中文文本分类-朴素贝叶斯
Posted 普通网友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文文本分类-朴素贝叶斯相关的知识,希望对你有一定的参考价值。
原创作品,出自 “晓风残月xj” 博客,欢迎转载,转载时请务必注明出处(http://blog.csdn.net/xiaofengcanyuexj)。
由于各种原因,可能存在诸多不足,欢迎斧正!
最近在想怎么利用数据挖掘的方法进行评论自动审核,分类为垃圾评论和非垃圾评论,完成自动审核功能。实现中文文本分类,支持文件、文本分类,基于多项式分布的朴素贝叶斯分类器。由于工作实际应用是二分类,加之考虑到每个分类属性都建立map存储词语向量可能引起的内存问题,所以目前只支持二分类。当然,直接复用这个结构扩展到多分类也是很容易。之所以自己写,主要原因是没有仔细研读mahout、weka等代码,不能灵活地进行中文分词、停用词过滤、词频统计、TF-IDF等,也就是向量化和特征提取没有自己手写相对灵活。
一、贝叶斯分类器
贝叶斯分类器是基于先验概率与条件概率进行概率计算的分类器。X是特征属性,Y是分类属性,P(Y|x0,x1....xn)是X在取值x0,x1,...xn的条件下Y发生的概率,成为P(Y)的后验概率,P(Y)的先验概率。实际在计算P(Y|x0,x1....xn)的时候由于维度太高,至少需要考虑特征属性与分类属性的所有搭配情况,计算量大而且无法对待分类数据集进行全面覆盖。
1.1朴素贝叶斯
朴素贝叶斯就是假设特征属性的取值彼此独立,即没有相互作用关系。如果P(AB|C)=P(A|C)P(B|C),则A和B在C条件独立。贝叶斯定理也是贝叶斯基于先验概率计算条件概率的重要理论基础,如下是贝叶斯定理:
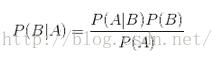
待分类的特征属性
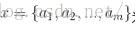
类别属性
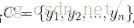
1)、在有分类属性的数据集上,计算:
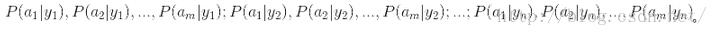
2)、在给定特征属性数据上,有贝叶斯定理:
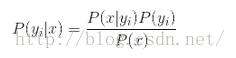
3)、已知P(x)是常数,加之特征属性间条件独立,只需求
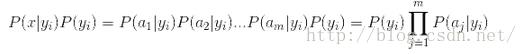
二、中文文本分类
中文分本分类通用方法是将文本按照一定规则编码成向量形式:特征属性和分类属性。具体的是利用一定的分词规则将文本切成一个个单词,然后去除停用词,如“了”、“的”等 没有实际语义含义的词汇,接着可以从剩余的词中选出尽可能标识分类属性的词汇降低维度,选取出来的词语组成特征属性。可以假设不同词汇的出现是相对独立的,于是就转换成了标准的朴素贝叶斯分类模型。
2.1.分词
下面是知乎上一段关于中文分词理论上说明,觉得通俗有用,在此摘抄,标识感谢。原贴。中文分词算法大概分为两大类
1)、第一类是基于字符串匹配,即扫描字符串,如果发现字符串的子串和词相同,就算匹配。
这类分词通常会加入一些启发式规则,比如“正向/反向最大匹配”, “长词优先” 等策略。这类算法优点是速度块,都是O(n)时间复杂度,实现简单,效果尚可。也有缺点,就是对歧义和未登录词处理不好。歧义的例子很简单"长春市/长春/药店" "长春/市长/春药/店".未登录词即词典中没有出现的词,当然也就处理不好。ikanalyzer,paoding 等就是基于字符串匹配的分词。
2)、第二类是基于统计以及机器学习的分词方式
这类分词基于人工标注的词性和统计特征,对中文进行建模,即根据观测到的数据(标注好的语料)对模型参数进行估计,即训练。 在分词阶段再通过模型计算各种分词出现的概率,将概率最大的分词结果作为最终结果。常见的序列标注模型有HMM和CRF。这类分词算法能很好处理歧义和未登录词问题,效果比前一类效果好,但是需要大量的人工标注数据,以及较慢的分词速度。ICTCLAS是基于HMM的分词库。
2.2.去停用词
英文是以词为单位的,词和词之间是靠空格隔开,而中文是以字为单位,字连起来组成词语。为了降低时空复杂度,提高存储和计算效率,会自动忽略某些词,即为停用词。停用词包括过滤词,如特定时期的黄色、政治等敏感关键词。停用词主要有两类:
1)、过于频繁的词语,包括"然而"、"下面"等等。
2)、文本中出现频率很高,但没有语义含义的词,包括副词、介词、连词等等。
关于停用词,可以结合具体的数据集进行设定,如电商的禁用词等等。很多通用的停用词集合,这个个人认为还不错,可用停用词集合
2.3.特征提取
文本分词并出去停用词之后,剩下的都可以看作是有效的词语,可以初步作为提取出来的特征属性。但是,需要进行一下处理,可以给不同的词语设置不同的权重,比较通用的方法是TF-IDF算法。
TF-IDF是采用统计思想,用以评估词语相对文件集中某个文件的重要程度。字词的重要性与它在文件中出现的次数成正比增加,但同时会与着它在语料库中出现的频率成反比下降,如下面的公式。
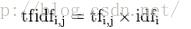
本次实验由于使用朴素贝叶斯分类,所以在计算条件概率的时候使用了类似TF-IDF的思想,所以赋予权重的时候并未直接采用该方法。而是人为设定固定的权重矩阵,毕竟是某个实际垂直场景的应用,我们知道那些词汇相对重要。
2.4.建立模型
依据上面的公式,朴素贝叶斯需要知道先验概率和单个属性取值对应的条件概率,然后计算后验概率,下面是本次使用的概率计算方法。当时,这样计算的概率在文本比较稀疏的时候概率偏小,可能存在很多误差,实际展示的时候需要做归一化处理。
1)、先验概率P(y)= 类y下单词总数/整个训练样本的单词总数
2)、类条件概率P(xi|y)=(类y下单词xi在各个文档中出现过的次数之和+1)/(类y下单词总数+向量的维度)
3)、P(y|xi)=P(y)*P(xi|y)/P(xi)等价于P(y)*P(xi|y)
其中为了防止某个词语xi没有出现,导致该类的条件概率P(xi|y)为0,需要一些平滑技术,本次选择Add-one (Laplace) 平滑技术,即P(xi|y)=(类y下单词xi在各个文档中出现过的次数之和+1)/(类y下单词总数+向量的维度),保证分子不为0。关于平滑技术,也有很多地方可以考虑;当时,上面P(xi|y)的求取也借用了TF-IDF的思想。
三、代码
package com.csdn.jinxu.ChineseTextClassifier;
import com.google.common.base.Splitter;
import com.google.common.collect.Maps;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import org.ansj.util.FilterModifWord;
import org.apache.commons.lang.StringUtils;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
/**
* 实现描述:ansj中文分词
*
* @author jin.xu
* @version v1.0.0
* @see
* @since 16-9-12 下午7:17
*/
public class AnsjSpliter
/**
* 分词
* @param file 文档文件或者目录
* @return
* @throws IOException
*/
public static Map<String,Integer> process(File file) throws IOException
Map<String, Integer> wordScoreMap = Maps.newHashMap();
if(file.isDirectory())
for(File tmp:file.listFiles())
Map<String,Integer> tmpWordScoreMap=process(tmp);
for (Iterator iterator = tmpWordScoreMap.entrySet().iterator(); iterator.hasNext(); )
Map.Entry entry = (Map.Entry) iterator.next();
String key=(String)entry.getKey();
Integer value=(Integer)entry.getValue();
if (wordScoreMap.containsKey(key))
wordScoreMap.put(key,wordScoreMap.get(key) +value);
else
wordScoreMap.put(key,value);
else
BufferedReader reader = new BufferedReader(new FileReader(file));
String tempString = null;
while ((tempString = reader.readLine()) != null)
wordScoreMap=process(tempString,wordScoreMap);
reader.close();
return wordScoreMap;
/**
* 分词
* @param inputText 文档文本
* @return
* @throws IOException
*/
public static Map<String,Integer> process(String inputText) throws IOException
Map<String, Integer> wordScoreMap = Maps.newHashMap();
process(inputText,wordScoreMap);
return wordScoreMap;
/**
* 过滤停用词
* @param file 停用词文件
* @return
* @throws IOException
*/
public static HashMap<String,String> filter(File file) throws IOException
BufferedReader reader = new BufferedReader(new FileReader(file));
HashMap<String,String>stopWordMap= Maps.newHashMap();
String tempString = null;
while ((tempString = reader.readLine()) != null)
stopWordMap.put(tempString.trim() , "_stop");
reader.close();
return stopWordMap;
/**
* 过滤停用词
* @param inputText 停用词文本,以逗号','隔开
* @return
* @throws IOException
*/
public static HashMap<String,String> filter(String inputText) throws IOException
HashMap<String,String>stopWordMap= Maps.newHashMap();
List<String> wordList= Splitter.on(',').splitToList(inputText);
if(wordList.size()>0)
for (String word : wordList)
stopWordMap.put(word, "_stop");
return stopWordMap;
/**
* 分词
* @param inputText 文档文本
* @param wordScoreMap 单词-频数映射
* @return
* @throws IOException
*/
private static Map<String,Integer> process(String inputText,Map<String,Integer>wordScoreMap) throws IOException
for (Term term : FilterModifWord.modifResult(ToAnalysis.parse(inputText)))
if(StringUtils.isNotBlank(term.getName().trim()))
if (wordScoreMap.containsKey(term.getName()))
wordScoreMap.put(term.getName(), wordScoreMap.get(term.getName()) + 1);
else
wordScoreMap.put(term.getName(), 1);
return wordScoreMap;
package com.csdn.jinxu.ChineseTextClassifier;
import java.util.Iterator;
import java.util.Map;
/**
* 实现描述:朴素贝叶斯分类
*
* @author jin.xu
* @version v1.0.0
* 1.先验概率P(y)= 类y下单词总数/整个训练样本的单词总数
* 2.类条件概率P(xi|y)=(类y下单词xi在各个文档中出现过的次数之和+1)/(类y下单词总数+向量的维度)
* 3.P(y|xi)=P(y)*P(xi|y)/P(xi)等价于P(y)*P(xi|y)
* @see
* @since 16-9-13 下午5:44
*/
public class NBClassifier
private Map<String, Double> wordWeightMap;
private Map<String, Integer> yesDocMap;
private Map<String, Integer> noDocMap;
private double yesPrioriProb;
private double noPrioriProb;
private Long wordDifCount;
private Long yesClassWordCount;
private Long noClassWordCount;
public NBClassifier(Map<String, Integer> yesDocMap, Map<String, Integer> noDocMap, Map<String, Double> wordWeightMap)
this.wordWeightMap = wordWeightMap;
this.wordDifCount = (long) this.wordWeightMap.size();//?????????????????
this.yesDocMap = yesDocMap;
this.noDocMap = noDocMap;
yesPrioriProb = 1.0 * yesDocMap.size() / (yesDocMap.size() + noDocMap.size());
noPrioriProb = 1.0 * noDocMap.size() / (yesDocMap.size() + noDocMap.size());
this.yesClassWordCount = getWordCount(yesDocMap);
this.noClassWordCount = getWordCount(noDocMap);
/**
* 增量训练
*
* @param docMap 待加入训练集的数据
* @param isbYes 对应标签
*/
public void train(Map<String, Integer> docMap, boolean isbYes)
if (isbYes)
this.yesDocMap = mergeDocMap(this.yesDocMap, docMap);
else
this.noDocMap = mergeDocMap(this.noDocMap, docMap);
yesPrioriProb = 1.0 * yesDocMap.size() / (yesDocMap.size() + noDocMap.size());
noPrioriProb = 1.0 * noDocMap.size() / (yesDocMap.size() + noDocMap.size());
this.yesClassWordCount = getWordCount(yesDocMap);
this.noClassWordCount = getWordCount(noDocMap);
/**
* 分类文档
*
* @param wordFreMap 待分类文档对应的单词-频数映射
* @return
*/
public double[] classify(Map<String, Integer> wordFreMap)
double[][] conditionalProb = new double[2][wordFreMap.size()];
conditionalProb[0] = getProbMatrix(yesDocMap, yesClassWordCount, wordFreMap);
conditionalProb[1] = getProbMatrix(noDocMap, noClassWordCount, wordFreMap);
double[] classProb = yesPrioriProb, noPrioriProb;
for (int i = 0; i < classProb.length; ++i)
for (int j = 0; j < wordFreMap.size(); ++j)
classProb[i] *= conditionalProb[i][j];
return classProb;
/**
* 概率归一化
*
* @param classProb 原概率列表
* @return
*/
public double[] normalized(double[] classProb)
double[] classProbAfterNor = new double[classProb.length];
double sum = 0.0;
for (int i = 0; i < classProb.length; ++i)
sum += classProb[i];
for (int i = 0; i < classProb.length; ++i)
classProbAfterNor[i] = classProb[i] / sum;
return classProbAfterNor;
/**
* 将文档合并到训练文档集
*
* @param allDocMap 训练文档集
* @param docMap 待增量添加文档
* @return
*/
public Map<String, Integer> mergeDocMap(Map<String, Integer> allDocMap, Map<String, Integer> docMap)
for (Iterator iterator = docMap.entrySet().iterator(); iterator.hasNext(); )
Map.Entry entry = (Map.Entry) iterator.next();
String key = (String) entry.getKey();
Integer value = (Integer) entry.getValue();
if (allDocMap.containsKey(key))
allDocMap.put(key, allDocMap.get(key) + value);
else
allDocMap.put(key, value);
return allDocMap;
/**
* 计算给定分类属性取值下每个特征属性不同取值的条件概率矩阵
*
* @param docMap 给定分类属性取值对应的单词-频数映射
* @param classWordCount 给定分类属性取值的单词总频数
* @param wordFreMap 待分类文档对应的单词-频数映射
* @return
*/
private double[] getProbMatrix(Map<String, Integer> docMap, Long classWordCount, Map<String, Integer> wordFreMap)
double[] probMatrixPerClass = new double[wordFreMap.size()];
int index = 0;
for (Iterator iterator = wordFreMap.entrySet().iterator(); iterator.hasNext(); )
Map.Entry entry = (Map.Entry) iterator.next();
String key = (String) entry.getKey();
Long tmpCount = 0l;
Double weight = 1.0;
if (docMap.containsKey(key))
tmpCount = (long) docMap.get(key);
if (this.wordWeightMap.containsKey(key))
weight = this.wordWeightMap.get(key);
probMatrixPerClass[index++] = 1.0 * (tmpCount + 1) * weight / (classWordCount + this.wordDifCount);
return probMatrixPerClass;
/**
* 计算docMap中所有单词频数和
*
* @param docMap 单词-频数映射
* @return
*/
private Long getWordCount(Map<String, Integer> docMap)
Long totalFrequency = 0l;
for (Iterator iterator = docMap.entrySet().iterator(); iterator.hasNext(); )
Map.Entry entry = (Map.Entry) iterator.next();
totalFrequency += (Integer) entry.getValue();
return totalFrequency;
package com.csdn.jinxu.ChineseTextClassifier;
import com.google.common.collect.Maps;
import org.ansj.util.FilterModifWord;
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* 实现描述:分类入口
*
* @author jin.xu
* @version v1.0.0
* @see
* @since 16-9-12 下午7:22
*/
public class MainApp
private static String YES_CLASS_INPUT_DIR = MainApp.class.getResource("/text/yes/").getPath();
private static String NO_CLASS_INPUT_DIR = MainApp.class.getResource("/text/no/").getPath();
private static String STOP_WORD_FILE = MainApp.class.getResource("/text/stop_word.txt").getPath();
private static String INPUT_FILE1 = MainApp.class.getResource("/text/test.txt").getPath();
public static void main(String[] args) throws IOException
HashMap<String, String> stopWordMap = AnsjSpliter.filter(new File(STOP_WORD_FILE));
FilterModifWord.setUpdateDic(stopWordMap);
Map<String, Integer> yesDocMap = AnsjSpliter.process(new File(YES_CLASS_INPUT_DIR));
System.out.println("yesDocMap" + yesDocMap);
Map<String, Integer> noDocMap = AnsjSpliter.process(new File(NO_CLASS_INPUT_DIR));
System.out.println("noDocMap" + noDocMap);
Map<String, Integer> testDocMap = AnsjSpliter.process(new File(INPUT_FILE1));
System.out.println("testDocMap" + testDocMap);
Map<String, Double> wordWeightMap = Maps.newHashMap();
NBClassifier classifier = new NBClassifier(yesDocMap, noDocMap, wordWeightMap);
double[] classProb = classifier.classify(testDocMap);
classProb = classifier.normalized(classProb);
print(classProb);
classifier.train(testDocMap, false);
classProb = classifier.classify(testDocMap);
classProb = classifier.normalized(classProb);
print(classProb);
private static void print(double[] classProb)
System.out.println("yes 概率" + classProb[0]);
System.out.println("no 概率" + classProb[1]);
if (classProb[0] > classProb[1])
System.out.println("yes");
else
System.out.println("no");
源代码github地址:https://github.com/XuJin1992/ChineseTextClassifier
路漫漫其修远兮,很多时候感觉想法比较幼稚。首先东西比较简单,其次工作也比较忙,还好周末可以抽时间处理这个。由于相关知识积累有限,欢迎大家提意见斧正,在此表示感谢!后续版本会持续更新…
以上是关于中文文本分类-朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章