第一讲:Kafka要点入门
Posted 哩哩啦啦’
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一讲:Kafka要点入门相关的知识,希望对你有一定的参考价值。
目录
Hi,大家好,我是一个爱冒泡的程序猿 好久不见呀,时间过得好快,转眼间已经2022年,好久没更新了,希望自己今年能坚持记录反省自己
一、Kafka是什么
Kafka最初是由LinkedIn公司采用Scala语言开发的一个分布式、多分区、多副本且基于ZooKeeper协调的内部基础设置,现已捐献给Apache基金会。Kafka主要用来发布和订阅数据流,是流式数据处理的利器。Kafka用于构建实时数据管道和流应用程序,具有水平可伸缩性,容错性,快速性。
Kafka可以处理消费者规模的网站中的所有动作(网页浏览,搜索和其他用户的行动-收藏)流数据。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
其实大家去看看官方文档就能够找到关于它的准确定义:
从0.8版本开始,官方文档的定位是:分布式、可分区、具有副本的日志提交服务,并提供了消息传递系统的功能
- Kafka 在称为主题的类别中维护消息
- 生产者向 Kafka 主题发布消息
- 消费者向 Kafka 主题订阅消息
- Kafka作为集群运行,集群由一个或多个服务器组成,每个服务器被称为broker
在0.10.0版本开始,官方文档关于Kafka的定义是:分布式的流处理平台
- 发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 以容错持久的方式存储记录流。
- 在记录流发生时对其进行处理
而在2.5版本开始,官方文档关于Kafka的定义是:事件流处理
- 从技术上讲,事件流是从数据库、传感器、移动设备、云服务和软件应用程序等事件源中以事件流的形式实时捕获的数据;
- 持久地存储这些事件流以供以后检索;
- 实时地、可回溯性地操作、处理和响应事件流;
- 根据需要将事件流路由到不同的目标。
因此,事件流可确保数据流的连续性和可解释性,以使正确的信息在正确的时间和正确的位置上。
Kafka 3.0都有哪些新特性:
弃用对 Java 8 和 Scala 2.12 的支持
Kafka Raft 支持元数据 Topic 快照,及自我仲裁管理的一些改进
为Kafka Producer提供更强大的交付保证
弃用v0 和 v1 版本消息格式
优化OffsetFetch 和 FindCoordinator 请求
弃用Mirror Maker 1,提供更灵活的 Mirror Maker 2
在 Kafka Connect 中的单个调用中重新启动连接器任务
事件流在众多行业中都有各种应用案例,如:
- 实时处理支付和金融交易,例如在证券交易所、银行和保险中。
- 实时跟踪和监控汽车、卡车、车队和货物,例如物流。
- 持续捕获和分析来自IoT设备或其他设备(例如工厂和风电场)的传感器数据。
- 收集客户交互和订单并立即做出反应,例如在零售、酒店和旅游行业以及移动应用程序中。
- 监测住院病人并预测病情变化,以确保在紧急情况下得到及时治疗。
- 连接、存储和提供公司不同部门产生的数据。
- 作为数据平台、事件驱动架构和微服务的基础设施。
二、Kafka主要特点
为什么使用Kafka?
主题和日志
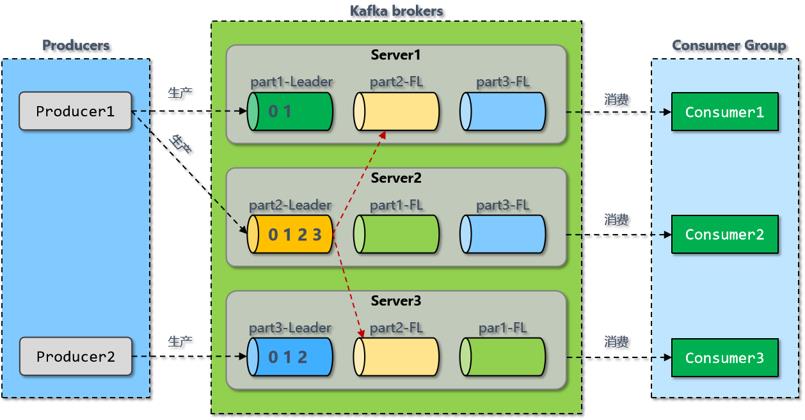
主题是Kafka提供的核心抽象。主题是将信息记录到的某个类别或订阅源名称。Kafka中的主题始终是多用户的,也就是说,一个主题可以有零个,一个或多个消费者来订阅写入该主题的数据。
对于每个主题,Kafka集群都会维护一个分区。每个分区都是由有序的不变的记录序列构成,这些记录连续地“append”到“commit log”中。每个分区中的记录都分配有一个称为“偏移量”的顺序ID,该ID唯一地标识分区中的每个记录。
请注意,与大多数消息传递系统不同,日志始终是持久的
1.主题(Topic)
Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到Kafka集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。
2.分区(Partition)
主题是一个逻辑上的概念,它还可以细分为多个分区,一个分区只属于单个主题,很多时候也会把分区称为主题分区(Topic-Partition)。
同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
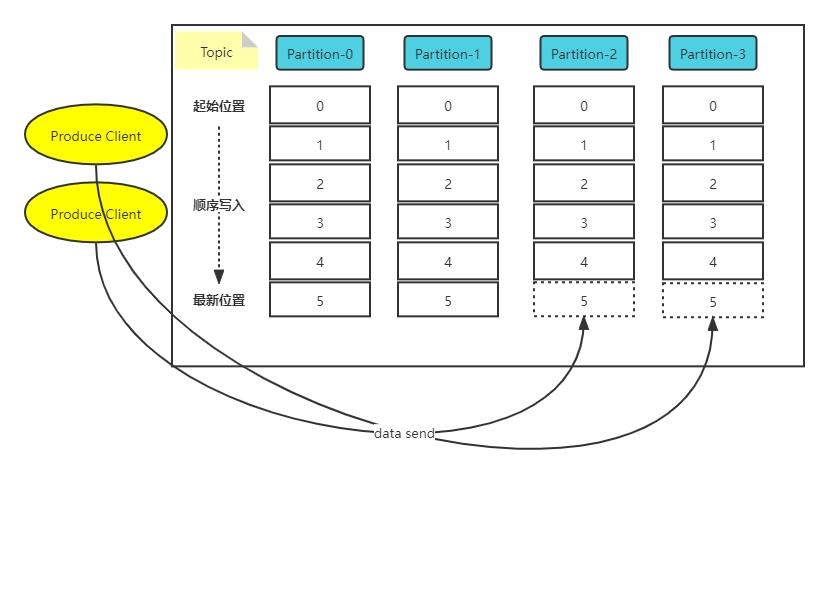
如上图所示,offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序。
Kafka中的分区可以分布在不同的服务器(broker)上,也就是说,一个主题可以横跨多个broker,以此来提供比单个broker更强大的性能。
分布式
分区分布在Kafka群集中的服务器上。每个分区都在可配置数量的服务器之间复制,以实现容错功能。每个分区都有一个充当“Leader”的服务器,零个或多个充当“Follower”的服务器。Leader处理所有读写请求,而Follower则被动地复制Leader的数据。如果Leader因宕机或者其他原因失败,Follower之一将通过选举成为新的Leader。每个服务器充当某些分区的Leader,而充当其他分区的Follower。
高性能
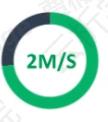
由3台廉价PC组成的Kafka集群每秒可以处理:200万条消息(写),每条10K
参考文档:《Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines)》
机器:8核2Ghz,16G内存,千兆网卡,千兆网络
RabbitMQ、ActiveMQ和Kafka对比
生产者测试,总共发布1000万条消息,每条消息200字节。
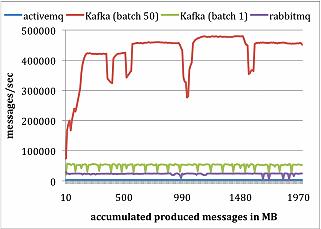
消费者测试,总共获取1000万条消息。
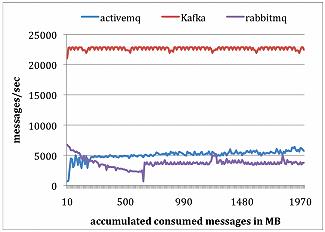
问题:Kafka为什么有这么高的性能?
充分利用了磁盘的物理特性,即,随机写入慢(磁头冲停),顺序写入快(磁头悬浮)。
机械结构的磁盘,如果把消息以随机的方式写入到磁盘,那么磁盘首先要做的就是 寻址,也就是定位到数据所在的物理地址,在磁盘上就要找到对应的柱面、磁头以及对应的扇区;这个过程相对内 存来说会消耗大量时间,为了规避随机读写带来的时间消耗,kafka采用顺序写的方式存储数据来避免这个过程。
*********************************
【windows】此文件是512M
// 随机读
fio -filename=D:\\software\\java\\JDK1.8.rar -iodepth=1 -ioengine=psync -rw=randread -bs=4k -size=1G -numjobs=1 -group_reporting -name=test-rand-read
read: IOPS=303k, BW=1184MiB/s (1241MB/s)(1024MiB/865msec)
READ: bw=1184MiB/s (1241MB/s), 1184MiB/s-1184MiB/s (1241MB/s-1241MB/s), io=1024MiB (1074MB), run=865-865msec
**************
// 顺序读
fio -filename=D:\\software\\java\\JDK1.8.rar -iodepth=1 -ioengine=psync -rw=read -bs=4k -size=1G -numjobs=1 -group_reporting -name=test-read
read: IOPS=307k, BW=1198MiB/s (1256MB/s)(1024MiB/855msec)
READ: bw=1198MiB/s (1256MB/s), 1198MiB/s-1198MiB/s (1256MB/s-1256MB/s), io=1024MiB (1074MB), run=855-855msec
**************
// 随机写
fio -filename=D:\\software\\java\\JDK1.8.rar -iodepth=64 -ioengine=psync -rw=randwrite -bs=4k -size=1G -numjobs=64 -runtime=20 -group_reporting -name=test-rand-write
write: IOPS=144k, BW=563MiB/s (591MB/s)(11.0GiB/20007msec); 0 zone resets
WRITE: bw=563MiB/s (591MB/s), 563MiB/s-563MiB/s (591MB/s-591MB/s), io=11.0GiB (11.8GB), run=20007-20007msec
**************
// 顺序写
fio -filename=D:\\software\\java\\JDK1.8.rar -iodepth=64 -ioengine=psync -rw=write -bs=4k -size=1G -numjobs=64 -runtime=20 -group_reporting -name=test-write
write: IOPS=152k, BW=593MiB/s (622MB/s)(11.6GiB/20006msec); 0 zone resets
WRITE: bw=593MiB/s (622MB/s), 593MiB/s-593MiB/s (622MB/s-622MB/s), io=11.6GiB (12.4GB), run=20006-20006msec
【Linux】
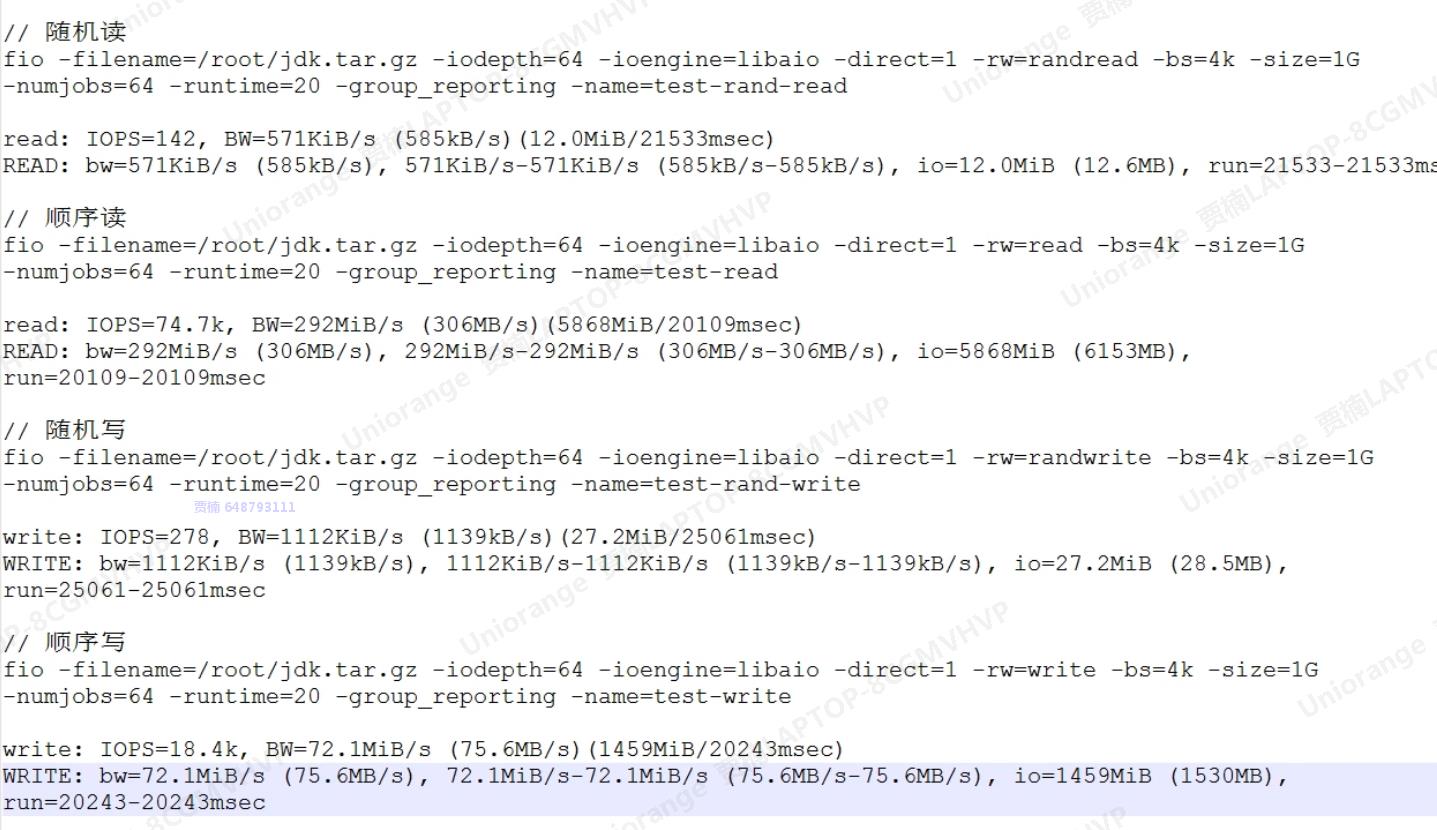
好困啊,但是我爱工作,我爱赚钱

以上是关于第一讲:Kafka要点入门的主要内容,如果未能解决你的问题,请参考以下文章