[机器学习与scikit-learn-46]:特征工程-特征选择(降维)-2-常见的特征降维的方法大全
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习与scikit-learn-46]:特征工程-特征选择(降维)-2-常见的特征降维的方法大全相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123953894
目录
2.1 按缺失比率删除特征(Missing Value Ratio)
2.3 高相关性滤波(High Correlation filter)
2.5 反向特征消除(Backward Feature Elimination)
前言:
降维是机器学习中一个高阶的技能,它属于特征工程范畴。
第1章 特征降维概述
1.1 机器学习在实际工作中遇到的难题--维度爆炸
在算法学习中,特征的数量都比较少,大多数都在是个特征以内,做多也就几十个。
但如果样本的特征得到成千上万个特征怎么办,甚至几十万、上百万?机器学习的算法的还那么高效吗?
比如文本处理中,每个单词就是一个维度的特征,但文本单词的种类高达几十万怎么办?
我们总是期望能够收到更多维度的数据,然后随着数据维度的增加,我们会进入一种悖论:维度越多,我们越不知道如何选择!!!
理论上,如果把描述宇宙的所有维度数据都能够获得,就可以描述整个宇宙的未来的状态。然后,实际上是,如果真能获取到整个宇宙维度的数据,你反而不知道如何处理了!数据的维度多到你无从选择。
怎么办???
降维!!!
1.2 降维的原因
样本所包含的特征过多,过于庞大,导致计算量暴增。
而部分特征的特征性和区分性很小,这些特征对最终的结果其实影响很小。
1.3 特征降维的目的
去除掉矛盾中的次要方面和次要因素(特征),保留主要方面和主要特征。
提升计算和决策的速度和效率。
1.4 什么是特征降维
所谓特征降维,就是较少、降低特征的维度。
简单的说,对所有的特征,该合并的合并,该去掉的去掉,
1.5 降维的好处和优点
(1)降低存储空间
随着数据维度不断降低,数据存储所需的空间也会随之减少。
(2)降低训练时间
低维数据有助于减少计算/训练用时。
(3)提升算法的可用性
一些算法在高维度数据上容易表现不佳,降维可提高算法可用性。
(4)解决共线性问题:
所谓共线性:就是两个特征,有强相关性,并且具备相同的线性趋势。
降维可以用删除冗余特征解决多重共线性问题。
比如我们有两个变量:“一段时间内在跑步机上的耗时”和“卡路里消耗量”。这两个变量高度相关,在跑步机上花的时间越长,燃烧的卡路里自然就越多。
因此,同时存储这两个数据意义不大,只需一个就够了。
(5)利于数据可视化
降维有助于数据可视化。如果数据维度很高,可视化会变得相当困难,而绘制二维三维数据的图表非常简单。
1.6 降维的缺点
(1)部分特征信息可能会丢失
(2)可能会导致线性可分变成线性不可分
1.7 降维的主要手段与对应的原则
(1)特征选择:从众多特征中选择部分特征
- 不能损失主要矛盾和矛盾的主要方面(主要特征)=》
- 根据业务需要选择不同的特征,不同的业务场景关注的特征是不一样的。
特征选择就是滤波,滤除掉一些特征。
(2)特征合并:把多个特征合并成同一个特征
- 正相关的特征进行合并
- 负相关的特征进行分离
- 无关性的特征进行归类
1.8 特征降维的优化
(1)分层训练和分层决策:L1 主要特征 =》L2 中等特征 =》 L3 次要特征
第2章 常见的降维方法简介
2.1 按缺失比率删除特征(Missing Value Ratio)
(1)概述
假设你有一个数据集,你第一步会做什么?
在构建模型前,对数据进行探索性分析必不可少。
但在浏览数据的过程中,有时候我们会发现其中包含不少缺失值。如果缺失值少,我们可以填补缺失值或直接删除这个变量;如果缺失值过多,你会怎么办呢?
当缺失值在数据集中的占比过高时,一般我会选择直接删除这个变量,因为它包含的信息太少了。但具体删不删、怎么删需要视情况而定,我们可以设置一个阈值,如果缺失值占比高于阈值,删除它所在的列。阈值越低,该维度由于数据缺失被删除掉的可能性越大。
(2)代码演示
df.isnull()
df.isnull().any()
df.isnull().sum()2.2 低方差滤波(Low Variance Filter)
(1)概述
如果某一特征,对所有样本,其取值都差不多,这说明,所有的样本,并不是通过该特征来标识差别的,这样的特征,其实对于区分不同样本,意义不大,就可以去除掉这些特征。
如何用数学表达上述特性呢?低方差!!!
放到实践中,就是先计算所有特征的方差大小,然后删去其中最小的几个。
需要注意的一点是:
方差与数据范围相关的,因此在采用该方法前需要对数据做归一化处理,这样不同特征的方差之间才具备可比性!!!!
(2)方差函数
numeric.var()2.3 高相关性滤波(High Correlation filter)
(1)概述
如果两个特征之间是高度相关的,这意味着它们具有相似的趋势并且可能携带类似的信息。
同理,这类变量的存在会降低某些模型的性能(例如线性和逻辑回归模型)。
为了解决这个问题,我们可以计算独立数值变量之间的相关性。
如果相关系数超过某个阈值,就删除其中一个变量。
通常情况下,如果一对变量之间的相关性大于0.5,那就应该考虑是否要删除一列属性了。
(2)相关性系数计算
首先,删除因变量(Item_Outlet_Sales),并将剩余的变量保存在新的数据列(df)中。
然后通过corr()函数求特征(变量)之间的相关性
df=train.drop('Item_Outlet_Sales', 1)
df.corr()2.4 随机森林(Random Forest)
(1)概述
随机森林是一种广泛使用的分类算法,它会自动计算各个特征的重要性,具备天然的特征选择的能力,从功能上看,无需单独编程,但从效率上看,还是在运行算法之间,先去除掉不重要的特征。
随机深林算法,自动优选选择差异性较大的特征,合并差异性较小的特征。
另一种有意思的应用就是:
- 确定随机深林的深度
- 利用随机深林进行分类
- 对影响随机深林决策的特征进行排序
- 选择出对随机深林决策算法影响Top N的几个特征。
- 去除掉对决策深林做决策无影响或影响较小的特征。
这就是随机森林算法对特征选择的奇特作用!
features = df.columns
importances = model.feature_importances_
indices = np.argsort(importances[0:9]) # top 10 features
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()
2.5 反向特征消除(Backward Feature Elimination)
(1)概述
反向特征消除的基本思想是:尝试性删除某些特征,然后对模型进行训练,再看删除后该特征后,对模型性能的影响,选择删除对模型影响小的特性!!!
反向特征消除的主要步骤:
- 先获取数据集中的全部n个变量,然后用它们训练一个模型。
- 计算模型的性能。
- 删除每个变量(n次)后计算模型的性能,即我们每次都去掉一个变量,用剩余的n-1个变量训练模型。
- 确定对模型性能影响最小的变量,把它删除。
- 重复此过程,直到不再能删除任何变量。
这种方法,其实是比较原始的,采用的是暴力穷举。
2.6 前向特征选择(Forward Feature Selection)
前向特征选择其实就是反向特征消除的相反过程,即找到能改善模型性能的最佳特征,而不是删除弱影响特征。
它背后的思路如下所述:
- 选择一个特征,用每个特征训练模型n次,得到n个模型。
- 选择模型性能最佳的变量作为初始变量。
- 每次添加一个变量继续训练,重复上一过程,最后保留性能提升最大的变量。
- 一直添加,一直筛选,直到模型性能不再有明显提高。
2.7 因子分析FA(Factor Analysis)
因子分析是一种常见的统计方法,它能从多个变量(特征)中提取共性因子,并得到最优解。
假设我们有两个变量:收入和教育。它们可能是高度相关的,因为总体来看,学历高的人一般收入也更高,反之亦然。所以它们可能存在一个潜在的共性因子,比如“能力”。
在因子分析中,我们将变量按其相关性分组,即特定组内所有变量的相关性较高,组间变量的相关性较低。我们把每个组称为一个因子,它是多个变量的组合。
和原始数据集的变量相比,这些因子在数量上更少,但携带的信息基本一致。
这种分析方法,就是人类的分类方法。进一步可以采用分层判决的方法。
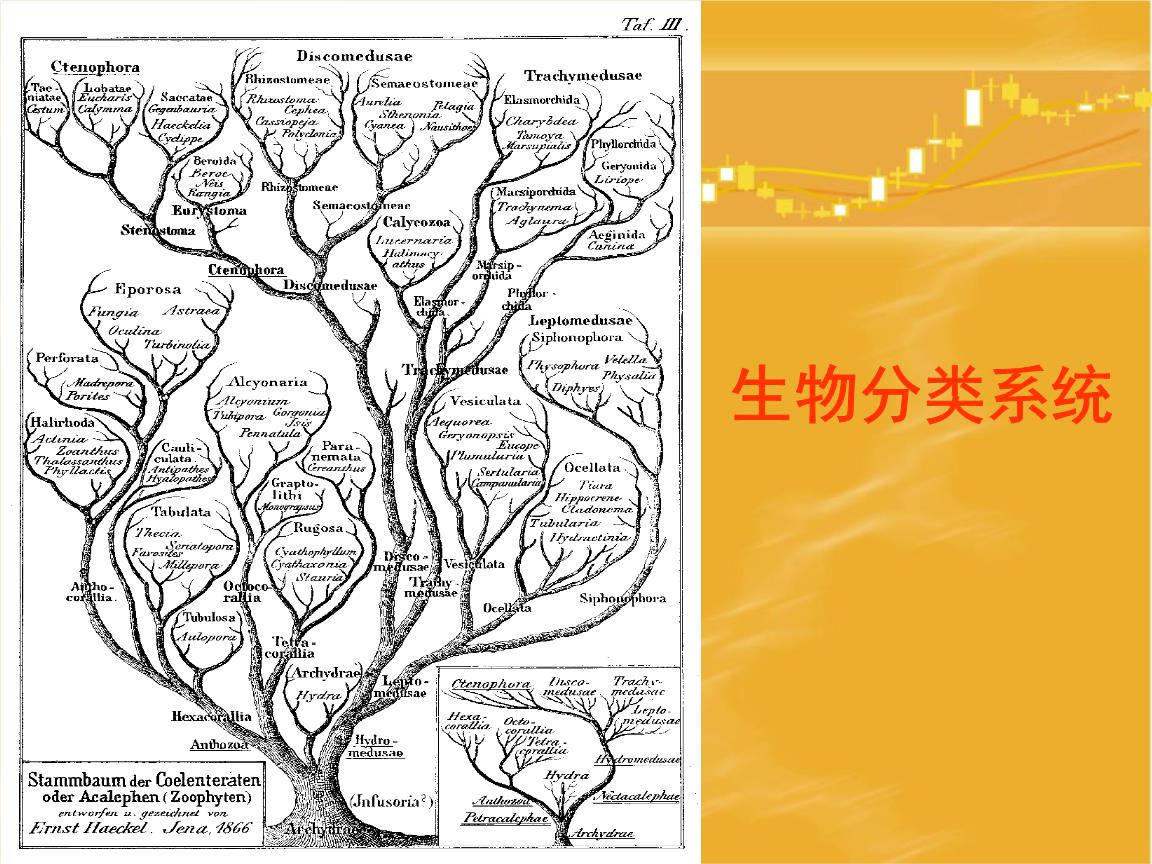
把所有的特征,按照树形的方式进行组织。具备相同类型的特征归属于同一个分类。
这样,把偏平的特征,构建成了一个分层的、结构化的特征。
在进行分类时,可以为不同层次的特征,指定不同的权重,优先在第层次的特征之间进行区分和比较,然后再高一层次的特征上进行进一步的比较。
2. 8 主成分分析(PCA)
该方法的基本思想是辩证唯物主义的思想:找到主要矛盾和主要矛盾的主要方面。
这是一个非常常用的特征提取的方法。
如果说因子分析是假设存在一系列潜在因子,能反映变量携带的信息,那PCA就是通过正交变换将原始的n维数据集变换到一个新的被称做主成分的数据集中,即从现有的大量变量中提取一组新的变量。
下面是关于PCA的一些要点:
- 主成分是原始变量的线性组合。
- 第一个主成分具有最大的方差值。
- 第二主成分试图解释数据集中的剩余方差,并且与第一主成分不相关(正交)。
- 第三主成分试图解释前两个主成分等没有解释的方差。
即一次找出方差最大的特征,且他们对结果影响最大。
主成分分析实际上是一种浓缩数据信息的方法,可将很多个指标浓缩成综合指标(主成分),并保证这些综合指标彼此之间互不相关。可用于简化数据信息浓缩、计算权重、竞争力评价等。
2.9 独立分量分析(ICA)
独立分量分析(ICA)基于信息理论,是最广泛使用的降维技术之一。
PCA和ICA之间的主要区别在于,PCA寻找不相关的因素,而ICA寻找独立因素。
独立分量分析(independent component analysis,ICA)原本是20世纪90年代发展起来的一种新的信号处理技术。基本的ICA是指从多个源信号的线性混合信号中分离出源信号的技术。
应用在特征的降维上,就是要分离多个不相干的特征信号(数据),并把相干数据合并在一起。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123953894
以上是关于[机器学习与scikit-learn-46]:特征工程-特征选择(降维)-2-常见的特征降维的方法大全的主要内容,如果未能解决你的问题,请参考以下文章