DATAX如何增量同步数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DATAX如何增量同步数据相关的知识,希望对你有一定的参考价值。
以时间段查询数据,并同步到其它库,每分钟自动执行一次,查询的时间段为上次查询的结束时间和当前时间。
参考技术A 你好,关于你的问题,希望以下问题对你有用:大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性),平台有hadoop 。
使用datax-web 按批次增量同步数据并生成对账数据
一、背景介绍:
业务数据表中更新标识字段
- 新增时间(Add_time)。表示业务表的数据首次创建的时间,默认为当前系统时间,格式为YYYY-MM-DD HH:MM:SS,如:2018-05-9 17:20:53。
- 增量标识(Cd_operation)。业务表的数据新增时值为“I”,修改时值为“U”,删除时值为“D”。
- 增量时间(Cd_time)。表示业务表的数据发生修改的时间,格式为YYYY-MM-DD HH:MM:SS,如:2018-05-9 17:20:53。
- 批次号(Cd_batch)。地市按批次在前置机更新数据,生成批次号格式为“数据日期+数据序号”,如:2021090100001。其中,数据日期是指更新数据的日期;数据序号为五位数字,每天从00001开始,按当天数据序号递增。
注意事项:
- 创建表时,新增时间(Add_time)和增量时间(Cd_time)需要赋予默认值为当前系统时间,增量标识(Cd_operation)默认值为“I”。
- 新增/添加数据时,设置增量标识(Cd_operation)的值为“I”,新增时间(Add_time)和增量时间(Cd_time)的值需保持一致(即赋予该字段当前数据库时间值)。
- 修改数据时,设置增量标识(Cd_operation)的值为“U”,修改业务字段内容后,新增插入数据,历史数据保留。
- 删除数据时,设置增量标识(Cd_operation)的值为“D”,新增插入数据,保留历史数据。
对账表(ech_batch)
| 序号 | 信息项名称 | 数据标识 | 数据类型 | 数据长度 | 是否必填 | 备注 |
| 1 | 主键 | ID | 数值型N | 20 | 必填 | 填写自增主键,从1开始,如“1”。 |
| 2 | 表名 | TableName | 字符串型C | 128 | 必填 | 填写业务表名,如“CORP_BSC_INFO”。 |
| 3 | 批次号 | Cd_batch | 字符串型C | 32 | 必填 | 填写该批次库表的批次号,如“2021112300001”。 |
| 4 | 数据量 | Cd_count | 数值型N | 11 | 必填 | 填写该批次的数据量,如“100”。 |
| 5 | 同步时间 | Cd_time | 日期时间型T | - | 必填 | 填写格式为:YYYY-MM-DD HH:MM:SS |
| 6 | 批次状态 | Batch_Status | 字符串型C | 1 | 必填 | 填写“0/1”。 0-表示初始状态,不会抽取。 1-表示生效状态,可以抽取。 |
注意事项:
- 同一批次数据使用同一个数据库事务插入。
- 同一个表中,批次状态(Batch_Status)为“0”状态的批次号不能大于“1”状态的批次号,即“1”状态不能超前于“0”状态出现。
- 地市国资委按批次将数据量写入数据对账表,按时报送数据。
二、解决方案:
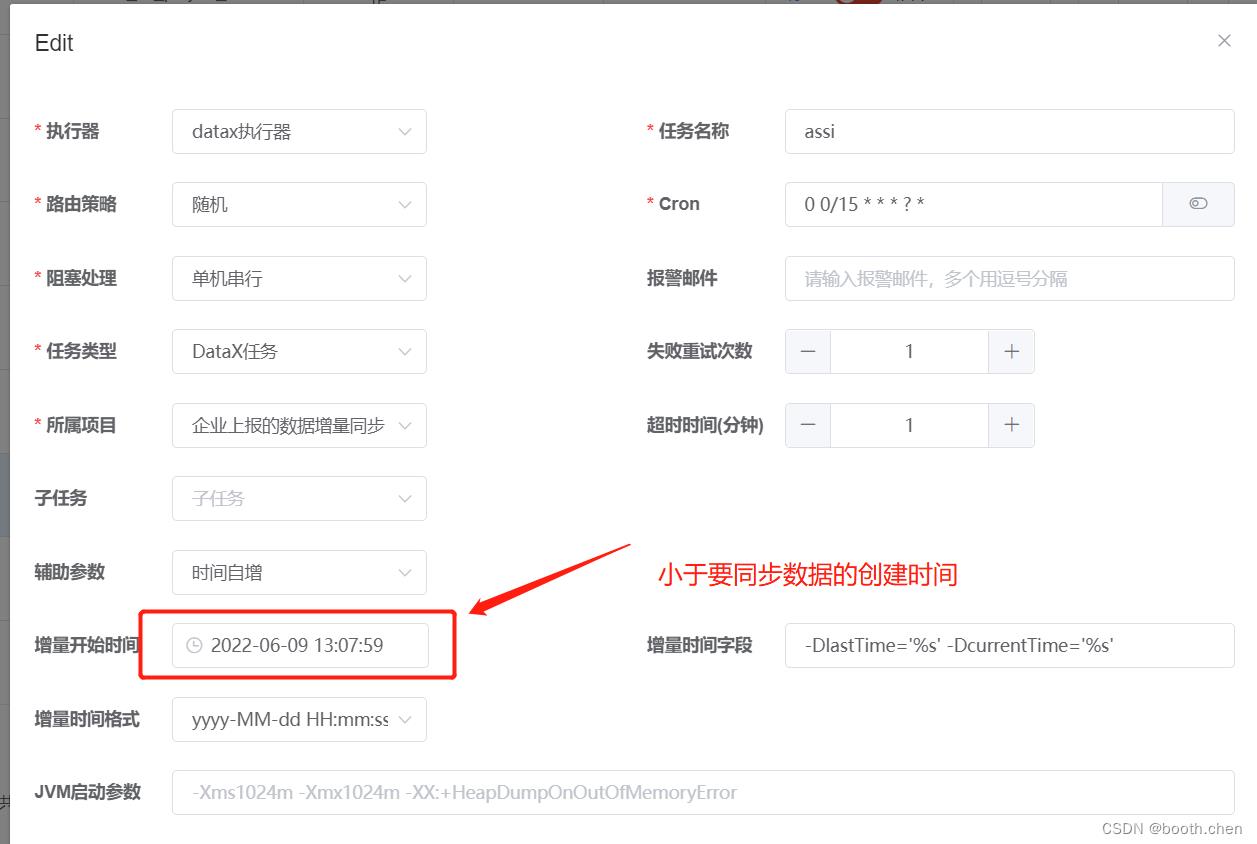
使用datax-web 配置任务
1.配置辅助参数为 时间自增
2.增量开始时间、,即sql中查询时间的开始时间,用户使用此选项方便第一次的全量同步。第一次同步完成后,该时间被更新为上一次的任务触发时间,任务失败不更新。
3.增量时间字段为 -DlastTime='%s' -DcurrentTime='%s'
1.-D是DataX参数的标识符,必配
2.-D后面的lastTime和currentTime是DataX json中where条件的时间字段标识符,必须和json中的变量名称保持一致
3.='%s'是项目用来去替换时间的占位符,比配并且格式要完全一致
4.注意-DlastTime='%s'和-DcurrentTime='%s'中间有一个空格,空格必须保留并且是一个空格4.增量时间格式选择 yyyy-MM-dd HH:mm:ss
5.json配置
mysql reader配置 where条件实现增量数据抽取
"where": "Cd_time >= $lastTime and Cd_time < $currentTime",
mysql writer 配置 writeMode、postSql
writeMode 控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句,所有选项:insert/replace/update ,默认值:insert
postSql 写入数据到目的表后会执行这里的标准语句,如果 Sql 中有你需要操作到的表名称,请使用 @table 表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。
生成业务表批次号(当天首次同步格式为2021112300001,第二次同步批次号为2021112300002,... ...依次叠加)
UPDATE @table SET Cd_batch=(SELECT IFNULL(MAX(Cd_batch)+1,CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'00001')) FROM ech_batch WHERE TableName='@table' AND Cd_batch LIKE CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'%')) WHERE Cd_batch IS NULL生成对账表数据
INSERT INTO ech_batch(TableName,Cd_batch,Cd_count,Cd_time,Batch_Status)
SELECT t.TableName,t.Cd_batch,b.cd_count,NOW(),1 FROM (
SELECT '@table' TableName ,IFNULL(MAX(Cd_batch)+1,CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'00001')) AS Cd_batch
FROM ech_batch WHERE TableName='@table' AND Cd_batch LIKE CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'%')
) t
LEFT JOIN (
SELECT Cd_batch,COUNT(*) cd_count FROM @table WHERE Cd_batch >= CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'00001') GROUP BY Cd_batch
) b ON b.Cd_batch=t.Cd_batch
WHERE cd_count>0 完整示例:
"job":
"setting":
"speed":
"channel": 3,
"byte": 1048576
,
"errorLimit":
"record": 0,
"percentage": 0.02
,
"content": [
"reader":
"name": "mysqlreader",
"parameter":
"username": "root",
"password": "123456",
"column": [
"`ID`",
"`Add_time`",
"`Cd_operation`",
"`Cd_time`",
"`Cd_batch`"
],
"where": "Cd_time >= $lastTime and Cd_time < $currentTime",
"splitPk": "",
"connection": [
"table": [
"assi"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/a"
]
]
,
"writer":
"name": "mysqlwriter",
"parameter":
"writeMode": "update",
"username": "root",
"password": "123456",
"column": [
"`ID`",
"`Add_time`",
"`Cd_operation`",
"`Cd_time`",
"`Cd_batch`"
],
"postSql": [
"UPDATE @table SET Cd_batch=(SELECT IFNULL(MAX(Cd_batch)+1,CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'00001')) FROM ech_batch WHERE TableName='@table' AND Cd_batch LIKE CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'%')) WHERE Cd_batch IS NULL",
"INSERT INTO ech_batch(TableName,Cd_batch,Cd_count,Cd_time,Batch_Status) SELECT t.TableName,t.Cd_batch,b.cd_count,NOW(),1 FROM (SELECT '@table' TableName ,IFNULL(MAX(Cd_batch)+1,CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'00001')) AS Cd_batch FROM ech_batch WHERE TableName='@table' AND Cd_batch LIKE CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'%')) t LEFT JOIN (SELECT Cd_batch,COUNT(*) cd_count FROM @table WHERE Cd_batch >= CONCAT(DATE_FORMAT(NOW(),'%Y%m%d'),'00001') GROUP BY Cd_batch) b ON b.Cd_batch=t.Cd_batch WHERE cd_count>0"
],
"connection": [
"table": [
"assi"
],
"jdbcUrl": "jdbc:mysql://192.168.1.100:3306/a"
]
]
三、参考文档
datax-web 使用介绍
https://github.com/WeiYe-Jing/datax-web#readme
DataX Web增量配置说明
https://github.com/WeiYe-Jing/datax-web/blob/master/doc/datax-web/increment-desc.md
MysqlReader
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
MysqlWriter
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
以上是关于DATAX如何增量同步数据的主要内容,如果未能解决你的问题,请参考以下文章