YOLOV1论文小整理
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOV1论文小整理相关的知识,希望对你有一定的参考价值。
文章目录
前言
为了更好地阅读源码,在进入源码阅读阶段必须先进行理论探究,之后才能结合工程干活。所以本次也是参考了众多大佬的视频,博客进行一个总结。我们先从初代版本V1开始,主要是第一篇论文不多,那么这里主要是关于这个神经网络的一个结构,它后面的一个具体的一个工作流程,这部分主要是分两个部分,一个是训练部分,还有一个是识别部分。这里咱们主要是对整个流程做一个了解分析。
相关资源链接如下:
https://arxiv.org/pdf/1506.02640.pdf
参考大牛文章如下:
https://blog.csdn.net/shuiyixin/article/details/82533849
https://www.cnblogs.com/makefile/p/nms.html
作者简介

这个是相当牛皮的大佬,负责编写了V1,V2,V3 不过后面由于,美国军方曾将YOLO智能识别技术用于军事武器开发,所以他后面退出了计算机视觉方面的研究和工作,所以从后面的V4到V6都是由继任者完成的维护,升级。是一个相当有责任担当且水平超高的大师。
算法简介
这部分是论文里面的
总之这玩意是一个很厉害的计算机视觉识别算法。
那么我们想要去解读这篇文章的目的主要是为了搞清楚,这个YOLO网络的工作过程 。前面通过这三篇博文大家应该是对神经网络有很多的了解了。
啊哈~花一天快速上手Pytorch(可能是全网最全流程从0到部署)
GitHub 水项目之 快速上手 YOLOV5
YOLOV5 参数设定与模型训练的坑点一二三
V1网络结构
相信你已经看过了前面三篇文章(里面有关于CNN神经网络的快速理解与入门CIRAF10实战搭建)
所以我们先来简单地看看一看这个神经网络长啥样。
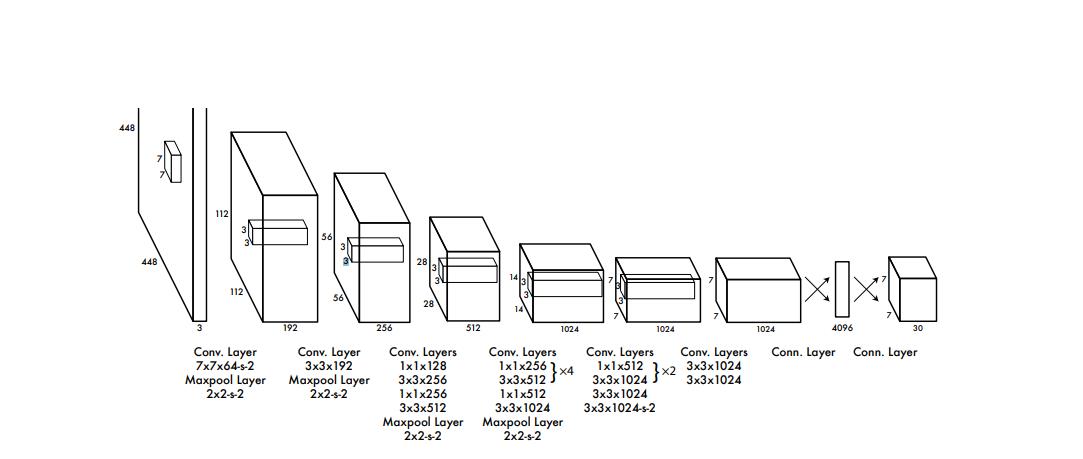
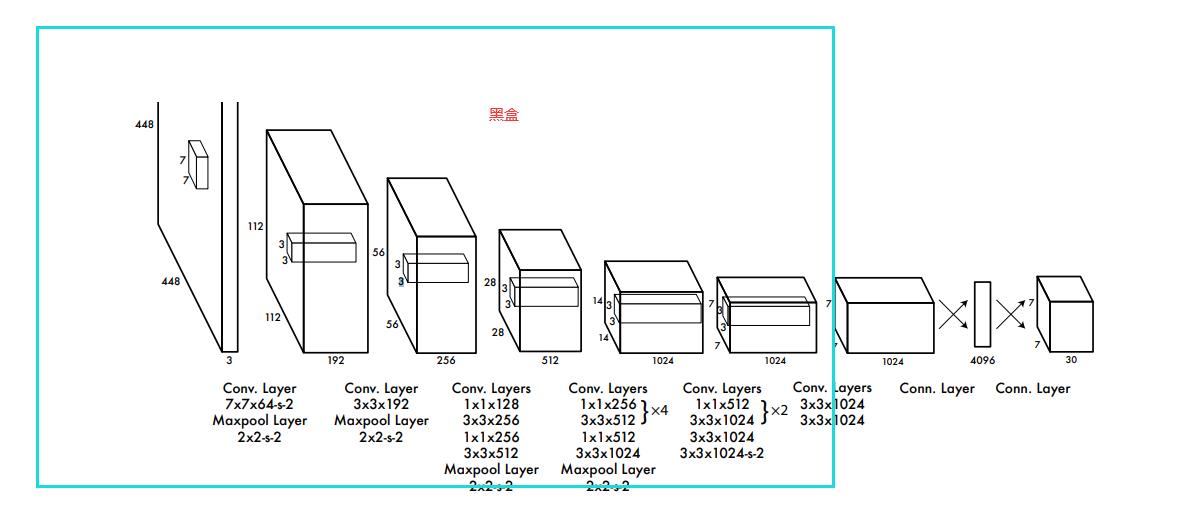
这个就是他的第一代V1的神经网络结构(第五代可能是一个残差神经网络,看代码的时候好像看到了残差结构)
整个过程其实也不是很复杂,整个V1的网络结构还是说,是通过众多的卷积层,池化层,最后得到一个
7 x 7 x 1024 的全连接层,然后经过1 x 1 x 4096 的全连接层 然后最后得到一个7x7x30的连接层。
所以整个过程主要还是一个复杂的卷积池化操作,这个很重要。
看看咱们先前搭建过的CIRAF10
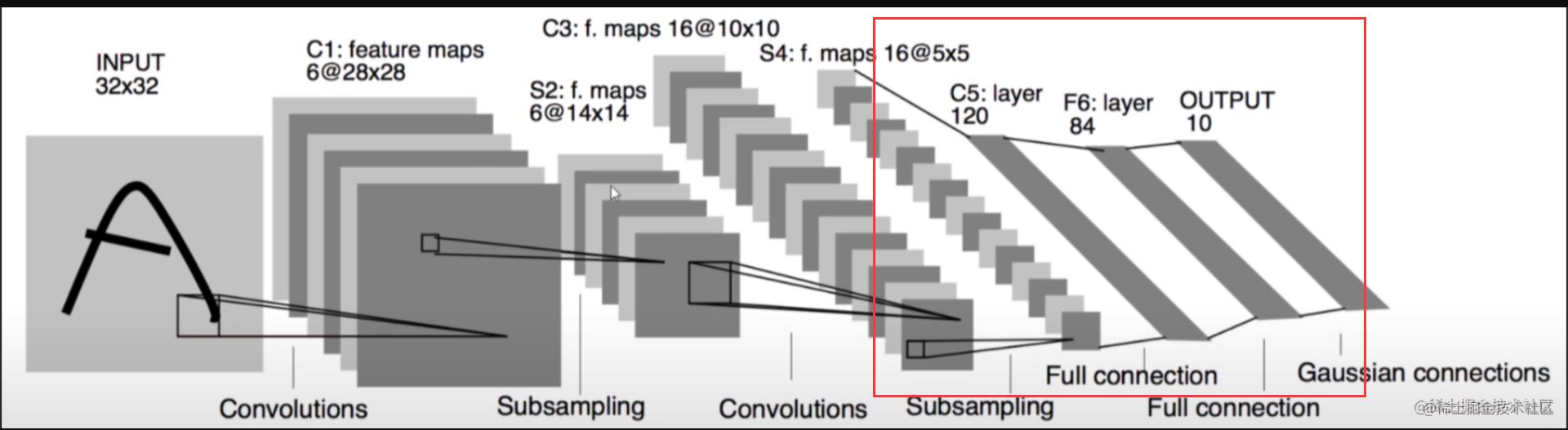
感觉其实也没有复杂到哪里去。无非是 神经节点 增加了不少,训练算力多了N倍罢了。
识别过程
想要梳理整个过程的话,咱们还是从识别的过程来看,因为这个是咱们最直观的部分。
卷积部分
我们先忽略卷积部分,因为这个还是一个建模的过程。
我们只关注最后面的 7 x 7 x 30
也就是说最后面 我们在实际上使用这个模型的时候,输入一张图片,首先这张图片会被缩放成 448x488 的大小 3 是RGB三个通道。最后一通操作得到了 7 x 7 x 30 的玩意。
不过这里的7 x 7 并不是说把一张图片变成7 x 7的像素。

也就是这样的
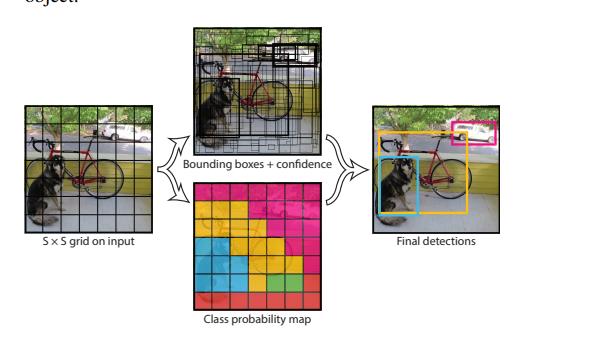
grid cell
这个玩意就是上面那张图的那个7x7的单元格。

我们最后输出的7x7x30的玩意就是为了后面得到这样的图片

后面通过处理我们才能够得到这样的图片
单元格存储信息
首先我们此时得到的是 7 x 7 x 30
那么我们 每一个单元格里面存储了什么信息? 为什么这玩意有30个维度?
首先 这里面存储了 两大类信息。
第一个 是 边框信息,起点,宽高,可信度。
第二个是 类别的条件概率,这里主要是20个类。
所以这里首先有20,此外由于边框,这里的话,每一个单元格是预测了两个边框的,所以有10,一共是三十。

边框
现在咱们来看看边框
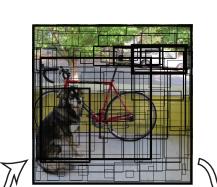
这里有 49 个 cell 一个 cell 两个边框,一共98个。每一个边框都是以其中一个cell为中心的,然后每一个边框都不一定是在标准的矩形,可能拉的很长,或者很短,但是中心点是在cell里面的。
那么对于这个边框,还有一个可信度,这个可信度我是这样理解的,就是确定这个区域内有物体的概率(边框框起来的)
后处理阶段
ok,现在咱们进入识别的最后一个阶段
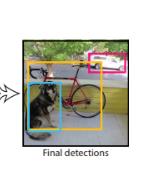
就是如何从上面的那张框框如此之多的图片变成这样的
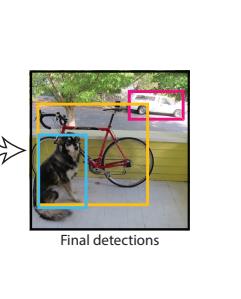
这样的

或者这样的


这部分主要是这样的。
首先咱们还是已经知道了,咱们有96个边框,并且我们知道了每一个cell 不同类别的条件概率。
例如我们预测上面的那个小姐姐。我这里以三个类别举个例子。
那么按照咱们的假设就是输出 7 x 7 x 13 的样子。
那么我们怎么处理呢,首先是先对这个边框 bounding box
对边框处理
我们这里一共有98个边框,每一个边框都有对应的可行度,我们假设是 3 个类别的话,那么,对于每一个类别,我们cell对应的类别的条件概率 x 边框置信度(c)这样一来,我们就知道了每个边框3个类别的概率。20个分类对应的就是20个。
此时我们先计算出全概率

此时我们先对第一类处理

IOU
这里需要引入一个概念,这玩意就是说,两个边框重合的部分。

这个参数呢在V5的detect也是有的
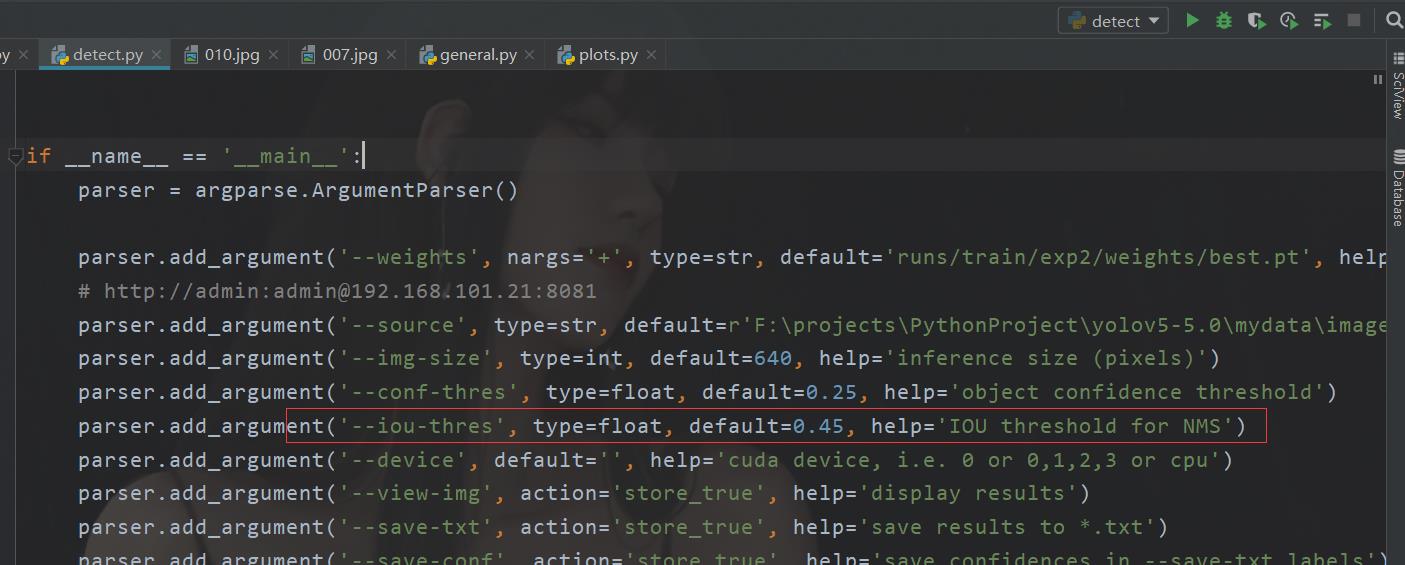
设置越高,图像上的框越多,设置越低,那么只有有重合一点就算一个,那么框就越少。
比对流程
那么接下来我们进入比对流程

此时第一个分类比出来了。
以此类推第二个第三个。
这个时候可能有个问题,为什么不直接选择概率最大的框。
原因很简单
一张图片有两个人物识别怎么搞

论文大概就在这部分

训练过程
说完了 这个识别过程终于到了训练过程。
这个过程其实还是相对简单的。
我们可以对比我们一开始的线性回归模型
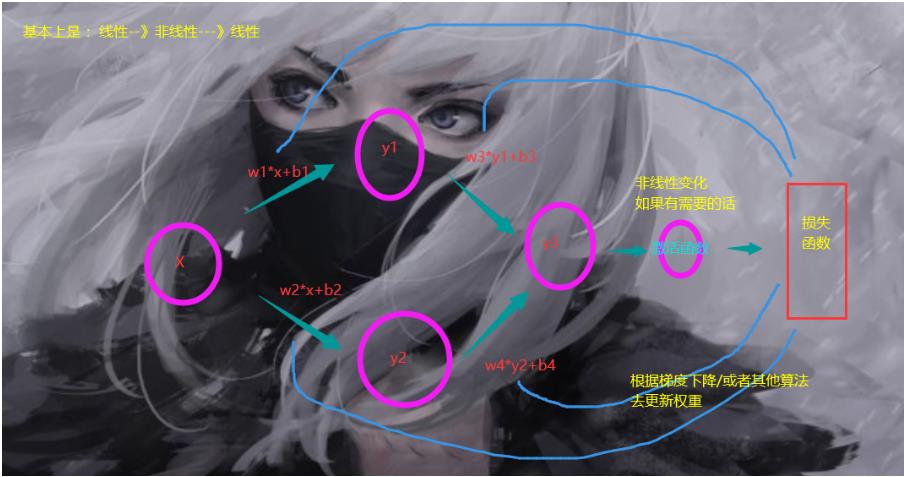
这玩意其实也算个神经网络,只不过上面只有两个连接层,一个输入,一个输出,然后是损失函数,反向传播。训练只需要正向传播,然后通过结果拿到值,然后处理(NMS)
本质上,我们这个是一个拟合的过程嘛。
如何拟合呢,首先确定一点,训练也好,预测也好,
在一通操作之后最后输出的都是 7 x 7 x 30的玩意。
我们喂给神经网络的是打标好的图片。
也就是这样的。
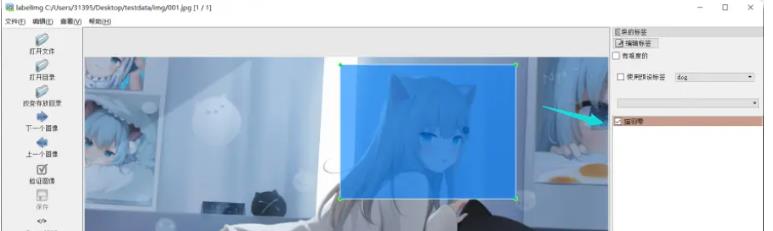
把标签打在图片上。
训练的时候,就是那个蓝色的矩形中心对应的cell去拟合,每一个cell有两个边框,让边框最大的(最接近你标注的边框的边框)去拟合计算。另外一个就那样吧。
损失函数
知道了咱们拟合训练的过程,那么接下来就是那啥,损失函数。


总结
说到这里其实只是到了论文的3,4页左右。不过后面的东西,都是老套路,前面提出我的观点,然后论述我的模型,内容,工作机制。后面是优缺点,对比,分析,然后是实验数据,这部分咱们就不看了,主要是为了搞清楚大体流程。
那么这里是关于YOLOV1的内容,明天去啃V2的。
以上是关于YOLOV1论文小整理的主要内容,如果未能解决你的问题,请参考以下文章