python笔记:jieba(中文分词)
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python笔记:jieba(中文分词)相关的知识,希望对你有一定的参考价值。
1 精确模式与全模式分割
import jieba
txt = '北京大学创办于1898年,初名京师大学堂,是中国第一所国立综合性大学。'
word_list = jieba.lcut(txt)
# 精确模式,完整且不重复
print(word_list)
#['北京大学', '创办', '于', '1898', '年', ',', '初名', '京师大学堂', ',', '是', '中国', '第一所', '国立', '综合性', '大学', '。']
word_list = jieba.lcut(txt, cut_all=True)
# 全模式,输出所有可能的词,会有冗余
print(word_list)
#['北京', '北京大学', '大学', '创办', '于', '1898', '年', ',', '初', '名', '京师', '京师大学堂', '师大', '大学', '大学堂', '学堂', ',', '是', '中国', '第一', '第一所', '一所', '国立', '综合', '综合性', '合性', '大学', '。']1.1 添加和删除指定词
# 如何识别不常见的词
txt = '丹戎巴鲁是一个新加坡的地铁站'
word_list = jieba.lcut(txt)
# 无法识别
print(word_list)
#['丹戎', '巴鲁', '是', '一个', '新加坡', '的', '地铁站']
jieba.add_word('丹戎巴鲁')
# 添加指定词
word_list = jieba.lcut(txt)
# 现在可以识别
print(word_list)
#['丹戎巴鲁', '是', '一个', '新加坡', '的', '地铁站']
jieba.del_word('丹戎巴鲁')
# 删除指定词
word_list = jieba.lcut(txt)
# 现在无法识别
print(word_list)
#['丹戎', '巴鲁', '是', '一个', '新加坡', '的', '地铁站']1.2 分词时标注词性
import jieba.posseg as pseg
content = '念刘备、关羽、张飞,虽然异姓,既结为兄弟,\\
……不求同年同月同日生,只愿同年同月同日死。'
words =pseg.cut(content)
words
#<generator object cut at 0x000001A9C778A5C8>
'''
pseg.cut()函数返回的是一个生成器,所以直接输出是不行的
'''
for w in words:
print(w,''*10,w.word,''*10,w.flag)
'''
念/v 念 v
刘备/nrfg 刘备 nrfg
、/x 、 x
关羽/nr 关羽 nr
、/x 、 x
张飞/nr 张飞 nr
,/x , x
虽然/c 虽然 c
异姓/n 异姓 n
,/x , x
既/c 既 c
结为/v 结为 v
兄弟/n 兄弟 n
,/x , x
…/x … x
…/x … x
不/d 不 d
求/v 求 v
同年同月/i 同年同月 i
同日生/nz 同日生 nz
,/x , x
只/d 只 d
愿/v 愿 v
同年/t 同年 t
同月同日/i 同月同日 i
死/v 死 v
。/x 。 x
'''1.2.1 词性表
| Ag | 形语素 | 形容词性语素。形容词代码为 a,语素代码g前面置以A。 |
| a | 形容词 | 取英语形容词 adjective的第1个字母。 |
| ad | 副形词 | 直接作状语的形容词。形容词代码 a和副词代码d并在一起。 |
| an | 名形词 | 具有名词功能的形容词。形容词代码 a和名词代码n并在一起。 |
| b | 区别词 | 取汉字“别”的声母。 |
| c | 连词 | 取英语连词 conjunction的第1个字母。 |
| dg | 副语素 | 副词性语素。副词代码为 d,语素代码g前面置以D。 |
| d | 副词 | 取 adverb的第2个字母,因其第1个字母已用于形容词。 |
| e | 叹词 | 取英语叹词 exclamation的第1个字母。 |
| f | 方位词 | 取汉字“方” |
| g | 语素 | 绝大多数语素都能作为合成词的“词根”,取汉字“根”的声母。 |
| h | 前接成分 | 取英语 head的第1个字母。 |
| i | 成语 | 取英语成语 idiom的第1个字母。 |
| j | 简称略语 | 取汉字“简”的声母。 |
| k | 后接成分 | |
| l | 习用语 | 习用语尚未成为成语,有点“临时性”,取“临”的声母。 |
| m | 数词 | 取英语 numeral的第3个字母,n,u已有他用。 |
| Ng | 名语素 | 名词性语素。名词代码为 n,语素代码g前面置以N。 |
| n | 名词 | 取英语名词 noun的第1个字母。 |
| nr | 人名 | 名词代码 n和“人(ren)”的声母并在一起。 |
| ns | 地名 | 名词代码 n和处所词代码s并在一起。 |
| nt | 机构团体 | “团”的声母为 t,名词代码n和t并在一起。 |
| nz | 其他专名 | “专”的声母的第 1个字母为z,名词代码n和z并在一起。 |
| o | 拟声词 | 取英语拟声词 onomatopoeia的第1个字母。 |
| p | 介词 | 取英语介词 prepositional的第1个字母。 |
| q | 量词 | 取英语 quantity的第1个字母。 |
| r | 代词 | 取英语代词 pronoun的第2个字母,因p已用于介词。 |
| s | 处所词 | 取英语 space的第1个字母。 |
| tg | 时语素 | 时间词性语素。时间词代码为 t,在语素的代码g前面置以T。 |
| t | 时间词 | 取英语 time的第1个字母。 |
| u | 助词 | 取英语助词 auxiliary |
| vg | 动语素 | 动词性语素。动词代码为 v。在语素的代码g前面置以V。 |
| v | 动词 | 取英语动词 verb的第一个字母。 |
| vd | 副动词 | 直接作状语的动词。动词和副词的代码并在一起。 |
| vn | 名动词 | 指具有名词功能的动词。动词和名词的代码并在一起。 |
| w | 标点符号 | |
| x | 非语素字 | 非语素字只是一个符号,字母 x通常用于代表未知数、符号。 |
| y | 语气词 | 取汉字“语”的声母。 |
| z | 状态词 | 取汉字“状”的声母的前一个字母。 |
| un | 未知词 | 不可识别词及用户自定义词组。取英文Unkonwn首两个字母。(非北大标准,CSW分词中定义) |
1.2 load_userdict
导入用户的dict,append在jieba原有的词性表上
比如我们现在有这样的一个文件:
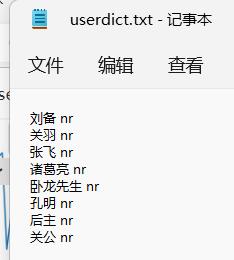
import jieba.posseg as pseg
jieba.load_userdict('userdict.txt')
content = '念刘备、关羽、张飞,虽然异姓,既结为兄弟'
words =pseg.cut(content)
words
#<generator object cut at 0x000001A9C778A5C8>
'''
pseg.cut()函数返回的是一个生成器,所以直接输出是不行的
'''
for w in words:
print(w,''*10,w.word,''*10,w.flag)
'''
念/v 念 v
刘备/nr 刘备 nr
、/x 、 x
关羽/nr 关羽 nr
、/x 、 x
张飞/nr 张飞 nr
,/x , x
虽然/c 虽然 c
异姓/n 异姓 n
,/x , x
既/c 既 c
结为/v 结为 v
兄弟/n 兄弟 n
'''发现“刘备”可以正确地给出词性了
 《新程序员》:云原生和全面数字化实践
《新程序员》:云原生和全面数字化实践
 50位技术专家共同创作,文字、视频、音频交互阅读
50位技术专家共同创作,文字、视频、音频交互阅读
以上是关于python笔记:jieba(中文分词)的主要内容,如果未能解决你的问题,请参考以下文章