先读懂CapsNet架构然后用TensorFlow实现:全面解析Hinton的提出的Capsule
Posted 机器之心V
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了先读懂CapsNet架构然后用TensorFlow实现:全面解析Hinton的提出的Capsule相关的知识,希望对你有一定的参考价值。
上周 Geoffrey Hinton 等人公开了那篇备受关注的 NIPS 论文,而后很多研究者与开发者都阅读了该论文并作出了一定的代码实现。机器之心在本文中将详细解释该论文提出的结构与过程,并借助 GitHub 上热烈讨论的项目完成了 CapsNet 的 TensorFlow 实现,并提供了主体架构的代码注释。
本文是机器之心的第三个 GitHub 项目,旨在解释 CapsNet 的网络架构与实现。为了解释 CapsNet,我们将从卷积层与卷积机制开始,从工程实践的角度解释卷积操作的过程与输出,这对进一步理解 Capsule 层的处理十分有利,后面我们将基于对 Capsule 层的理解解释 Geoffrey Hinton 等人最近提出来的 CapsNet 架构。最后我们会根据 naturomics 的实现进行测试与解释。
机器之心 GitHub 项目地址:https://github.com/jiqizhixin/ML-Tutorial-Experiment
卷积层与卷积机制
这一部分主要是为不太了解卷积机制具体过程的读者准备,因为 CapsNet 的前面两层本质上还是传统的卷积操作。若读者已经了解基本的卷积操作,那么可以跳过这一章节直接阅读 Capsule 层的结构与过程。
若要解释卷积神经网络,我们先要知道为什么卷积在图像上能比全连接网络有更好的性能,以下分别展示了全连接网络和卷积网络一般的架构:
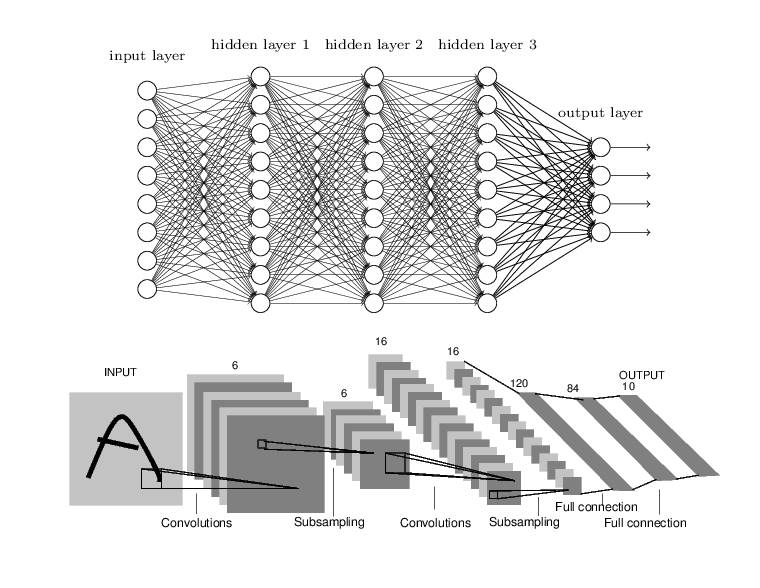
我们知道全连接网络前一层的每个神经元(或单元)都会与后一层中每个神经元相连,连接的强弱可以通过相对应的权重控制。而所有连接权重就是该全连接神经网络希望学到的。上图可知卷积神经网络也是由一层一层的神经元组织起来的,只不过全连接网络相邻两层的神经元都有连接,所以可以将相同层的神经元排列为一列,这样可以方便显示连接结构。而卷积网络相连两层之间只有部分神经元相连,为了展示每一层神经元的维度,我们一般会将每一个卷积层的结点组织为一个三维张量。
全连接网络处理图像最大的问题是每层之间的参数或权重太多了,主要是因为两层间的神经元都有连接。若使用一个隐藏层为 500 个单元的全连接网络(784×500×10)识别 MNIST 手写数字,那么参数的数量为 28×28×500+5000+510=397510 个参数,这大大限制了网络层级的加深。
而对于卷积网络来说,每一个单元都只会和上一层部分单元相连接。一般每个卷积层的单元都可以组织成一个三维张量,即矩阵沿第三个方向增加一维数据。例如 Cifar-10 数据集的输入层就可以组织成 32×32×3 的三维张量,其中 32×32 代表图片的尺寸或像素数量,而 3 代表 RGB 三色通道。
卷积层
卷积层试图将神经网络中的每一小块进行更加深入的分析,从而得出抽象程度更高的特征。一般来说通过卷积层处理的神经元结点矩阵会变得更深,即神经元的组织在第三个维度上会增加。
下图展示了卷积核或滤波器(filter)将当前层级上的一个子结点张量转化为下一层神经网络上的一个长和宽都为 1,深度不限的结点矩阵。下图输入是一个 32×32×3 的张量,中间的小长方体为卷积核,一般可以为 3×3 或 5×5 等,且因为要计算乘积,那么卷积核的第三个维度必须和其处理的图像深度(即输入张量第三个维度 3)相等。最右边的矩形体的深度为 5,即前面使用了五个卷积核执行卷积操作。这五个卷积核有不同的权重,但每一个卷积层使用一个卷积核的权重是一样的,所以下图五层特征中每一层特征都是通过一个卷积核得出来的,也就是该层共享了权重。
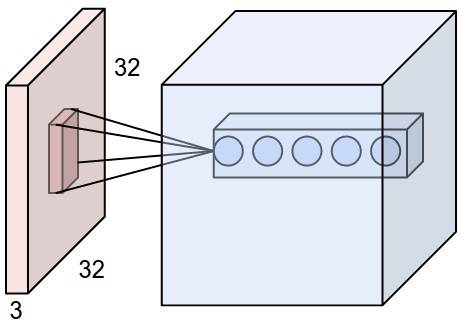
卷积操作
可能入门读者对卷积的具体过程还是不够了解,下面我们可以讨论卷积操作的具体过程。如下所示,该图展示了卷积的具体操作过程。首先我们的输入为 5×5×3 的张量,即 x[:, :, 0 : 3]。其次我们有两个 3×3 的卷积核,即 W0 和 W1,第三个维度必须和输入张量的第三个维度相等,所以一般只用两个维度描述一个卷积核。最后卷积操作输出 3×3×2 的张量,其中 o[:, :, 0] 为第一个卷积核 W0 的卷积输出,o[:, :, 1] 为第二个卷积核的输出。因为输入张量使用了 Padding,即每一个通道的输入图像周围加 0,且卷积核移动的步幅为 2,则每个卷积核输出的维度为 3×3(即 (7-3)/2)。

在上图中,卷积核会与输入张量对应相乘相加,然后再加上偏置项就等于输出张量中对应位置的值。例如使用卷积和 W0 对输入张量(深度为 3 可看作图像拥有的 RGB 三个通道)做卷积,卷积和三个层级将对应输入张量的三个层级做乘积累计。w0[:, :, 0] 乘以 x[:, :, 0] 左上角的九个元素为 1*0+1*0-1*0-1*0+0*0+1*1-1*0-1*0+0*1=1,同理 w0[:, :, 1] 乘以 x[:, :, 1] 左上角九个元素为-1、w0[:, :, 2] 乘以 x[:, :, 2] 左上角九个元素为 0,这三个值相加再加上偏置项 b0 就等于最右边输出张量 o[:, :, 0] 的左上角第一个元素,即 1-1+0+1=1。
随着卷积核移动一个步长,我们可以计算出输出矩阵移动一个元素的值。注意但卷积核在输入张量上移动的时候,卷积核权重是相同的,也就是说这一层共享了相同的权重,即 o[:, :, 0] 和 o[:, :, 1] 分别共享了一组权重。这里之所以强调权重的共享,不仅因为它是卷积层核心的属性,同时还有利于我们在后面理解 CapsNet 的 PrimaryCaps 层。
卷积还有很多性质没有解释,例如最大池化选取一个滤波器内数值最大的值代表该区域的特征以减少输出张量的尺寸,Inception 模块将多组卷积核并联地对输入张量进行处理,然后再将并联处理得到的多个输出张量按序串联地组成一个很深的输出张量作为 Inception 模块的输出等。读者也可以继续阅读机器之心关于卷积的文章进一步了解。最后,我们提供了一个简单的实现展示卷积操作的计算过程:
import tensorflow as tf
import numpy as np
# 输入张量为3×3的二维矩阵
M = np.array([
[[1],[-1],[0]],
[[-1],[2],[1]],
[[0],[2],[-2]]
])
# 定义卷积核权重和偏置项。由权重可知我们只定义了一个2×2×1的卷积核
filter_weight = tf.get_variable('weights', [2, 2, 1, 1], initializer = tf.constant_initializer([
[1, -1],
[0, 2]]))
biases = tf.get_variable('biases', [1], initializer = tf.constant_initializer(1))
# 调整输入格式符合TensorFlow要求
M = np.asarray(M, dtype='float32')
M = M.reshape(1, 3, 3, 1)
#计算输入张量通过卷积核和池化滤波器计算后的结果
x = tf.placeholder('float32', [1, None, None, 1])
# 我们使用了带Padding,步幅为2的卷积操作,因为filter_weight的深度确定了卷积核的数量
conv = tf.nn.conv2d(x, filter_weight, strides = [1, 2, 2, 1], padding = 'SAME')
bias = tf.nn.bias_add(conv, biases)
# 使用带Padding,步幅为2的平均池化操作
pool = tf.nn.avg_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 执行计算图
with tf.Session() as sess:
tf.global_variables_initializer().run()
convoluted_M = sess.run(bias,feed_dict=x:M)
pooled_M = sess.run(pool,feed_dict=x:M)
print ("convoluted_M: \\n", convoluted_M)
print ("pooled_M: \\n", pooled_M)
这一段代码执行了卷积操作和平均池化,它的输出如下:

Capsule 层与动态路由
这一部分主要是解释 Capsule 层与动态路由(DynamicRouting)机制的大概原理,这一部分基于我们对 Hinton 原论文的理解完成,并采用了知乎 SIY.Z、Debarko De 等人的观点。文末将给出更多的参考资料,读者可进一步阅读以了解更多。
前面我们已经知道卷积通过权重共享和局部连接可以减少很多参数,此外共享卷积核权重可以使图像上的内容不受位置的影响。例如 Cifar-10 中的图像为 32×32×3,而由 16 个尺寸为 5×5 的卷积核(或表述深度为 16)所构成的卷积层,其参数共有 5*5*3*16+16=1216 个。但这这样的卷积层单元还是太简单了,它们也不能表征复杂的概念。
例如当图像进行一些旋转、变形或朝向不同的方向,那么 CNN 本身是无法处理这些图片的。当然这个问题可以在训练中添加相同图像的不同变形而得到解决。在 CNN 中每一层都以非常细微的方式理解图像,因为我们卷积核的感受野一般使用 3×3 或 5×5 等像素级的操作来理解图像,所以卷积层总是尝试理解局部的特征与信息。而当我们由前面低级特征组合成后面复杂与抽象的特征时,我们很可能需要使用池化操作来减少输出张量或特征图的尺寸,而这种操作实际上会丢失一些信息,比如说位置信息。
而等变映射(Equivariance)可以帮助 CNN 理解旋转或比例等属性变换,并相应地调整自己,这样图像空间中的位置等属性信息就不会丢失。而 Geoffrey Hinton 等人提出的 CapsNet 使用向量代替标量点,因此能获取更多的信息。此外,我们感觉 Capsule 使用向量作为输入与输出是这篇论文的亮点。
Capsule 层
在论文中,Geoffrey Hinton 介绍 Capsule 为:「Capsule 是一组神经元,其输入输出向量表示特定实体类型的实例化参数(即特定物体、概念实体等出现的概率与某些属性)。我们使用输入输出向量的长度表征实体存在的概率,向量的方向表示实例化参数(即实体的某些图形属性)。同一层级的 capsule 通过变换矩阵对更高级别的 capsule 的实例化参数进行预测。当多个预测一致时(本论文使用动态路由使预测一致),更高级别的 capsule 将变得活跃。」
Capsule 中的神经元的激活情况表示了图像中存在的特定实体的各种性质。这些性质可以包含很多种不同的参数,例如姿势(位置,大小,方向)、变形、速度、反射率,色彩、纹理等等。而输入输出向量的长度表示了某个实体出现的概率,所以它的值必须在 0 到 1 之间。
为了实现这种压缩,并完成 Capsule 层级的激活功能,Hinton 等人使用了一个被称为「squashing」的非线性函数。该非线性函数确保短向量的长度能够缩短到几乎等于零,而长向量的长度压缩到接近但不超过 1 的情况。以下是该非线性函数的表达式:

其中 v_j 为 Capsule j 的输出向量,s_j 为上一层所有 Capsule 输出到当前层 Capsule j 的向量加权和,简单说 s_j 就为 Capsule j 的输入向量。该非线性函数可以分为两部分,即
 和
和  ,前一部分是输入向量 s_j 的缩放尺度,第二部分是输入向量 s_j 的单位向量,该非线性函数既保留了输入向量的方向,又将输入向量的长度压缩到区间 [0,1) 内。s_j 向量为零向量时 v_j 能取到 0,而 s_j 无穷大时 v_j 无限逼近 1。该非线性函数可以看作是对向量长度的一种压缩和重分配,因此也可以看作是一种输入向量后「激活」输出向量的方式。
,前一部分是输入向量 s_j 的缩放尺度,第二部分是输入向量 s_j 的单位向量,该非线性函数既保留了输入向量的方向,又将输入向量的长度压缩到区间 [0,1) 内。s_j 向量为零向量时 v_j 能取到 0,而 s_j 无穷大时 v_j 无限逼近 1。该非线性函数可以看作是对向量长度的一种压缩和重分配,因此也可以看作是一种输入向量后「激活」输出向量的方式。
那么如上所述,Capsule 的输入向量就相当于经典神经网络神经元的标量输入,而该向量的计算就相当于两层 Capsule 间的传播与连接方式。输入向量的计算分为两个阶段,即线性组合和 Routing,这一过程可以用以下公式表示:

其中 u_j|i hat 为 u_i 的线性组合,这一点可以看作是一般全连接网络前一层神经元以不同强弱的连接输出到后一层某个神经元。只不过 Capsule 相对于一般神经网络每个结点都有一组神经元(以生成向量),即 u_j|i hat 表示上一层第 i 个 Capsule 的输出向量和对应的权重向量相乘(W_ij 表示向量而不是元素)而得出的预测向量。u_j|i hat 也可以理解为在前一层为第 i 个 Capsule 的情况下连接到后一层第 j 个 Capsule 的强度。
在确定 u_j|i hat 后,我们需要使用 Routing 进行第二个阶段的分配以计算输出结点 s_j,这一过程就涉及到使用动态路由(dynamic routing)迭代地更新 c_ij。通过 Routing 就能获取下一层 Capsule 的输入 s_j,然后将 s_j 投入「Squashing」非线性函数后就能得出下一层 Capsule 的输出。后面我们会重点解释 Routing 算法,但整个 Capsule 层及它们间传播的过程已经完成了。
所以整个层级间的传播与分配可以分为两个部分,第一部分是下图 u_i 与 u_j|i hat 间的线性组合,第二部分是 u_j|i hat 与 s_j 之间的 Routing 过程。若读者对传播过程仍然不是太明晰,那么可以看以下两层 Capsule 单元间的传播过程,该图是根据我们对传播过程的理解而绘制的:
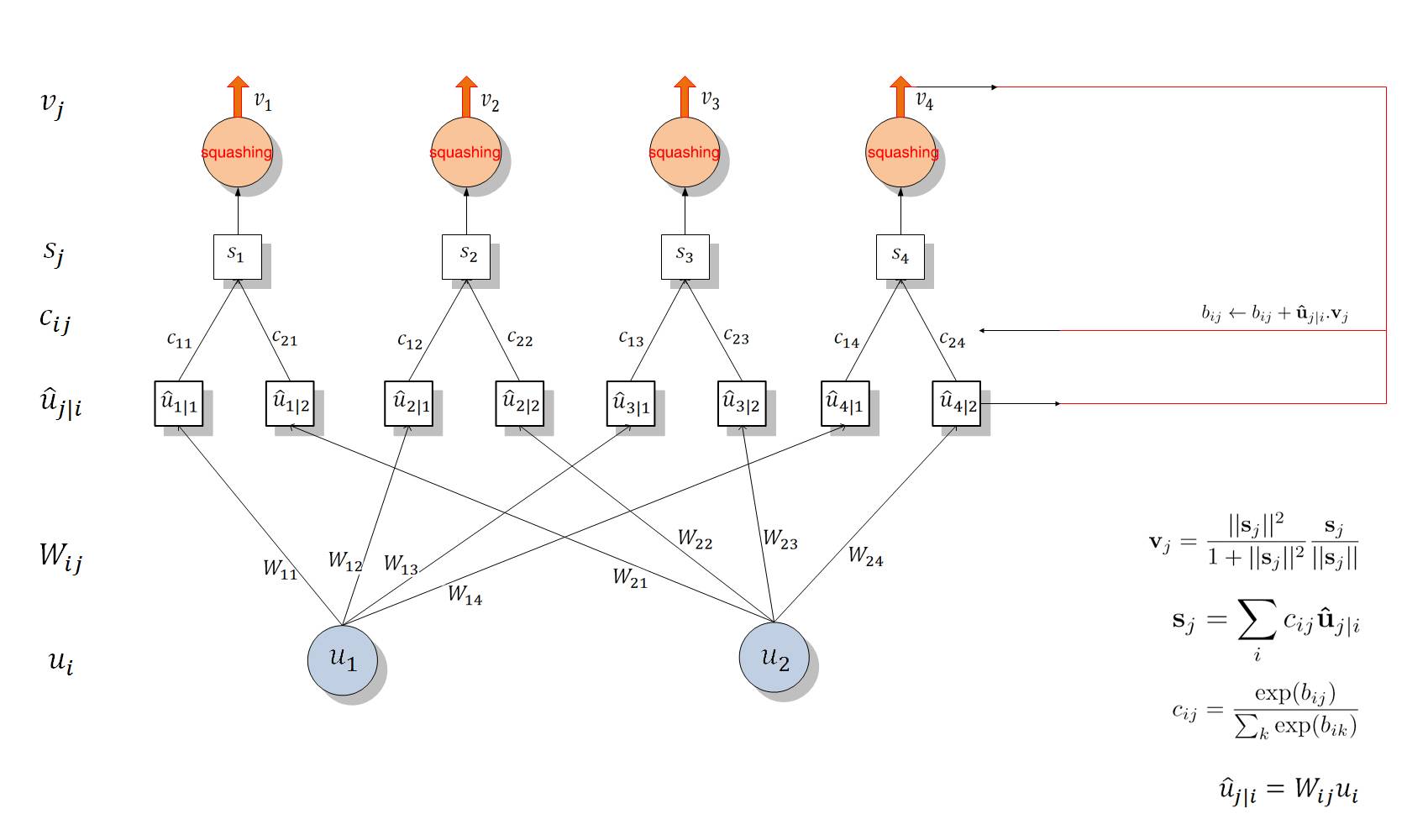
图:Capsule 层级结构图
如上所示,该图展示了 Capsule 的层级结构与动态 Routing 的过程。最下面的层级 u_i 共有两个 Capsule 单元,该层级传递到下一层级 v_j 共有四个 Capsule。u_1 和 u_2 是一个向量,即含有一组神经元的 Capsule 单元,它们分别与不同的权重 W_ij(同样是向量)相乘得出 u_j|i hat。例如 u_1 与 W_12 相乘得出预测向量 u_2|1 hat。随后该预测向量和对应的「耦合系数」c_ij 相乘并传入特定的后一层 Capsule 单元。不同 Capsule 单元的输入 s_j 是所有可能传入该单元的加权和,即所有可能传入的预测向量与耦合系数的乘积和。随后我们就得到了不同的输入向量 s_j,将该输入向量投入到「squashing」非线性函数就能得出后一层 Capsule 单元的输出向量 v_j。然后我们可以利用该输出向量 v_j 和对应预测向量 u_j|i hat 的乘积更新耦合系数 c_ij,这样的迭代更新不需要应用反向传播。
Dynamic Routing 算法
因为按照 Hinton 的思想,找到最好的处理路径就等价于正确处理了图像,所以在 Capsule 中加入 Routing 机制可以找到一组系数 c_ij,它们能令预测向量 u_j|i hat 最符合输出向量 v_j,即最符合输出的输入向量,这样我们就找到了最好的路径。
按照原论文所述,c_ij 为耦合系数(coupling coefficients),该系数由动态 Routing 过程迭代地更新与确定。Capsule i 和后一层级所有 Capsule 间的耦合系数和为 1,即图四 c_11+c_12+c_13+c_14=1。此外,该耦合系数由「routing softmax」决定,且 softmax 函数中的 logits b_ij 初始化为 0,耦合系数 c_ij 的 softmax 计算方式为:

b_ij 依赖于两个 Capsule 的位置与类型,但不依赖于当前的输入图像。我们可以通过测量后面层级中每一个 Capsule j 的当前输出 v_j 和 前面层级 Capsule i 的预测向量间的一致性,然后借助该测量的一致性迭代地更新耦合系数。本论文简单地通过内积度量这种一致性,即 ,这一部分也就涉及到使用 Routing 更新耦合系数。
,这一部分也就涉及到使用 Routing 更新耦合系数。
Routing 过程就是上图 4 右边表述的更新过程,我们会计算 v_j 与 u_j|i hat 的乘积并将它与原来的 b_ij 相加而更新 b_ij,然后利用 softmax(b_ij) 更新 c_ij 而进一步修正了后一层的 Capsule 输入 s_j。当输出新的 v_j 后又可以迭代地更新 c_ij,这样我们不需要反向传播而直接通过计算输入与输出的一致性更新参数。
该 Routing 算法更具体的更新过程可以查看以下伪代码:

对于所有在 l 层的 Capsule i 和在 l+1 层的 Capsule j,先初始化 b_ij 等于零。然后迭代 r 次,每次先根据 b_i 计算 c_i,然后在利用 c_ij 与 u_j|i hat 计算 s_j 与 v_j。利用计算出来的 v_j 更新 b_ij 以进入下一个迭代循环更新 c_ij。该 Routing 算法十分容易收敛,基本上通过 3 次迭代就能有不错的效果。
CapsNet 架构
Hinton 等人实现了一个简单的 CapsNet 架构,该架构由两个卷积层和一个全连接层组成,其中第一个为一般的卷积层,第二个卷积相当于为 Capsule 层做准备,并且该层的输出为向量,所以它的维度要比一般的卷积层再高一个维度。最后就是通过向量的输入与 Routing 过程等构建出 10 个 v_j 向量,每一个向量的长度都直接表示某个类别的概率。
以下是 CapsNet 的整体架构:

第一个卷积层使用了 256 个 9×9 卷积核,步幅为 1,且使用了 ReLU 激活函数。该卷积操作应该没有使用 Padding,输出的张量才能是 20×20×256。此外,CapsNet 的卷积核感受野使用的是 9×9,相比于其它 3×3 或 5×5 的要大一些,这个能是因为较大的感受野在 CNN 层次较少的情况下能感受的信息越多。这两层间的权值数量应该为 9×9×256+256=20992。
随后,第二个卷积层开始作为 Capsule 层的输入而构建相应的张量结构。我们可以从上图看出第二层卷积操作后生成的张量维度为 6×6×8×32,那么我们该如何理解这个张量呢?云梦居客在知乎上给出了一个十分形象且有意思的解释,如前面章节所述,如果我们先考虑 32 个(32 channel)9×9 的卷积核在步幅为 2 的情况下做卷积,那么实际上得到的是传统的 6×6×32 的张量,即等价于 6×6×1×32。
因为传统卷积操作每次计算的输出都是一个标量,而 PrimaryCaps 的输出需要是一个长度为 8 的向量,因此传统卷积下的三维输出张量 6×6×1×32 就需要变化为四维输出张量 6×6×8×32。如下所示,其实我们可以将第二个卷积层看作对维度为 20×20×256 的输入张量执行 8 次不同权重的 Conv2d 操作,每次 Conv2d 都执行带 32 个 9×9 卷积核、步幅为 2 的卷积操作。
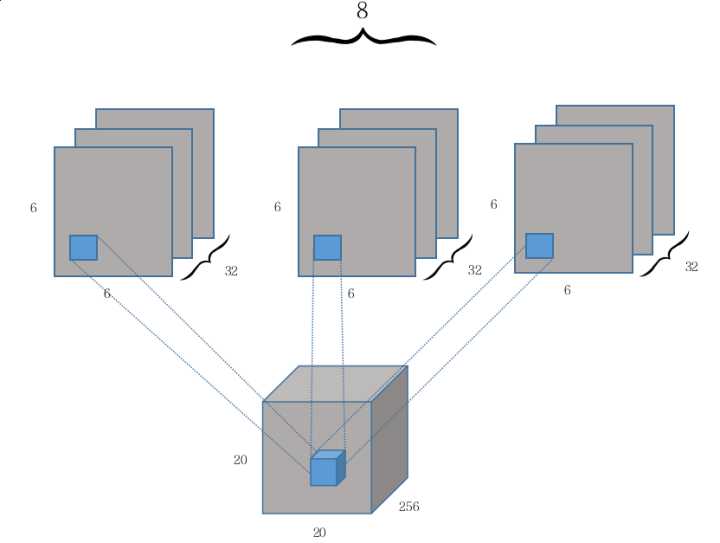
由于每次卷积操作都会产生一个 6×6×1×32 的张量,一共会产生 8 个类似的张量,那么将这 8 个张量(即 Capsule 输入向量的 8 个分量)在第三个维度上合并在一起就成了 6×6×8×32。从上可知 PrimaryCaps 就相当于一个深度为 32 的普通卷积层,只不过每一层由以前的标量值变成了长度为 8 的向量。
此外,结合 Hinton 等人给出的 Capsule 定义,它就相当于一组常见的神经元,这些神经元封装在一起形成了新的单元。在本论文讨论的 CapsNet 架构中,我们将 8 个卷积单元封装在一起成为了一个新的 Caosule 单元。PrimaryCaps 层的卷积计算都没有使用 ReLU 等激活函数,它们以向量的方式预备输入到下一层 Capsule 单元中。
PrimaryCaps 每一个向量的分量层级是共享卷积权重的,即获取 6×6 张量的卷积核权重为相同的 9×9 个。这样该卷积层的参数数量为 9×9×256×8×32+8×32=5308672,其中第二部分 8×32 为偏置项参数数量。
第三层 DigitCaps 在第二层输出的向量基础上进行传播与 Routing 更新。第二层共输出 6×6×32=1152 个向量,每一个向量的维度为 8,即第 i 层共有 1152 个 Capsule 单元。而第三层 j 有 10 个标准的 Capsule 单元,每个 Capsule 的输出向量有 16 个元素。前一层的 Capsule 单元数是 1152 个,那么 w_ij 将有 1152×10 个,且每一个 w_ij 的维度为 8×16。当 u_i 与对应的 w_ij 相乘得到预测向量后,我们会有 1152×10 个耦合系数 c_ij,对应加权求和后会得到 10 个 16×1 的输入向量。将该输入向量输入到「squashing」非线性函数中求得最终的输出向量 v_j,其中 v_j 的长度就表示识别为某个类别的概率。
DigitCaps 层与 PrimaryCaps 层之间的参数包含两类,即 W_ij 和 c_ij。所有 W_ij 的参数数量应该是 6×6×32×10×8×16=1474560,c_ij 的参数数量为 6×6×32×10×16=184320,此外还应该有 2×1152×10=23040 个偏置项参数,不过原论文并没有明确指出这些偏置项。最后小编计算出该三层 CapsNet 一共有 5537024 个参数,这并不包括后面的全连接重构网络参数。
损失函数与最优化
前面我们已经了解 DigitCaps 层输出向量的长度即某个类别的概率,那么我们该如何构建损失函数,并根据该损失函数迭代地更新整个网络?前面我们耦合系数 c_ij 是通过一致性 Routing 进行更新的,他并不需要根据损失函数更新,但整个网络其它的卷积参数和 Capsule 内的 W_ij 都需要根据损失函数进行更新。一般我们就可以对损失函数直接使用标准的反向传播更新这些参数,而在原论文中,作者采用了 SVM 中常用的 Margin loss,该损失函数的表达式为:

其中 c 是分类类别,T_c 为分类的指示函数(c 存在为 1,c 不存在为 0),m+ 为上边界,m- 为下边界。此外,v_c 的模即向量的 L2 距离。
因为实例化向量的长度来表示 Capsule 要表征的实体是否存在,所以当且仅当图片里出现属于类别 k 的手写数字时,我们希望类别 k 的最顶层 Capsule 的输出向量长度很大(在本论文 CapsNet 中为 DigitCaps 层的输出)。为了允许一张图里有多个数字,我们对每一个表征数字 k 的 Capsule 分别给出单独的 Margin loss。
构建完损失函数,我们就能愉快地使用反向传播了。
重构与表征
重构即我们希望利用预测的类别重新构建出该类别代表的实际图像,例如我们前面部分的模型预测出该图片属于一个类别,然后后面重构网络会将该预测的类别信息重新构建成一张图片。
前面我们假设过 Capsule 的向量可以表征一个实例,那么如果我们将一个向量投入到后面的重构网络中,它应该能重构出一个完整的图像。因此,Hinton 等人使用额外的重构损失(reconstruction loss)来促进 DigitCaps 层对输入数字图片进行编码。下图展示了整个重构网络的的架构:

我们在训练期间,除了特定的 Capsule 输出向量,我们需要蒙住其它所有的输出向量。然后,使用该输出向量重构手写数字图像。DigitCaps 层的输出向量被馈送至包含 3 个全连接层的解码器中,并以上图所示的方式构建。这一过程的损失函数通过计算 FC Sigmoid 层的输出像素点与原始图像像素点间的欧几里德距离而构建。Hinton 等人还按 0.0005 的比例缩小重构损失,以使它不会主导训练过程中的 Margin loss。
Capsule 输出向量的重构与表征除了能提升模型的准确度以外,还能提升模型的可解释性,因为我们能修正需要重构向量中的某个或某些分量而观察重构后的图像变化情况,这有助于我们理解 Capsule 层的输出结果。
以上就是本论文构建的 CapsNet 架构,当然 Hinton 还描述了很多试验结果与发现,感兴趣的读者可以查阅论文的后一部分。
CapsNet 的 TensorFlow 实现
以下定义构建 CapsNet 后面两层的方法。在 CapsNet 架构中,我们能访问该类中的对象和方法构建 PrimaryCaps 层和 DigitCaps 层。
#通过定义类和对象的方式定义Capssule层级
class CapsLayer(object):
''' Capsule layer 类别参数有:
Args:
input: 一个4维张量
num_outputs: 当前层的Capsule单元数量
vec_len: 一个Capsule输出向量的长度
layer_type: 选择'FC' 或 "CONV", 以确定是用全连接层还是卷积层
with_routing: 当前Capsule是否从较低层级中Routing而得出输出向量
Returns:
一个四维张量
'''
def __init__(self, num_outputs, vec_len, with_routing=True, layer_type='FC'):
self.num_outputs = num_outputs
self.vec_len = vec_len
self.with_routing = with_routing
self.layer_type = layer_type
def __call__(self, input, kernel_size=None, stride=None):
'''
当“Layer_type”选择的是“CONV”,我们将使用 'kernel_size' 和 'stride'
'''
# 开始构建卷积层
if self.layer_type == 'CONV':
self.kernel_size = kernel_size
self.stride = stride
# PrimaryCaps层没有Routing过程
if not self.with_routing:
# 卷积层为 PrimaryCaps 层(CapsNet第二层), 并将第一层卷积的输出张量作为输入。
# 输入张量的维度为: [batch_size, 20, 20, 256]
assert input.get_shape() == [batch_size, 20, 20, 256]
#从CapsNet输出向量的每一个分量开始执行卷积,每个分量上执行带32个卷积核的9×9标准卷积
capsules = []
for i in range(self.vec_len):
# 所有Capsule的一个分量,其维度为: [batch_size, 6, 6, 32],即6×6×1×32
with tf.variable_scope('ConvUnit_' + str(i)):
caps_i = tf.contrib.layers.conv2d(input, self.num_outputs,
self.kernel_size, self.stride,
padding="VALID")
# 将一般卷积的结果张量拉平,并为添加到列表中
caps_i = tf.reshape(caps_i, shape=(batch_size, -1, 1, 1))
capsules.append(caps_i)
# 为将卷积后张量各个分量合并为向量做准备
assert capsules[0].get_shape() == [batch_size, 1152, 1, 1]
# 合并为PrimaryCaps的输出张量,即6×6×32个长度为8的向量,合并后的维度为 [batch_size, 1152, 8, 1]
capsules = tf.concat(capsules, axis=2)
# 将每个Capsule 向量投入非线性函数squash进行缩放与激活
capsules = squash(capsules)
assert capsules.get_shape() == [batch_size, 1152, 8, 1]
return(capsules)
if self.layer_type == 'FC':
# DigitCaps 带有Routing过程
if self.with_routing:
# CapsNet 的第三层 DigitCaps 层是一个全连接网络
# 将输入张量重建为 [batch_size, 1152, 1, 8, 1]
self.input = tf.reshape(input, shape=(batch_size, -1, 1, input.shape[-2].value, 1))
with tf.variable_scope('routing'):
# 初始化b_IJ的值为零,且维度满足: [1, 1, num_caps_l, num_caps_l_plus_1, 1]
b_IJ = tf.constant(np.zeros([1, input.shape[1].value, self.num_outputs, 1, 1], dtype=np.float32))
# 使用定义的Routing过程计算权值更新与s_j
capsules = routing(self.input, b_IJ)
#将s_j投入 squeeze 函数以得出 DigitCaps 层的输出向量
capsules = tf.squeeze(capsules, axis=1)
return(capsules)
下面是整个 CapsNet 的架构与推断过程代码,我们需要从 MNIST 抽出图像并投入到以下定义的方法中,该批量的图像将先通过三层 CapsNet 网络输出 10 个类别向量,每个向量有 16 个元素,且每个类别向量的长度为输出图像是该类别的概率。随后,我们会将一个向量投入到重构网络中构建出该向量所代表的图像。
# 以下定义整个 CapsNet 的架构与正向传播过程
class CapsNet():
def __init__(self, is_training=True):
self.graph = tf.Graph()
with self.graph.as_default():
if is_training:
# 获取一个批量的训练数据
self.X, self.Y = get_batch_data()
self.build_arch()
self.loss()
# t_vars = tf.trainable_variables()
self.optimizer = tf.train.AdamOptimizer()
self.global_step = tf.Variable(0, name='global_step', trainable=False)
self.train_op = self.optimizer.minimize(self.total_loss, global_step=self.global_step) # var_list=t_vars)
else:
self.X = tf.placeholder(tf.float32,
shape=(batch_size, 28, 28, 1))
self.build_arch()
tf.logging.info('Seting up the main structure')
# CapsNet 类中的build_arch方法能构建整个网络的架构
def build_arch(self):
# 以下构建第一个常规卷积层
with tf.variable_scope('Conv1_layer'):
# 第一个卷积层的输出张量为: [batch_size, 20, 20, 256]
# 以下卷积输入图像X,采用256个9×9的卷积核,步幅为1,且不使用
conv1 = tf.contrib.layers.conv2d(self.X, num_outputs=256,
kernel_size=9, stride=1,
padding='VALID')
assert conv1.get_shape() == [batch_size, 20, 20, 256]
# 以下是原论文中PrimaryCaps层的构建过程,该层的输出维度为 [batch_size, 1152, 8, 1]
with tf.variable_scope('PrimaryCaps_layer'):
# 调用前面定义的CapLayer函数构建第二个卷积层,该过程相当于执行八次常规卷积,
# 然后将各对应位置的元素组合成一个长度为8的向量,这八次常规卷积都是采用32个9×9的卷积核、步幅为2
primaryCaps = CapsLayer(num_outputs=32, vec_len=8, with_routing=False, layer_type='CONV')
caps1 = primaryCaps(conv1, kernel_size=9, stride=2)
assert caps1.get_shape() == [batch_size, 1152, 8, 1]
# 以下构建 DigitCaps 层, 该层返回的张量维度为 [batch_size, 10, 16, 1]
with tf.variable_scope('DigitCaps_layer'):
# DigitCaps是最后一层,它返回对应10个类别的向量(每个有16个元素),该层的构建带有Routing过程
digitCaps = CapsLayer(num_outputs=10, vec_len=16, with_routing=True, layer_type='FC')
self.caps2 = digitCaps(caps1)
# 以下构建论文图2中的解码结构,即由16维向量重构出对应类别的整个图像
# 除了特定的 Capsule 输出向量,我们需要蒙住其它所有的输出向量
with tf.variable_scope('Masking'):
#mask_with_y是否用真实标签蒙住目标Capsule
mask_with_y=True
if mask_with_y:
self.masked_v = tf.matmul(tf.squeeze(self.caps2), tf.reshape(self.Y, (-1, 10, 1)), transpose_a=True)
self.v_length = tf.sqrt(tf.reduce_sum(tf.square(self.caps2), axis=2, keep_dims=True) + epsilon)
# 通过3个全连接层重构MNIST图像,这三个全连接层的神经元数分别为512、1024、784
# [batch_size, 1, 16, 1] => [batch_size, 16] => [batch_size, 512]
with tf.variable_scope('Decoder'):
vector_j = tf.reshape(self.masked_v, shape=(batch_size, -1))
fc1 = tf.contrib.layers.fully_connected(vector_j, num_outputs=512)
assert fc1.get_shape() == [batch_size, 512]
fc2 = tf.contrib.layers.fully_connected(fc1, num_outputs=1024)
assert fc2.get_shape() == [batch_size, 1024]
self.decoded = tf.contrib.layers.fully_connected(fc2, num_outputs=784, activation_fn=tf.sigmoid)
# 定义 CapsNet 的损失函数,损失函数一共分为衡量 CapsNet准确度的Margin loss
# 和衡量重构图像准确度的 Reconstruction loss
def loss(self):
# 以下先定义重构损失,因为DigitCaps的输出向量长度就为某类别的概率,因此可以借助计算向量长度计算损失
# [batch_size, 10, 1, 1]
# max_l = max(0, m_plus-||v_c||)^2
max_l = tf.square(tf.maximum(0., m_plus - self.v_length))
# max_r = max(0, ||v_c||-m_minus)^2
max_r = tf.square(tf.maximum(0., self.v_length - m_minus))
assert max_l.get_shape() == [batch_size, 10, 1, 1]
# 将当前的维度[batch_size, 10, 1, 1] 转换为10个数字类别的one-hot编码 [batch_size, 10]
max_l = tf.reshape(max_l, shape=(batch_size, -1))
max_r = tf.reshape(max_r, shape=(batch_size, -1))
# 计算 T_c: [batch_size, 10],其为分类的指示函数
# 若令T_c = Y,那么对应元素相乘就是有类别相同才会有非零输出值,T_c 和 Y 都为One-hot编码
T_c = self.Y
# [batch_size, 10], 对应元素相乘并构建最后的Margin loss 函数
L_c = T_c * max_l + lambda_val * (1 - T_c) * max_r
self.margin_loss = tf.reduce_mean(tf.reduce_sum(L_c, axis=1))
# 以下构建reconstruction loss函数
# 这一过程的损失函数通过计算FC Sigmoid层的输出像素点与原始图像像素点间的欧几里德距离而构建
orgin = tf.reshape(self.X, shape=(batch_size, -1))
squared = tf.square(self.decoded - orgin)
self.reconstruction_err = tf.reduce_mean(squared)
# 构建总损失函数,Hinton论文将reconstruction loss乘上0.0005
# 以使它不会主导训练过程中的Margin loss
self.total_loss = self.margin_loss + 0.0005 * self.reconstruction_err
# 以下输出TensorBoard
tf.summary.scalar('margin_loss', self.margin_loss)
tf.summary.scalar('reconstruction_loss', self.reconstruction_err)
tf.summary.scalar('total_loss', self.total_loss)
recon_img = tf.reshape(self.decoded, shape=(batch_size, 28, 28, 1))
tf.summary.image('reconstruction_img', recon_img)
self.merged_sum = tf.summary.merge_all()
以上是该网络的主体代码,更多代码请查看 naturomics 的 GitHub 地址,或机器之心的 GitHub 地址,我们上传的是带注释的代码,希望能帮助初学者更加理解 CapsNet 的过程与架构。以下是上面我们定义 CapsNet 的主体计算图,即 TensorFlow 中的静态计算图:
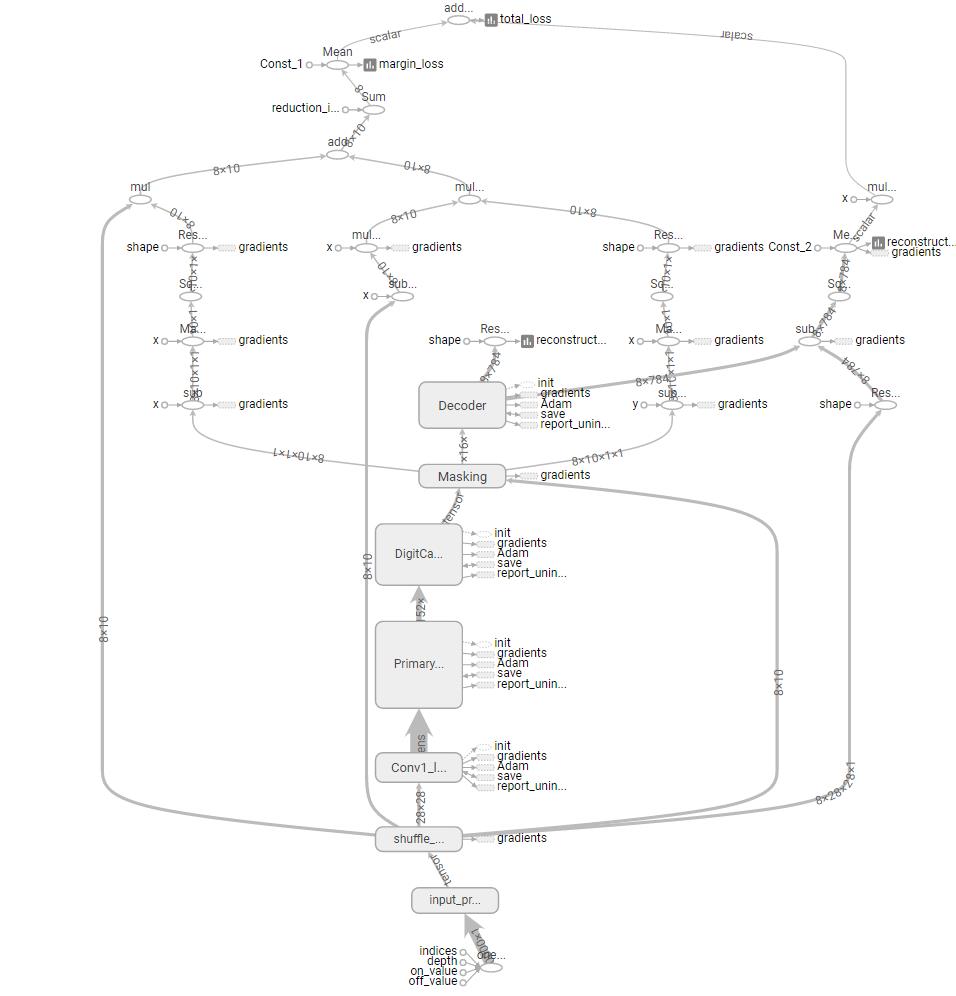
我们也迭代训练了大概 3 万多步,不过因为使用的是 CPU,所以我们将批量大小调整为 8 以减少单次迭代的计算压力,以下是我们训练时的损失情况,最上面是 Margin loss,下面还有重构损失和总损失:

最后放上两张由 DigitCaps 层输出向量重构出的对应图像:

我们只是初步地探索了 CapsNet,它还存在很多的可能性,例如它以向量的形式应该能获取非常多的图像信息,这种优势是否能在其它大型数据集或平面 3D 图像数据集中进一步展现出非凡的表征力?而且第二层 PrimaryCaps 的参数非常多,就像一组横向并联的卷积结构以产生向量(类似 Inception 模块,但要宽地多),我们是否能通过某种方式的共享进一步减少该层级的参数?还有当前 Routing 过程的效果至少在 MNIST 数据集中并不好,它仅仅只能展示存在这个概念,那么我们能否找到更加高效的 Routing 算法?此外,Capsule 是否能扩展到其他神经网络结构如循环或门控单元?这些可能都是我们存在的疑惑,但向前走,时间总会给我们答案的。
参考资料
- 原论文:Dynamic Routing Between Capsules, https://arxiv.org/abs/1710.09829
- 知乎讨论地址:https://www.zhihu.com/question/67287444/answer/251241736
- naturomics 实现地址(TensorFlow):https://github.com/naturomics/CapsNet-Tensorflow
- XifengGuo 实现地址(Keras):https://github.com/XifengGuo/CapsNet-Keras
- leftthomas 实现地址(Pytorch):https://github.com/leftthomas/CapsNet
以上是关于先读懂CapsNet架构然后用TensorFlow实现:全面解析Hinton的提出的Capsule的主要内容,如果未能解决你的问题,请参考以下文章