啊哈~花一天快速上手Pytorch(可能是全网最全流程从0到部署)
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了啊哈~花一天快速上手Pytorch(可能是全网最全流程从0到部署)相关的知识,希望对你有一定的参考价值。
文章目录
前言
刚好有空顺便整理一下以前学习pytorch的笔记,做一个梳理,便于后面的学习~
在学习pytorch之前,建议可以先掌握numpy,本质上来说,最早的版本来说,pytorch其实是numpy的增强,让矩阵可以在GPU里面运行,之后具备自动求导的特性,也就是咱们的梯度,学过线性回归的朋友应该知道,我们是通过损失函数来计算修正我们的未知参数的,那么在这里手算的话我们就需要求导,那么在pytorch里面肯定不是直接求导,而是通过记录变化值,也就是通过当前参数的变化值来进行反向修改。那么这个东西就叫做梯度,可以正向传播,也可以反向传播。
之后就是pytorch官方给咱们提供的一些API,例如自制数据集,常用神经网络,CNN 卷积核等。
环境
这里注意一下,我的环境是Windows10,N卡,装的pytorch版本是GPU版本,CUDA驱动版本是10.1(10.2也是一样的)

可以看到,我这边的显卡是GTX1650
没有显卡的朋友不要慌,我们可以使用谷歌实验室,当然你得会那啥。免费,一个礼拜30个小时的使用时长,代码你可以在本地写好,然后改成GPU版本,放到实验平台先跑一下,能过,然后在完整地训练一下。

Tensor初识
tensor 与 numpy
在我们的pytorch包括TensorFlow里面经常会出现Tensor这个词,这个其实就是它的基本数据结构,这个玩意其实和我们的numpy的那个结构是一样的,其实就是那个结构,只是他现在叫Tensor,区别就是在我们的深度学习框架里面这个Tensor可以做GPU加速!你们可以先感受一下

所以其实tensor的一些操作(除了CURD)基本上和numpy其实差不多,而numpy又具备了很多list的特性,所以tensor也一样
所以python就是老流氓嘛,用python写算法直接开挂。
在flink里面我想用元组,我还得调用scale封装的API Tuple,python直接一个小括号搞定,直接耍流氓。
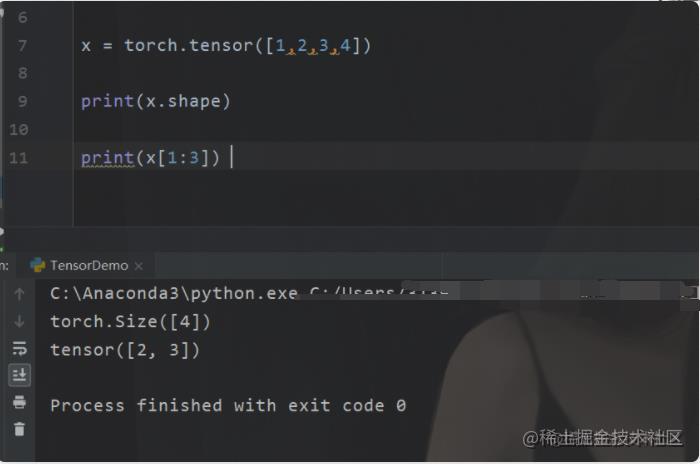
当然回到主题,我们说tensor还能够在GPU里面运行,那我们来看看例子。
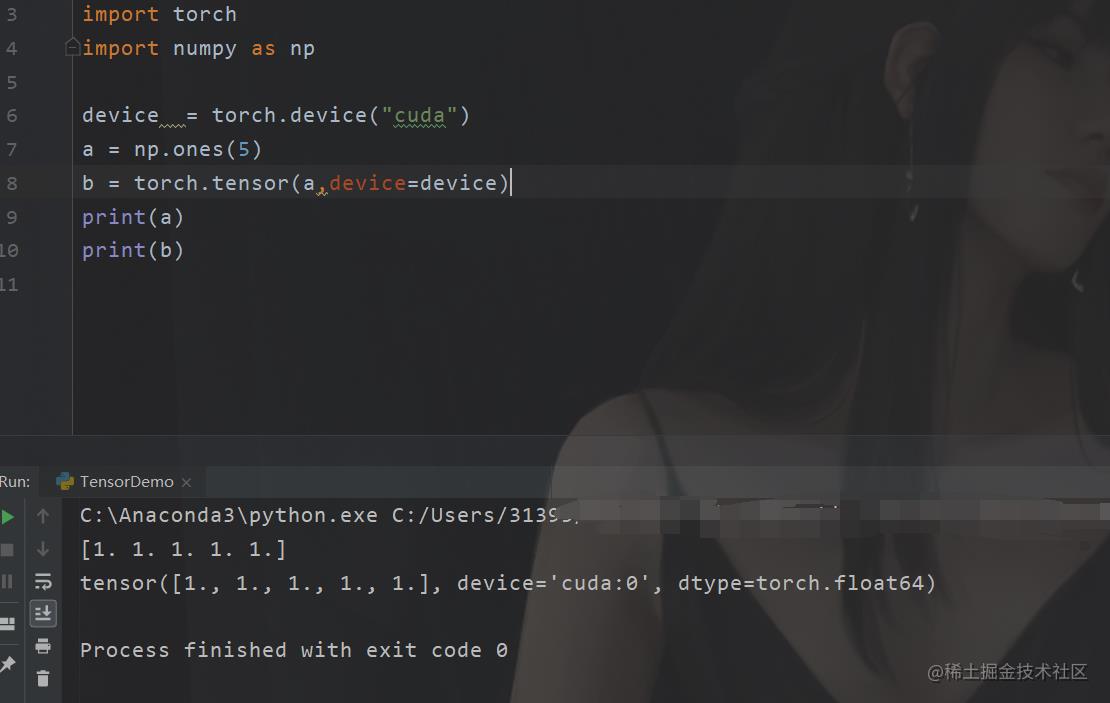
现在我们的代码就已经在我们的GPU里面了。那么除此之外还有什么差别嘛,有的。梯度
这个梯度 就是我们高数里面的内容。Pytorch可以自动求导,主要是在神经网络里面需要反向传播嘛。(好吧不太理解神经网络的话,这个确实不好理解,我前面也有博文提到了这个,应该是算是说的比较明白了,也是在本专栏)
tensor 使用
基本使用
这部分内容不多,也不复杂,很多和numpy类似,具体的可以查看这篇文章
我这里主要说说,不一样的细节。
numpy与tensor转换
我们的numpy和tensor是可以相互转换的。
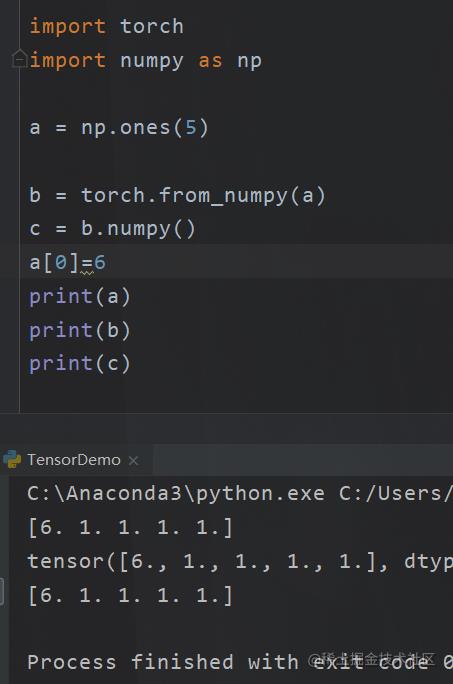
但是注意两点,第一
只有都在CPU上的才能相互转换
第二点
直接使用from_numpy的是指向了同一个地址
如果想创建新的
b = torch.tensor(a)

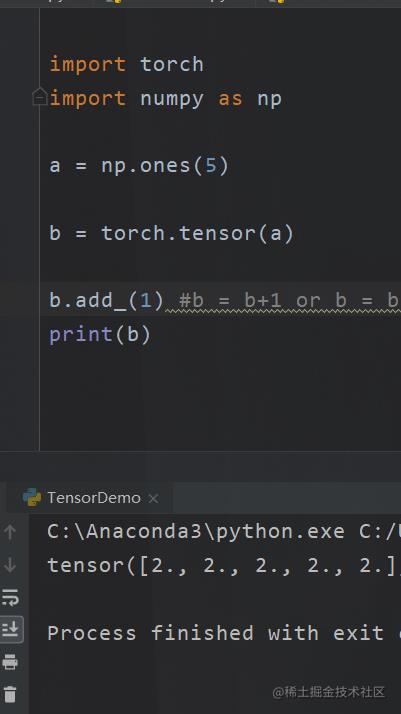
有“_”尾巴的函数
在pytorch当中你会见到很多这样的类型的函数add_()
最后面有个“_“
这个函数的意思是说,把处理后的值进行覆盖。例如
梯度
梯度使用
这个是tensor里面很重要的东西之一。
顾名思义就是求梯度,先来一个例子你们就明白了。
import torch
a = torch.tensor([[1,1,4,4],[4,4,4,4]],requires_grad=True,dtype=torch.float) #初始化的tensor a
b = a**2 # 等价与 x ^2
c = b.sum() # 求和
print(c)
c.backward() # 反向传递(相当于求导)
print(a.grad) #结果,指的是有 a 到 c 的变化的梯度

这个我其实可以解释一下,看好了
首先是 a 我们把a想象成一个函数
A(x) = [X1,X2,4*(X3),4*(X4)],[...]
现在我们乘以^2
于是就变成了
A^2(x) = [X1^2,X2^2,4*(X3^2)...]
后面我们求和
于是又变成了
Sum(A^2) = [X1^2+X2^2+4*(X3^2) ...])
对这个函数求偏导,然后再还原成矩阵的样子,不就是

这里开始注意一个细节,那就是,我们是a – >c的过程的反向传播,也就是a --> c的梯度,a 是我们的根节点,只有a才会有我们的梯度。其实你可以这样理解,b其实是a的引用,由于a的变化才会产生梯度。
不然你可以看看b 的梯度。
之所以要说这个是因为一方面是我们的后面要用,还有一方面是我们关于 tensor的复制
取消梯度
有时候我们不想要那个梯度,因为这个Tensor可能只是一个普通变量。
于是你就可以直接使用 detach()来取消梯度。很多别的博客也说这个是个复制的函数,但是这个我认为是不准确的,因为这个玩意
其实只是取消了梯度,两者的内存指向还是一样的。不过比较特殊的是,例如 b = a.detach() 此时b是a的地址引用,在使用b的时候是没有梯度的,但是使用a的时候本身还是有梯度的,所以严格意义上来说并不是复制。
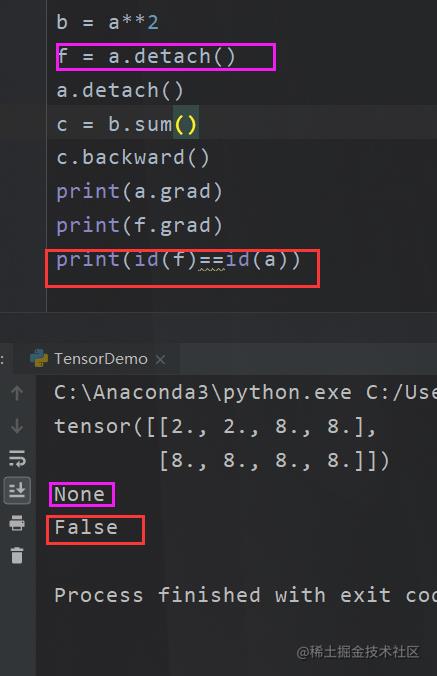
当你声明detach()的时候就不会有了,此外
import torch
import numpy as np
a = torch.tensor([[1,1,4,4],[4,4,4,4]],requires_grad=True,dtype=torch.float)
a.requires_grad_(False) # 等价 torch.tensor(数据,requires_grad=True)
a.detach()
b = a**2
f = a.detach()
a.detach()
c = b.sum()

直接不让,也行,或者
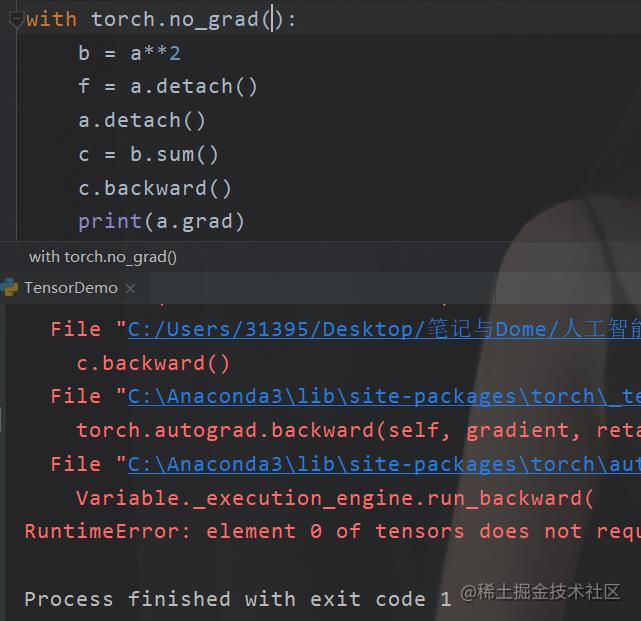
复制tensor
之所以要先说梯度,原因是一方面要用,还有一方面是复制的时候要注意,还记得深度拷贝嘛,假设我们要用的话.
首先我们想要克隆或者深度拷贝,一个玩意。我们注意,前面我们不是说只要叶子节点最后才能拿到梯度吗。我们想要拷贝使用clone() 或者 copy_() 都类似(前者常用)

所以有时候为了拿到梯度,让两个变量彻底无关,所以我们要
>>> a = torch.tensor(1.0, requires_grad=True)
>>> b = a.clone().detach()
数据加载与转换
通过前面的一些介绍的话,我们大概知道了我们的pytorch的tensor的一些基本概念,还有咱们梯度和tensor复制时的一些细节,tensor和numpy在很大程度上很像,在某些场合我们甚至可以直接使用tensor来进行运算。那么现在我们来说说pytorch的一些基本使用。
毕竟我们使用pytorch是用来搭建我们的神经网络,进行深度学习的。那么在机器学习小概述里面说过,深度学习其实也是我们机器学习的一种分支,也就是特殊一点的机器学习。那么先前sklearn的机器学习和aruze的云平台的机器学习步骤大致分为了五部曲,那么在pytorch里面其实也是类似,只是算法部分换成了比较抽象的神经网络。
所以我们可以把pytorch大致分为这几块
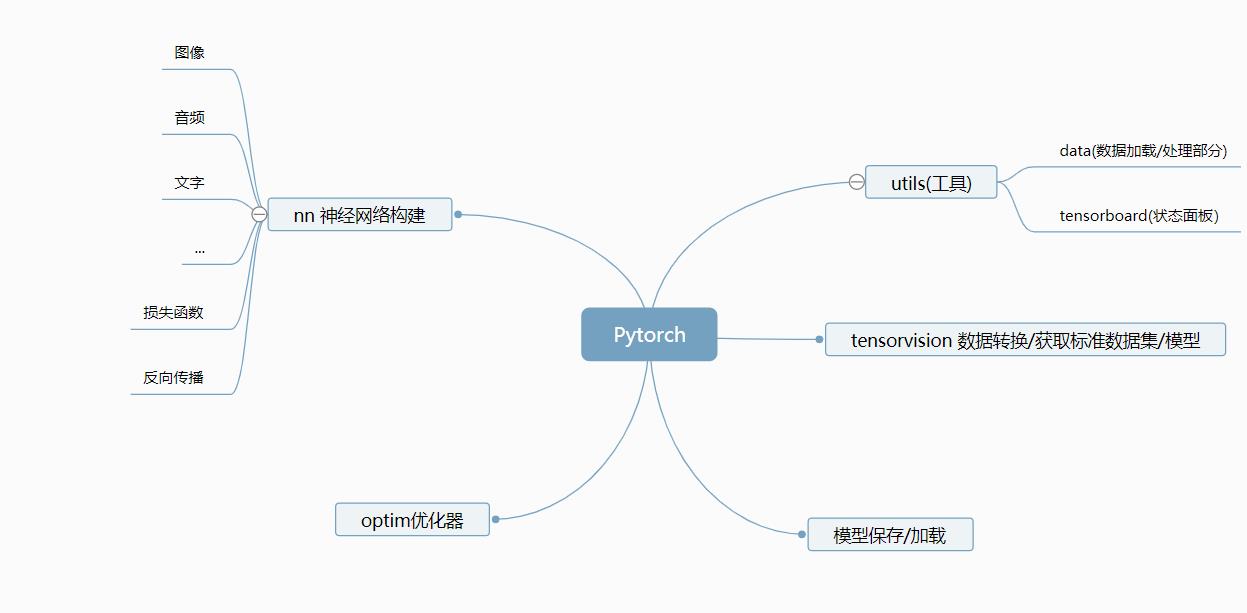
那么在这里主要将的是数据的加载,与转换。
类型转换
一开始我们说了,tensor可以将numpy的数据进行转换,但是有时候我们需要处理的可能是文本,或者图片,声音。所以我们需要一个转换器(当然你也可以转成numpy然后再转换为tensor但是那闲的慌才那么干)
这里使用工具包
tensorvision
例如我们对图片进行转换。
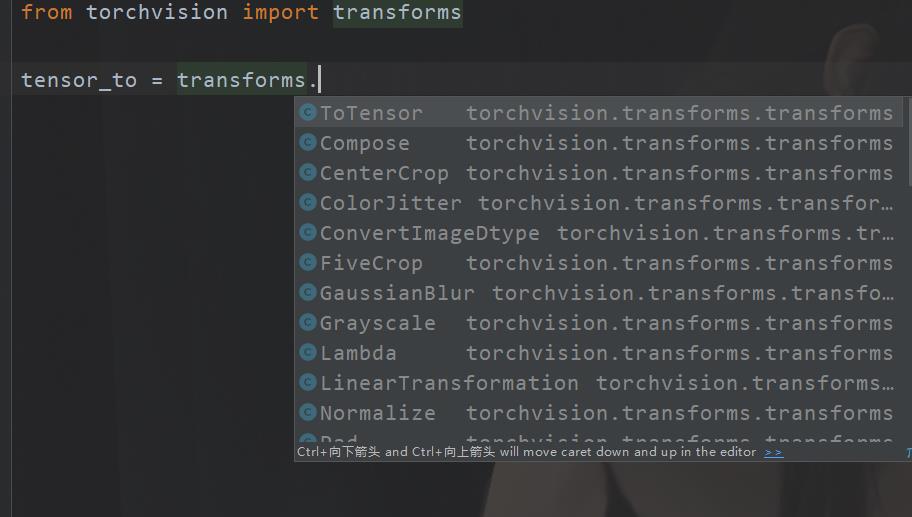
我们发现这工具包下面还有很多内容,Totensor()可以直接进行转换(看见源码还有说明)

在这里我们就轻松完成了转化。
Compose “链式转化”
有时候我们可能需要进行多次转化,例如我们需要对一个图片先改变尺寸,然后进行转化。那么这个时候为了避免重复代码,所以此时我们还能这样做。
from torchvision import transforms
tensor_to = transforms.ToTensor()
compose = transforms.Compose([tensor_to,])
image = Image.open("train/1/0BGHNV6P.jpg")
img = compose(image)
print(img)
那么这里还有其他的方式,我就不说了,你pycharm一点都出来了,还有注释。
类型转换的话其实很简单,而且对应的情况也比较多,我这边真不好说明。
数据处理
我们都知道,机器学习其实都离不开数据,数据集。那么对于一些比较出名的网络模型,或者是数据集,在pytorch里面都提供了自动下载的工具。
自带数据集
这个是指pytorch会自动通过爬虫来下载数据集合,然后给我们封装好。
这个也是使用tenssorvision
例如下载CIFAR10数据集
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
tese_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
直接搞的,但是注意的是,这里得到的数据集不是tensor类型的,我们还要进行类型转换
from torchvision import transforms
trans = transforms.Compose([transforms.ToTensor()])
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=trans,download=True)
数据加载
之后就是我们的数据加载
这里的话使用的就是utils下面的工具了
from torch.utils.data import DataLoader
from torchvision import transforms
trans = transforms.Compose([transforms.ToTensor()])
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=trans,download=True)
dataloader = DataLoader(dataset,batch_size=64)
这里主要介绍一些DataLoader的参数。

自定义获取数据
这个的话就比较原始,就是有时候我们需要自己加载数据集,举个例子。

这个就是从网上下载的数据集,现在要把这个导入到我们的pytorch里面。
这个文件夹是标签名,在这个数据集里面。1 是 1块钱的图片 100是一百块钱的图片。
我这里先直接给出代码
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
import os
from PIL import Image
# 通过Dataset来获取数据
class MyDataset(Dataset):
def __init__(self,RootDir,LabelDir):
self.RootDir = RootDir
self.LabelDir = LabelDir
self.transform = transforms.ToTensor()
self.ImagePathDir = os.path.join(self.RootDir,self.LabelDir)
self.ImageNameItems = os.listdir(self.ImagePathDir)
def __getitem__(self, item):
# item 是获取某一个数据元素,懒汉模式,你要用我才给你
ItemName = self.ImageNameItems[item]
ImagePathItem = os.path.join(self.RootDir,self.LabelDir,ItemName)
ItemGet = self.transform(Image.open(ImagePathItem).resize((500,500)))
ItemLabel = self.LabelDir
return ItemGet,ItemLabel
def __len__(self):
return len(self.ImageNameItems)
if __name__ =="__main__":
RootDir = "train"
OneYuanLabel = "1"
HandoneYuanLabel = "100"
OneYuanData = MyDataset(RootDir,OneYuanLabel)
HandoneData = MyDataset(RootDir,HandoneYuanLabel)
DataGet = OneYuanData+HandoneData
train_data = DataLoader(dataset=DataGet,batch_size=18,shuffle=True,num_workers=0,drop_last=True)
for data in train_data:
imgs,tags = data
print(imgs.shape)
重点是我们进行那个 继承Dataset,然后实现 __getitem()__这个魔法方法。看代码其实很简单,获取了我们路径的图片名称,然后,再调用魔法方法的时候,我们读取图片然后直接转化为tensor,这个其实和前面获取的数据是类似的,只是我们直接转化了一下,同时这里也是为什么我们要用 DataLoader,用这个可以把数据拿出来,而不是等到训练模型的时候再来,那样是很慢的。
TensorBoard 可视化工具箱
目标
这里主要分两部分,一个是如何直观的显示出我们预测的效果,或者是误差,另一个是如何进行网络的搭建,以及再次理解神经网络。
神经网络
先前我们举过一个例子,就是从线性回归来推导神经网络的工作流程。我们使用损失函数,来进行反向传播,也就是使用损失函数来进行梯度下降,我们假设 y = x2 +2 此时,我们输入的是x ,y 但是我们要猜测的是 2 和 2 也就是
y = ax + b 的 a,b 。之后对于非线性的拟合,我们还有激活函数,那么这个激活函数是什么?就是给我们的线性拟合做非线性变换。(学好神经网络,机器学习,智能优化算法你会发现大部分的数学建模题目都能用这些玩意来做,比如那个2021数学建模的A题我没看懂,C题其实不难但是懒得分析,B直接套,先来个拟合,然后我直接用傅里叶拟合,神经网络推算关系(这个做法可以有,但是过拟合是绝对的,因为数据太少,所以要有大量的误差,灵敏度分析来填坑(然鹅我忘了这个流程)),最后一个优化直接跑优化算法,然后也是有问题也要评估分析,最后一个根据你的分析带上实验步骤,其实就是分析实验不足,也就是你的模型不足,还需要那些数据来修正。虽然做法很暴力,但是比语文建模好多了,而且分析到位的话是能够拿国奖的)。
神经网络在运行的过程中其实分三大部分,第一部分是初始化,这个就是我说的先随便猜测几个参数,第二个部分是通过损失函数,进行反向传递(也就是梯度下降)来优化我们的未知参数,最后一步就是各种优化
OK,我们来看看一个基本的神经网络模型

还有我们上次的那个网络模型
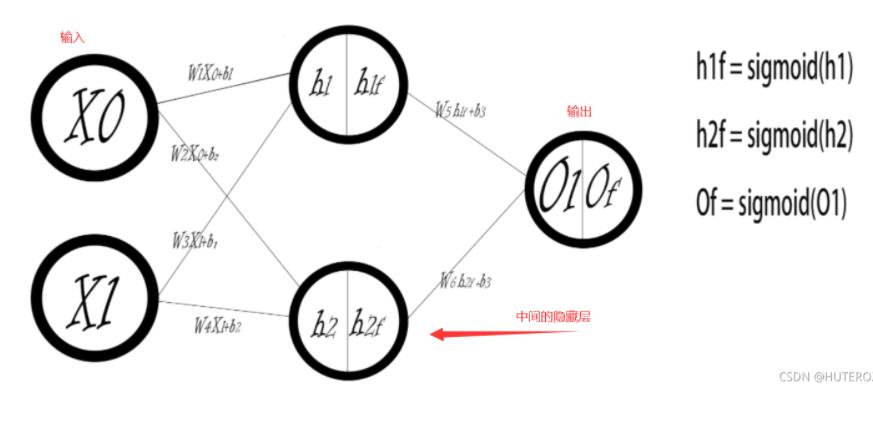
其实真正完整的过程是这样的

但是注意哦,在实际的神经网络当中 我们的 “线性”是有双引号的,例如图像等等。如果只是说拟合的话,我们可以这样说,因为输入的参数,维度就是这样的线性的离散的。
动手搭建线性回归模型
现在,我们是时候使用pytorch搭建一个简单的线性模型了
在此我们先简单地说一下我们的API
Linear 这个是我们的线性层,对比上面的图片
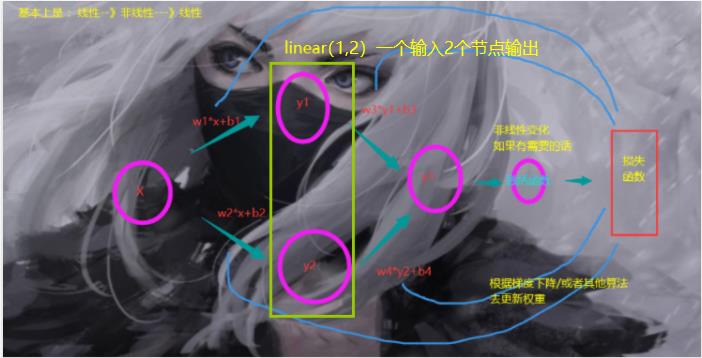
OK,现在我们直接看代码
from torch import nn
from torch.optim import SGD
import torch
class LineBack(nn.Module):
def __init__(self):
super().__init__()
# y=ax+b
self.line = nn.Linear(1,1)
def forward(self,x):
x = self.line(x)
return x
myline = LineBack()
# 设置学习速度
optim = SGD(myline.parameters(),lr=0.01)
lossfunction = nn.MSELoss()
#数据生成
x = [i for i in range(10)]
y = [(i*2 + 2) for i in range(10)]
#数据转换
x = torch.tensor(x,dtype=torch.float)
x = x.reshape(-1,1) #变成10行一列
y = torch.tensor(y,dtype=torch.float)
y = y.reshape(-1,1)
for epoch in range(1,1001):
optim.zero_grad()#清空梯度防止影响
outputs = myline(x)
loss = lossfunction(outputs,y)
loss.backward()
optim.step()
if(epoch % 50 == 0):
print("训练:次的总体误差为".format(epoch,loss.item()))
然后,让我们看看效果

总体上还是非常简单的。
我们的y = 2*x +2
非线性模型搭建
前面我们搭建了线性模型,那么现在我们来看看非线性模型。
这里由于是非线性的,所以我们必须使用激活函数。这里使用的是rule
这个rule是非线性变幻,这个函数大概长这个样子
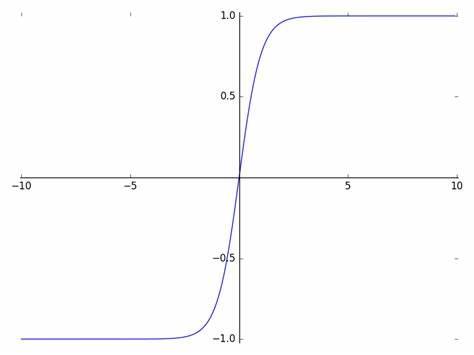
我们的神经网络本质上那就是一个拟合的过程,例如咱们使用什么傅里叶拟合,是一个道理,只不过是使用了不同的模型罢了。
不过这里面当然有很多细节需要注意。
from torch import nn
from torch.optim import SGD
import torch
import torch.nn.functional as F
class LineBack(nn.Module):
def __init__(self):
super().__init__()
self.line1 = nn.Linear(1,10)
self.line2 = nn.Linear(10,1)
def forward(self,x):
x = F.relu(self.line1(x)) # 这个和nn.RELU()是一样的,区别是这个可以当中函数在forward里面使用
x = self.line2(x)
return x
myline = LineBack()
optim = SGD(myline.parameters(),lr=0.01)
lossfunction = nn.MSELoss()
#数据生成
x = torch.linspace(-1, 1, 100) #生成-1到1的100个数字
y = x.pow(2) + 0.2*torch.rand(x.size())
#数据转换
x = x.reshape(-1,1) #变成10行一列
y = y.reshape(-1,1)
for epoch in range(1,1001):
optim.zero_grad()#清空梯度防止影响
outputs = myline(x)
loss = lossfunction(outputs,y)
loss.backward()
optim.step()
if(epoch % 50 == 0):
print("训练:次的总体误差为".format(epoch,loss.item()))
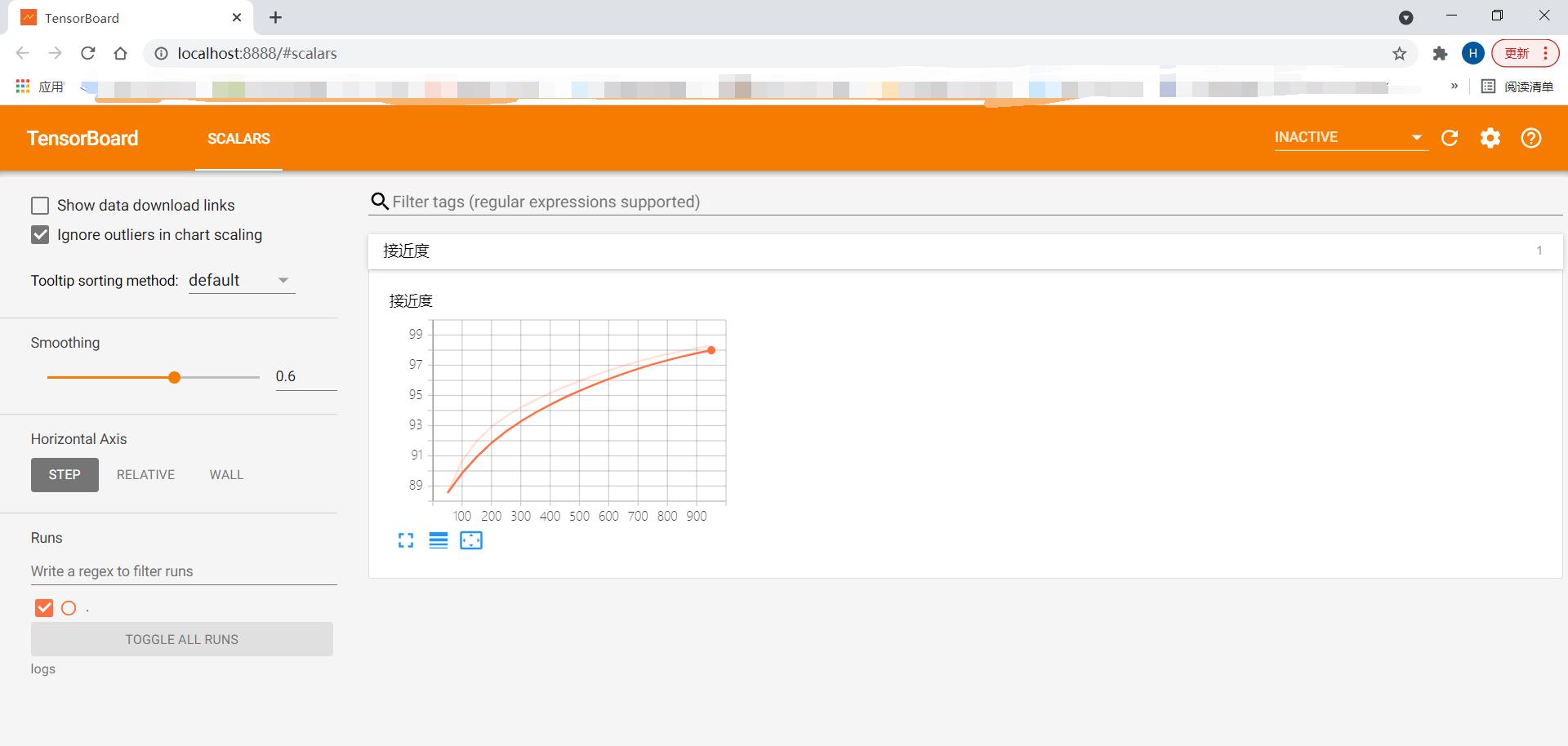
TensorBoard 直观显示
前面我们在控制台显示可不好看,所以我们得华哥图,我们可以直接使用matplotlib但是在我们的tensorflow或者是pytorch里面有tensorboard这玩意可以画图,而且功能相当强大。
不过在使用之前,你需要下载
pip install tensorboard
或者使用conda,看你的环境,我是直接把pytorch环境当中本机环境了,我双系统,而且先前有 virtualenv 创建开发环境。
from torch import nn
from torch.optim import SGD
import torch
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
class LineBack(nn.Module):
def __init__(self):
super().__init__()
self.line1 = nn.Linear(1,10)
self.line2 = nn.Linear(10,1)
def forward(self,x):
x = F.relu(self.line1(x)) # 这个和nn.RELU()是一样的,区别是这个可以当中函数在forward里面使用
x = self.line2(x)
return x
wirter = SummaryWriter("logs") #图形工具,logs保存路径
myline = LineBack()
optim = SGD(myline.parameters(),lr=0.01)
lossfunction = nn.MSELoss()
#数据生成
x = torch.linspace(-1, 1, 100) #生成-1到1的100个数字
y = x.pow(2) + 0.2*torch.rand(x.size())
#数据转换
x = x.reshape(-1,1) #变成10行一列
y = y.reshape(-1,1)
for epoch in range(1,1001):
optim.zero_grad()#清空梯度防止影响
outputs = myline(x)
loss = lossfunction(outputs,y)
loss.backward()
optim.step()
if(epoch % 50 == 0):
percent =(1- loss.item())*100
wirter.add_scalar("接近度",percent,epoch)
print("训练:次的总体误差为".format(epoch,loss.item()))
代码如上,然后在我们的控制台输入

然后打开浏览器
后面我们再来说是如何使用Pytorch搭建CNN神经网络,已经常见的神经网络。之后我们搭建一个简单的5层神经网络CIFAR10这个最经典的神经网络,也是数据集比较小的。没办法神经网络就是要用数据来喂。
CIRAF10网络搭建
由于咱们的CIRAF10是一个CNN模型,所以在这里我们需要简单地说一下什么是CNN神经网络。
记住一句话,就是前面说的一句话,神经网络本质上就是在做拟合。 我们把这个过程想像成数学建模的过程。
CNN + 神经网络
CNN 就是建模的过程,(CNN 卷积,卷积这个概念我们稍后解释)对于一张图片,我们人类可以轻而易举地识别出来,但是对于计算机,这个它可搞不出来,所以我们必须要想办法让计算机去识别出一张图片,计算机最擅长的就是计算,最喜欢的就是矩阵,所以我们想办法把一张图片和对应的一些信息,例如咱们的这个模型,这是一个分类模型,我们想办法把图片和标签对应起来。
任何的,我们人类的可视化,可理解的内容例如文字,图片,音频都可以在计算机里面使用矩阵表示,于是问题就变成了线性代数,离散数学,微积分,高数的问题。
所以在这个过程当中,对应这个模型CIARF10来说,我们可以这样理解。
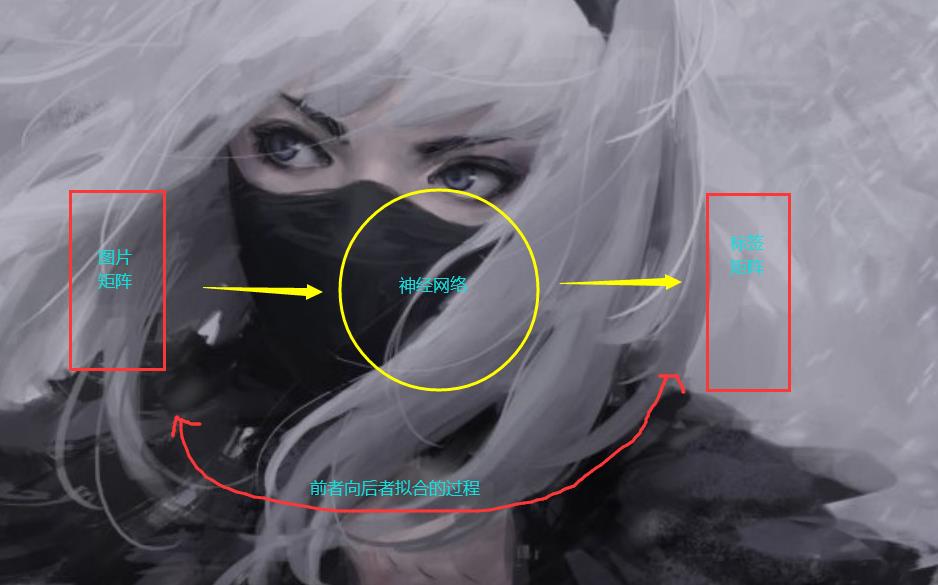
我们的神经网络是一个抽象的黑盒,通过训练之后,我们得到了每个神经网络节点的参数,阈值,这样我们不就可以进行简单地预测了嘛。
然后针对神经网络又有一堆优化问题。
所以 在这个过程当中,我们要解决的有两个问题,一个是神经网络模型,还有一个就是这个图片的处理。那么在这里我们使用的是CNN 卷积的处理方式。
ok,我们先来看看我们的这个CIARF10模型