Elasticsearch 分布式搜索引擎 -- RestClient操作文档
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 分布式搜索引擎 -- RestClient操作文档相关的知识,希望对你有一定的参考价值。
文章目录
1. RestClient操作文档
为了与索引库操作分离,我们再次参加一个测试类,做两件事情:
- 初始化RestHighLevelClient
- 我们的酒店数据在数据库,需要利用IHotelService去查询,所以注入这个接口
HotelDocumentTest.java
package cn.itcast.hotel;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class HotelDocumentTest
private RestHighLevelClient client;
@Autowired
private IHotelService hotelService;
@BeforeEach
void setUp()
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.135.130:9200")
));
@AfterEach
void tearDown() throws IOException
client.close();
说明:
1.1 根据id新增文档

我们要将数据库的酒店数据查询出来,写入elasticsearch中。
代码整体步骤如下:
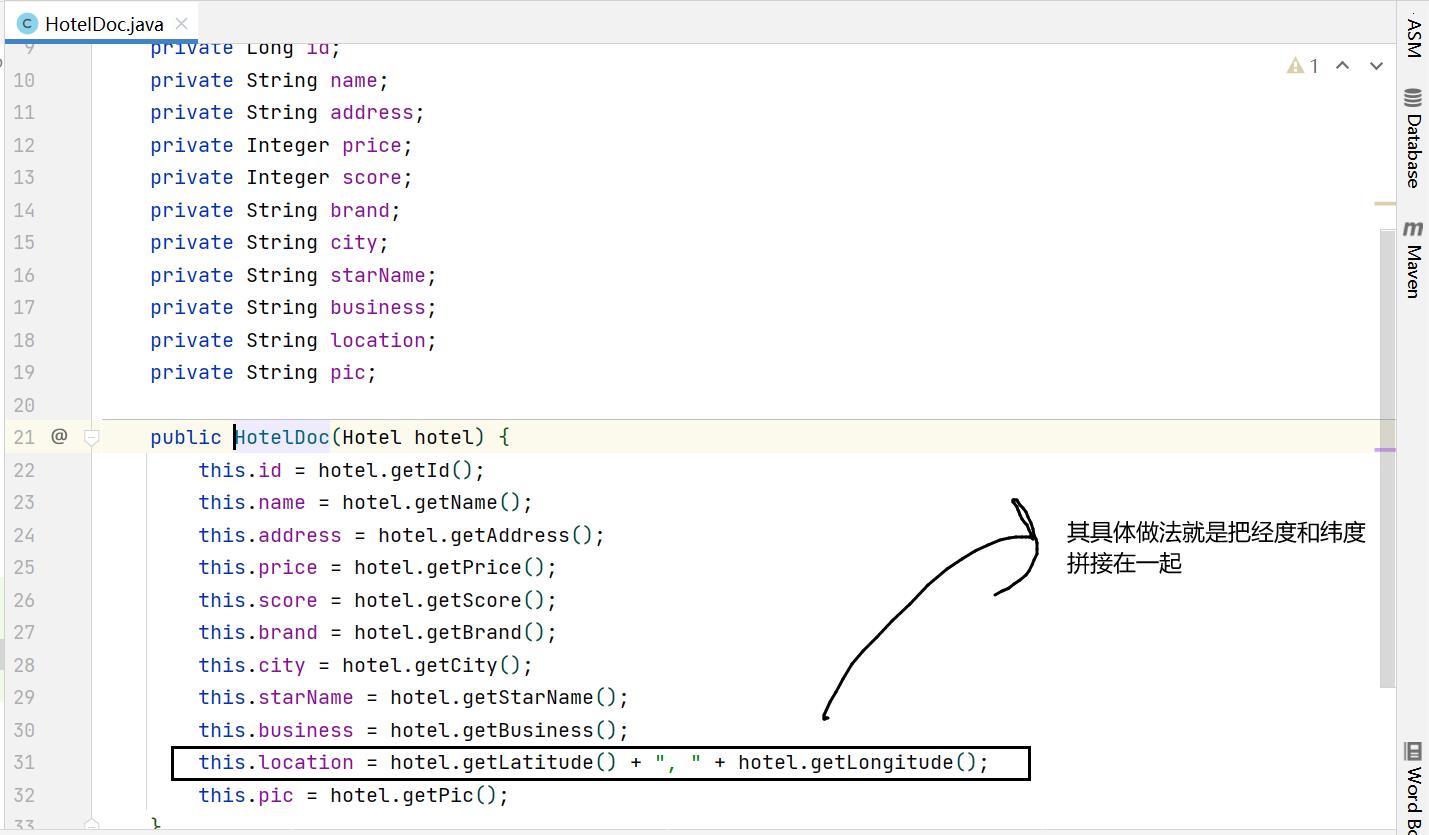
- 1)根据id查询酒店数据Hotel
- 2)将Hotel封装为HotelDoc
- 3)将HotelDoc序列化为JSON
- 4)创建IndexRequest,指定索引库名和id
- 5)准备请求参数,也就是JSON文档
- 6)发送请求
在测试类新增一个方法:这里是用的 com.alibaba.fastjson.JSON
@Test
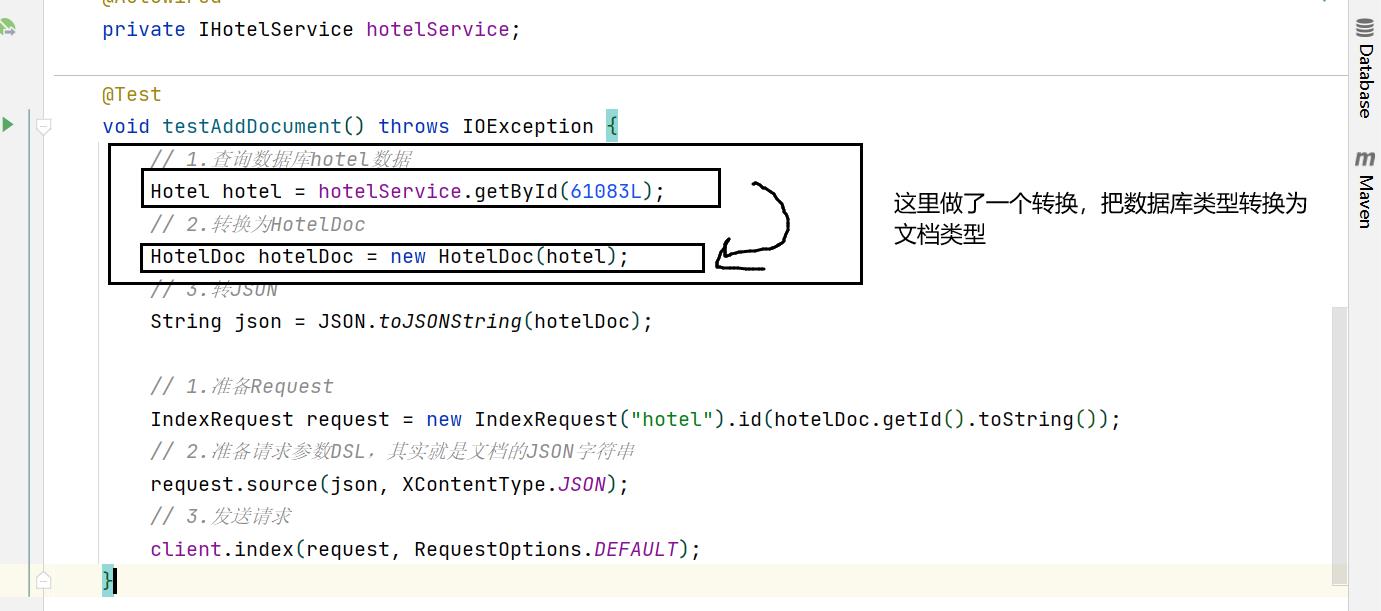
void testAddDocument() throws IOException
// 1.查询数据库hotel数据
Hotel hotel = hotelService.getById(61083L);
// 2.转换为HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.转JSON
String json = JSON.toJSONString(hotelDoc);
// 1.准备Request
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.准备请求参数DSL,其实就是文档的JSON字符串
request.source(json, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
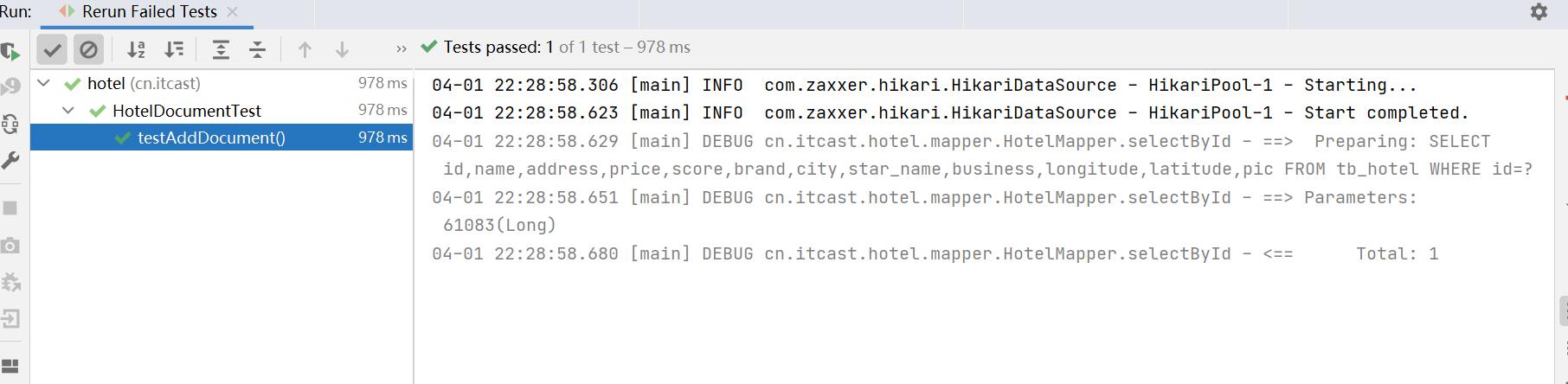
运行结果:
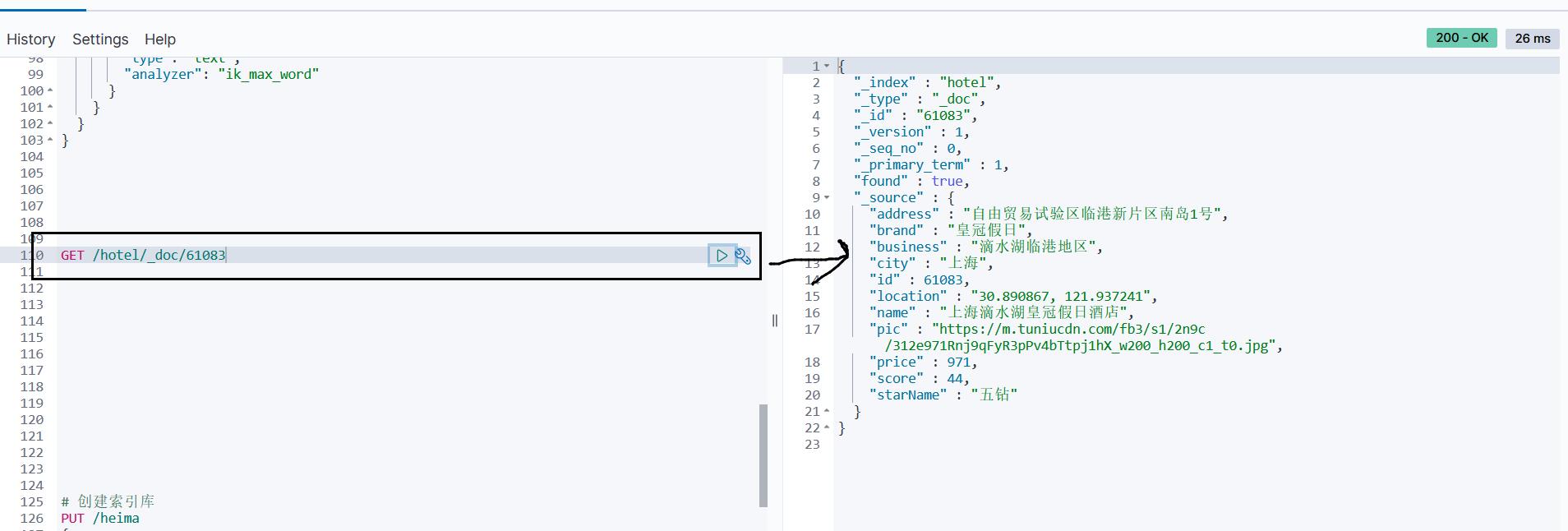
1.2 根据id查询酒店数据
查询的DSL语句如下:
GET /hotel/_doc/id
非常简单,因此代码大概分两步:
- 准备Request对象
- 发送请求
不过查询的目的是得到结果,解析为HotelDoc,因此难点是结果的解析。完整代码如下:

可以看到,结果是一个JSON,其中文档放在一个_source属性中,因此解析就是拿到_source,反序列化为Java对象即可。
与之前类似,也是三步走:
- 1)准备Request对象。这次是查询,所以是GetRequest
- 2)发送请求,得到结果。因为是查询,这里调用client.get()方法
- 3)解析结果,就是对JSON做反序列化
在测试类新增一个方法:
@Test
void testGetDocumentById() throws IOException
// 1.准备Request
GetRequest request = new GetRequest("hotel", "61083");
// 2.发送请求,得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析响应结果
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
运行结果:

1.3 根据id修改文档
修改我们讲过两种方式:
- 全量修改:本质是先根据id删除,再新增
- 增量修改:修改文档中的指定字段值
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
- 如果新增时,ID已经存在,则修改
- 如果新增时,ID不存在,则新增
这里不再赘述,我们主要关注增量修改。
代码示例如图:
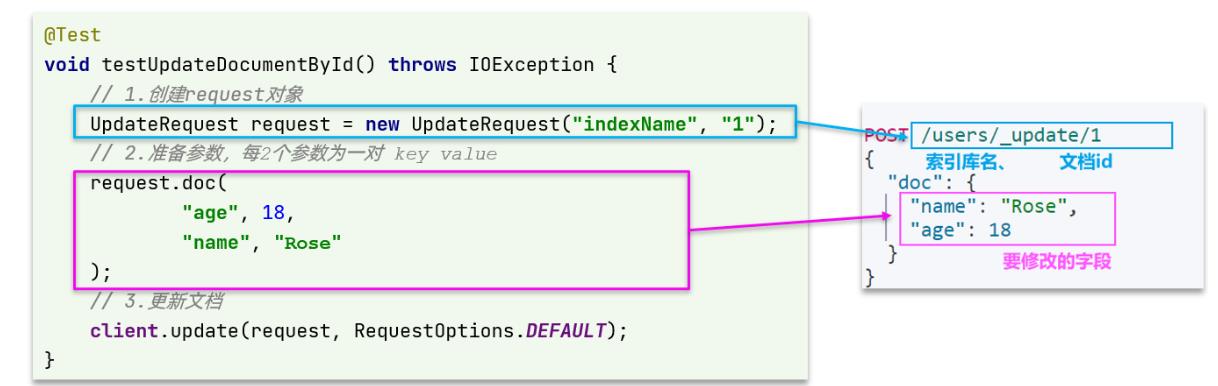
与之前类似,也是三步走:
- 1)准备Request对象。这次是修改,所以是UpdateRequest
- 2)准备参数。也就是JSON文档,里面包含要修改的字段
- 3)更新文档。这里调用client.update()方法
在测试类新增一个方法:
@Test
void testUpdateDocument() throws IOException
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.准备请求参数
request.doc(
"price", "952",
"starName", "四钻"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
运行结果:


1.4 根据id删除文档
删除的DSL为是这样的:
DELETE /hotel/_doc/id
与查询相比,仅仅是请求方式从DELETE变成GET,可以想象Java代码应该依然是三步走:
- 1)准备Request对象,因为是删除,这次是DeleteRequest对象。要指定索引库名和id
- 2)准备参数,无参
- 3)发送请求。因为是删除,所以是client.delete()方法
在测试类新增一个方法:
@Test
void testDeleteDocument() throws IOException
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
运行结果:

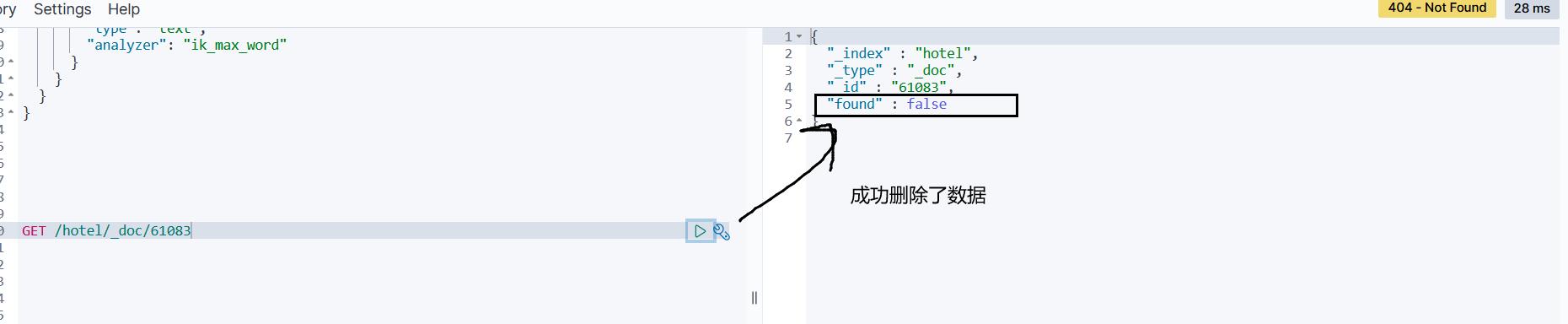
1.5 批量导入文档
案例需求:利用BulkRequest批量将数据库数据导入到索引库中。
步骤如下:
-
利用mybatis-plus查询酒店数据
-
将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
-
利用JavaRestClient中的BulkRequest批处理,实现批量新增文档
批量处理BulkRequest,其本质就是将多个普通的CRUD请求组合在一起发送。
其中提供了一个add方法,用来添加其他请求:
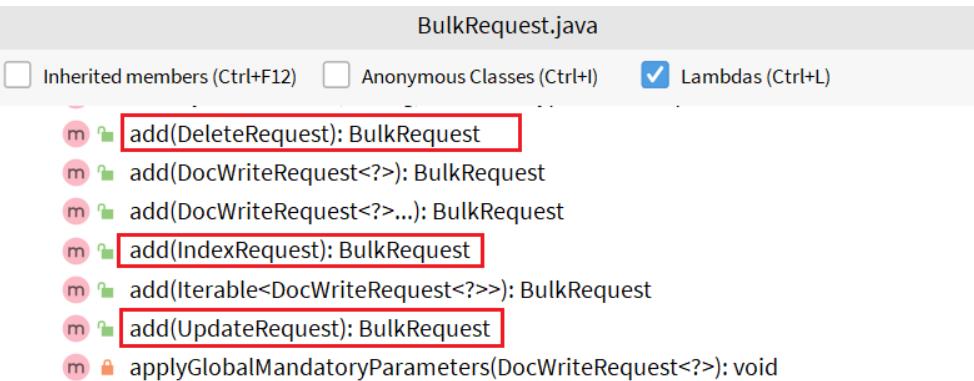
可以看到,能添加的请求包括:
- IndexRequest,也就是新增
- UpdateRequest,也就是修改
- DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。示例:
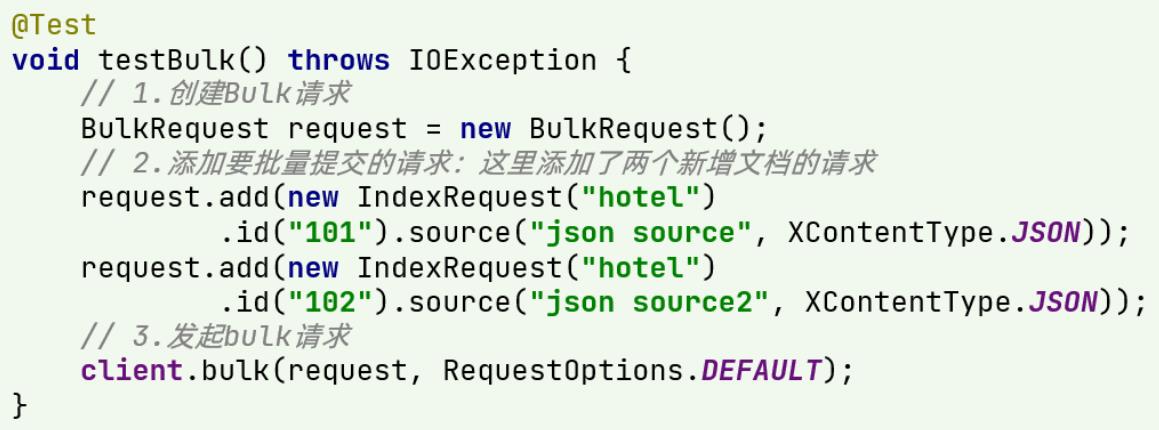
其实还是三步走:
- 1)创建Request对象。这里是BulkRequest
- 2)准备参数。批处理的参数,就是其它Request对象,这里就是多个IndexRequest
- 3)发起请求。这里是批处理,调用的方法为client.bulk()方法
我们在导入酒店数据时,将上述代码改造成for循环处理即可。
在测试类新增一个方法:
@Test
void testBulkRequest() throws IOException
// 批量查询酒店数据
List<Hotel> hotels = hotelService.list();
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Hotel hotel : hotels)
// 2.1.转换为文档类型HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
运行结果:

以上是关于Elasticsearch 分布式搜索引擎 -- RestClient操作文档的主要内容,如果未能解决你的问题,请参考以下文章