socket发送字符串时怎么自定义编码格式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了socket发送字符串时怎么自定义编码格式相关的知识,希望对你有一定的参考价值。
项目搭建在在服务器上,是与银行的一个交换。规定由我方发起socket请求,发送请求报文(xml格式,utf-8编码),银行应答后发送对账文件(字符串,gbk编码)。最近银行反馈我方发送的字符串也是utf-8编码,导致处理报错,求大神解答!
// 获取socket输入输出流,阻塞通信
InputStream is = null;
Writer writer = null;
try
writer = new OutputStreamWriter(socket.getOutputStream(),"GBK");
is = socket.getInputStream();
catch (IOException e1)
e1.printStackTrace();
// 组装发送核心的请求信息
buildMessage = CenterControll.getImplementOfRequest(requestType);
message = buildMessage.build(replyMessage, fileName, fileType, begainIndex, fileLen, endIndex, dataPackage, path,privateKey);
settleLogger.settlePrintData("发送的报文"+message);
System.out.println("请求:"+message);
if (message.equals("stop"))
continueCommunicate = false;
break;
writer.write(message);
if(message.indexOf("X1.0")==0)
if(0 != requestType.indexOf("send"))
writer.write("0000");
writer.flush();
首先先大概介绍一下向导生成的代码:
程序的进入点是全局函数_tWinMain, 仔细看一下这个函数,会发现当运行程序时,可以加上参数,例如: ServiceDemo /RegServer 或者 ServiceDemo -RegServer,这个是用来本地服务器注册(Register as Local S Register as Service erver); ServiceDemo / Service 或者 ServiceDemo -Service,这个是服务的注册(Register as Service);ServiceDemo /UnRegServer 或者 ServiceDemo -UnRegServer ,这个是服务的删除。所以,当写好了服务程序,只要运行的时候加上参数 Service ,这个时候在SCM中就会看到我们的服务了。可以试一下在SCM中对这个什么也不做的服务"启动","停止",改变一下它的启动方式。 参考技术A 你把字符utf-8转GBK发出去,接受回来是GBK在转utf-8
python socket
草稿,未完待续:

json.dumps 序列化(将数据变成字符串格式)
head_json.encode(\'utf-8\') 将字符串编译成bytes格式。
struct提供用format specifier方式对数据进行打包和解包(将数字转成固定长度的bytes格式)
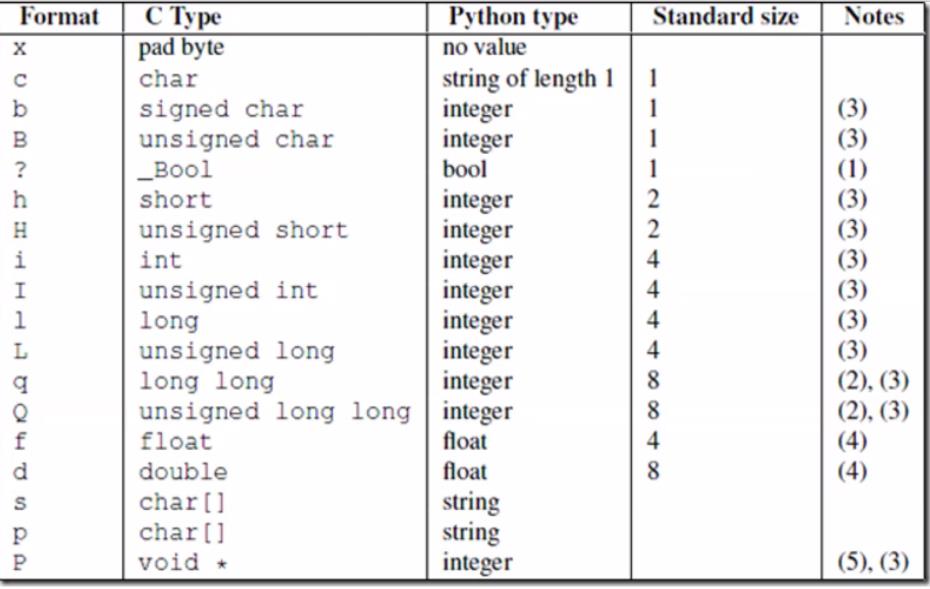
套接字只能发送bytes格式的数据
只有字符能编码成bytes格式,数字等其它类型的数据不能编码成bytes格式。

进程、线程
Socket实现并发
Self.Request就是conn;
import socketserver
#Ftpserver(conn, client_addr, obj)
class FTPserver(socketserver.BaseRequestHandler):
#通讯 #必须创建一个类,必须继承这个方法(固定死的)
def handle(self): #必须创建handle这个函数(固定死的)
print(\'=-=====>\',self.request)
print(self.request)
while True:
data=self.request.recv(1024)
print(data)
self.request.send(data.upper())
if __name__ == \'__main__\':
obj=socketserver.ThreadingTCPServer((\'127.0.0.1\',8080),FTPserver) #创建线程,一个线程就是一个服务员,多线程就是多个服务员。
print(obj.server_address)
print(obj.RequestHandlerClass)
print(obj.socket)
obj.serve_forever() #链接循环
实现多线程
开启一个子线程:使用threading模块
并行:多进程同时运行,不需要切换
并发:多进程之间切换运行,切换调节:
#子线程继承父线程的setDaemon的状态,主(注意不是父)线程默认为false;true为守护线程,false为非守护线程。主线程执行结束会强行关闭守护线程,需要等待非守护线程执行完才结束。
#IO操作不占用CPU,并且遇到IO操作直接执行其他线程。GIL锁规定单一进程只能实现并发,不能实现并行。结合以上两个原因得出结论:多线程对IO密集型任务有优势,对计算密集型任务没有优势。
创建线程1
import threading
import time
def foo(n):
time.sleep(n)
print("foo....%s" % n)
print(threading.activeCount()) #总共有多少个线程
def bar(n):
time.sleep(n)
print("bar......%s" % n)
s=time.time()
t1=threading.Thread(target=foo,args=(2,)) #创建线程对象,args=(线程数,)
#t1.setDaemon(True) #设置为守护线程
t1.start() #开启线程
t2=threading.Thread(target=bar,args=(5,))
#t2.setDaemon(True)
t2.start()
t1.join() # 阻塞主线程
t2.join()
print("++++++",threading.activeCount())
print("ending!")
print("cost time:",time.time()-s)
# foo(4)
# bar(5)
创建线程2
创建10个线程
进程:由程序、数据集、进程控制块三部分组成。
线程是最小的执行单元。
进程是最小的资源管理单元,进程是在一个数据集上正在运行的程序。管理着数据集和线程。
进程和线程的关系:
(1) 一个线程只能属于一个进程,一个进程至少有一个或多个线程。
(2) 资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3) 操作系统把CPU分给线程,即真正在CPU上运行的是线程。
进程和线程切换的原则:
1、时间片(非常短的时间)
2、遇到IO操作(sleep,input,accept)[不占用CPU]就切换。
3、优先级切换,优先切换到优先级高的。
创建子线程:
对象名=Threading.Thread(target=函数,args=(线程数,)
对象名.start() #开启子线程。
join函数:子线程调用不结束,下面的代码不执行
守护进程:守护线程和主线程共进退,等待非守护线程执行完退出
子线程继承父线程是否是守护线程的特征。也就是说如果父线程是守护线程,那么子线程也是守护线程。。。
多线程比较适合IO密集型,如果用于计算密集型反而会降低效率。
同步:进程在执行某个请求时,一直等待返回数据之后才执行下面的代码。
异步:异步双方不需要共同的时钟,不阻塞当前线程,允许后续操作。(全程无阻塞)
总结了一句话不知道对不对:IO密集型任务就是异步。
Python中函数,类和模块有自己的名称空间。
互斥锁:
多线程处理相同数据源的数据时,如果有IO会出现阻塞和切换,从而导致计算结果不准确。
保证共享数据操作的完整性。每个对象都对应一个"互斥锁" ,保证只能有一个线程访问该对象。
互斥锁只加到处理数据的代码上。
互斥锁的创建:
|
import threading
R=threading.Lock()
R.acquire() \'\'\' 对公共数据的操作 \'\'\' R.release() |
import threading
import time
def sub():
global num # 掌握为什么加global num
lock.acquire() #获取锁
temp=num
time.sleep(0.1 )
num=temp-1
lock.release() #释放锁
time.sleep(2)
num=100
l=[]
lock=threading.Lock() #创建互斥锁对象
for i in range(100):
t=threading.Thread(target=sub,args=())
t.start()
l.append(t)
for t in l:
t.join()
print(num)
互斥锁的讲解:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。
那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
实例:
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
执行以上程序,输出结果为:
开启线程: Thread-1
开启线程: Thread-2
Thread-1: Wed Apr 6 11:52:57 2016
Thread-1: Wed Apr 6 11:52:58 2016
Thread-1: Wed Apr 6 11:52:59 2016
Thread-2: Wed Apr 6 11:53:01 2016
Thread-2: Wed Apr 6 11:53:03 2016
Thread-2: Wed Apr 6 11:53:05 2016
退出主线程
死锁:
两把锁互相等待对方释放,
以上是关于socket发送字符串时怎么自定义编码格式的主要内容,如果未能解决你的问题,请参考以下文章