GPT-3好“搭档”:这种方法缓解模型退化,让输出更自然
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPT-3好“搭档”:这种方法缓解模型退化,让输出更自然相关的知识,希望对你有一定的参考价值。

作者 | LZM
来源丨数据实战派
文本生成对于许多自然语言处理应用来说都是非常重要的。
但神经语言模型的基于最大化的解码方法(如 beam search)往往导致退化解,即生成的文本是不自然的,并且常常包含不必要的重复。现有的方法通过采样或修改训练目标来引入随机性,以降低某些 token 的概率(例如,非似然训练)。然而,它们往往导致解决方案缺乏连贯性。
近日,来自剑桥大学、香港中文大学、腾讯 AI 实验室和 DeepMind 的科学家们证明,自然语言生成模型出现退化现象的一个潜在原因是 token 的分布式表示向量存在各向异性。
他们进一步提出了一个基于对比学习的自然语言生成框架。在两种语言的三个基准测试上进行的大量实验和分析表明,该方法在人工评估和自动评估两个方面上优于目前最先进的文本生成方法。
研究动机与主要研究内容
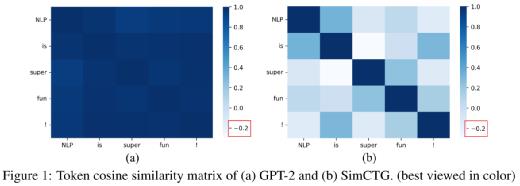
图1. Token 表示向量的 cosine 相似度矩阵
这项研究中,研究团队发现,神经语言模型的退化源于 token 表示向量的各向异性分布,即它们的表示向量驻留在整个空间的一个狭窄子集中。
图1(a)展示了 token 表示向量的 cosine 相似度矩阵,其中表示向量来源于 GPT-2 的最后一个隐层的输出。研究团队看到句子中 token 之间的余弦相似度超过 0.95,这意味着这些表征彼此十分接近。
在理想情况下,模型的 token 表示应遵循各向同性分布,即 token 相似度矩阵应是稀疏的,不同 token 的表示应是有区别的,如图2(b)所示。在解码过程中,为了避免模型退化,需要保留生成文本的 token 相似矩阵的稀疏性。
基于上述动机,研究团队提出了 SimCTG(一个简单的神经文本生成对比框架),该框架鼓励模型学习有区分度的、各向同性的 token 表示。
对比搜索背后的关键直觉是:
(1)在每个解码步骤,输出应该从组中选择最有可能的候选词的预测模型,以更好地维护生成的文本之间的语义一致性;
(2)token 相似矩阵的稀疏性应该保持以避免退化。
主要方法
对比训练
研究团队的目标是鼓励语言模型学习有区别且各向同性的 token 表示。为此,在语言模型的训练中引入了一个对比损失函数 LCL。给定任意一个变长序列 x,该对比损失函数定义为:
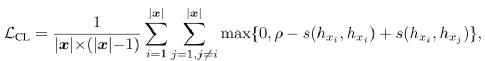
其中,ρ 是预先设定的 margin,hxi 是模型输出的 xi 的表示向量。相似度函数 s 计算任意两个表示向量之间的余弦相似度:
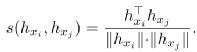
可以想象,通过训练上述对比损失函数,不同 token 的表示间的距离将被拉开。因此,可以得到一个可分的、各向同性的模型表示空间。最终的总损失函数为:
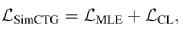
对比搜索
研究团队提出一种新的解码方法:对比搜索(contrastive search)。每一步解码时,(1)模型从最可能的候选集合中选出一个作为输出,(2)产生的输出应当与前面已经生成的内容足够不同。这种方式下生成的文本在保持与前文的语义一致性的同时还能避免模型退化。具体来说,输出 xt 的生成满足:
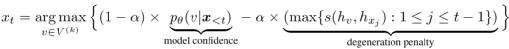
其中 V(k) 是候选词集合,k 通常取 3 到 10。上式的第一项代表模型对 v 的支持度 v(model confidence),是模型估计的候选词 v 为下一个词的概率。第二项是对模型退化的惩罚项(degeneration penalty)是下一个词 v 与前面已生成的词的相似度最大值。α 是超参数,负责调节两项损失之间的平衡。当 α=0 时,解码方法退化到贪婪搜索。
效率分析:该方法可以有效地实现对比搜索。所需的额外计算是退化罚的计算,该计算可以通过简单的矩阵乘法来实现。后文将证明,对比搜索的译码速度优于或可与其他广泛应用的译码方法相媲美。
文本生成
首先在开放式文本生成任务(open-ended document generation)上评价研究团队所提出的新方法。
模型和基线 本文提出的方法与模型结构无关,因此可以应用于任何生成模型。在这项实验中,他们在具有代表性的 GPT-2 模型上评估了所提出的方法。
具体来说,研究团队在评估基准(详细如下)上使用提出的目标 LSimCTG 对 GPT-2 进行了调优,并使用不同的解码方法生成连续文本。使用基础模型(117 M 参数)进行实验,该模型由 12 个 Transformer 层和 12 个 attention head 组成,将本方法与两个强基线方法进行比较:
(1)GPT-2 在标准 MLE 损失函数上微调;(2)利用非似然目标函数微调。研究团队的实现基于 Huggingface 库(Wolf 等人,2019)。
基准数据集 研究团队在 Wikitext-103 数据集(Merity 等人, 2017)上进行了实验,该数据集包含了一个包含超过 1 亿单词。Wikitext-103 是一个文档级数据集,已被广泛用于大规模语言建模的评估。
评价指标
研究团队从两个方面进行评价:
(1)语言建模质量,衡量模型的内在质量;
(2)生成质量,用来衡量生成文本的质量。
l 语言建模质量
n 困惑度
n 预测准确率
n 预测重复率
l 文本生成质量
n 生成重复度
n 多样性
nMAUVE(一种度量机器生成文本与人类生成文本间相近程度的指标;MAUVE 越高,机器文本越像人类文本)
n 语义连贯性
n 生成文本的困惑度
实验结果
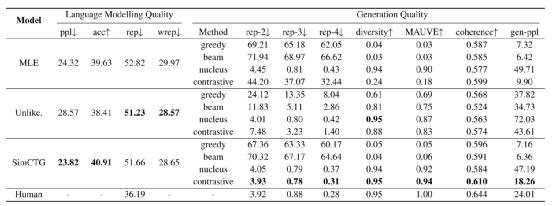
表1. 多种方法在 Wikitext-103 数据集上的测试结果
表1 展示了 Wikitext-103 数据集上的实验结果。
语言建模质量 从结果来看,SimCTG 获得了最好的困惑度和下一个 token 预测准确率。因为其使用了更有区分度的分布式表示,SimCTG 在进行下一个 token 预测时更不容易混淆,从而提高了模型性能。在 rep 和 wrep 度量上,非似然模型产生了最好的结果,但代价是复杂性和下一个 token 预测准确性方面的性能下降。
文本生成质量
首先,在 rep-n 和多样性指标上,SimCTG+对比搜索获得了最好的性能,表明它最好地解决了模型退化问题。其次,MAUVE 分数表明 SimCTG+对比搜索生成的文本在令牌分布方面与人类编写的文本最接近。第三,在所有方法中,SimCTG+对比搜索是唯一一种一致性得分在 0.6 以上的方法,表明该方法生成的文本质量高,且相对于前缀而言语义一致。最后,gen-ppl 度量也验证了 SimCTG+对比搜索的优越性,因为与其他方法相比,它获得了明显更好的生成困惑度。
此外,从 MLE 和 Unlikelihood 基线的结果来看,对比搜索仍然比贪婪搜索和 beam 搜索带来了额外的性能提升。然而,对比训练的性能提高仍然滞后于 SimCTG,这说明了对比训练的必要性。一个可能的原因是,没有对比损失 LCL,MLE 或 unlikelihood 训练出来的 token 表示不具备充分的可区分性。因此,不同候选对象的退化惩罚不易区分,输出的选择受模型置信度的影响,使得对比搜索的有效性降低。
人工评价
研究团队还通过内部评分平台,在高英语水平学生的帮助下进行了人工评价。所有生成文本和真实的后文放在一起随机打乱,然后由 5 个人类评分者评估,最终产生总共 9000 个标注样本。评估遵循李克特 5 点量表(1、2、3、4 或 5),从以下三个方面进行打分:
连贯性:生成的文本是否与前文在语义上保持一致
流畅性:生成的文本是否易读
信息量:生成的文本是否多样,是否包含有趣的内容
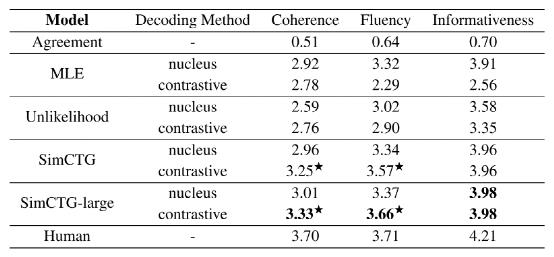
表2. 文本生成的人工评价
表2 给出了人工评价结果,其中第一行显说明了人类评价能够很好的发现参考文本。首先,研究团队发现直接使用 MLE 或 Unlikelihood 模型进行对比搜索并不能得到满意的结果。这是由于它们表示空间的各向异性。第二,Unlikelihood 模型的一致性得分明显低于 MLE 和 SimCTG,表明其产生的结果最不可能,这从表1 的 generation perplexity(gen-ppl)中也可以看出。此外,SimCTG +对比搜索结果在一致性和流畅性方面明显优于不同模型的核抽样。
最后,SimCTG-large +对比搜索获得了全面的最佳性能,甚至在流畅度指标上与人类书写的文本表现相当。这揭示了该方法对于大型模型的通用性,未来的工作可以集中于将其扩展到包含超过数十亿参数的模型,如 GPT-3。
开放式对话系统
为了测试这个方法在不同任务和语言中的通用性,本文还在开放域对话生成任务中评估了研方法。在这个任务中,给定一个多回合对话上下文(每个回合都是一个用户的话语),要求模型生成一个语义上与上下文一致的适当的响应。在这里,对话语境被视为前文。
基线模型和基准测试集 研究在中文和英文两种语言的两个基准数据集上进行了实验。中国数据集方面,使用 LCCC 数据集(Wang 等人,2020)。英语数据集方面,则使用 DailyDialog 数据集。
研究团队比较了通过 SimCTG 和 MLE 微调的 GPT-2 模型。具体来说,对于中文基准数据集,使用了一个公开可用的中文 GPT-2(Zhao 等人,2019)。在训练期间,使用 128 作为 batch size,并将训练样本截断为最大长度 256 个 token。在 LCCC 数据集上,对模型进行 40k 步的训练(即微调)。对于 DailyDialog 数据集,由于其数据集较小,将模型训练 5k 步。优化方面,使用 Adam 优化器和 2e-5 的学习率。
模型评价 研究团队依靠人工评价来衡量模型的性能,从测试集中随机选取了 200 个对话上下文,请 5 位标注者从三个维度:连贯性、流畅性和(3)信息量,分别进行打分。分数遵循李克特 5 分量表(1、2、3、4 或 5)。
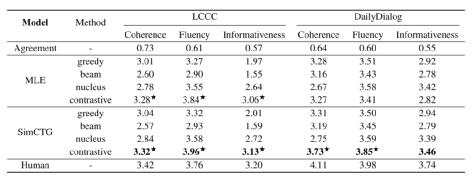
表3. 开放式对话的人工评价
表3 展示了开放式对话的人工评价结果。在这两个数据集上, SimCTG +对比搜索在各种指标上显著优于其他方法,这表明该方法可推广到不同的语言和任务上。值得强调的是,在 LCCC 基准测试中,SimCTG +对比搜索在流畅度指标上的表现出人意料地优于人类,而在连贯性和信息量指标上的表现也相当不错。
并且,即使不进行对比训练,MLE 模型在使用对比搜索时的性能也显著提高。这是由于汉语语言模型的固有属性,MLE 目标已经可以产生一个表现出高度各向同性的表示空间,使得对比搜索可以直接应用。这一发现尤其具有吸引力,因为它揭示了对比搜索在现成语言模型(即不进行对比训练)上的潜在适用性,适用于某些语言,如汉语。
总结
这项研究中,作者们证明了神经语言模型的退化源于它们的 token 表示的各向异性性质,并提出了一种新的方法——SimCTG,用于训练语言模型,使其获得一个各向同性且有区分度的表示空间。此外,研究还介绍了一种新的解码方法——对比搜索,该方法与本文所提出的 SimCTG 目标一致。基于在两种语言的三个基准测试集上进行的广泛实验和分析,自动和人工评价都表明了,本文所提的方法大大削弱了模型退化程度,显著优于当前最先进的文本生成方法。

往
期
回
顾
技术
资讯
技术
技术

分享

点收藏

点点赞

点在看
以上是关于GPT-3好“搭档”:这种方法缓解模型退化,让输出更自然的主要内容,如果未能解决你的问题,请参考以下文章