Python使用阿里API进行身份证识别
Posted ZHW_AI课题组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python使用阿里API进行身份证识别相关的知识,希望对你有一定的参考价值。
Python使用阿里API进行身份证识别
1. 作者介绍
孟莉苹,女,西安工程大学电子信息学院,2021级硕士研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:2425613875@qq.com
2. 身份证识别介绍
凭借领先的人工智能与知识图谱技术,对身份证正反面自动识别,并提取姓名、出生日期、身份证号、住址、性别、民族、发证机关等身份证实体信息。
3. 调用阿里智能云API
步骤一 :浏览器搜索阿里云,使用支付宝或者其他阿里APP扫码后用手机验证码登陆。
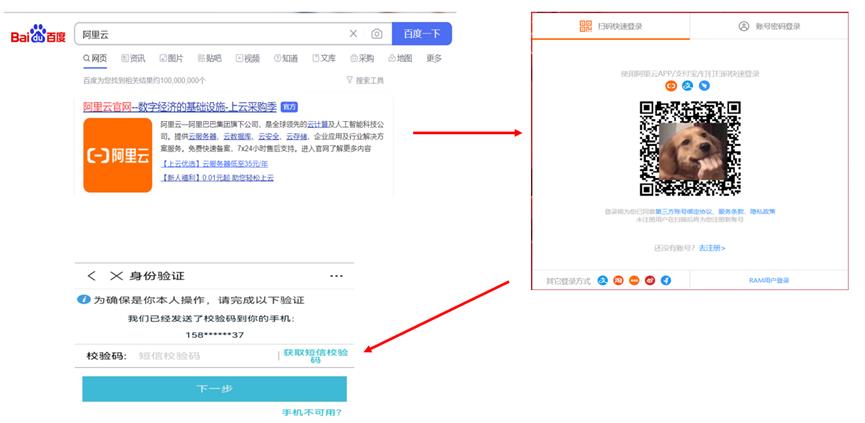
步骤二:登录后点开云市场并找到API市场。

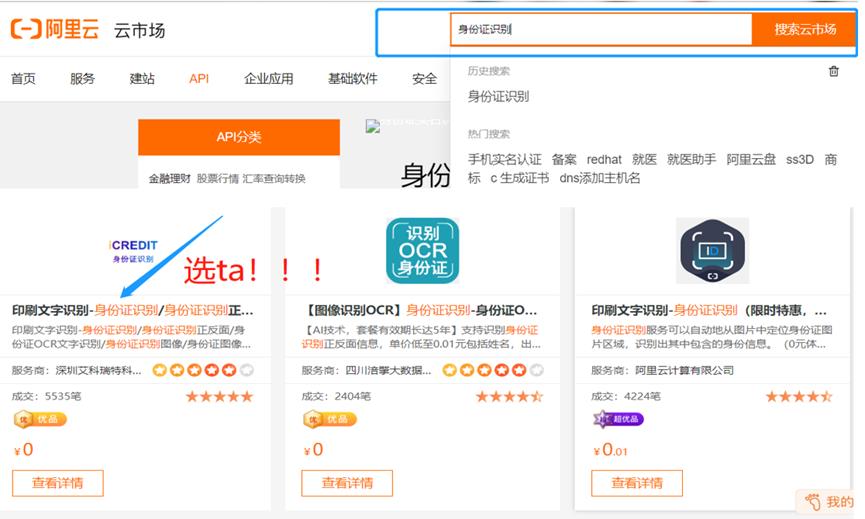
步骤三:在索搜框中输入身份证识别后回车,在弹出的API中选择深圳艾科瑞特身份证识别API。
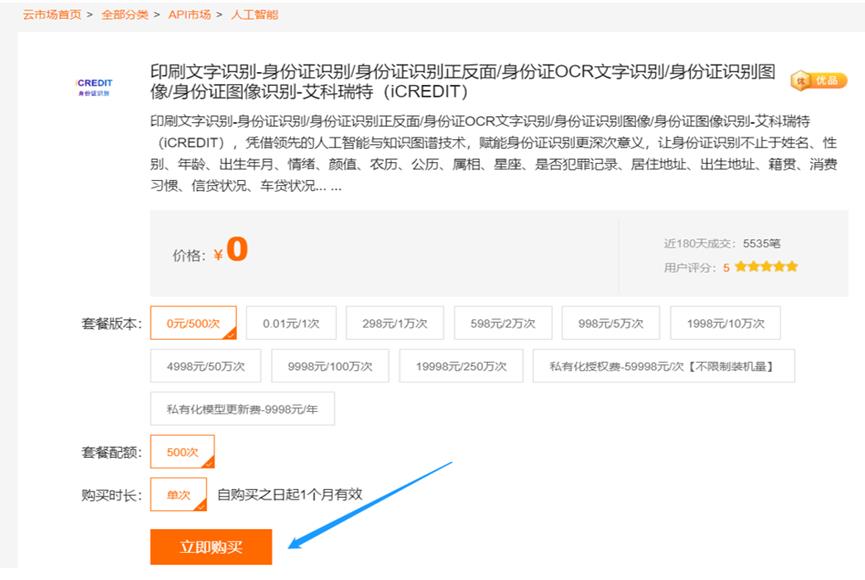
步骤四:点击立即购买。
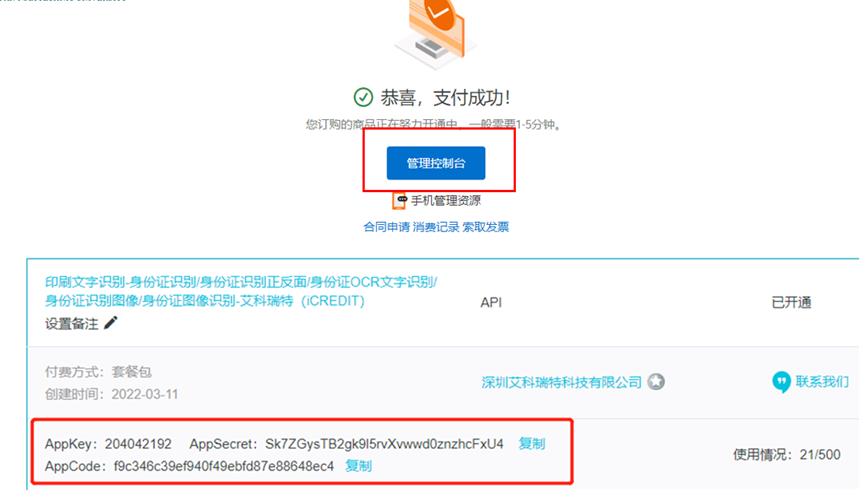
步骤五:购买成功后点击管理控制台,就可以查看到身份证识别的AppCode等信息。
4. 代码解析
4.1导入库
#导入所需的库
import urllib.request # 打开和读取 URL
import base64 # 用于传输8Bit字节码的编码方式
Urllib 库是 Python 内置的 HTTP 请求库,可用于访问网页,并且与网页交互,不需要额外安装就可使用,它包含四个模块:
▪ urllib.request:最基本的 HTTP 请求模块,打开和读取URL,可以用它来模拟发送请求;就像在浏览器里输入网址后敲击回车一样。
▪ urllib.error:异常处理模块,如果出现请求错误,可以捕获这些异常,然后进行重试或其他操作保证程序不会意外终止。
▪ urllib.parse :一个工具模块,提供了许多 URL 处理方法,比如拆分、解析、合并等。
▪ urllib.robotparser :用来识别网站的 robots.txt 文件,用的比较少。
Base64库是网络上最常见的用于传输字节码的编码方式之一,一般用于在HTTP协议下传输二进制数据,由于HTTP协议是文本协议,所以在HTTP协议下传输二进制数据需要将二进制数据转换为字符数据。然而,不能直接将二进制数据转换成字符数据,因为网络传输只能传输可打印字符。在ASCII码中规定, 32~126这95个字符属于可打印字符,也就是说网络只能传输这95个字符,不在这个范围内的字符无法传输。其他字符的传输方式就可以通过使用Base64。
URL:网络上的每一个网页都具有一个唯一的名称标识,通常称之为URL(Uniform Resource Locator, 统一资源定位器)。简单地说URL就是网络地址,俗称“网址”。
一般语法格式为:protocol : // hostname[:port] / path / [;parameters][?query]#fragment
Protocol(协议):指定使用的传输协议,最常用的是HTTP协议,格式为HTTP://。
Hostname(主机名):指存放资源的服务器的域名系统主机名或IP地址。
Path(路径):一般用来表示主机上的一个目录或文件地址。
4.2 API产品路径及阿里云APPCODE
#API产品路径
host = 'https://personcard.market.alicloudapi.com'
path = '/ai-market/ocr/personid'
#阿里云APPCODE
appcode = 'f9c346c39ef940f49ebfd87e88648ec4'
url = host + path
bodys =
querys = ""
4.3 读入数据、参数配置和转换编码
#参数配置
#启用BASE64编码方式进行识别
#内容数据类型是BASE64编码
f = open(r'C:\\Users\\MengLiPing\\Pictures\\ketizu\\8.jpg', 'rb') # rb表示以二进制方法读入图片的内容
#将读取到的图片信息编码为可显示的二进制文本信息,读到的是信息是二进制类型,用base64转换成二进制
contents = base64.b64encode(f.read())
print('contents')
f.close() # 读入文件后要记得关闭
#输入图像的参数信息
bodys['AI_IDCARD_IMAGE'] = contents
bodys['AI_IDCARD_IMAGE_TYPE'] = '0'
bodys['AI_IDCARD_SIDE'] = 'BACK'
#编码工作使用urllib的parse.urlencode()函数,帮我们将key:value这样的键值对转换成"key=value"这样的字符串
#因为bodys中存的是字典,所以需要先用 urllib.parse.urlencode() 编码
post_data = urllib.parse.urlencode(bodys).encode('utf-8') # encode() 方法以指定的编码格式编码字符串,默认编码为 ‘utf-8’。
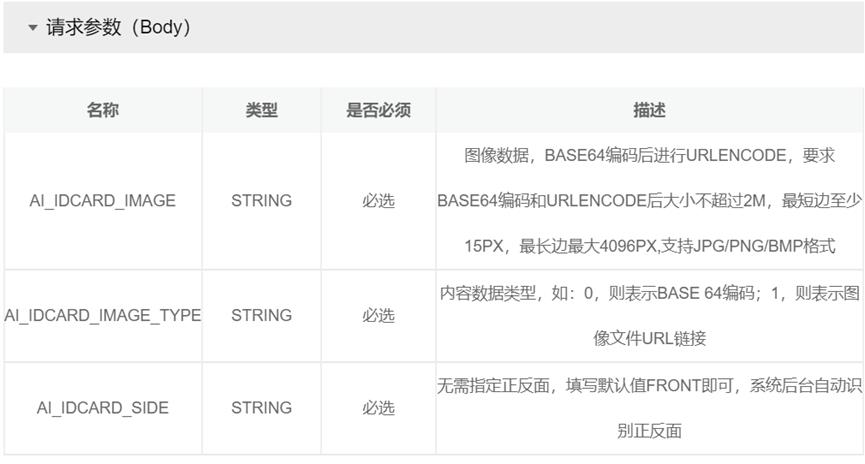
4.4 调用API
request = urllib.request.Request(url, post_data) # 打开和读取 URL,传入的数据类型必须是二进制byte
#实名认证接口
request.add_header('Authorization', 'APPCODE ' + appcode)
#根据API的要求,定义相对应的Content-Type
request.add_header('Content-Type', 'application/x-www-form-urlencoded; charset=UTF-8')
response = urllib.request.urlopen(request)
content = response.read()
if (content):
print(content.decode('utf-8'))
4.5 代码返回值


4.6 实验结果


5. 完整代码
#导入所需的库
import urllib.request # 打开和读取 URL
import base64 # 用于传输8Bit字节码的编码方式
#API产品路径
host = 'https://personcard.market.alicloudapi.com'
path = '/ai-market/ocr/personid'
#阿里云APPCODE
appcode = 'f9c346c39ef940f49ebfd87e88648ec4'
url = host + path
bodys =
querys = ""
#参数配置
#启用BASE64编码方式进行识别
#内容数据类型是BASE64编码
f = open(r'C:\\Users\\MengLiPing\\Pictures\\ketizu\\8.jpg', 'rb') # rb表示以二进制方法读入图片的内容
#将读取到的图片信息编码为可显示的二进制文本信息,读到的是信息是二进制类型,用base64转换成二进制
contents = base64.b64encode(f.read())
print('contents')
f.close() # 读入文件后要记得关闭
#输入图像的参数信息
bodys['AI_IDCARD_IMAGE'] = contents
bodys['AI_IDCARD_IMAGE_TYPE'] = '0'
bodys['AI_IDCARD_SIDE'] = 'BACK'
#编码工作使用urllib的parse.urlencode()函数,帮我们将key:value这样的键值对转换成"key=value"这样的字符串
#因为bodys中存的是字典,所以需要先用 urllib.parse.urlencode() 编码
post_data = urllib.parse.urlencode(bodys).encode('utf-8') # encode() 方法以指定的编码格式编码字符串,默认编码为 ‘utf-8’。
request = urllib.request.Request(url, post_data) # 打开和读取 URL,传入的数据类型必须是二进制byte
#实名认证接口
request.add_header('Authorization', 'APPCODE ' + appcode)
#根据API的要求,定义相对应的Content-Type
request.add_header('Content-Type', 'application/x-www-form-urlencoded; charset=UTF-8')
response = urllib.request.urlopen(request)
content = response.read()
if (content):
print(content.decode('utf-8'))
以上是关于Python使用阿里API进行身份证识别的主要内容,如果未能解决你的问题,请参考以下文章