请教,如何下载pdf文档。谢谢!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了请教,如何下载pdf文档。谢谢!相关的知识,希望对你有一定的参考价值。
我打开了网上的一个pdf文档,我想下载此文档,但网页上没有下载的按钮。在系统的临时文件夹里也找不到此文档。请教,如何下载此文档。谢谢!
参考技术A PDF全称Portable Document Format,是Adobe公司开发的电子文件格式。这种文件格式与操作系统平台无关,也就是说,PDF文件不管是在Windows,Unix还是在苹果公司的Mac OS操作系统中都是通用的。这一特点使它成为在Internet上进行电子文档发行和数字化信息传播的理想文档格式。越来越多的电子图书、产品说明、公司文告、网络资料、电子邮件开始使用PDF格式文件。PDF格式文件目前已成为数字化信息事实上的一个工业标准。Adobe公司设计PDF文件格式的目的是为了支持跨平台上的,多媒体集成的信息出版和发布,尤其是提供对网络信息发布的支持。为了达到此目的, PDF具有许多其他电子文档格式无法相比的优点。PDF文件格式可以将文字、字型、格式、颜色及独立于设备和分辨率的图形图像等封装在一个文件中。该格式文件还可以包含超文本链接、声音和动态影像等电子信息,支持特长文件,集成度和安全可靠性都较高。
PDF文件使用了工业标准的压缩算法,通常比PostScript文件小,易于传输与储存。它还是页独立的,一个PDF文件包含一个或多个“页”,可以单独处理各页,特别适合多处理器系统的工作。此外,一个PDF文件还包含文件中所使用的PDF格式版本,以及文件中一些重要结构的定位信息。正是由于 PDF文件的种种优点,它逐渐成为出版业中的新宠。
对普通读者而言,用PDF制作的电子书具有纸版书的质感和阅读效果,可以“逼真地”展现原书的原貌,而显示大小可任意调节,给读者提供了个性化的阅读方式。由于PDF文件可以不依赖操作系统的语言和字体及显示设备,阅读起来很方便。这些优点使读者能很快适应电子阅读与网上阅读,无疑有利于计算机与网络在日常生活中的普及。Adobe公司以PDF文件技术为核心,提供了一整套电子和网络出版解决方案,其中包括用于生成和阅读PDF文件的商业软件Acrobat和用于编辑制作PDF文件的Illustrator等。 Adobe还提供了用于阅读和打印亚洲文字,即中日韩文字所需的字型包。
软件的下载地址:http://nj.onlinedown.net/soft/2696.htm追问
答非所问!!!!!!!
下载网页中的 pdf 各种姿势,教你如何 carry 各种网页上的 pdf 文档。
关联词: PDF 下载 FLASH 网页 HTML 报告 内嵌 浏览器 文档 FlexPaperViewer swfobject pdf2swf 。
这个需求是最近帮一个学妹处理一下各大高校网站里的 PDF 文档下载,又增加了无用的逆向知识 XD ,根据这些思路,可以有效的下载这类网站的文档文件。
这需要你有点 HTML5 和 Flash 时代的基础认知,顺便能看 F12 的 network 、cache 等内容,推算真实地址等。
我从最简单的说起,首先准备一个谷歌浏览器,有趣的是需要谷歌浏览器的打印功能,导出到 PDF 上。
第一种样本,是直接的 .pdf 该类直接下载即可,没有难度。
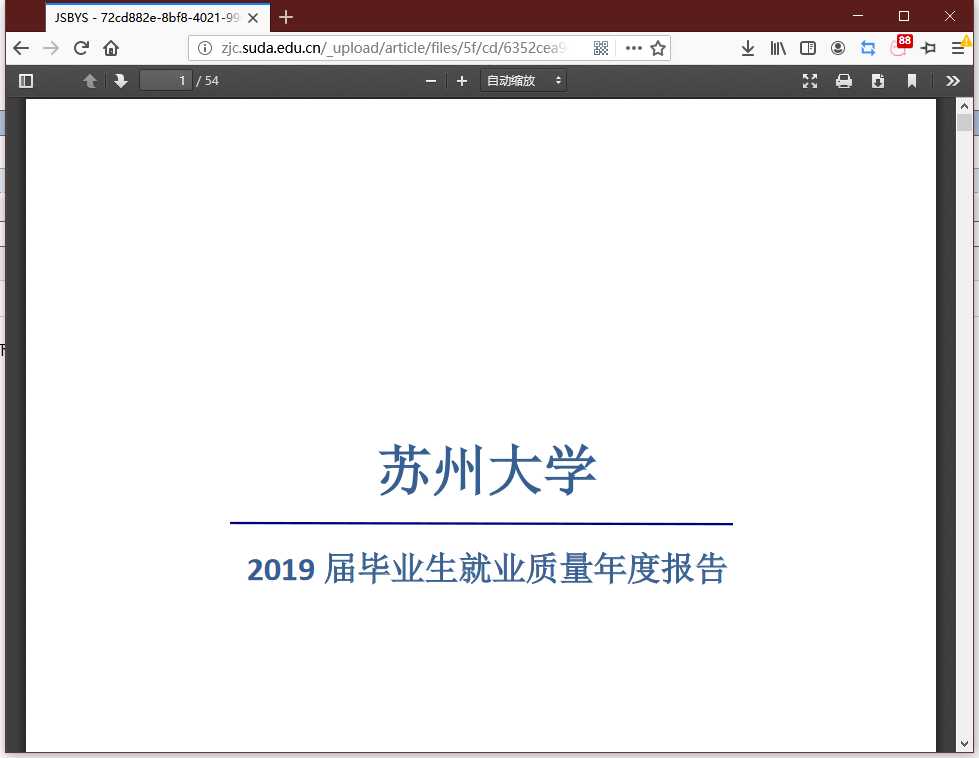
第二种样本,是现代 H5 + JS 内嵌 PDF 浏览器的方式。
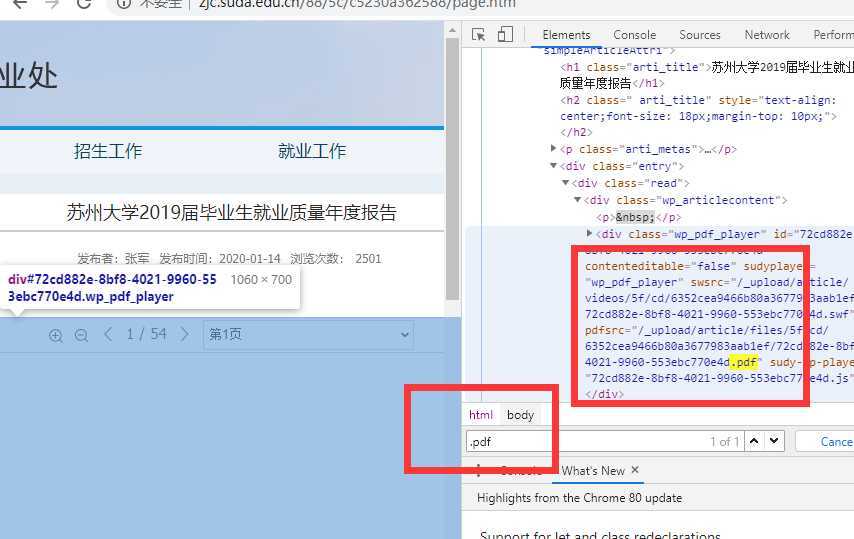
属于现代 H5 JS 的产物,需要用 F12 开发者工具看源码推断 PDF 文件路径,接下来截图举例。
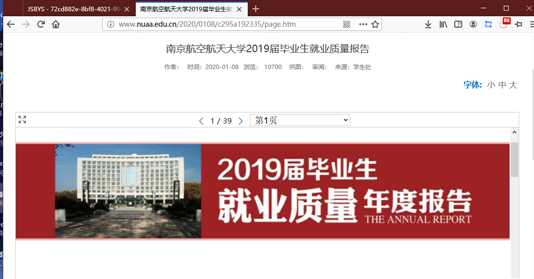
对其右键选检查,此时进入 F12 的 HTML 元素审查位置,可以找到它的定义代码。
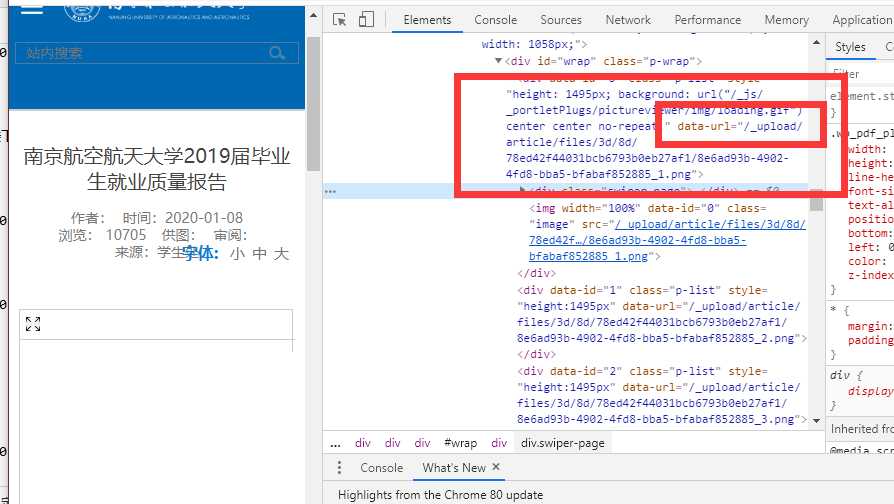
仔细看标签内容可以发现,存在 data-url="/_upload/article/files/3d/8d/78ed42f44031bcb6793b0eb27af1/8e6ad93b-4902-4fd8-bba5-bfabaf852885_1.png" 这类标签。
试图搜索(Ctrl + F)页面内容中的 .pdf 文件后缀,就会发现它的文件源存在了 pdfsrc="/_upload/article/files/3d/8d/78ed42f44031bcb6793b0eb27af1/8e6ad93b-4902-4fd8-bba5-bfabaf852885.pdf" 。
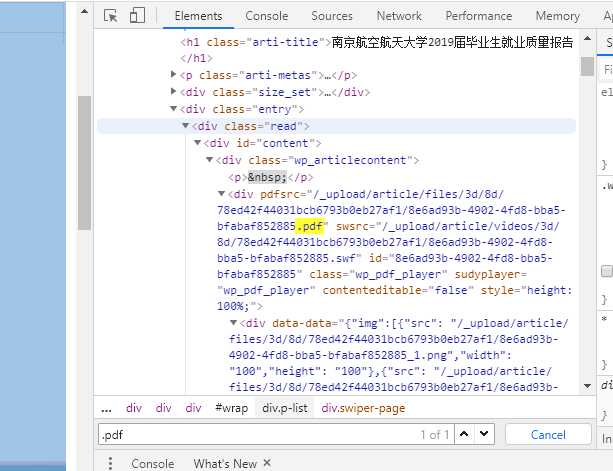
此时需要确定它的服务器源,从而获取真实地址,可以绝大概率是从这里来的。
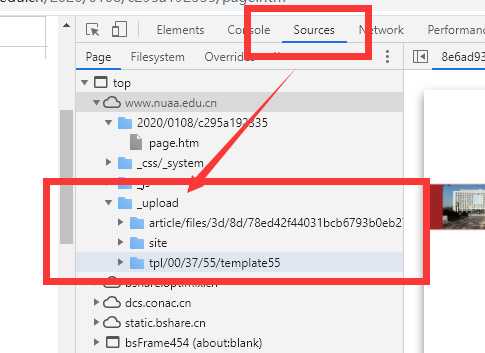
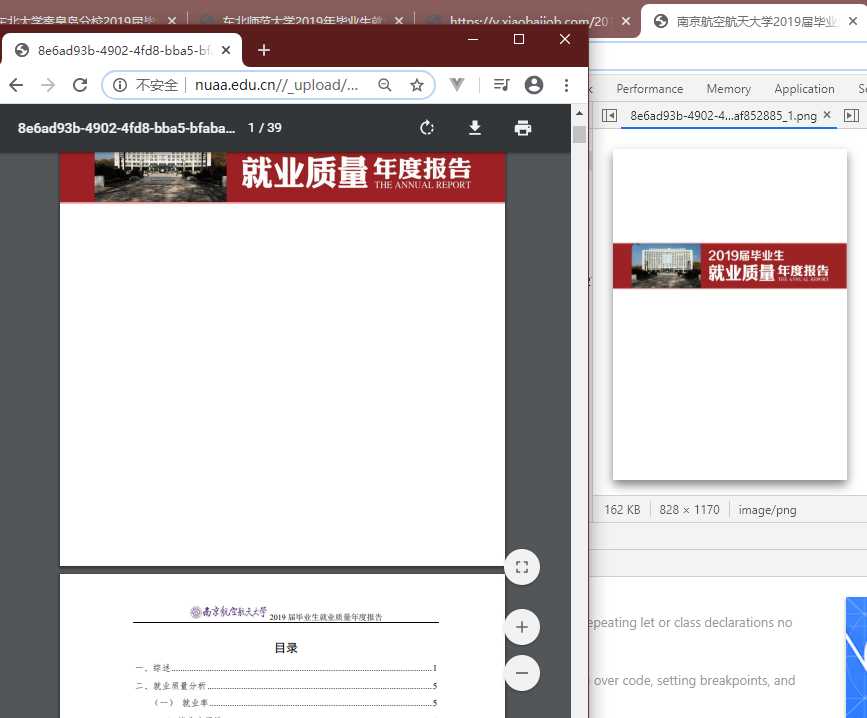
觉得还不太相信?那就再来一个。
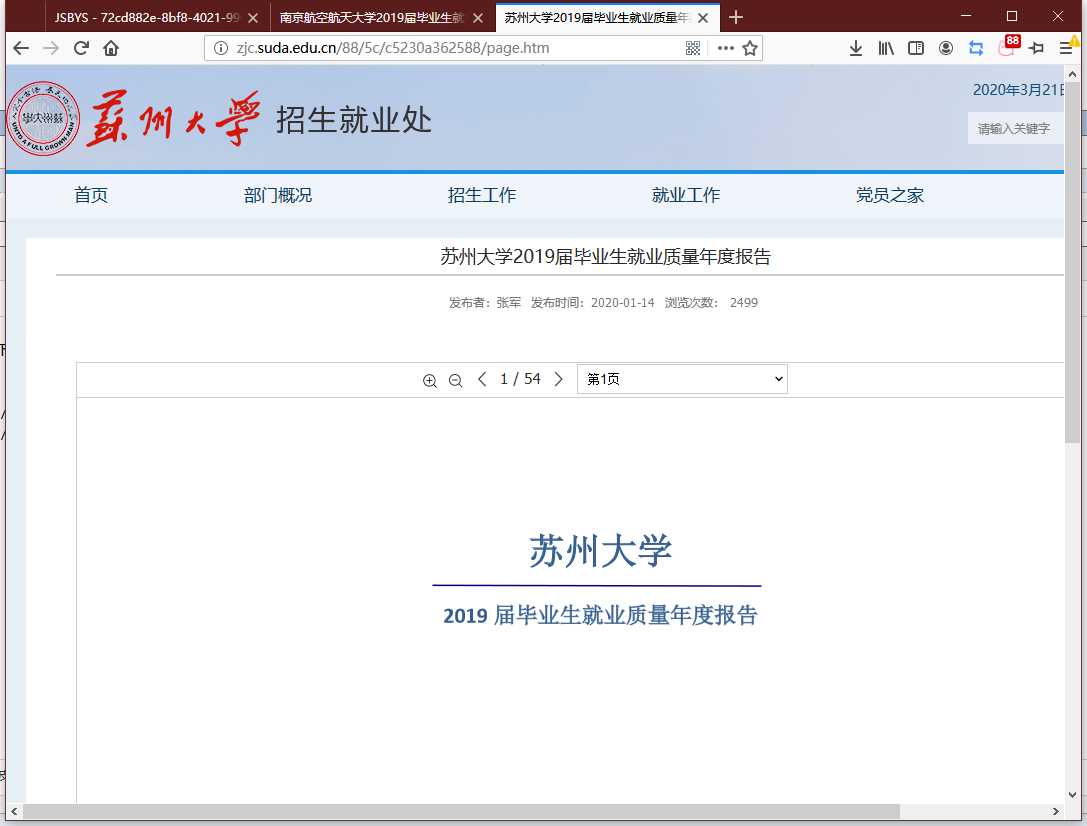
直接进 F12 直接搜 .pdf 直接找到源直接替换直接得到文件路径。
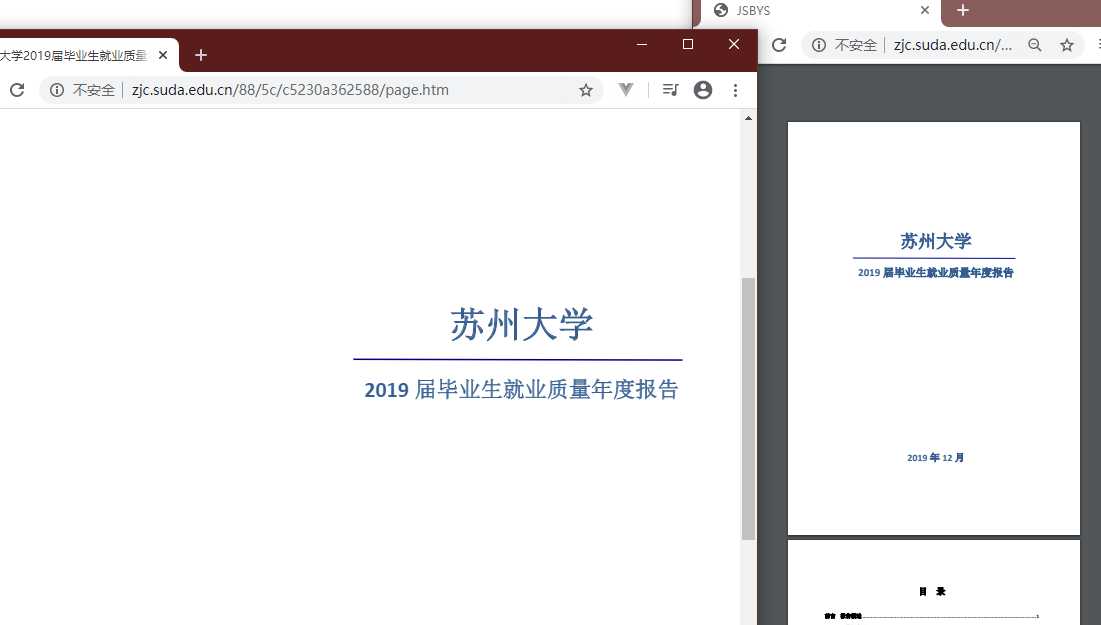
聪明的你学会了吗?接着我们进入第三种样本吧。
第三种样本,旧时代的遗留产物 FLASH 下的 PDF 文档
这个需要一点编程基础了,我之前思路走歪了,现代电脑已经不支持过去的 Flash 软件了,我先是获取了 swf 后试图转换图片、反编译其内容,但能够在 Win10 上 work 的软件已经不多了。
最后痛定思痛,想起,我是个程序猿鸭,为什么要这么耿直的使用工具呢?没错,我直接怼代码进去了,就可以解决了嘻嘻,接下来就是复现这个过程。
注意,针对 swf 转 pdf 问题文件,可以使用 github 的代码去实现,在这里不过多提及,关键词可以是 pdf2swf 和 FlexPaper 使用正向代码解决问题。
只是想起以前浏览器还可以直接读取 flash swf 文件的,不知道为什么现在已经不支持了。
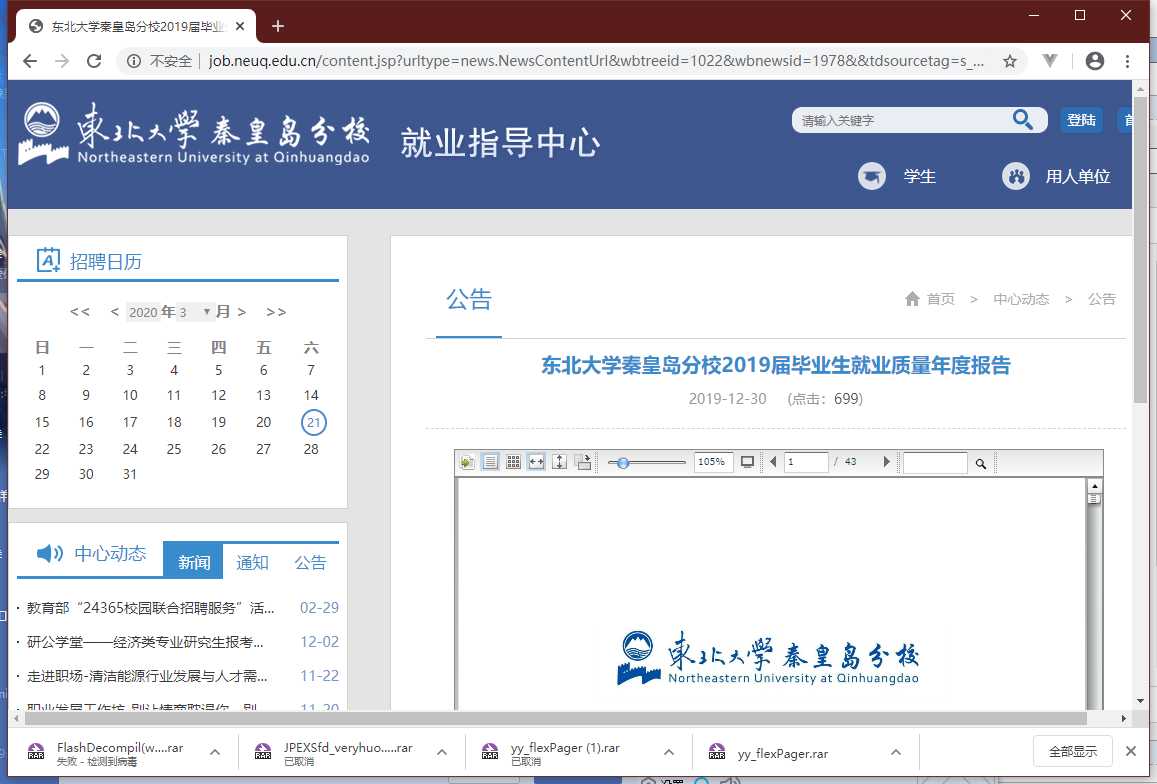
从右键我们可以得知它是 flash 播放器,这个真的没办法通过 html 得到,那么怎么办呢。
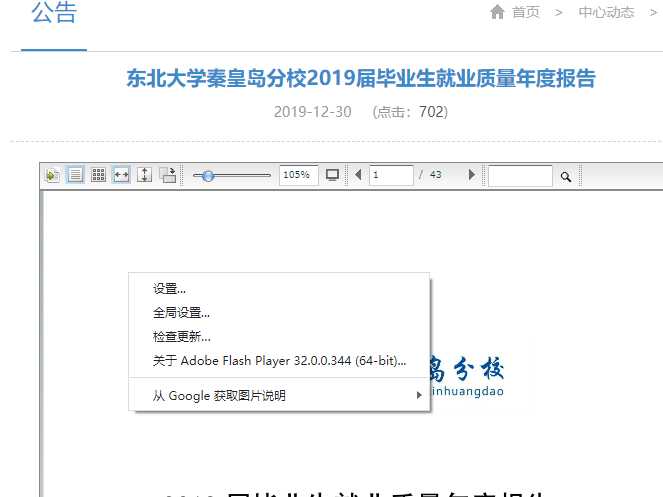
搜索 .pdf 或 .doc 都没用了,根本得不到它的文件,反而可以得到 swf 文件,讲道理,如果是早年间的电脑,相关工具应该还是可以解决问题的,如 swf2png 这类工具。
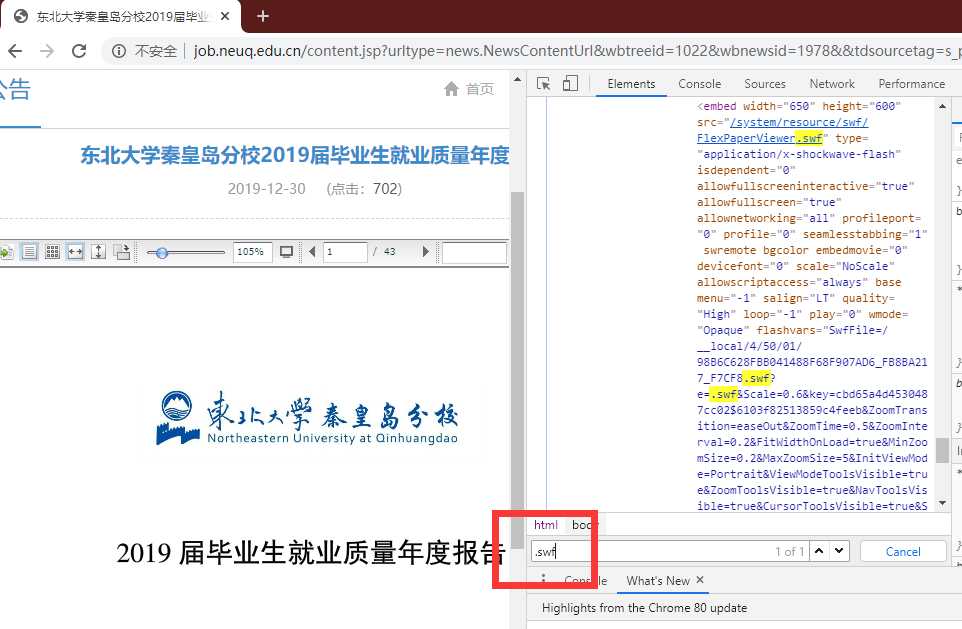
但是 win10 已经无法正常 work 了,那么我在这个地方浪费了很久以后,仔细看了一下它的组件,对,就是 /system/resource/swf/FlexPaperViewer.swf 挺古老的东西了。
顺便一提,谷歌浏览器将在 2020年12月终止 flash 组件。
那么,正面转换 swf 已经不现实了,我开始阅读标签代码,如下图。
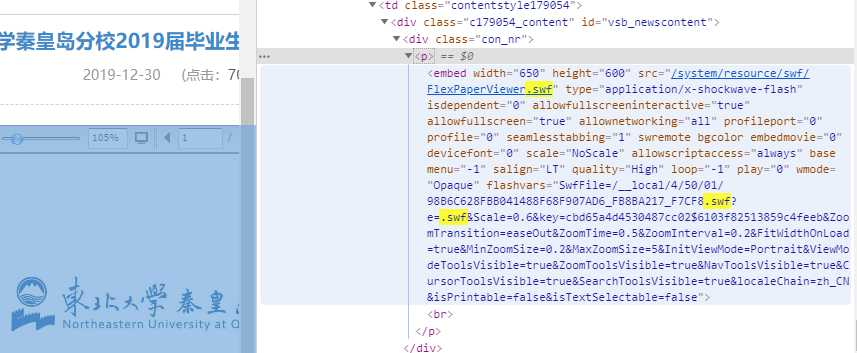
<p><embed width="650" height="600" src="/system/resource/swf/FlexPaperViewer.swf" type="application/x-shockwave-flash" isdependent="0" allowfullscreeninteractive="true" allowfullscreen="true" allownetworking="all" profileport="0" profile="0" seamlesstabbing="1" swremote="" bgcolor="" embedmovie="0" devicefont="0" scale="NoScale" allowscriptaccess="always" base="" menu="-1" salign="LT" quality="High" loop="-1" play="0" wmode="Opaque" flashvars="SwfFile=/__local/4/50/01/98B6C628FBB041488F68F907AD6_FB8BA217_F7CF8.swf?e=.swf&Scale=0.6&key=cbd65a4d4530487cc02$6103f82513859c4feeb&ZoomTransition=easeOut&ZoomTime=0.5&ZoomInterval=0.2&FitWidthOnLoad=true&MinZoomSize=0.2&MaxZoomSize=5&InitViewMode=Portrait&ViewModeToolsVisible=true&ZoomToolsVisible=true&NavToolsVisible=true&CursorToolsVisible=true&SearchToolsVisible=true&localeChain=zh_CN&isPrintable=false&isTextSelectable=false"><br></p>写代码嘛,这里就是定义这个 FlexPaperViewer 组件的调用参数,那么看到 isPrintable=false ,这里 false 就是关,表示停用打印机选项,改成 true 先。
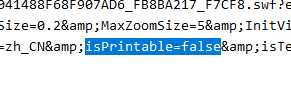
发现没反应,这是因为这时候标签没有刷新,所以编辑一下再保存,让 JS 重载改组件。
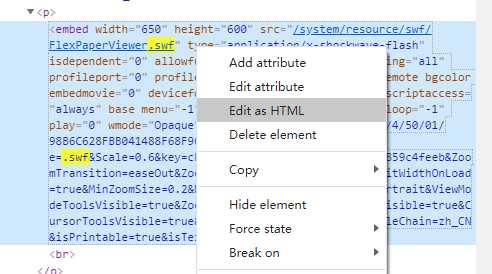
此时你会看到一个神奇的选项出来了,对的,就是打印机,那么你知道怎么做了吗?
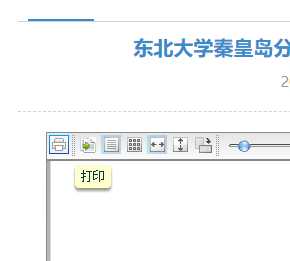
打印它,然后另存为 PDF 就可以了。
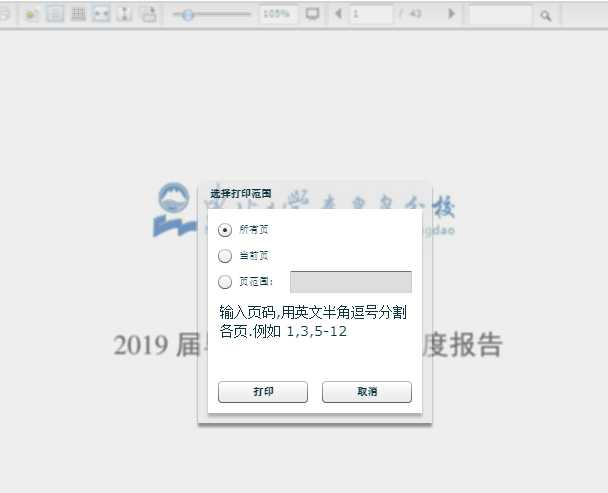
嗯,接下来你都知道了吧。
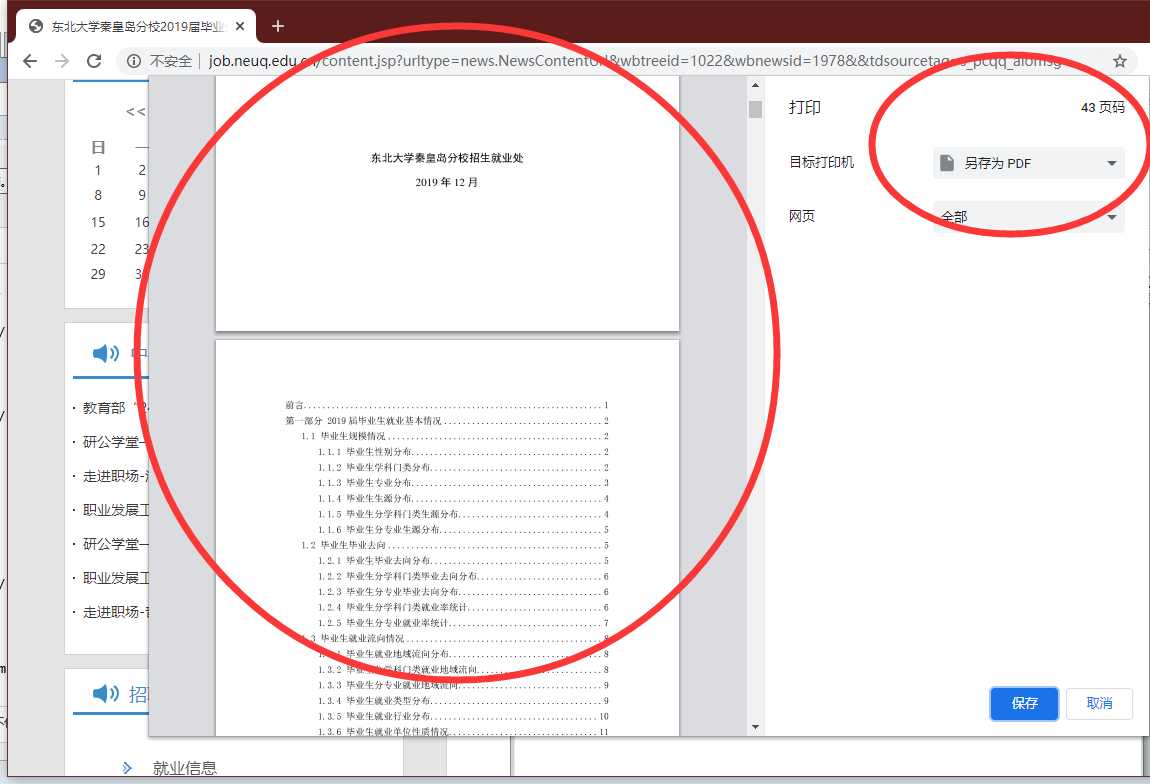
第四种样本,炫酷的动画版 PDF 文档。
这一种动画制的 PDF 版本,有点复杂,依赖库使用的是 SWFObject 组件,但也不是不能搞,但不能像前面的那种方式处理了。
/*! SWFObject v2.2 <http://code.google.com/p/swfobject/>
is released under the MIT License <http://www.opensource.org/licenses/mit-license.php>
*/现在怎么办呢?打印也没用,文件源也找不到,只好仔细观察 network 的数据流了。
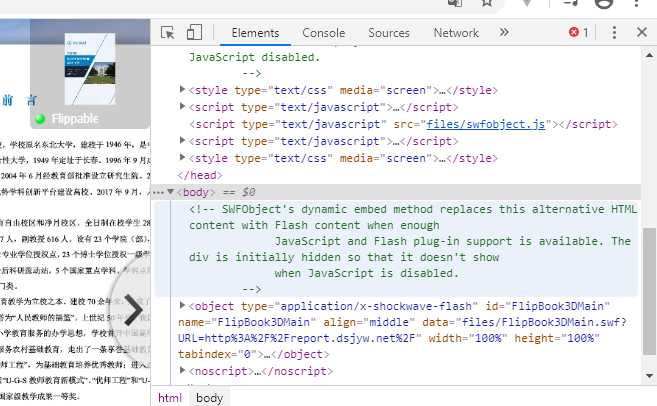
PC 页面下什么也做不了了,那就切换到手机页面试试
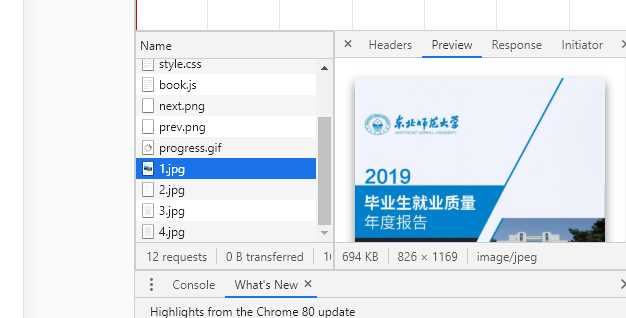
此时注意到 network 的图片文件在随着翻页加载。
现在发现它在获取图片了,这是个好消息。
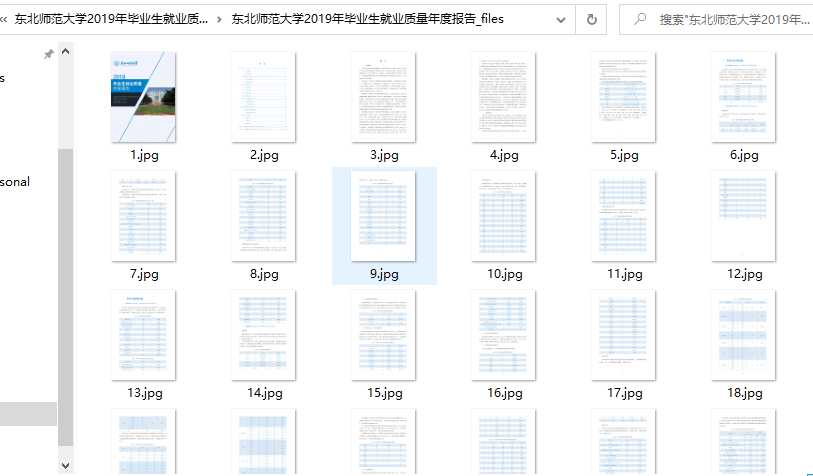
对的,我们可以将全部图片下载下来,然后保存全部网页,包括图片。
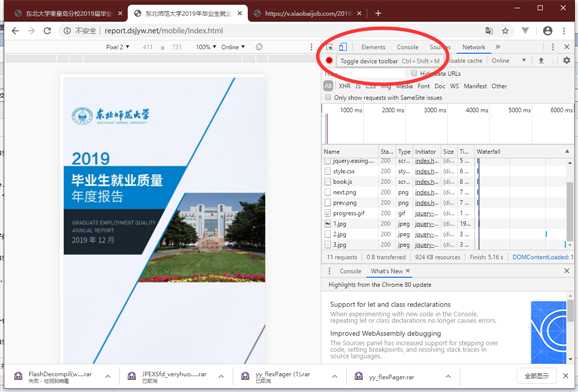
有了图片,就可以使用福昕 PDF 图片合并工具了。
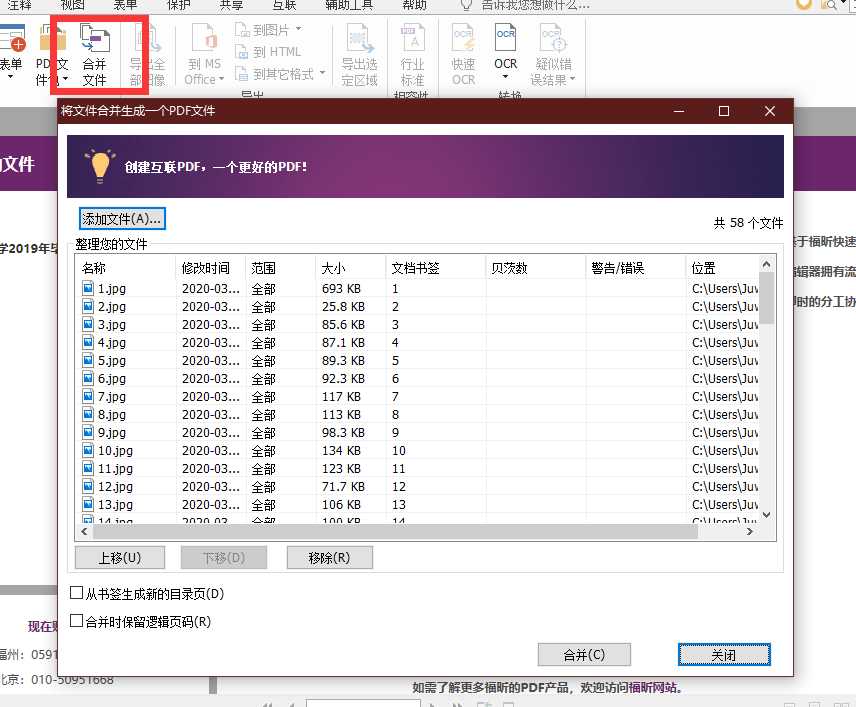
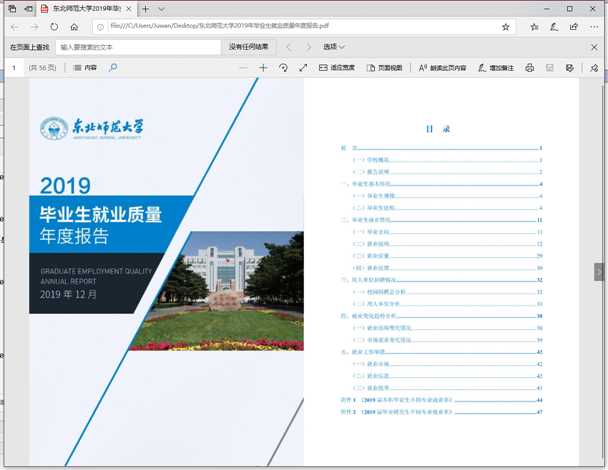
现在就可以得到,但这种方法下得到的像素会有一点损失,并不是最佳的,主要是因为 jpg 的有损显示导致的字体模糊。
如果你仔细阅读代码,也许可以把打印机的选项开起来,但我看到这个高度封装的 nodejs 产物就没有耐心了(摊手。
第五种样本,恶心的 PPT 视频
没想到吧,还有 MP4 的动画版本。

最后一种的 MP4 样本,我认为可以忽略了,如果真的要处理,那就丢到 ScreenToGif 中取关键帧出来,去除相似度较高的内容即可。
最后,这些内容希望可以给你一些启发,嘻嘻。
以上是关于请教,如何下载pdf文档。谢谢!的主要内容,如果未能解决你的问题,请参考以下文章