使用 Thanos 实现多集群(租户)监控
Posted 格格巫 MMQ!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Thanos 实现多集群(租户)监控相关的知识,希望对你有一定的参考价值。
Thanos 已成为目前 Kubernetes 集群监控的标准解决方案之一。它基于 Prometheus 之上,可以为我们提供:
全局的指标查询视图
近乎无限的数据保留期限
包含 Prometheus 在内所有组件的高可用性
在拟定监控方案之前,阅读一些成熟的 用户案例 是十分必要的。这些博文首先分析了各自团队的集群现状以及当前监控方案难以解决的痛点,再对目前流行的几种技术栈进行对比,最后介绍投入生产使用的部署方案,因此非常值得一读。
不过,由于 Thanos 的组件众多,且每种组件都有较多参数需要配置。对于刚接触 Thanos 的用户来说,可能难以快速上手。考虑到上述博文均未给出组件的具体配置信息,而官方提供的 部署清单 又稍显复杂并缺少详细说明。因此本文将介绍一个使用 Thanos 实现多集群(租户)监控的简单 Demo,希望能对试图尝鲜 Thanos 的用户有所帮助。它实现了以下功能:
能够监控多个集群,并提供一个全局的指标查询视图;
每个集群都对应了一个唯一的租户 ID,可以通过租户标签区分不同集群的指标数据;
如果某个租户创建了新的集群,只需在新集群中部署 Prometheus 并配置远程写入;
简单的告警规则和告警消息推送。
Sidecar vs. Receiver#
Thanos 支持 Sidecar 和 Receiver 两种部署模式。它们各有利弊,需要我们根据实际情况进行取舍。
Sidecar 通常每隔 2 小时才会把 Prometheus 采集到的指标上传到对象存储中,因此 Query 查询近期数据时需要向所有 Sidecar 发起请求并合并返回结果。但这并非是 Thanos 团队引入 Receiver 的决定性因素。
Receiver is only recommended for uses for whom pushing is the only viable solution, for example, analytics use cases or cases where the data ingestion must be client initiated, such as software as a service type environments.
按照文档中的说法,Receiver 只推荐用于多租户以及 Prometheus 配置受限的场景下,比如:
租户使用某些 SaaS 服务对集群进行监控,如 Openshift Operator 部署的 Prometheus;
由于安全或权限问题,监控团队无法在被监控集群中配置 Sidecar;
被监控集群部署的是非容器化部署的 Prometheus。
这是因为 Receiver 会暂存多个 Prometheus 实例的 TSDB,当数据量较大时可能会发生 OOM。另外根据 官方文档,开启远程写入还将增加 Prometheus 约 25% 的内存使用。
我们并非一定要在 Receiver 和 Sidecar 之间做出抉择,比如 Lastpass 就采用了 Sidecar 与 Receiver 混合部署的方式:
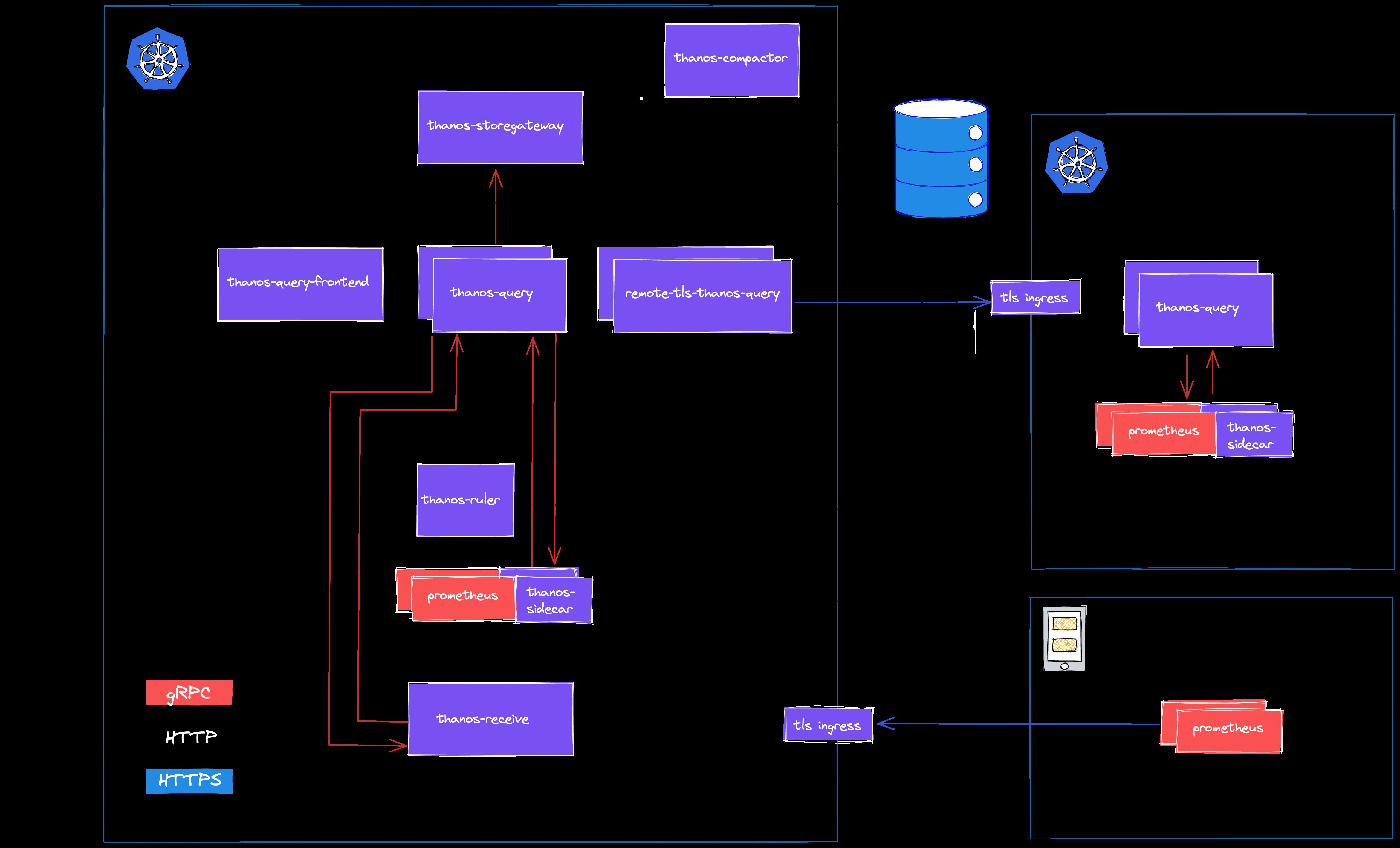
由于我们的 Demo 优先考虑实现的简单性以及对多租户的支持,对资源占用和性能的要求并不高,因此决定选用 Receiver 模式。
快速开始#
Thanos 版本:v0.24.0
Kubernetes 版本:v1.16.9-aliyun.1
环境:阿里云 ACK
git clone https://github.com/koktlzz/thanos-k8s-deployment.git
cd thanos-k8s-deployment
kubectl apply -k overlays/aliclound/
部署 Prometheus#
git clone https://github.com/coreos/kube-prometheus.git
cd kube-prometheus
kubectl create -f manifests/setup
wait for namespaces and CRDs to become available, then
kubectl create -f manifests/
在国内环境拉取 k8s.gcr.io 上的镜像可能会失败,需要将镜像名称改为 bitnami/kube-state-metrics:2.3.0 和 willdockerhub/prometheus-adapter:v0.9.0。
为 Prometheus 实例配置远程写入#
使用 kubectl edit -n monitoring prometheus k8s命令开启 Prometheus 的远程写入:
local cluster
spec:
remoteWrite:
- url: http://thanos-receiver.thanos.svc.cluster.local:19291/api/v1/receive
cluster kazusa
spec:
remoteWrite:
- url: http://thanos-receiver.uuid.cn-shanghai.alicontainer.com/api/v1/receive
headers:
THANOS-TENANT: kazusa
cluster setsuna
spec:
remoteWrite:
- url: http://thanos-receiver.uuid.cn-shanghai.alicontainer.com/api/v1/receive
headers:
THANOS-TENANT: setsuna
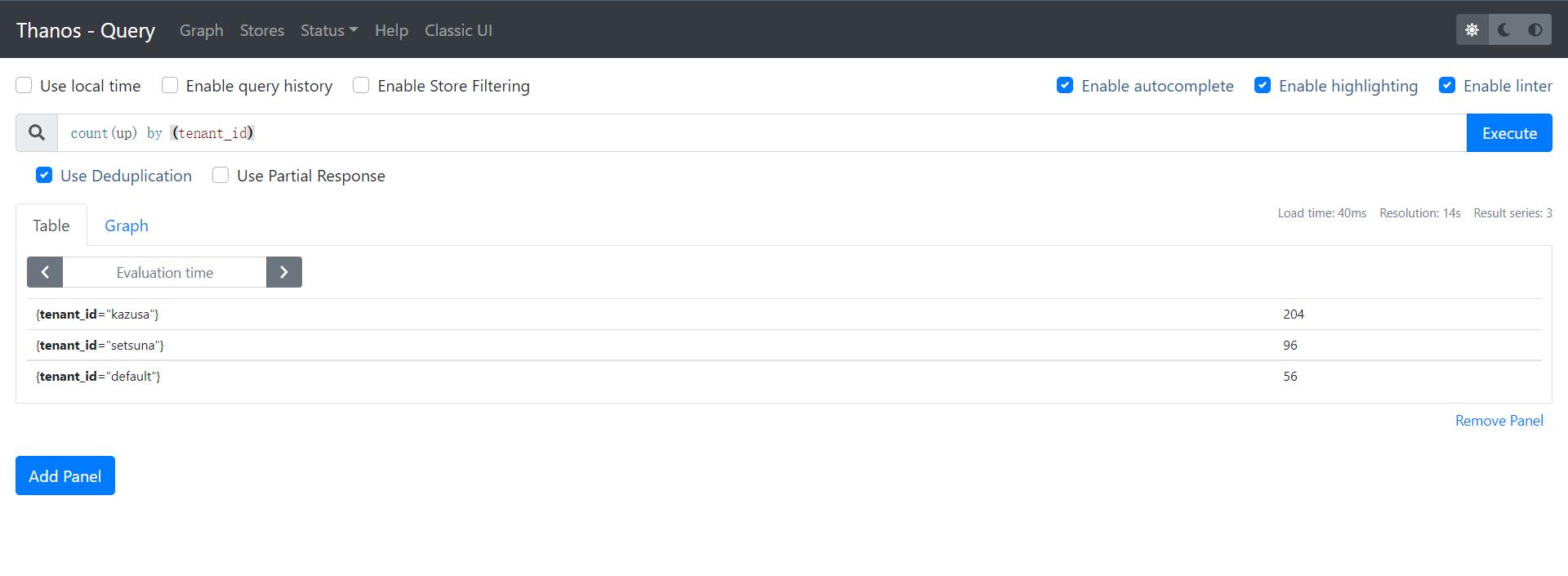
一段时间后将在 Query UI(kubectl get ingresses -n thanos | grep querier)中看到三个集群(租户)的实例:

架构说明#
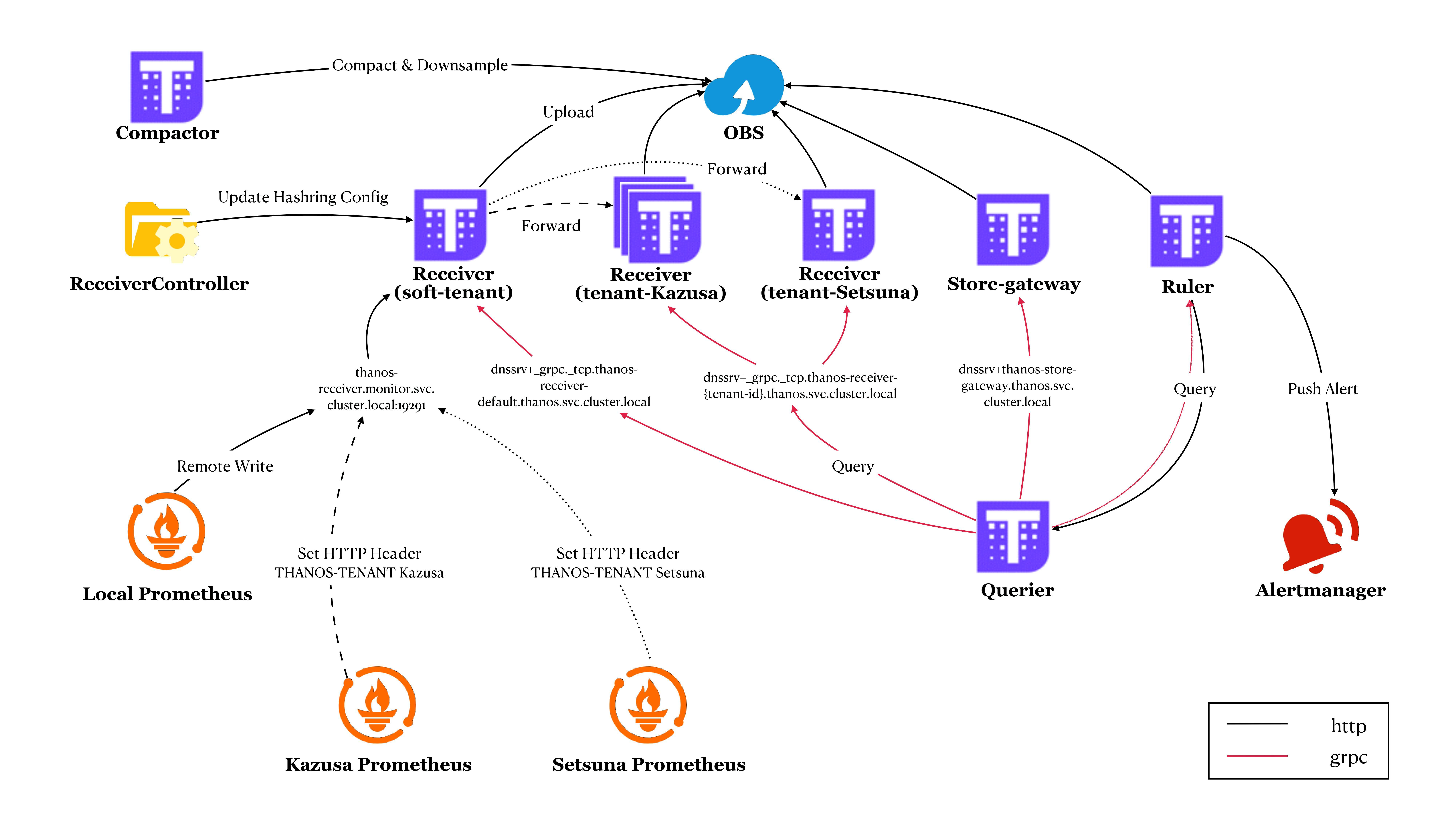
指标数据流向#
如上图所示,监控集群(Local)以及两个外部集群(Kazusa 和 Setsuna)中的 Prometheus 均将指标数据写入到软租户(soft-tenant)的 Receiver 中。而由于 Kazusa 和 Setsuna 的 Prometheus 还在远程写入中配置了 HTTP 头部,因此软租户 Receiver 会根据其中的租户 ID 将其转发到对应的硬租户 Receiver 中。
我们可以在 Receiver 容器挂载的 Hashring 配置文件中找到每个租户 Receiver 的 endpoints:
[root@master1 thanos]# kubectl exec -n thanos thanos-receiver-default-0 – cat /etc/prometheus/hashring-config/hashrings.json | jq
[
“hashring”: “hashring-setsuna”,
“tenants”: [
“setsuna”
],
“endpoints”: [
“thanos-receiver-setsuna-0.thanos-receiver-setsuna.thanos.svc.cluster.local:10901”
]
,
“hashring”: “hashring-kazusa”,
“tenants”: [
“kazusa”
],
“endpoints”: [
“thanos-receiver-kazusa-0.thanos-receiver-kazusa.thanos.svc.cluster.local:10901”,
“thanos-receiver-kazusa-1.thanos-receiver-kazusa.thanos.svc.cluster.local:10901”,
“thanos-receiver-kazusa-2.thanos-receiver-kazusa.thanos.svc.cluster.local:10901”
]
,
“hashring”: “default”,
“endpoints”: [
“thanos-receiver-default-0.thanos-receiver-default.thanos.svc.cluster.local:10901”
]
]
实际上该文件来自于 Configmap thanos-receiver-hashring-generated-config,它是由 Thanos-Receive-Controller 读取当前集群中的 Receiver 实例并根据 Configmap thanos-receiver-hashring-config 动态生成的。
Receiver 使用一致性哈希作为数据分发策略的原因详见:Thanos Receiver - why does it need consistent hashing?
Receiver 的可扩展性和高可用性#
假设 Kazusa 集群中的工作负载比较多,其指标数据量也比较大。为了防止接收 Kazusa 集群指标数据的 Receiver 发生 OOM,我们增加其 Statefulset 的 副本数。
上一节提到,指标数据是软租户 Receiver 根据 Hashring 配置分发到硬租户 Receiver 的。这意味着即使我们将 Kazusa 的 Receiver 扩展到三个,数据也不会在某台 Receiver 宕机后分发到其他可用的 Receiver 中。因此我们还要为数据设置 副本,从而实现高可用。Receiver 的副本包含 receiver_replica 标签,Query 可以根据它来对数据 去重。
关于 Receiver 的可扩展性和高可用性,详见 Turn It Up to a Million: Ingesting Millions of Metrics with Thanos Receive.
Headless Service#
我们为每个租户的 Receiver 都创建了各自的 Headless Service,这样 Query 就可以通过 DNS 的 SRV 记录动态发现所有的 Receiver 实例:
- –store=dnssrv+_grpc._tcp.thanos-receiver-default.thanos.svc.cluster.local
- –store=dnssrv+_grpc._tcp.thanos-receiver-kazusa.thanos.svc.cluster.local
- –store=dnssrv+_grpc._tcp.thanos-receiver-setsuna.thanos.svc.cluster.local
如果将其改为 ClusterIP 类型,Store API 的 grpc 请求将通过轮询发往其中一台 Receiver 实例。这样在 Query UI 中就只能看到一台 Kazusa Receiver:

值得注意的是,用于处理指标数据的写入请求的 Service 是 ClusterIP 类型的。
Future Work#
本文介绍的 Demo 仅供读者参考,若想要将其投入生产使用,还需要考虑以下方面:
为软租户的 Receiver 配置 TLS 证书校验;
上文提到,开启远程写入将增加 Prometheus 的内存使用,我们应当根据 文档 中的建议对其参数进行调优;
持久化 Compactor 和 Storegateway 的数据目录可以减少其重启时间,存储空间的大小可以参考 Slack 中的 讨论;
部署前根据指标数据量评估 Receiver 的 Request、Limit 以及副本数,防止其因数据量过大而导致 OOM;
此 Demo 使用 Ruler 进行全局告警,可能因查询超时而发生 报警失效。
以上是关于使用 Thanos 实现多集群(租户)监控的主要内容,如果未能解决你的问题,请参考以下文章