SPARK统计信息的来源-通过优化规则来分析
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SPARK统计信息的来源-通过优化规则来分析相关的知识,希望对你有一定的参考价值。
背景
此文的分析基于spark 3.1.2
且set spark.sql.catalogImplementation = hive 且表是分区的情况下
在之前翻译的文章Spark SQL explaind中的统计信息-深入了解CBO优化里,我们说到,如果一个hive表是分区的,没有开启CBO,没有进行ATC,那么该逻辑计划的sizeInBytes就是8EB。其实这是不对的。我来分析一下。
分析
就如前面的图所示:
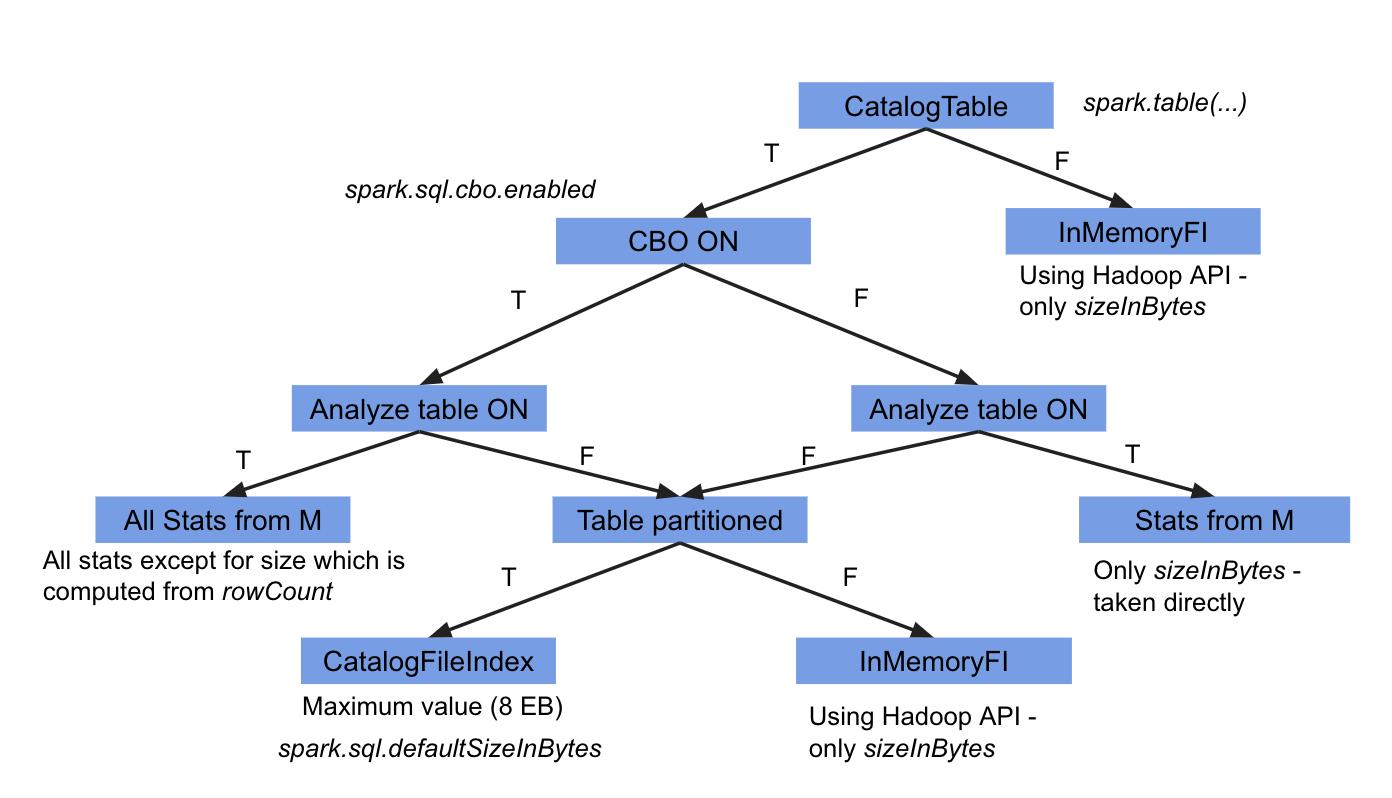
这只是一个大概的流程,在spark的实现中,是有细微的区别的(至少在spark 3.1.2是不一样的)。
我们运行,之前SPARK SQL中 CTE(with表达式)会影响性能么?提到的sql,我们就会发现该sql会进行如下的规则(只列举relation及统计信息的部分):
经过ResolveRelations规则(代码比较简单,不做解释):
UnresolvedRelation
||
\\/
UnresolvedCatalogRelation(CatalogTable)
经过FindDataSourceTable规则(代码比较简单,不做解释):
UnresolvedCatalogRelation(CatalogTable)
||
\\/
HiveTableRelation(CatalogTable)
经过DetermineTableStats规则(增加统计信息sizeInBytes):
HiveTableRelation(CatalogTable)
||
\\/
HiveTableRelation(tableStats=Some(Statistics(sizeInBytes = BigInt(sizeInBytes))))
这部分代码如下:
private def hiveTableWithStats(relation: HiveTableRelation): HiveTableRelation =
val table = relation.tableMeta
val partitionCols = relation.partitionCols
// For partitioned tables, the partition directory may be outside of the table directory.
// Which is expensive to get table size. Please see how we implemented it in the AnalyzeTable.
val sizeInBytes = if (conf.fallBackToHdfsForStatsEnabled && partitionCols.isEmpty)
try
val hadoopConf = session.sessionState.newHadoopConf()
val tablePath = new Path(table.location)
val fs: FileSystem = tablePath.getFileSystem(hadoopConf)
fs.getContentSummary(tablePath).getLength
catch
case e: IOException =>
logWarning("Failed to get table size from HDFS.", e)
conf.defaultSizeInBytes
else
conf.defaultSizeInBytes
val stats = Some(Statistics(sizeInBytes = BigInt(sizeInBytes)))
relation.copy(tableStats = stats)
也就是说如果hive表如果是非分区的话,而且开启了spark.sql.statistics.fallBackToHdfs(默认是关闭),
就会从hdfs获取统计信息。
如果是分区表的话,直接默认为Long.MaxValue。
经过RelationConversions规则:
HiveTableRelation(tableStats=Some(Statistics(sizeInBytes = BigInt(sizeInBytes))))
||
\\/
LogicalRelation(HadoopFsRelation(CatalogFileIndex(sizeInBytes)))
其中sizeInBytes是HiveTableRelation的LogicalPlanVisitor 计算出来的sizeInBytes
这个规则主要是把元数据的relation 转换成基于source的relation,这会提高性能。
因为后续的规则,会基于relation做进一步的优化,比如分区下推filter。
经过PruneFileSourcePartitions规则:
LogicalRelation(HadoopFsRelation(CatalogFileIndex()))
||
\\/
LogicalRelation(HadoopFsRelation(InMemoryFileIndex(partitionSpec,sizeInBytes=allFiles().map(_.getLen).sum)))
该规则主要是针对LogicalRelation把CatalogFileIndex转换为InMemoryFileIndex,InMemoryFileIndex这里就包括了用户指定分区的路径,以及sizeInBytes,
这就是在SPARK UI 为什么能看到scan的数据明细,而且sizeInBytes在后续做优化判断的时候,具有很好的指导意义。
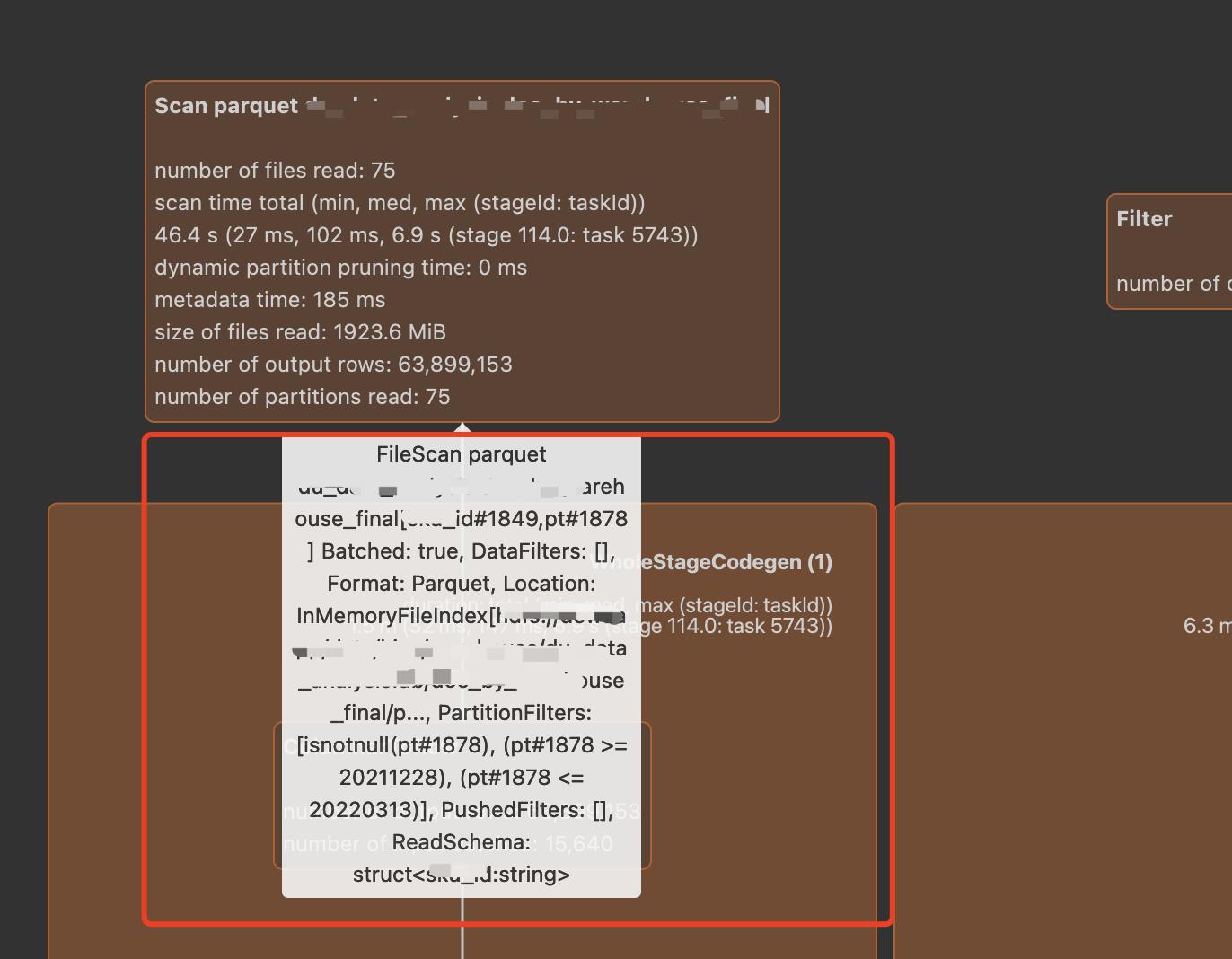
再结合visit,就可以知道统计信息的来源了,代码如下:
trait LogicalPlanStats self: LogicalPlan =>
/**
* Returns the estimated statistics for the current logical plan node. Under the hood, this
* method caches the return value, which is computed based on the configuration passed in the
* first time. If the configuration changes, the cache can be invalidated by calling
* [[invalidateStatsCache()]].
*/
def stats: Statistics = statsCache.getOrElse
if (conf.cboEnabled)
statsCache = Option(BasicStatsPlanVisitor.visit(self))
else
statsCache = Option(SizeInBytesOnlyStatsPlanVisitor.visit(self))
statsCache.get
结论
其中最重要的规则还是DetermineTableStats RelationConversions和PruneFileSourcePartitions。它们把基于元数据的relatoin转换成基于datasource的relation,这样我们能够在datasource上做更进一步的分析和优化。
当然具体的case还是得具体分析。
以上是关于SPARK统计信息的来源-通过优化规则来分析的主要内容,如果未能解决你的问题,请参考以下文章