YOLOV5 参数设定与模型训练的坑点一二三
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOV5 参数设定与模型训练的坑点一二三相关的知识,希望对你有一定的参考价值。
文章目录
前言
蓝桥杯干完了,怎么说,出题组换了,不讲武德,当然还是自己不行… Ok,该回来办点正事了。
上次我们简单地玩了一下YOLOV5 如果是按照那个我上次记录的文章来走的话,我想,至少大家的YOLO环境应该是搭建好了,也会怎么设定数据集自己训练了。然后我说我在玩的时候,说我翻车了,说图片尺寸有问题,其实呢,我没有翻车,没错,没有翻车,是我在测试,模型训练的时候参数的问题。为什么我会说我自己没有翻车咧。很简单。
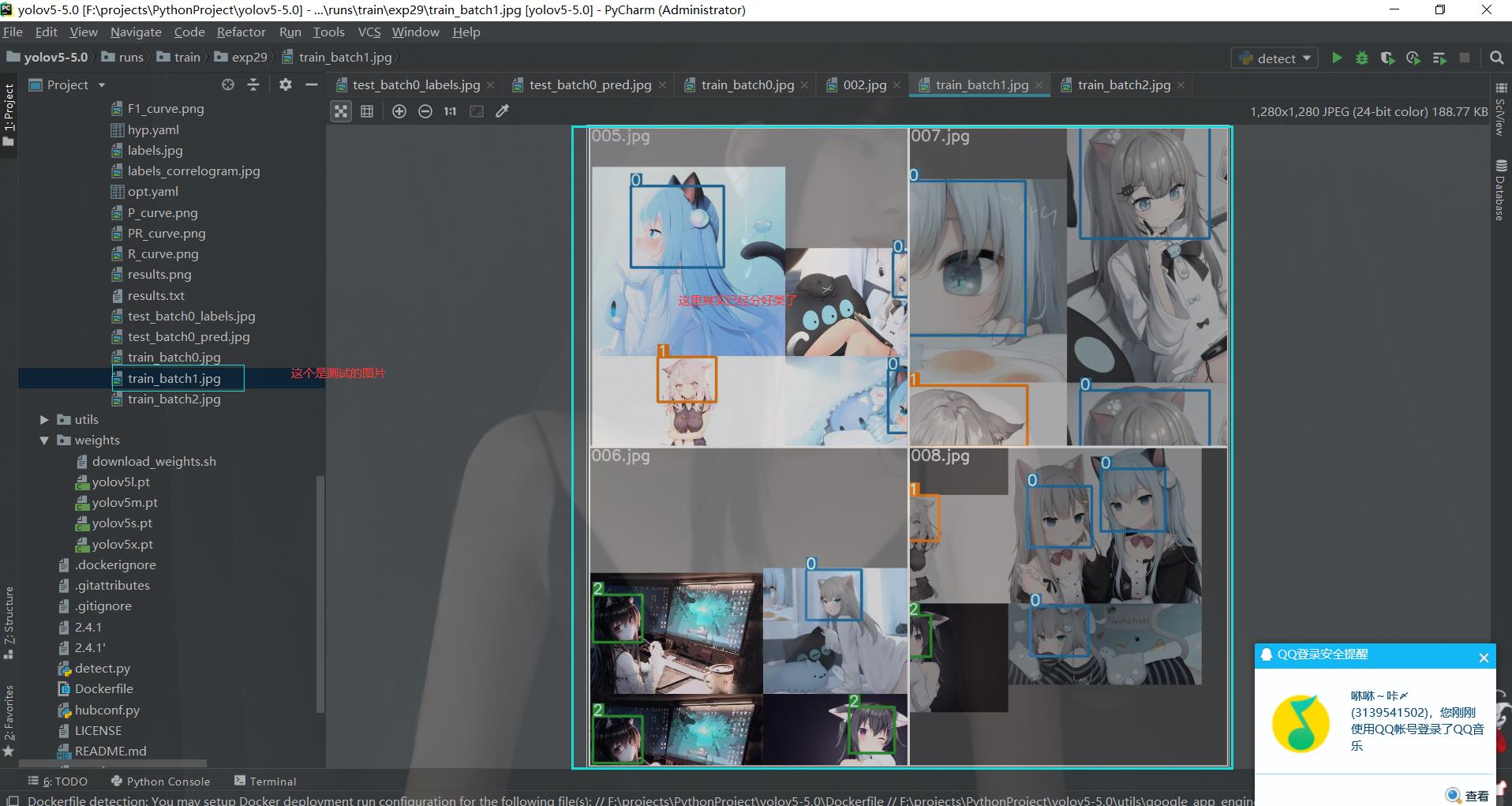
但是为什么会出不来结果呢,这里面的原因有很多,最容易出现,也最有可能的原因就是置信度的问题。那么今天我要搞定的问题就是让我自己的模型出来结果。并且做一个记录,
自训练模型问题
无目标框
问题分析
这个就是咱们现在遇到的问题,那就是模型明明训练好了,但是却没有目标框出现。而且在做测试的时候,我们使用可是同一个训练集里面的图片。并且在我们实际上的训练过程当中也发现它其实应该是已经识别出来了。但是就是没有框出来。
先说可能的原因,第一个也是比较容易误导人的就是这个玩意
detect.py

train.py

这个玩意其实根本就不是指你图片的原始大小。而是送入神经网络的时候会被处理的大小,之说以需要这样,如果看了我前面的那篇Pytorch 从0到部署 应该是知道的,这里我不想复述,看这篇文章的多少都是有基础的。
所以,我前面是被误导了。那竟然不是这个原因还能是什么原因呢。显然这里还有一个原因那就是 可信度。
问题来了,如果是可信度的问题,那么为什么训练测试的就好好的有明显的的目标标注呢。这个怎么说呢。深度学习本质上是一个机器学习。是一个学习的过程,并且神经网络的训练本质上应该是一个建模拟合的过程。
我们举一个最直观的例子,那就是学生学习做试卷。
一个学生想要取得好成绩,无非两条件,天赋+学习。
在我们这里 天赋就是神经网络结构,对神经网络进行优化。学习自然就是获取权重的过程,也就是训练过程。
我们在排查问题的现在,显然我们先排除天赋问题,也就是神经网络结构的问题。
所以现在的问题来到了学习上。
学习有多种方式,要么题海战术,要么精打细算(认真搞清楚会的)
所以这里引出了我们深度学习需要的几个东西:数据量(题目),学习速率,学习时间(学习轮数)。
那么我们看看题海战术会出现什么问题,首先采用这个策略需要有足够的数据集,但是这里有个问题,你题目做的多,看的题型多,并不意味着,你就会了呀,做的多不代表懂得多。深度学习的过程,相当于拿着标准答案去刷题(所以你测试的时候能够出来很正常)。但是实际上考试的时候,没有答案,你见到题目多但是,你没有掌握到精髓呀,所以自然题目做不出来,那么也就是识别不出来。
看看第二个,精打细算。这个属于什么呢,不拼数量,拼精度。学会举一反三,问题就是学得慢,适合咱们数据集小的情况。
也就是咱们现在的情况,一共才24张图片。所以,这个时候我们要干嘛,提高精度呀,学久一点,学慢一点,慢慢来。
那么实际上控制这些的有哪些参数呢
我们把目光放在train.py 这个文件
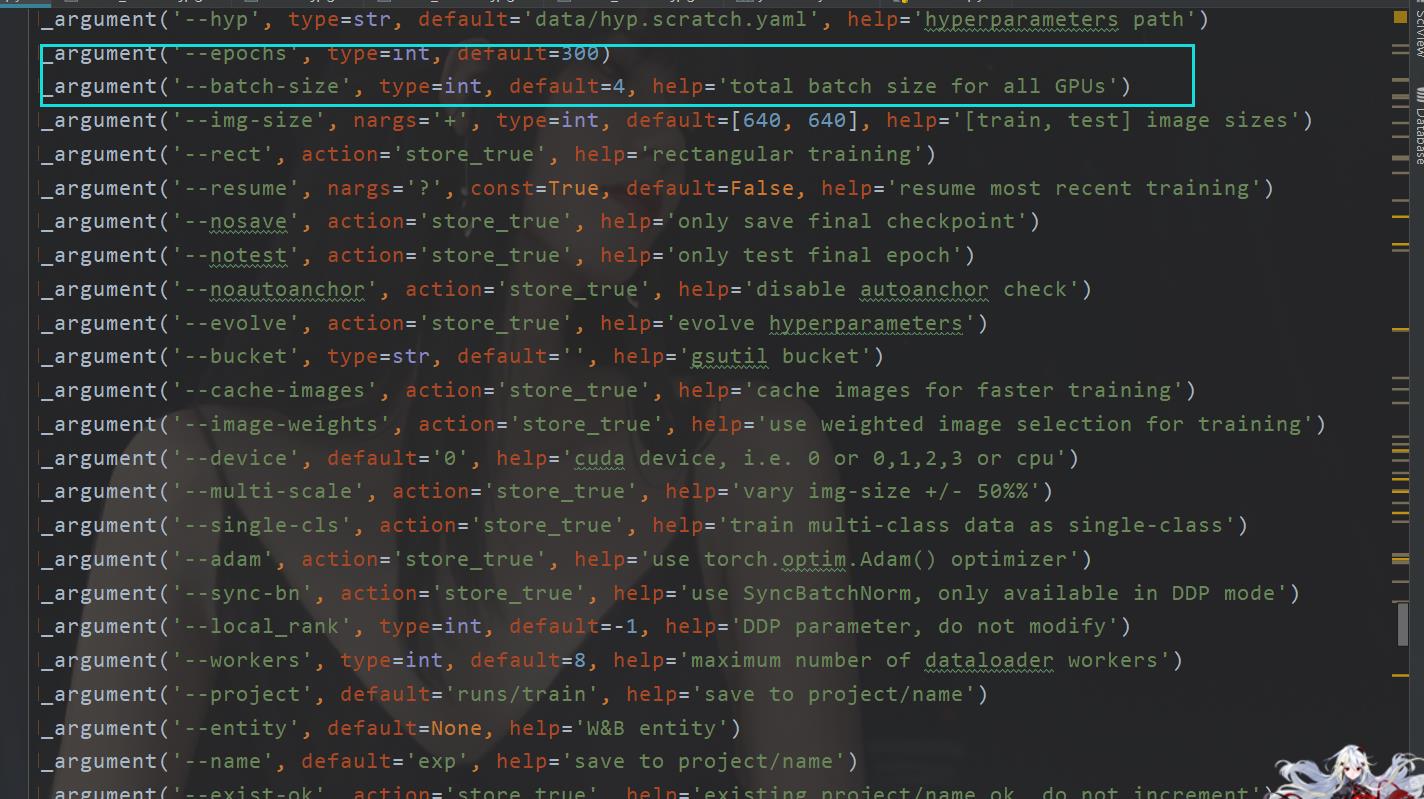
当然还有一个 lr 这个没必要动,我们也可以通过提高学习轮数来达到效果。
第一个不用说,学久一点,第二个 batch-size
这个参数很重要,两个原因,第一个我们是在显卡上面跑,这个的大小涉及到我们显卡性能
第二个,这个大小也就是我说的,你要不要学精的问题,越大,学得越快,N个题目一块看,自然学不到啥,当然是在相同的学习时长(轮数)下,设置小一点,例如这里是4(默认是8)那就一次性学4个题目,自然会精度高一点。
重新训练
来看看咱们原来的指令
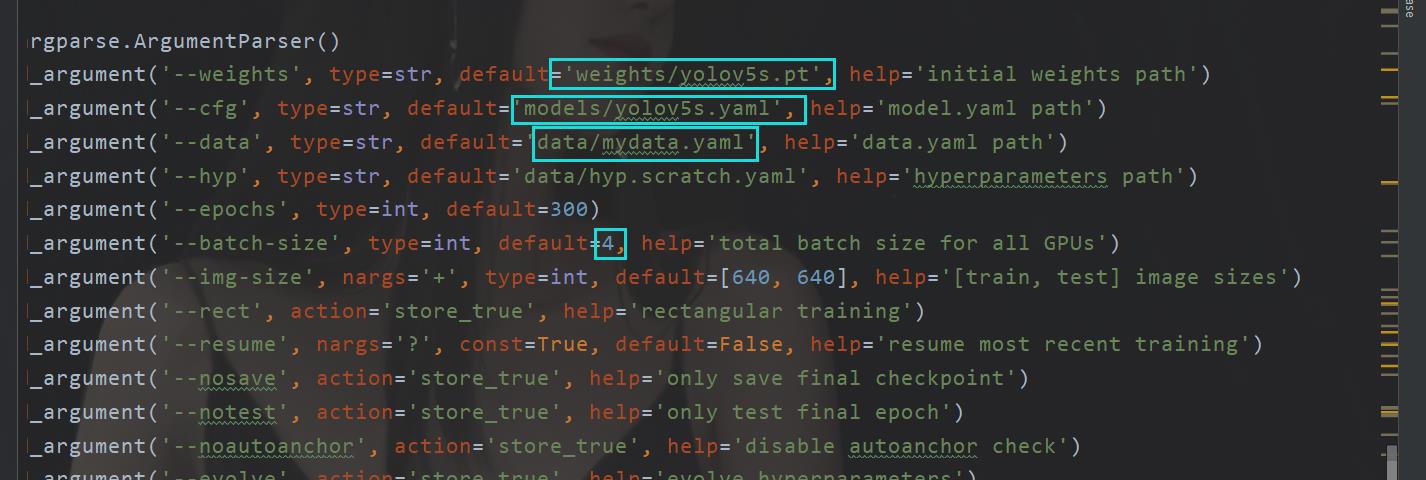
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/mydata.yaml --epoch 200 --batch-size 4 --device 0
首先第一个呢,其实迁移学习的意思,用训练好的参数去再训练,而不是默认值,这样会快一点
第二个参数呢,是那个模型的参数设置,分几个类呀啥的
第三个参数,指定咱们的数据集
第四个参数,训练次数(时长,这样理解)
第五个参数,一次性进入训练的数据集大小(个数)
第六个参数,训练平台(我这里是cuda0也就是用我自己的显卡训练GTX1650(害,穷,垃圾卡先用着))
所以现在,我们训练的轮数可能太少了,所以嘞,我们就用300看看(默认也是300)
现在这里的话为了方便,我就直接在文件里面改了
直接让它运行,之后咱们来查看结果
tensorboard --logdir=runs

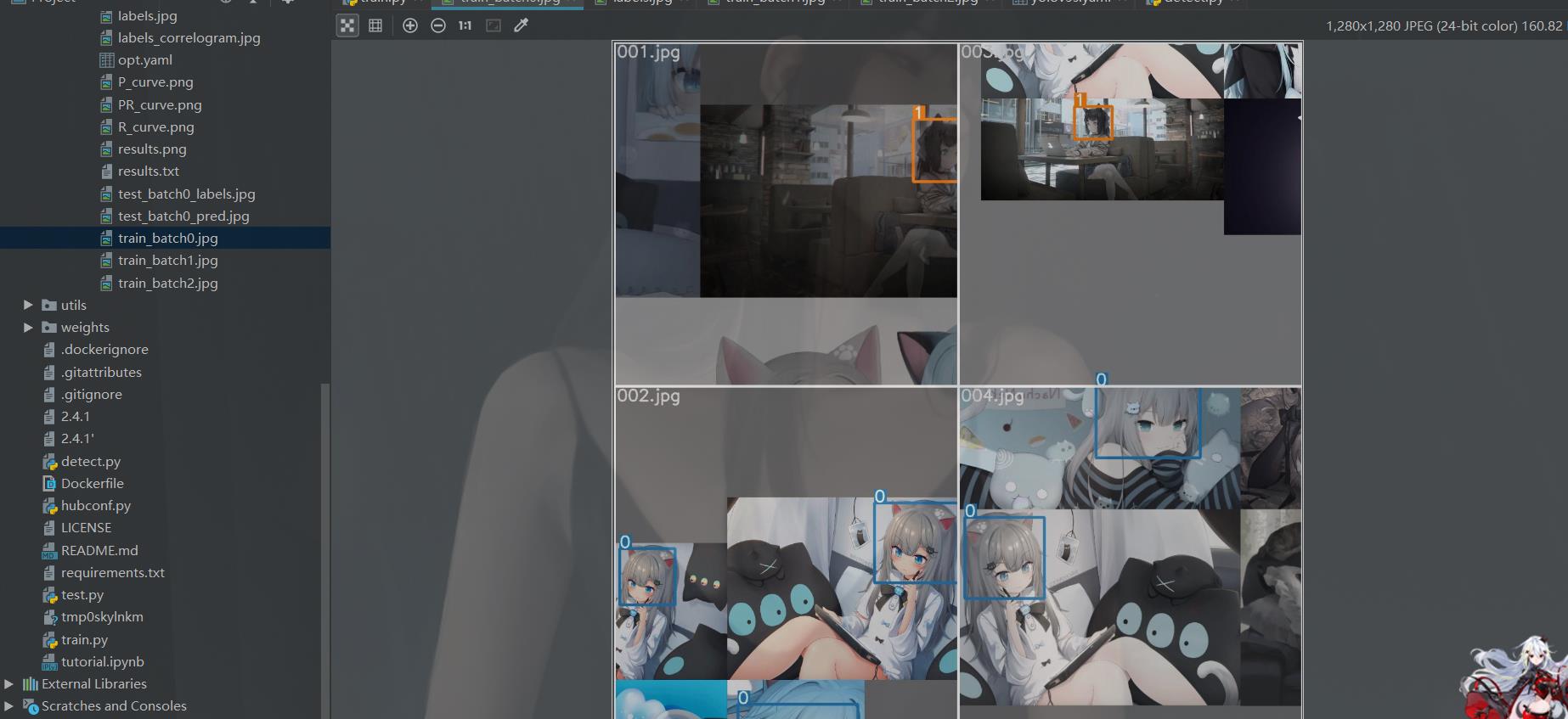
测试
现在咱们测试一下咱们的模型
同样的为了方便,我这里也是直接该参数在文件里面搞
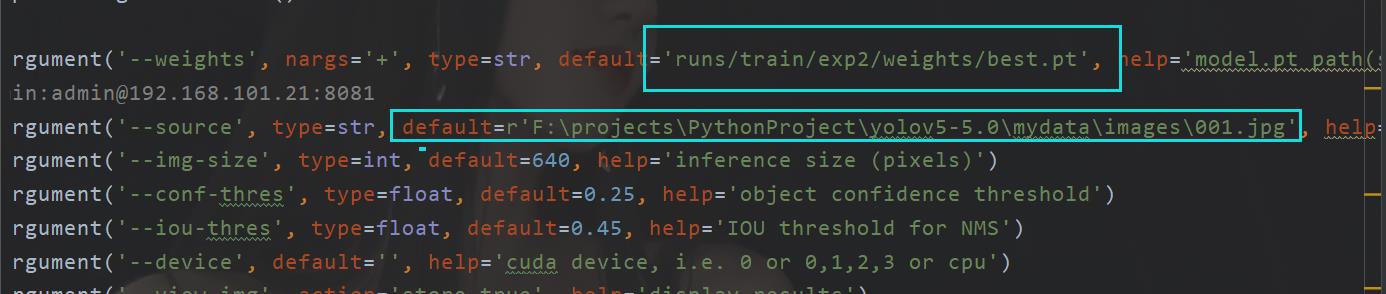
这里的话,一方面是为了方便,还有就是有些超参数我懒得去设置了。
来看看效果:

好框出来了,但是问题来了 问号是什么玩意
中文乱码
好不容易解决了训练问题,接下来是这个毛病,这个呢也好解决,主要是opencv的问题。
这玩意默认是不支持中文的,在我们当前的这个版本当中,问题定位到这里。
所以修改一下源码就好了。

一开始 我的解决方案是直接在Puttext指定那个字体,但是可能是和我一般使用的cv版本不一样,没有设置参数。
所以最后也是在Bing了一下,之后找到解决方案。
先来看看咱们解决好之后的样子

先来一个搜索小技巧
yolov5-5 中文框 -csdn
原文参考链接
https://zhuanlan.zhihu.com/p/359494157
那么如何解决呢,首先的话得先下载字体
链接:https://pan.baidu.com/s/1qXVXBgfDyUUhOhyHDkooGw
提取码:6666
下载之后解压,这里的话我放在了这个文件夹
然后找到咱们的 这个文件
找到这个函数
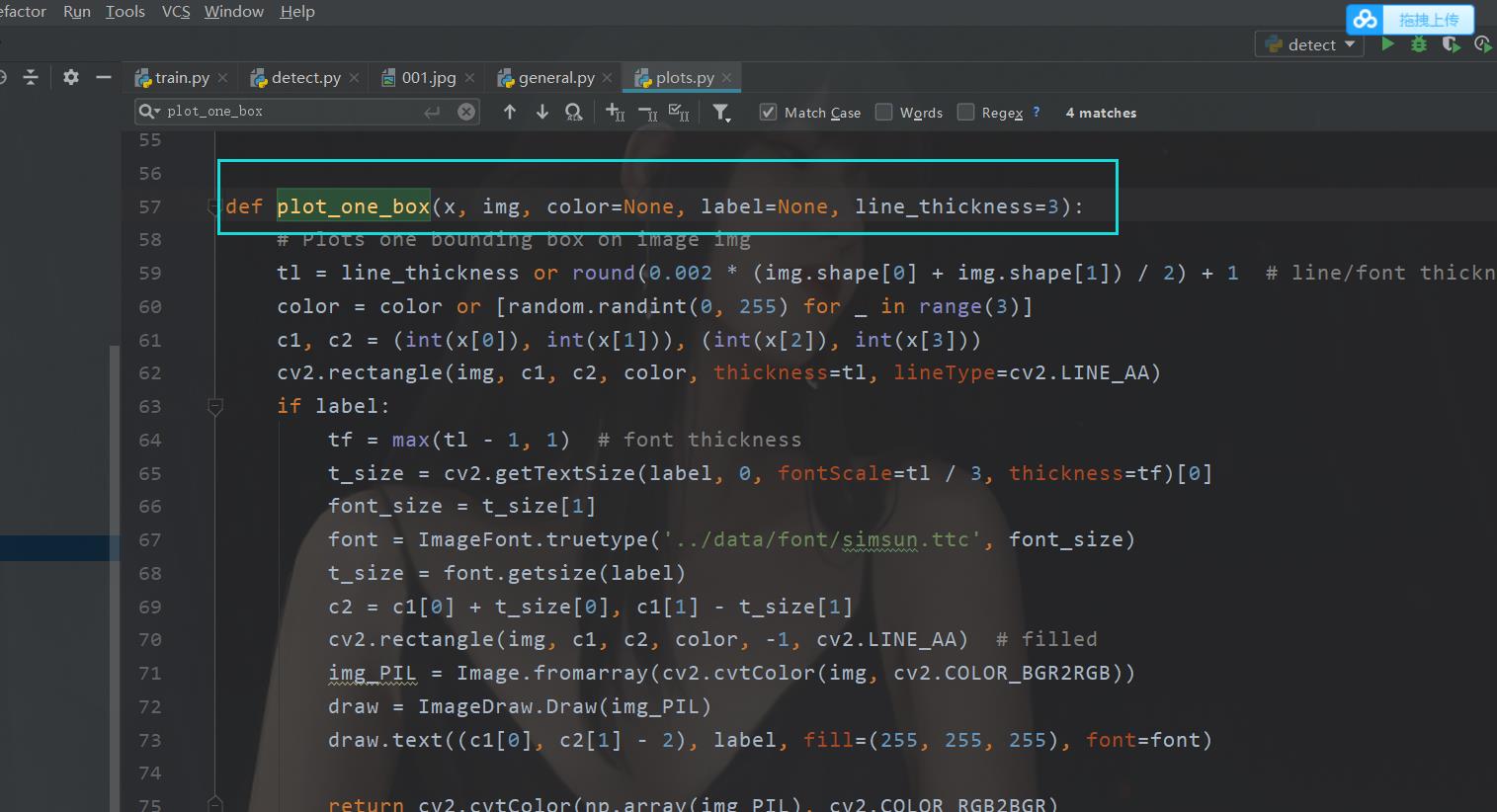
修改代码
def plot_one_box(x, img, color=None, label=None, line_thickness=3):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
font_size = t_size[1]
font = ImageFont.truetype('../data/font/simsun.ttc', font_size)
t_size = font.getsize(label)
c2 = c1[0] + t_size[0], c1[1] - t_size[1]
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
img_PIL = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_PIL)
draw.text((c1[0], c2[1] - 2), label, fill=(255, 255, 255), font=font)
return cv2.cvtColor(np.array(img_PIL), cv2.COLOR_RGB2BGR)
# if label:
# tf = max(tl - 1, 1) # font thickness
# t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
# c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
# cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
# cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
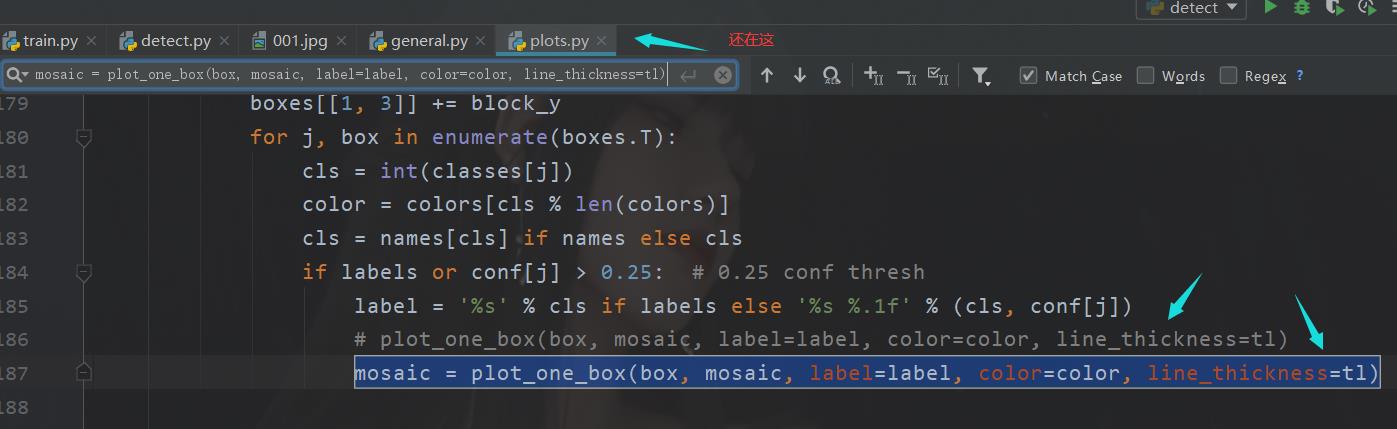
mosaic = plot_one_box(box, mosaic, label=label, color=color, line_thickness=tl)
回到 detect.py
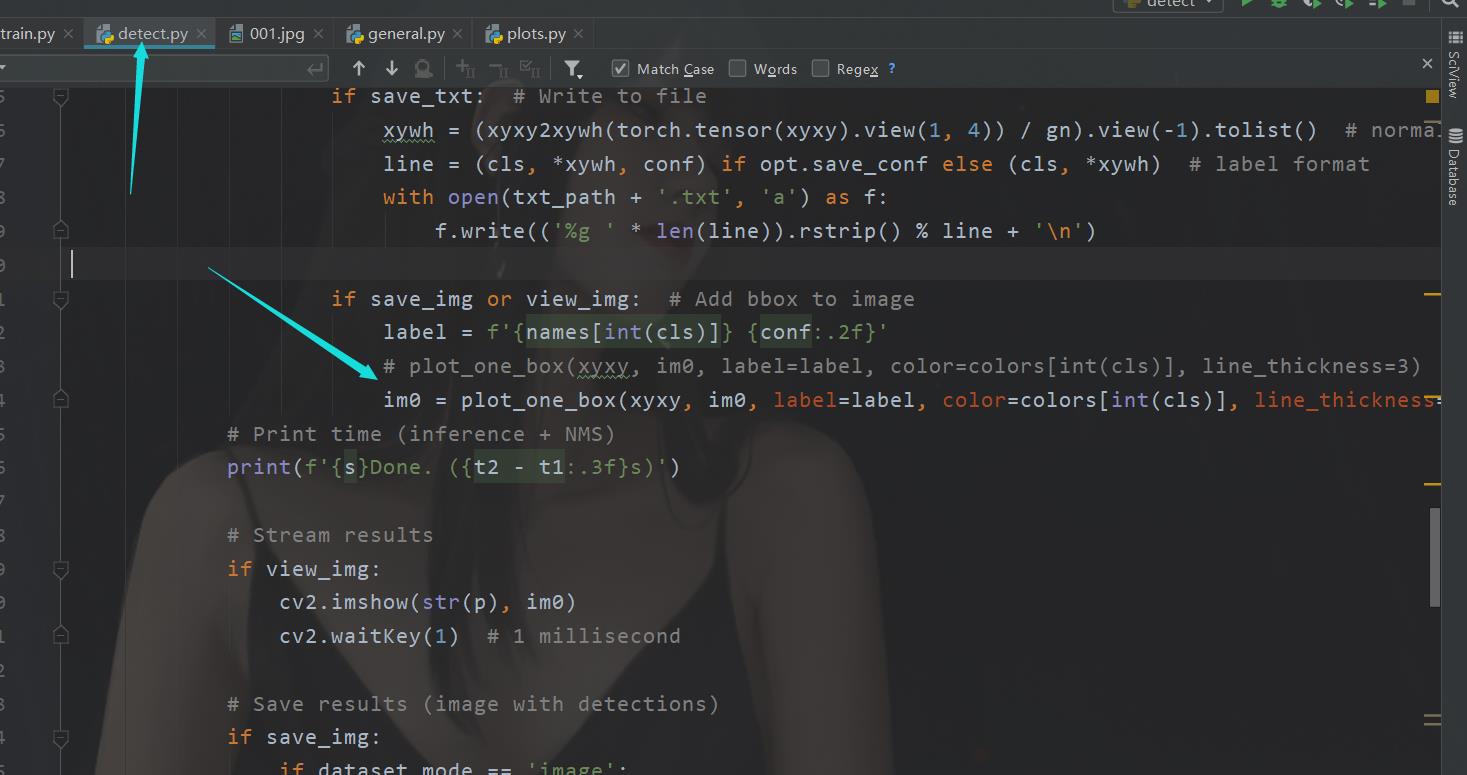
im0 = plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
ok ,到目前为止就好了。
哦,此外,除了上次编码的错误外,为了安全起见,这个 text.py 下面也可以修改一下
到这里,就OK了。
那么接下来是那些参数的设置。搞清楚这些,差不多就能熟练地使用了。
接下来就是先啃论文,然后怼源码。最后工程化 YOLOV5,然后做项目,没错我就是为了互联网+ 比赛铺路。
参数
detect.py 参数
weights:训练的权重
source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流
output:网络预测之后的图片/视频的保存路径
img-size:网络输入图片大小
conf-thres:置信度阈值
iou-thres:做nms的iou阈值
device:设置设备
view-img:是否展示预测之后的图片/视频,默认False
save-txt:是否将预测的框坐标以txt文件形式保存,默认False
classes:设置只保留某一部分类别,形如0或者0 2 3
agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
augment:推理的时候进行多尺度,翻转等操作(TTA)推理
update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
train.py 参数
weights:训练的权重(这里主要是为了迁移学习,你也可以不要default=‘’)
cfg:模型配置文件,网络结构
data:数据集配置文件,数据集路径,类名等
hyp:超参数文件
epochs:训练总轮次
batch-size:批次大小
img-size:输入图片分辨率大小
rect:是否采用矩形训练,默认False
resume:接着打断训练上次的结果接着训练
nosave:不保存模型,默认False
notest:不进行test,默认False
noautoanchor:不自动调整anchor,默认False
evolve:是否进行超参数进化,默认False
bucket:谷歌云盘bucket,一般不会用到
cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
weights:加载的权重文件
name:数据集名字,如果设置:results.txt to results_name.txt,默认无
device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
multi-scale:是否进行多尺度训练,默认False
single-cls:数据集是否只有一个类别,默认False
adam:是否使用adam优化器
sync-bn:是否使用跨卡同步BN,在DDP模式使用
local_rank:gpu编号
logdir:存放日志的目录
workers:dataloader的最大worker数量
总结
大概就这么多,主要结合上篇博文的后续补充。
以上是关于YOLOV5 参数设定与模型训练的坑点一二三的主要内容,如果未能解决你的问题,请参考以下文章