OpenCV实践小项目 - 停车场车位实时检测
Posted 翻滚的小@强
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV实践小项目 - 停车场车位实时检测相关的知识,希望对你有一定的参考价值。
1. 写在前面
今天整理OpenCV入门的第三个实战小项目,前面的两篇文章整理了信用卡数字识别以及文档OCR扫描, 大部分用到的是OpenCV里面的基础图像预处理技术,比如轮廓检测,边缘检测,形态学操作,透视变换等, 而这篇文章的项目呢,不仅需要一些基础的图像预处理,还需要搭建模型进行识别和预测,所以通过这个项目,能把图像预处理以及建模型等一整套流程拉起来,并应用到实际的应用场景,还是非常有意思的。
停车场车位实时检测任务,是拿到停车场的一段视频video,主要完成两件事情:
- 检测整个停车场当中,当前一共有多少辆车,一共有多少个空余的车位
- 把空余的停车位标识出来,这样用户停车的时候,就可以直接去空余的停车位处, 为停车节省了很多时间
所以这个项目还是非常有实践应用价值的,用了大约一天半的时间搞定这个项目,参考的是唐老师的OpenCV入门教程视频, 不过这里面对于这个任务做的相对粗糙,我在这个基础上基于我的理解进行了一些优化,主要改动如下:
- 数据处理方面,按列框出停车位之后,我对每一列框的坐标手工进行了调整,确保每个停车位不遗漏,不多余, 然后是对每个停车位的坐标位置进行了微调,尽量让其标记的准一些
- 模型方面,原视频采用迁移学习方式,基于keras对VGG网络进行的微调,而我模型这里统一基于pytorch,用的ResNet32预训练模型进行的finetune,验证集正确率能到0.94多,但第一版还是有少量预测的不是很准,所以又基于已有的帧图片做了数据增强,额外增加了一些数据,把准确率提升到0.98左右
- 项目的整体架构全部改变,算是听懂了上面的思想,然后基于自己的理解进行的重构,好处是后面可以进行各种优化,按照自己需求做数据增强,数据预处理以及训练各种高级模型等。
不过,发现小resnet就够强大的了,最终的预测效果如下:
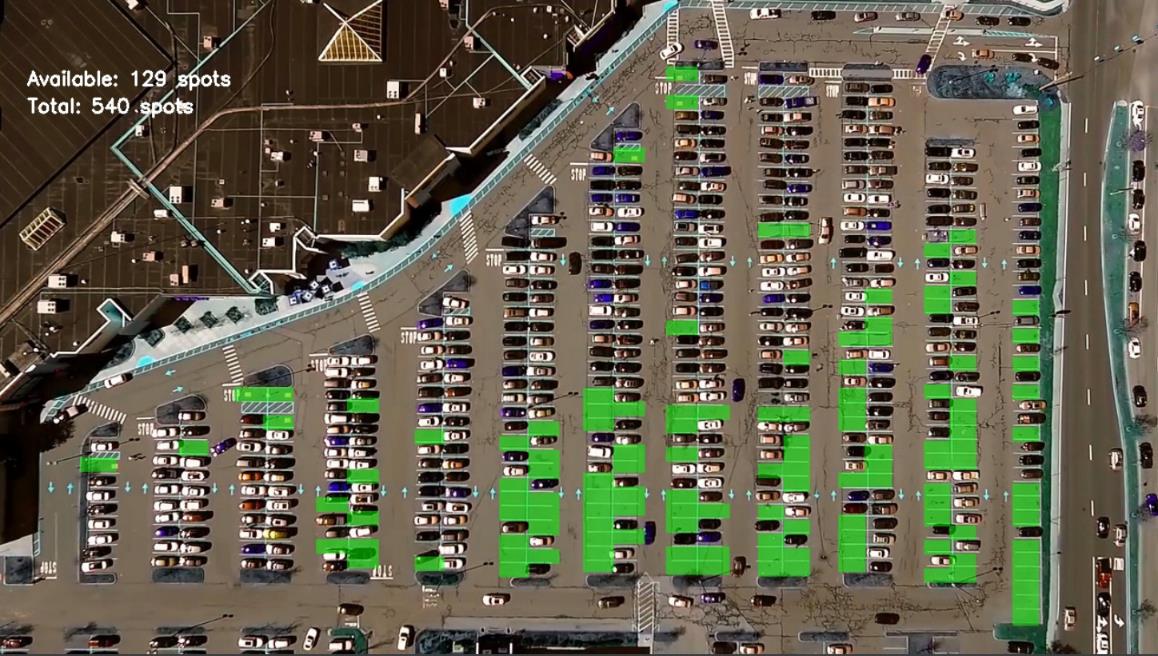
这是视频中的某一帧图像,实际运行的时候,是读入视频,快速分开帧,每一帧做出这样的预测标记,然后实时显示。这样在每个时刻,都能动态的知道该停车场有哪些车位空了出来。
下面就对这个项目中用到的关键技术进行整理,由于这个项目稍微大一些,代码量多,不可能在这里全部展示,但想记录下对于这个项目我的思考过程,以及各种处理的动机,以及如何进行的处理,我觉得这个才是对以后有用的东西。
2. 整体流程梳理
首先,拿到这个任务之后, 得大致上梳理下流程,才能确定行动方案。 我们开始拿到了这样的一段视频,那么为了完成上面停车位检测以及识别的任务,就需要考虑两步:
- 我得先把停车场的每个停车位给提取出来
- 有了每个停车位,我训练一个模型,去预测这个停车位上有没有车就行啦,把没有车的标识出来,然后统计个数
其实宏观上就这么两大步。那么后面的问题就是怎么把每个车位提取出来,又怎么训练模型预测呢?
我这里主要分为了两大步, 数据预处理以及模型的训练及预测:
-
数据预处理方面
- 以视频中某一帧的图像为单位,进行处理
- 通过二值化,灰度化,边缘检测,特定点标定连线等,把图片中多余的部分去掉,只保留停车场内的这部分对象
- 霍夫变换的直线检测,去找图片中的直线,根据直线坐标,先按列为单位,把车位按列框起来, 然后对框手动微调
- 在每一列中,锁定每个停车位的位置,并对每个停车位进行标号,把这个保存成字典
- 有了每个停车位的位置,就能提取出对应图片,可以作为后面模型的训练以及验证的数据集,不过需要人工手动划分
-
通过上面步骤,会积累一些数据,大约800多张图片,接下来就可以训练模型,但是由于数据量太少,从头训练模型往往效果不好,所以这里采用迁移学习的方式,使用了预训练的resnet34,用这800多张图片微调。
-
训练好了模型保存,接下来,对于每一帧图像,有了停车位位置字典,就能直接提取出每一个停车位,然后对于这每个停车位,模型预测有没有车即可
所以有了这样的一个流程,就能再进一步分解细化,就可以大处着眼小处着手啦,下面整理每一步里面的关键细节。
3. 数据预处理
3.1 背景过滤
首先,把一帧图像读入进来,原始图像如下:

先通过二值化的方式过滤掉背景,突出重要信息,然后转成灰度图。
def select_rgb_white_yellow(image):
# 过滤背景
lower = np.uint8([120, 120, 120])
upper = np.uint8([255, 255, 255])
# 三个通道内,低于lower和高于upper的部分分别变成0, 在lower-upper之间的值变成255, 相当于mask,过滤背景
# 保留了像素值在120-255之间的像素值
white_mask = cv2.inRange(image, lower, upper)
masked_img = cv2.bitwise_and(image, image, mask=white_mask)
return masked_img
masked_img = select_rgb_white_yellow(test_image)
这里看到inRange(),想到了之前用到的二值化的方法threshold, 我在想这俩有啥区别? 为啥这里不用这个了? 下面是我经过探索得到的几点使用经验:
cv2.threshold(src, thresh, maxval, type[, dst]):针对的是单通道图像(灰度图), 二值化的标准,type=THRESH_BINARY: if x > thresh, x = maxval, else x = 0, 而type=THRESH_BINARY_INV: 和上面的标准反着,目前常用到了这俩个cv2.inRange(src, lowerb, upperb):可以是单通道图像,可以是三通道图像,也可以进行二值化,标准是if x >= lower and x <= upper, x = 255, else x = 0
这里做了一个实验, 事先把图片转化成灰度图warped = cv2.cvtColor(test_image, cv2.COLOR_BGR2GRAY),然后下面两句代码的执行结果是一样的:
cv2.threshold(warped, 119, 255, cv2.THRESH_BINARY)[1]cv2.inRange(warped, 120, 255)
处理之后的图片长这样:

3.2 Canny边缘检测
接下来,采用Canny边缘检测算法,检测出边缘来
low_threshold, high_threshold = 50, 200
edges_img = cv2.Canny(gray_img, low_threshold, high_threshold)
结果如下:

下面尝试把停车场这块提取出来, 把其余那些没用的去掉。
3.3 停车场区域提取
这里的思路就是,先用6个标定点把停车场的这几个角给他定住,这个标定点得需要自己找。 找到之后, 采用OpenCV中的填充函数,就能制作一个mask矩阵,然后就能把其余部分去掉了。
def select_region(image):
"""这里手动选择区域"""
rows, cols = image.shape[:2]
# 下面定义6个标定点, 这个点的顺序必须让它化成一个区域,如果调整,可能会交叉起来,所以不要动
pt_1 = [cols*0.06, rows*0.90] # 左下
pt_2 = [cols*0.06, rows*0.70] # 左上
pt_3 = [cols*0.32, rows*0.51] # 中左
pt_4 = [cols*0.6, rows*0.1] # 中右
pt_5 = [cols*0.90, rows*0.1] # 右上
pt_6 = [cols*0.90, rows*0.90] # 右下
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
point_img = image.copy()
point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2BGR)
for point in vertices[0]:
cv2.circle(point_img, (point[0], point[1]), 10, (0, 0, 255), 4)
# cv_imshow('points_img', point_img)
# 定义mask矩阵, 只保留点内部的区域
mask = np.zeros_like(image)
if len(mask.shape) == 2:
cv2.fillPoly(mask, vertices, 255) # 点框住的地方填充为白色
#cv_imshow('mask', mask)
roi_image = cv2.bitwise_and(image, mask)
return roi_image
roi_image = select_region(edges_img)
处理的效果如下:

这样处理好了,我们就需要找到这里面的直线,然后通过直线去猜测大致的位置。
3.4 霍夫变换检测直线
这里采用霍夫变换检测直线, 函数是cv2.HoughLinesP, 该函数能检测直线的两个端点(x0,y0, x1, y1)。函数原型:
HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]]) -> lines
- image: 边缘检测的输出图像,这里要注意必须是边缘检测的输出图像
- rho: 参数极径r以像素值为单位的分辨率,一般1
- threa: 以弧度为单位的分辨率,一般1
- threshold: 检测一条直线所需最少的曲线交点
- minLineLength: 能形成一条直线的最小长度,太短,不认为是一条直线
- maxLineGap: 两条直线直接最大间隔,小于这个值,认为是一条直线
所以,这个函数拿来直接用。
def hough_lines(image):
# 输入的图像需要是边缘检测后的结果
# minLineLengh(线的最短长度,比这个短的都被忽略)和MaxLineCap(两条直线之间的最大间隔,小于此值,认为是一条直线)
# rho距离精度,theta角度精度,threshod超过设定阈值才被检测出线段
return cv2.HoughLinesP(image, rho=0.1, theta=np.pi/10, threshold=15, minLineLength=9, maxLineGap=4)
list_of_lines = hough_lines(roi_image) # (2338, 1, 4)
竟然检测到了2338条直线,这里面肯定有很多不能用的,所以后面处理,需要对直线先进行一波筛选。筛选原则是线不能是斜的,且水平方向不能太长或者是太短。 具体代码下面会看到,这里先展示下过滤之后的效果。

过滤完了,总共628条直线。
3.5 以列为单位,划分停车位
下面的代码会稍微复杂,所以需要分块讲思路。
首先,我们拿到了停车场的直线以及它的坐标位置。 过滤操作已经做好,接下来,就是对每条直线进行排序。 让这些线,从一列一列的,从上往下依次排列好。
def identity_blocks(image, lines, make_copy=True):
if make_copy:
new_image = image.copy()
# 过滤部分直线
stayed_lines = []
for line in lines:
for x1, y1, x2, y2 in line:
# 这里是过滤直线,必须保证不能是斜的线,且水平方向不能太长或者太短
if abs(y2-y1) <=1 and abs(x2-x1) >=25 and abs(x2-x1) <= 55:
stayed_lines.append((x1,y1,x2,y2))
# 对直线按照x1排序, 这样能让这些线从上到下排列好, 这个排序是从第一列的第一条横线,往下走,然后是第二列第一条横线往下,...
list1 = sorted(stayed_lines, key=operator.itemgetter(0, 1))
排列好之后,遍历所有线, 看看相邻两条线之间的距离,如果是一列, 那么两条线的x_1应该离得非常近,毕竟是同一列,如果这个值太大了,说明是下一列了。根据这个准则,遍历完之后,就能把这些线划分到不同的列里面。这里是用了一个字典,键表示列,值表示每一列里面的直线。
代码接上:
# 找到多个列,相当于每列是一排车
clusters = collections.defaultdict(list)
dIndex = 0
clus_dist = 10 # 每一列之间的那个距离
for i in range(len(list1) - 1):
# 看看相邻两条线之间的距离,如果是一列的,那么x1这个距离应该很近,毕竟是同一列上的
# 如果这个值大于10了,说明是下一列的了,此时需要移动dIndex, 这个表示的是第几列
distance = abs(list1[i+1][0] - list1[i][0])
if distance <= clus_dist:
clusters[dIndex].append(list1[i])
clusters[dIndex].append(list1[i+1])
else:
dIndex += 1
有了每一列里面的直线,下面就是就是遍历每一列,先拿到所有直线,然后找到纵坐标的最大值和最小值,以及横坐标的最大和最小值,但由于横坐标这里,首尾列都一排车位,中间排都是两列,不好直接取到最大最小坐标,所以这里采用了求平均的方式。 这样遍历完,针对每一列,就能得到左上角点和右下角点,这是一个矩形框。
代码接上:
# 得到每列停车位的矩形框
rects =
i = 0
for key in clusters:
all_list = clusters[key]
cleaned = list(set(all_list))
# 有5个停车位至少
if len(cleaned) > 5:
cleaned = sorted(cleaned, key=lambda tup: tup[1])
avg_y1 = cleaned[0][1]
avg_y2 = cleaned[-1][1]
if abs(avg_y2-avg_y1) < 15:
continue
avg_x1 = 0
avg_x2 = 0
for tup in cleaned:
avg_x1 += tup[0]
avg_x2 += tup[2]
avg_x1 = avg_x1 / len(cleaned)
avg_x2 = avg_x2 / len(cleaned)
rects[i] = [avg_x1, avg_y1, avg_x2, avg_y2]
i += 1
print('Num Parking Lanes: ', len(rects))
下面,把矩形框画出来:
# 把列矩形画出来
buff = 7
for key in rects:
tup_topLeft = (int(rects[key][0] - buff), int(rects[key][1]))
tup_botRight = (int(rects[key][2] + buff), int(rects[key][3]))
cv2.rectangle(new_image, tup_topLeft, tup_botRight, (0, 255, 0), 3)
return new_image, rects
这里的buff,也是进行了一点微调操作。 这种是根据实际场景来的,不是死的。 效果如下:

这样就会发现,对于每一列的停车位,有了大致上的矩形框标定,但是这个非常粗糙。 原视频里面就基于这个往后面走了。 我这里对于每一列框进行微调,因为这个框非常重要。不准的话影响后面的具体车位划分。
def rect_finetune(image, rects, copy_img=True):
if copy_img:
image_copy = image.copy()
# 下面需要对上面的框进行坐标微调, 让框更加准确
# 这个框很重要,影响后面停车位的统计,尽量不能有遗漏
for k in rects:
if k == 0:
rects[k][1] -= 10
elif k == 1:
rects[k][1] -= 10
rects[k][3] -= 10
elif k == 2 or k == 3 or k == 5:
rects[k][1] -= 4
rects[k][3] += 13
elif k == 6 or k == 8:
rects[k][1] -= 18
rects[k][3] += 12
elif k == 9:
rects[k][1] += 10
rects[k][3] += 10
elif k == 10:
rects[k][1] += 45
elif k == 11:
rects[k][3] += 45
buff = 8
for key in rects:
tup_topLeft = (int(rects[key][0]-buff), int(rects[key][1]))
tup_botRight = (int(rects[key][2]+buff), int(rects[key][3]))
cv2.rectangle(image_copy, tup_topLeft, tup_botRight, (0, 255, 0), 3)
return image_copy, rects
微调之后的效果如下:
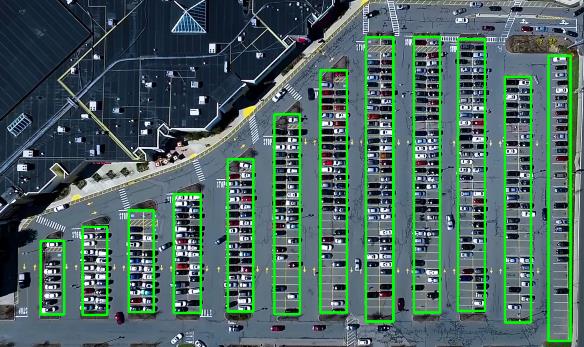
原则就是不遗漏,不多余。
3.6 锁定每个停车位
这里就是针对每个矩形框, 对里面的停车位用直线切割成一个个的,每个停车位用(x1,y1,x2,y2)标识,左上角和右下角的坐标。并进行标号,最终形成一个字典,字典的键就是位置,值就是序号。当然,这里的一个细节,依然是中间排是两排,首尾是一排,这个在具体划分停车位的时候,一定要注意。
def draw_parking(image, rects, make_copy=True, save=True):
gap = 15.5
spot_dict = # 一个车位对应一个位置
tot_spots = 0
#微调
adj_x1 = 0: -8, 1:-15, 2:-15, 3:-15, 4:-15, 5:-15, 6:-15, 7:-15, 8:-10, 9:-10, 10:-10, 11:0
adj_x2 = 0: 0, 1: 15, 2:15, 3:15, 4:15, 5:15, 6:15, 7:15, 8:10, 9:10, 10:10, 11:0
fine_tune_y = 0: 4, 1: -2, 2: 3, 3: 1, 4: -3, 5: 1, 6: 5, 7: -3, 8: 0, 9: 5, 10: 4, 11: 0
for key in rects:
tup = rects[key]
x1 = int(tup[0] + adj_x1[key])
x2 = int(tup[2] + adj_x2[key])
y1 = int(tup[1])
y2 = int(tup[3])
cv2.rectangle(new_image, (x1, y1),(x2,y2),(0,255,0),2)
num_splits = int(abs(y2-y1)//gap)
for i in range(0, num_splits+1):
y = int(y1+i*gap) + fine_tune_y[key]
cv2.line(new_image, (x1, y), (x2, y), (255, 0, 0), 2)
if key > 0 and key < len(rects) - 1:
# 竖直线
x = int((x1+x2) / 2)
cv2.line(new_image, (x, y), (x, y2), (0, 0, 255), 2)
# 计算数量 除了第一列和最后一列,中间的都是两列的
if key == 0 or key == len(rects) - 1:
tot_spots += num_splits + 1
else:
tot_spots += 2 * (num_splits + 1)
# 字典对应好
if key == 0 or key == len(rects) - 1:
for i in range(0, num_splits+1):
cur_len = len(spot_dict)
y = int(y1 + i * gap) + fine_tune_y[key]
spot_dict[(x1, y, x2, y+gap)] &#以上是关于OpenCV实践小项目 - 停车场车位实时检测的主要内容,如果未能解决你的问题,请参考以下文章