你有一定的参考价值。


4月6日,TeaTalk· Online开源论道系列活动第2期——“论道云原生,且看大数据江湖”线上直播成功举办。本次直播从“从Hadoop到云原生”、“云原生大数据的关键技术”、“云原生大数据分析Lakehouse”这三个方面围绕技术发展的趋势,深度融合云原生技术,碰撞出彩,同时也对发展未来进行展望。
以下为中国移动云能力中心,大数据技术专家陶捷老师演讲实录。

大数据技术发展到今天已经有十多年的时间,如今大数据技术已经从新兴前沿技术逐渐成熟成为普惠性技术。同时现今云原生技术又在如火如荼的发展,那么大数据技术,尤其是基于Hadoop开源生态的技术如何与云原生技术结合并迸发出火花,是人们关注的热点。
这次分享主要包括几个方面:
-
讲解基于开源的Hadoop技术发展以及和云原生技术的渊源
-
讲解大数据云原生的关键技术,这里主要包括大数据组件容器化、计算存储分离、数据湖&湖仓一体方面
-
介绍移动云云原生大数据分析Lakehouse产品,这个是大数据与云原生结合的典型案例
-
对云原生大数据进行总结和展望
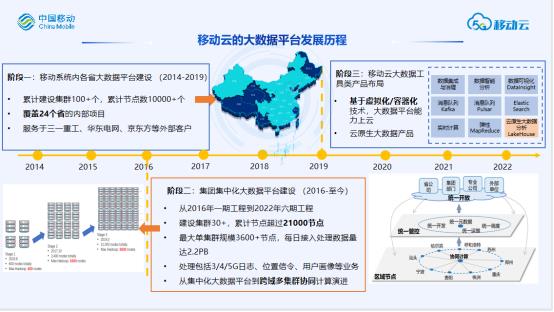
中国移动云能力中心从2014年开始大数据平台相关工作,到今天已经有8年的积累了。从发展的历程来看,整体分为了三个阶段:
阶段一:从14年到19年,主要为移动体系内各省建设大数据平台,覆盖了全国2/3的省份,累计建设集群超过100个,节点数超过10000个,同时也服务于部分外部客户。
阶段二:从16年至今,主要为集团建设统一的大数据平台,目前节点已经超过21000个,并且正在从集中化大数据平台演进到跨域多集群协同计算的架构。
阶段三:从19年云改开始到现在,将大数据能力上到移动云,同时打造云原生的大数据产品。
整体上目前移动云的大数据平台是公有云大数据产品和私有化大数据平台并举的发展状态。
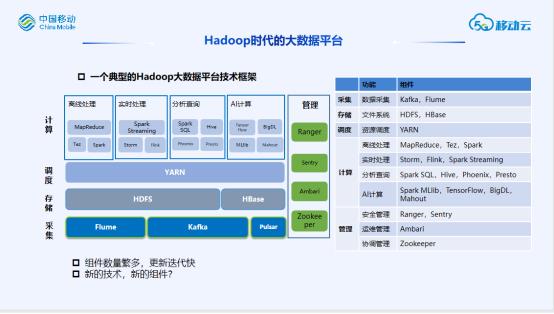

关于Hadoop大数据平台技术
Hadoop自07年诞生到现在已经第十五个年头,传统Hadoop体系的大数据平台基于Hadoop开源生态的诸多组件,各种组件覆盖数据采集、存储、计算、调度、管理等方面,并且组件不断迭代,新技术不断涌现。在实时计算、批量处理、消息队列等领域,Flink、Spark、Pulsar等技术正在逐步取代Storm、MapReduce、Kafka等技术。然而近年来实际组件迭代升级的速度实际是在不断放缓的,更多随着Spark、Flink等技术自身不断演进成熟而提升。
另一方面,传统Hadoop平台主要通过物理化部署,并且采用存算一体的架构,组件通过管理平台部署,计算资源通过Yarn来管理和调度。主要存在以下几个方面问题:
-
资源弹性伸缩不足
-
资源利用率低
-
资源隔离性差
-
自动化运维成本高
-
不同组件管理方式不统一
解决这些问题往往更多需要依靠整体架构上的演进而不仅仅是组件的更新。
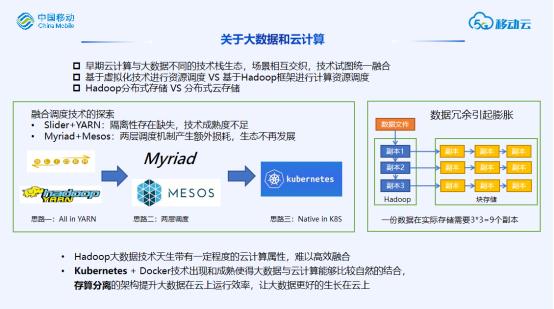

关于大数据与云计算
大数据与云计算的融合早期就经常会产生讨论。实际的情况是这两种技术的生态是不同的,但是解决的场景有所重叠,相互交织,所以试图从技术上进行统一融合,典型的在于两个方面:
1、计算资源调度
在云计算场景通常采用虚拟化技术对资源进行调度,而在大数据场景会采用Hadoop的框架提供资源调度能力。我们曾经也尝试过Slider+Yarn以及Myriad+Mesos的方式进行统一调度,但是前者隔离性上存在缺失,后者机制上是两层调度,产生额外损耗,并且两个方案社区成熟度都很低,很快都不在发展了。如今随着Kubernetes+Docker技术的出现和成熟,大数据组件能够更自然的和计算资源调度相结合,也逐渐成为主流的调度方案。
2、存储方向
在大数据和云计算的场景,存储都非常重要,并且都是需要基于分布式存储。分布式存储对数据可靠性的要求,需要数据通常3副本的冗余,而直接将大数据的存储映射到云上的分布式存储,往往会产生数据膨胀,一份原始数据产生3*3=9份真实数据,从而产生大量不必要的成本,而解决的方案通常是需要存算分离的方式。
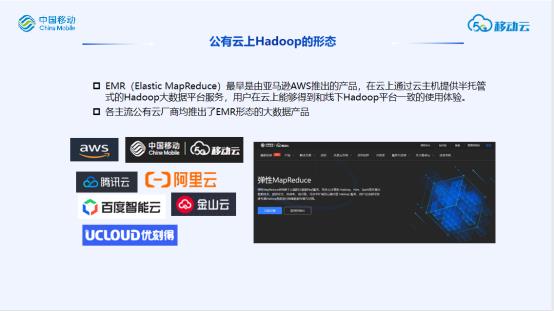
大数据在公有云上的典型形态就是EMR这类产品,在云上通过云主机提供半托管式的服务,用户能够得到和线下Hadoop平台一样的用户体验。最早由AWS退出,如今包括移动云在内的主流云厂商也都提供了类似的产品。
EMR这样的云产品能够一定程度上利用云的资源为大数据平台提供弹性伸缩的能力,但是还远达不到云原生的状态。
所谓云原生的大数据要能够天然与云计算技术相结合,最高效的利用云上的资源服务于大数据的业务场景,用户能够像使用水电煤一样使用大数据的能力。其主要的特征包括:存储与云深度融合,计算Serverless化,极低的使用门槛。
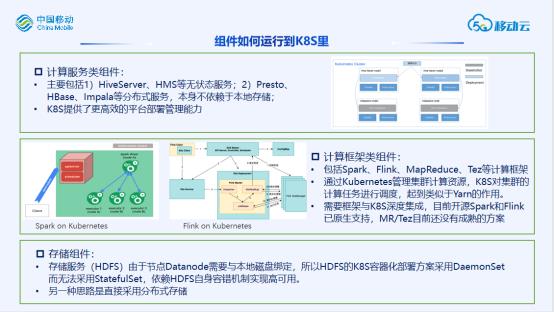

大数据组件容器化
大数据组件容器化是一个发展的趋势,如今越来越多的企业尝试将大数据组件运行到K8S里,从而也有大量业界的实践工作。相对于虚拟化技术,容器化技术能够支持更快更轻量级的部署,服务启动时间从分钟级降低到秒级,同时性能损耗也从10%降低到5%左右。
我们总结了一下大数据组件容器化带来的优势:
1、组件服务快速灵活部署:服务运行在容器镜像之中,隔离了服务对平台环境的依赖,部署快速,服务秒级启动能够方便支持多实例、多版本的需求。
2、资源管理,弹性伸缩,提升利用率:K8S管理集群资源,能够支持服务间资源隔离(yarn能做到运行计算任务之间隔离,但是无法与例如hbase这样服务进行隔离),同时各种业务(离线任务、在线服务、实时计算)之间混合部署。同时能够支持各种调度策略,支持纳管不同资源(不同规格服务器、GPU等特殊资源)。
3、更高效的自动化运维能力:Kubernetes 自身框架能够对服务可用性提供一定保证(例如服务pod挂掉、节点宕机等场景),同时可以通过自定义服务存活性探针来定义自动化运维的逻辑。与Prometheus或ELK等成熟生态集成。
但是在大规模物理化部署场景里,容器化大数据平台也存在一定局限性。在平台层面的弹性伸缩提升有限。物理化部署环境里资源的供给取决于物理设备的到位,而部署Hadoop还是K8s并不能对快速集群扩容带来改变。同时集群规模越大,带来的性能损耗也会随之放大,另外因为引入K8S一层服务,在超大规模下稳定性方面也会带来挑战。
我们总结了一下各种不同服务运行到K8S中的不同方式,其中计算服务类组件可以比较自然的运行到K8S中。计算框架类服务需要要求框架本身对K8S的支持,而目前flink、spark等框架能够原生支持,而MapReduce、Tez框架并没有成熟的方案。对于一个同时需要支持不同计算框架的平台通常可以采用两种方案来支持:
-
资源统一管理,但是任务会经过K8S/Yarn两层调度,产生额外开销。
-
采用组件原生支持调度框架,但是需要预先划分好yarn和k8s两个资源池,资源池之间难以负载均衡。

另外我们在集约化部署的场景,集群私有化部署,但是数据量没那么大,也不具备公有云上基础设施,通过大数据容器化方式部署,能够在高效利用物理资源的方面起到非常明显的作用。
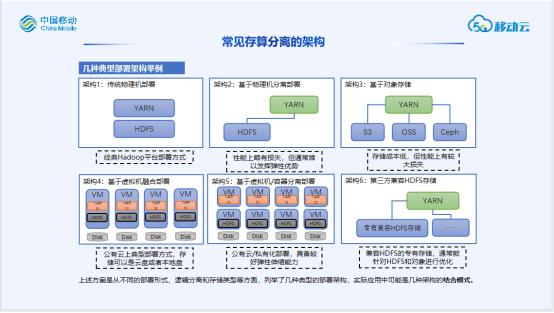

计算存储分离
计算存储分离更多是一种设计理念,而非具体的技术或者产品。我们总结了常见多种存算分离架构。存算分离核真正关心的问题在于:
-
真正降低存储带来的成本(软硬件单位成本、适应不同性能需求下的成本、资源利用率/弹性伸缩带来的成本)
-
与现有大数据平台体系融合(是否兼容当前接口协议、能否与现有存储良好并存、能否满足当前对性能和扩展性的需求)
从而实际上存算分离需要解决的是两个问题:
-
更高性价比的存储
-
数据统一访问方案
大数据场景提供一种更高性价比的存储,主流有两种方向:1、构造一种兼容HDFS的分布式存储,并通常设计会针对HDFS存在性能瓶颈(例如NN单点、小文件)进行优化,辅以通用的优化技术:缓存、SSD、EC、压缩等,往往可能还会采用软硬件一体的设计。2、接入现有低成本存储(通常是对象存储),这种方案实际是解决对象存储在大数据场景性能差的问题,这种方案在云上场景具有更大价值(成本更具有优势)。
数据统一访问的价值在于,当引入新的存储(即使兼容HDFS)的时候能够尽可能对上层计算透明,减少用户感知和改造成本。同时统一数据访问往往可以结合小文件合并、冷热数据等优化。往往可以通过代理访问(RBF),缓存系统(Alluxio)等方案实现。

一个具体的案例,就是移动云Hbase产品,我们从本地物理化部署的方式到云上存算分离架构方式,再到存储使用云上对象存储。这个也是产品云原生程度逐步提升的过程。
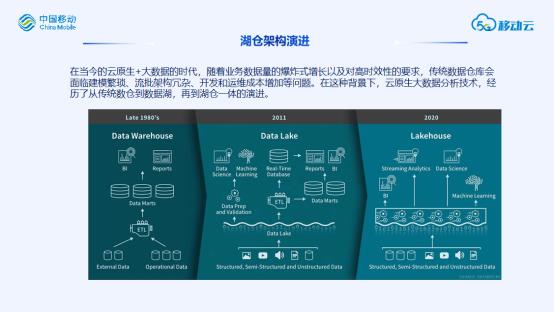

数据湖&湖仓一体
数据湖或者湖仓一体也是近两年来非常热门的技术话题。我们总结数据平台整体的架构演进可以是从传统数仓(MPP)到传统数据湖(Hadoop)再到湖仓一体(Lakehouse)的过程。
数据湖核心观点在于采用统一存储存放原始数据,支持各种格式(结构化、半结构化、非结构化)数据,并提供统一的数据分析处理能力。
我们当前典型的Hadoop架构的大数据平台,本身就是一种数据湖,具备一定的数据湖特质,然而和我们谈论的湖仓还是有一些区别:
-
当前底层存储单一,主要以HDFS为主,未来演进为支持多种介质,多种类型数据的统一存储系统。
-
当前根据业务分多个集群,之间大量数据传输,未来演进到统一存储系统,降低集群间传输消耗。
-
当前计算框架以MR/Spark为主,未来演进在数据湖上直接构建更多计算框架和应用场景。
在公有云上,数据湖和云数据仓库各自有其热门的产品:
数据湖产品:亚马逊LakeFormation、阿里云DLA、华为云DLI、腾讯云DLC
云数仓产品:亚马逊RedShift、阿里云MaxCompute、SnowFlake、ClickHouse
我们认为数据湖和数据仓库总体是朝相同方向演进,但是侧重点有所不同:数据湖具有更好的灵活性,支持各种类型数据,适用于初创期企业需要快速灵活进行数据探索场景;云数仓具有更高性价比和更完备数据规范治理能力,适用于逐渐成熟快速成长型企业需要更高效处理大数据业务的场景。
另一方面技术的趋势是湖仓一体:一方面数据湖和数据仓库的生态更好的交互融合,湖能访问仓,仓能融入湖;另一方面数据湖和数据仓库产品能力相互延伸扩展,像仓一样使用湖,仓能扩展成湖。
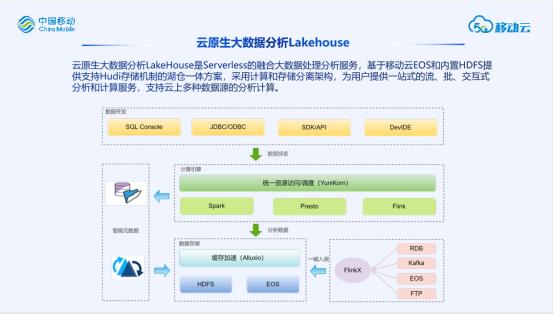

云原生大数据分析Lakehouse
云原生大数据分析Lakehouse是移动云自主研发的大数据平台类产品,融合了湖仓一体、存算分离、容器化等云原生关键技术,为客户提供一站式的大数据服务能力。
Lakehouse的主要特征包括:
-
计算存储分离:我们计算基于K8S调度,存储支持HDFS和移动云对象存储EOS两种,并通过Alluxio进行缓存加速,计算存储分别计费,计算不足扩计算,存储不足扩存储。
-
Serverless:区别于传统资源类服务会按照使用的内存、cpu进行规格计费,Lakehouse对客户可以做到按实际使用的资源量进行计费,用户可以不必精细预估好需求资源,订购以后只有真正运行作业才会记录使用并收取费用,不用不收费。同时即使需要扩缩容规格,也是秒级完成。
-
All In SQL:传统大数据平台需要用户对大数据组件具备一定的开发能力,而Lakehouse采用通用的SQL作为交互的输入,用户只要会写SQL就能进行开发,像使用数据库一样开发大数据。
-
智能元数据:支持不同数据源元数据统一管理,同时具备元数据发现能力,对于存储在对象存储上无Schema的数据,能够自动爬取格式并转化为结构化数据。自动化工作减少大量ETL任务的繁琐配置。

总结与展望
1、传统Hadoop生态大数据技术已趋于成熟进入普惠期,云原生的技术能够在弹性伸缩、资源利用率提升、运维管理方面进行有效提升。
2、基于K8S容器化提升弹性、结合云上对象存储降低成本是当前大数据云原生的主要趋势。
3、云原生架构的LakeHouse能更好的利用云的资源提供大数据服务能力,并且会逐步降低大数据技术的使用门槛。
4、私有化大数据和公有云大数据场景差异使得“云原生”并非解决所有问题的银弹,但整体发展趋势仍然趋于统一。

扫码可得活动回顾及专家PPT
这一期的 TeaTalk· Online 我们跟随陶老师,乘着侠义时代的风云,从微毫处见识了盛大的大数据江湖,非常感谢陶老师带我们领略云原生的魅力所在。作为开发者社区系列活动的重要一环,未来TeaTalk·Online线上直播栏目将更加专注细分技术领域,进一步扩展知识广度、技术深度,加速拥抱开发者。
继续关注我们吧,我们下一期不见不散!
诚邀加入移动云开发者社区
共筑移动云生态!

扫码进入
以上是关于TeaTalk·Online 演讲实录 | 圆满完结 大数据+云原生,再度风云起的主要内容,如果未能解决你的问题,请参考以下文章