IPU(Image Processing Unit )
Posted 四季帆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IPU(Image Processing Unit )相关的知识,希望对你有一定的参考价值。
Chapter 38 Image Processing Unit (IPU)
38.1 概述
IPU计划成为应用程序处理器中的视频和图形子系统的一部分。
IPU的目标是为从图像传感器和/或到显示设备的数据流提供全面支持。这项支助包括这些活动的所有方面:
连接到相关设备-摄像机,显示器,图形加速器,电视编码器和解码器。
相关图像处理与操作:传感器图像信号处理、显示处理、图像转换等。
同步和控制功能(以避免撕裂工件)。
这种综合方法带来了几个显著的优势:
自动化:减少了单片机(主控单元)对图像管理的介入。特别是,显示刷新/更新和摄像头预览(显示来自图像传感器的输入)可以完全自主地执行。由此带来的好处是减少了由于SW-HW同步带来的开销,释放了MCU去执行其他任务,并降低了功耗(当MCU空闲时,可以关机)。
最优数据路径:最小化对系统内存的访问。特别是,当从图像传感器接收数据和/或向显示器发送数据时,可以实时执行重要的处理。系统内存基本上只在需要改变像素顺序或帧率时使用。由此产生的好处是减少了系统总线上的负载,并进一步降低了功耗。
资源共享:最大限度的重用HW为了不同的应用程序,从而以最少的硬件支持广泛的需求。
上面提到的HW重用是通过每个HW块的复杂配置来实现的。这种可配置性还允许支持广泛的外部设备、数据格式和操作模式。由此产生的灵活性也很重要,因为支持需求正在发生重大变化,因此需要预测和解释预期的未来变化。
在选择IPU提供的支持时,遵循了以下进一步的原则:
对于需要HW支持(加速或低功耗)的关键应用程序,提供最佳支持(实现最佳实现)。
对于可以从HW中受益的其他应用程序,请考虑进行较小的修改/扩展以支持它们的成本和收益。
对于所有其他相关应用程序(将由SW支持),验证它们的支持没有降级。
只要有可能,就让操作系统(及其窗口系统)在没有IPU的情况下工作。
38.1.1 架构
在这里可以找到一个简化的IPU框图。在IPU中描述了每个区块的作用。
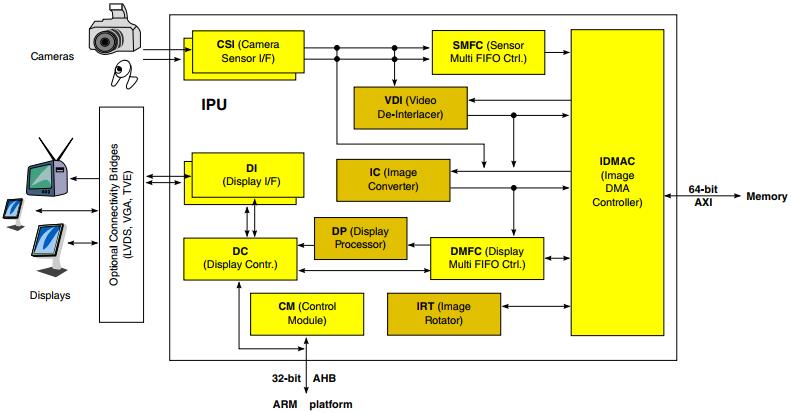
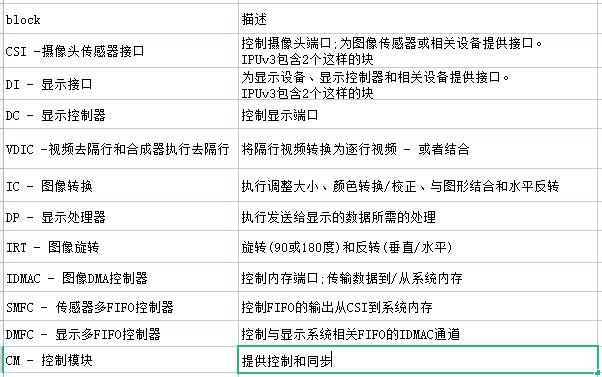
各个区块的作用如下:
38.1.2 特性和功能
38.1.2.1 外部端口
IPU有以下接口:|
两个摄像头端口 - 每个由CSI子块控制,提供与图像传感器和相关设备的连接。
两个显示端口 - 每个由DI子块控制,提供与显示器和相关设备的连接。
内存端口 - AXI (AHB V3.0)主,由IDMAC控制-提供与系统内存的连接。
AHB - lite从端口,提供与ARM平台的连接(以及与任何其他连接到ARM的横条开关的主端口)。
用于控制和调试的附加端口。
38.1.2.1.1 摄像头端口
这些端口的作用是接收来自视频源(例如图像传感器)的输入,并为相机的时间敏感控制信号提供支持。(非时间敏感的控制-例如配置,复位-由MCU通过I2C I/F或GPIO信号执行)。
每个摄像头接口包括以下特点:
直接连接到大多数相关的图像传感器和电视解码器。
接口类型
并行接口
多达20位输入数据总线。
除了下表(注释列)中列出的特殊情况外,每个循环中只有一个值。
可编程的极性。
高速串行接口- MIPI(移动工业处理器接口)CSI-2 摄像头串行接口(部分在IPU中实现,部分在HSC中实现)。
多达四个数据通道;每通道高达800mbps
Class 1遵从性(支持所有主要格式)
数据格式
交错颜色组件,每个值(组件)高达16位。
支持的格式如下表所示。
扫描顺序:逐行或交错的数据(只期望YUV 4:2:2)被直接发送到系统内存,在那里它可以读回进一步处理。
帧大小:高达8192 x 4096像素
同步:视频模式
该传感器是像素时钟(PIXCLK)和同步信号的主人
使用以下任一方法接收同步信号:
专用控制信号-垂直同步,HSYNC -可编程脉冲宽度和极性
控制嵌入在数据流中,松散地遵循BT.656协议,具有代码值和位置的灵活性。
同步:静态图像捕捉
图像捕捉由ARM平台或外部信号(如机械快门)触发。
同步闪光灯产生多达6个输出-传感器和相机外围设备(如闪光灯,机械快门)。
附加功能
通过周期性跳过帧来降低帧率
支持的折减比为:m:n,其中m,n<=5
这是独立支持的不同目的地- IC, SMFC。
Window-of-interest选择
预闪光-用于减少红眼和在弱光条件下测量(如聚焦) 多个传感器可以连接到每个CSIs。同时支持的功能(发送数据)如下:
两个传感器可以独立发送数据,每个通过不同的端口,每个使用并行或快速串行接口。
多个传感器可以发送数据到同一个端口,使用MIPI接口(通过一个HUB),每个传感器由不同的ID标识。
最多可提供两种流(或两种流)的拆封和压缩功能通过相同或不同的接口),而其他数据则被视为通用数据。
只有一个(非通用)流可以传输到VDIC或IC进行实时处理,而其他流直接发送到系统内存。摄像头接口支持的输入速率如下:
对于并行接口,接口的最大速度为240Mhz。接口所需的工作频率计算方法如下:
F = FH * FW * FPS * BI * DF
FH = frame height (in pixels)
FW = Frame width (in pixels)
fps = frame rate (frames per second)
BI = 通常35%的开销应该假定为1.35。实际空白间隔是所附装置的参数。
DF = 数据格式,定义发送单个像素所需的周期数。发送单个像素所需的周期数取决于接口和数据格式。
数据格式示例:
YUV422 over 16 bit = 1 cycle/pixel
RGB888 over 8 bit = 3 cycles/pixel
RGB565 over 16 bit = 1 cycle/pixel
Bayer/Generic data = 1 cycle/pixel
YUV422 over 8 bit = 2 cycles/pixel
BT.656, YUV422 format = 2 cycles/pixel
BT.1120, YUV422 format = 1 cycle/pixel 支持的接口示例:
3.2MP camera, 15fps, yuv422 format, 8 bit interface
1080P30, yuv422, 8 bit interface
快速串行接口(MIPI-CSI2):
IPU每个周期从MIPI-CSI2接口接收2个组件
界面的最大速度为:
200Mhz用于4个数据通道配置
2个数据通道配置250Mhz接口的最大带宽为:
200Mhz for 4 data lanes configuration (800Mbps/lane, 400MByte/sec)
187.5Mhz for 3 data lanes configuration (1000Mbps/lane, 375MByte/sec)
125Mhz for 2 data lanes configuration (1000Mbps/lane, 250MByte/sec )
62.5Mhz for 1 data lane configuration (1000Mbps/lane, 125Mbyte/sec) 接口所需的工作频率计算方法与上述并行接口相同。DF参数不同。
YUV422 = 1 cycle/pixel
RGB888 = 1.5 cycles/pixel
Generic data = 2 bytes/pixel
支持的接口示例:
3.2MP camera, 2 lanes configuration, 15fps, yuv422 format (~65Mhz)
6MP camera, 4 lanes configuration, 15fps, RGB888 format (~182Mhz)
38.1.2.1.2 显示端口
这些端口的作用是直接或通过控制器(如图形加速器)或桥接器(如电视编码器或LVDS接口桥接器)与显示设备通信。
38.1.2.1.2.1 访问模式
支持两种访问方式。
38.1.2.1.2.1.1 同步访问
在这种模式下,IPU向显示设备传输一个二维像素块,与屏幕刷新周期同步。
在MIPI标准中称为“视频模式”。
该模式具有双重作用:
对于没有ram的显示器或电视屏幕,此模式用于从系统内存中的显示缓冲区执行屏幕刷新过程。
对于“智能”显示器,这种模式用于将矩形像素块转移到显示器的屏幕上,在某些情况下,也转移到显示缓冲区
传输的块可能只是屏幕的一部分(屏幕的其余部分由集成控制器从内部缓冲区刷新)。此外,掩码可用于将块的部分转移到显示,例如被其他窗口部分隐藏的窗口。
如果块只转移到屏幕上,则转:速率必须等于刷新率。然而,如果传输也到显示器的内存,则速率可以降低到输入缓冲区更新的速率。 在所有情况下(包括最后一个),IPU向显示屏发送所有控制屏幕刷新的同步信号,块传输与这些信号同步。这种同步意味着在使用此模式时避免了撕裂效果。
38.1.2.1.2.1.2 异步访问
这是用于与外部显示控制器(可能在智能显示器或图形加速器中)通信的主要模式。
在MIPI标准中称为“命令模式”。在此模式下,IPU对控制器的内存和寄存器进行随机读写。
支持两种类型的寻址方法
泛型线性寻址像素和泛型数据
像素的二维(X/Y)寻址
提供了以下访问类型:
在IPU中进行实时处理后,将数据传输到外部设备。
数据传输(DMA) -读/写-在主机的系统内存和外部设备之间,通过IPU的内存端口(由IDMAC控制),例如一个矩形像素块(可能是全屏)的传输。
主机访问-读/写-到外部设备,通过AHB-slave端口
访问类型
直接访问 - 模拟直接寻址访问(见下面)这包括突发访问(增量;最多8个单词/突发)
底层访问 - 将显式生成访问协议的任务留给主机
可能的访问模块包括ARM平台和系统DMA控制器(以及任何其他AHB主连接到ARM的交叉条开关)。 将视频/图形数据流传输到控制器的显示缓冲区使用上述前两种模式之一。与同步模式不同,此过程与屏幕刷新周期不是紧密同步的。然而,松散的同步 - 为了避免撕裂 - 仍然是可能的:适当的传输时间可以从屏幕刷新的垂直同步信号中得到 - 要么由IPU的显示控制器产生,要么由外部控制器接收。
异步访问需要指定一个地址。显示界面使用“间接寻址”,即没有地址总线,地址以及控制和配置命令都嵌入到数据流中。访问过程 - 包括写地址和命令 - 由接口自主管理,方式有两种:
自动模拟透明访问,遵循ARM平台生成的微码(“访问模板”)。这种机制非常灵活,支持各种各样的设备。
从(由ARM平台)存储在系统内存中的缓冲区流命令/地址。
请注意,直接访问需要使用第一种方法 - 自动模拟。
38.1.2.1.2.2 显示接口
显示接口非常灵活,支持主要制造商的各种设备。提供了以下接口类型(在两个显示端口中)。
并行视频接口(用于同步访问)-高达24位数据总线。
兼容MIPI-DPI标准。
控制协议-遵循Sharp HR和通用TFT定义
支持BT.656(8位)和BT.1120(16位)协议
支持HDTV标准SMPTE274 (1080i/p)和SMPTE296 (720p)
并行双向总线接口(用于异步访问)- 32位数据总线。
兼容MIPI-DPI标准。
控制协议-无论是系统80或系统68k信号的时间和极性是可编程的。
Byte-enable - 可选,用于16位接口
突发访问对于直接访问,突发是由AHB接口中相应的信号决定的。
串行接口 - 3线、4线和5线(两种类型)(用于异步访问)
高速串行接口: MIPI(移动工业处理器接口)- DSI(显示串行接口)全力支持,多达2个数据通道,多达4个虚拟通道(在IPU中实现,部分在HSC中实现)。 支持的像素数据格式有:
RGB - 颜色深度完全可配置;高达8位/值(颜色分量)
YUV 4:2:2, 8位/值(用于电视编码器)
MIPI的DBI, DPI和DSI的所有强制格式。
在并行接口中,数据总线最多有32位。像素到总线的非平凡映射被限制为24 LSB。这种映射是完全可配置的,非常灵活。在串行接口中,数据以与并行接口相同的方式映射,然后进行串行化。
该接口还支持“通用数据”。这样的数据在系统存储器和显示设备之间(通过串行接口或8/16位并行接口)逐字节地传输,而不需要修改。可以将非传统像素格式视为“通用数据”来支持它们。
对于接口时钟,有以下选项(对于每个端口独立):
来源于IPU内部时钟(主模式)
由外部源提供(从模式)
支持的传输速率【对于单端口(片上接口)】:
240兆访问/秒如果DI时钟来自外部到IPU源(如另一个PLL)
如果DI时钟来自IPU时钟(HSP_CLK),则是264兆次/秒
当涉及芯片外接口时,速率可能受到IO能力的限制。具体数字请参阅设备的数据表。
对于一个周期/像素的同步访问,这使得,例如(包括35%的下料间隔)
1080p (1920x1080) @ 60 fps
WSXGA+ (1680x1050) @ 60 fps
两个端口的合并速率高达240mp /sec
该界面包括以下附加功能:
屏幕尺寸:高达4096 x 2048像素,可由软件编程。
扫描顺序:连续或交错
同步:
可编程水平和垂直同步输出信号(用于同步接入)
数据使能输出信号
采用8位可编程脉宽调制(PWM)的软件对比度控制
提供两个专用的PWM输出 连接到显示设备
IPU可以连接多个显示设备。特别地,它支持以下设置:
主要液晶显示器;智能、哑(RAM-less)或双端口;可以使用快速串行,或并行接口或(通过集成桥)LVDS接口。
第二个液晶显示器;智能、哑(RAM-less);可以使用快速串行、并行或串行接口或(通过集成桥)LVDS接口。
上面的每一个连接都有独立的设置-接口定时、访问模板、片选等。
以上设备的同时功能可以通过以下方式实现:
可以(同步或异步)独立地访问两个设备,每个设备都通过一个不同的端口:每个设备都使用任何可用的接口。
两个设备可以通过传统的串行和并行接口,使用CS信号分时异步访问。
可以同步或异步地通过同一个端口访问两个设备,使用MIPI接口(通过HUB),每个设备由不同的ID标识。
异步访问可以在同步访问的垂直删除间隔期间执行(屏幕刷新;到同一设备或其他设备)。
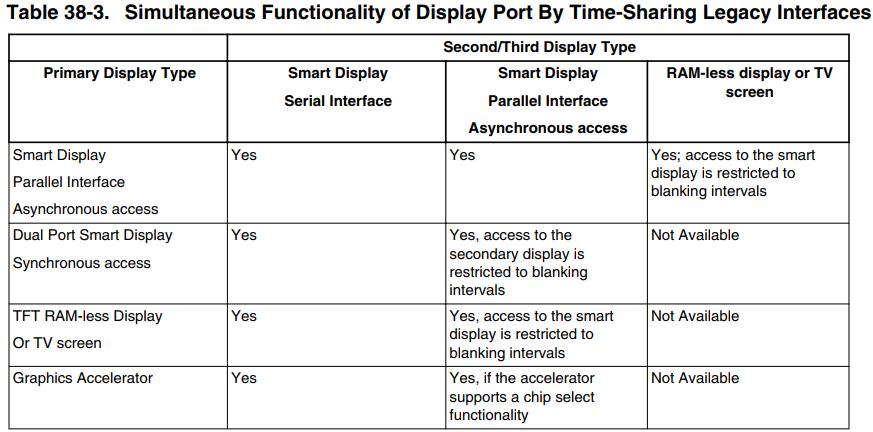
下表总结了通过在单个端口中分时使用遗留接口来实现同步功能的可能性。
38.1.2.1.3 内存端口
内存端口是一个AXI (AHB V3.0)主端口,用于从系统内存读取/写入数据 - 通常是二维块。
该接口支持以下特性:
像素格式被翻译成/从一个统一的内部格式:RGBA/YUVA 8:8:8
支持的字节和像素排序是小端序。对于4位/像素,也支持大端序。
寻址模式包括:
顺序访问通用数据(到一个连续的内存缓冲区)。
在视频/显示缓冲区的二维窗口内对像素和普通数据进行光栅扫描。
二维窗口内二维块的光栅扫描(用于旋转像素数据)
附加特性:
扫描顺序:对于存储在单独内存缓冲区或行交错在单个缓冲区中的字段,支持交错访问。
重新排序扫描,实现反转和旋转。
旋转和水平反转-仅当传输二维块(到/从IRT)
垂直反转 - 也在逐行光栅扫描
滚动
应用程序帧内平移帧滚动
不支持非交错和部分交错格式
垂直分辨率:单个的水平像素:18 BPP - 4 pixels; 12, 4 BPP orYUV 422 - 2 pixels; other formats - one pixel
条件读取(用于组合): 不读取完全透明或隐藏的像素。
对于图形,这是受支持的。通过从一个单独的缓冲区读取透明度(alpha)。
输入/输出FIFO(在SMFC、DMFC和处理子块中)大小调整,以提供高达1500个周期的延迟弹性。 38.1.2.1.4 处理
IPU处理矩形块像素。处理是在这些子块- VDIC, DP, IC和IRT。
38.1.2.1.4.1 处理流
支持几种分时数据流,如下表所示。
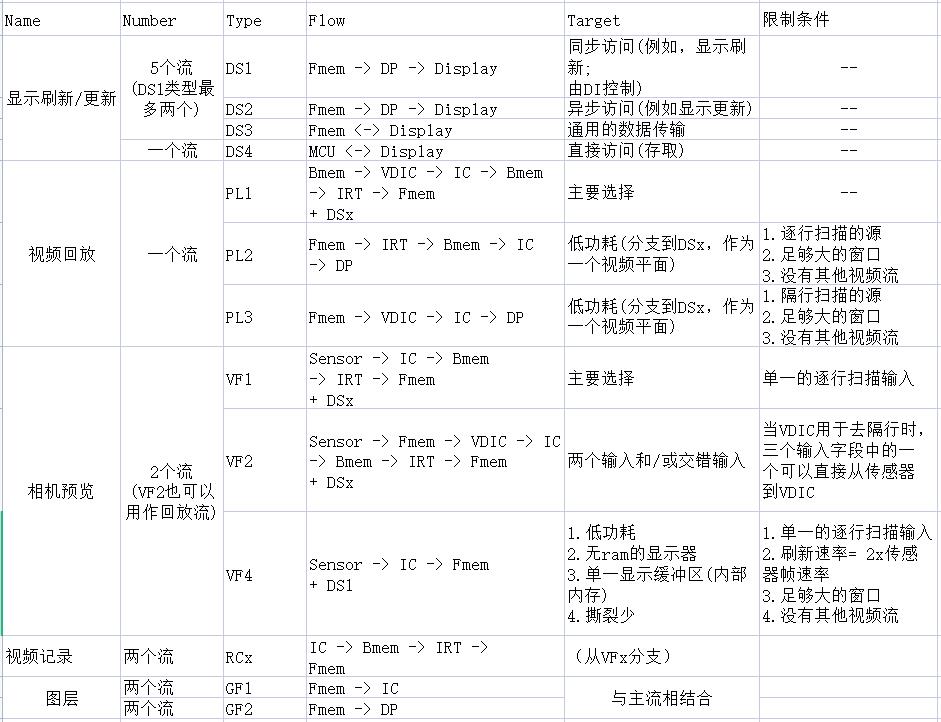
注解
系统内存使用-图例
Fmem:系统内存中的帧双缓冲区(翻页)(通常外部存储器: DDR DRAM[address 0x1000_0000 - 0xFFFF_FFFF])
Bmem:两种可能
帧双缓冲区,如上所述
一种带(4-256行)双缓冲区(翻页)的系统内存(可以是内部内存:OCRAM [address 0x0900_0000 - 0x093F_FFFF])
两个处理阶段之间的直接箭头表示一个内部管道
分时
IC可以紧密分时三个流:一个 VFx,一个RCx和一个PLx(具有独立的加工参数)
DP可以分时使用一个DS1流和一个DS2流(每个流都有不同的目的地和独立的处理参数)
直接访问显示(DS4)与其他主动DSx流紧密地共享显示端口。
其他分时(在PLx流和IRT中的DS2和DS3流之间)是逐帧的
上面流中的任何处理阶段都可以跳过。
触发和同步
从传感器开始的流量段由传感器的输入触发并同步
以显示刷新结束的流段由DI中的刷新控制机制触发和同步。
在系统内存中开始和结束的流段由双缓冲机制或显式配置触发,并以可用资源决定的速率连续无延迟地处理。这些流段的优先级低于传感器/显示驱动的流。下面描述每个处理块的功能。
38.1.2.1.4.2 显示处理(DP)
显示处理器执行发送到显示器的数据所需的所有处理。
输入:来自IC和/或系统内存
顺序:行、逐行或隔行
格式:YUVA/RGBA, non-decimated, 8 bits/value
处理链:
结合2个视频/图形平面
覆盖一个简单的HW光标32 x 32像素,颜色一致;可以与完整平面在逻辑上结合。
颜色转换/校正-线性(乘法和加法)可编程,包括:
YUV<-> RGB, YUV<->YUV转换,其中YUV表示MPEG-4标准中定义的任何一种颜色格式
调整:亮度、对比度、色彩饱和度等。
特效:灰度、颜色反转、色度、蓝调等。
色彩保存剪辑,用于色域映射
保持色调的色域映射-为最小的颜色失真
应用于组合的输出或一个输入
伽马校正和对比拉伸-可编程分段线性映射
输出:显示(通过DC)
速率:高达240M像素/秒
格式:YUV/RGB,非decimated, 8位/值 DP处理单个数据流在任何给定的时间,但支持多达三个数据流通过分时。
一个主要流程:
使用计时器定期加载输入(例如,用于同步访问)
如果内容没有改变,可以选择跳过帧(适用于智能显示)
两个二次流:
异步的;当主流不需要DP时(在消隐间隔期间或主帧被跳过时)处理。
这两个次级流是逐帧交换的。 38.1.2.1.5 视频去隔行或结合(VDIC)
视频去隔行和合并有两种操作模式:
去隔行:将隔行视频流转换为逐行顺序。
组合:将两个视频/图形平面和一个背景色组合在一起
38.1.2.1.5.1 VDIC中去隔行
视频去隔行使用高质量的3场运动自适应滤波器将交错视频流转换为递进顺序。
Video source - SDTV: 480i30 (720x480 @ 30 fps) or 576i25 (720x576 @ 25 fps)and HDTV: 1080i/30 (1920x1080 @ 30 fps)
输入:三个连续的字段
源
最近的字段可能来自CSI或系统内存
另外两个字段从内存中读取
字段大小:高达968x1024像素(可能是更宽字段的垂直条纹;例如:1920像素)
像素格式: YUV 4:2:2/4:2:0, 8 bits/value
输出:逐行的帧
目标:到系统存储器或到图像转换器。
帧大小:高达968x2048像素
速率:高达240 MP/sec(例如,1920x1080 @ 85 fps)
格式:与输入格式相同 去隔行使用高质量的运动自适应3场滤波器:
对于慢动作-保留完整的分辨率(顶部和底部字段)
用于快速运动-防止运动伪影
VDIC在任何给定时间都支持单个视频流。
38.1.2.1.5.2 VDIC中合并
组合输入:两个渐进式视频/图形平面
Source: system memory
Plane size: up to 1920x1200 pixels.
Pixel format: RGB/YUV 4:2:2, 8 bits/value在这种模式下:
两个输入平面从系统内存中读取,使用前一个字段和下一个字段输入fifo。
他们的相对高度,向上/向下是可配置的
它们中的每一个可能只覆盖输出帧的一部分。对于帧的剩余部分,芯片使用以下值:
下平面:一种24位的背景色,存储在内部寄存器中
上平面:一个透明的像素
其组合方法与DP、IC的方法相同。 38.1.2.1.5.3 图像转换(IC)
图像转换器在视频流上执行各种操作。
输入:从传感器或系统内存
帧大小:高达4096x4096像素
速率:高达200M像素/秒(例如5mp @ 30 fps + 35%消隐间隔)
顺序:行,逐行。如果不使用调整大小,也可接受隔行顺序。
像素格式:YUV/RGB, 8位/值
处理链:
调整大小
完全灵活的缩放比最大缩小比:8:1。受此限制,任何N->M大小的调整都可以执行。
独立的水平和垂直调整比例。
颜色转换/校正-线性(乘法和加法)可编程,包括:
YUV<-> RGB, YUV<->YUV转换,其中YUV表示MPEG-4标准中定义的任何一种颜色格式
调整:亮度,对比度,颜色饱和度…
特效:灰度,颜色反转,sephia,蓝色…
与图形平面结合(例如特定于应用程序的覆盖)
水平反转
输出:到系统内存或(对于单个活动流)到显示设备(通过DP)。
帧大小:高达1024x1024像素
速率:高达100m像素/秒(例如1920x1080 @ 30 fps)
顺序:行,逐行。如果不使用调整大小,也可接受隔行顺序。
格式:YUV/RGB, 8位/值 IC支持三种分时数据流:记录、摄像头预览和回放(前两种共享一个共同的输入)。
38.1.2.1.5.4 图像旋转(IRT)
输入/输出:从/到系统内存
速度
高达120M像素/秒(当单个任务是活跃的)。
高达100M像素/秒(当多个任务是活跃的)。
顺序:8x8像素块的光栅扫描
格式:YUV/RGB,非decimated, 8位/值
转换:以下组合
90度旋转
水平反转
垂直反转 38.1.2.1.6 自动程序
IPU配备了强大的控制和同步功能,以执行其任务的最小涉及ARM核心和最小的内存使用。
特别是,它包括:
一个集成的DMA控制器与一个AXI主端口,允许自主访问系统内存。
一个集成的显示控制器,执行无ram显示的屏幕刷新。
翻页双缓冲机制,同步读和写访问系统内存,以防止撕裂效应。
带有视频/图形源的双/三重缓冲同步机制。
内部同步,例如,从传感器输入和输出到显示之间的同步。
因此,在大多数情况下,只有在ARM平台也执行部分处理(例如视频编码)时,才涉及到ARM平台。特别是,以下程序由IPU完全自主执行:
无ram显示的屏幕刷新 更新用于屏幕刷新的(“部分平面”)显示缓冲区(位于系统内存或外部显示控制器中,例如智能显示器或图形加速器),当内容在不同的(“完整平面”)缓冲区中生成时。
通常,在系统中没有其他活动时,会有一段较长的时间。ARM平台在闲置状态下,可将其置于低
功耗模式,降低功耗,显著延长电池寿命。
IPU支持几种技术进一步降低显示系统的功耗:
动态优化的屏幕刷新率(参见下面的屏幕刷新)
优化了显示缓冲区的更新(参见下面的显示缓冲区的更新)
动态背光控制,通过图像增强进行低光补偿
下面概述了自动程序的进一步特性和功能。
38.1.2.1.6.1 屏幕刷新
刷新率可以在预定义的范围内变化。在此范围内,速率将根据内容更新速率动态调整。
关于新内容的可用性的指示如下:
如果使用了翻页双缓冲,则该机制提供了这一指示
如果只使用了单个缓冲区(并且增量更新),IPU可以从ARM平台接收到修改的指示(通过设置一个内部标志)。
IPU统计刷新周期,包括总刷新周期和有新内容的刷新周期。ARM平台可以使用这些计数器来优化显示管理(例如切换显示缓冲压缩开关)。计数器由ARM平台重置。
传输的数据可以在被处理的过程中使用IC和DP。
38.1.2.1.6.2 更新显示缓冲区
条件更新IPU可以接收到一个外部“窥探”信号,表明整个平面缓冲区的修改(如上屏幕刷新期间)。它监测信号,并在检测到,它执行以下其中之一:
在没有任何SW干预的情况下执行更新
中断ARM核心,这可以启动一些更复杂的过程(例如选择性更新)
自动显示一个变化的图像(动画)或移动的图像(滚动)这是通过读取帧(从一个完整的平面缓冲区)增量偏移来实现的。当IPU到达最后一个程序帧时,它可以执行以下操作之一:
返回第一帧,没有任何SW干预
中断ARM平台,生成下一个内容
更新的时间可以调整,避免撕裂。
传输的数据可以在被处理的过程中使用IC和DP。
38.1.2.1.6.3 相机预览
人为撕裂可以通过系统内存中的(自动)页面翻转双缓冲来防止。
或者,来自图像传感器的视频流可以直接发送到用于屏幕刷新的显示缓冲区。这个选项的意义在于只需要一个帧缓冲区(而不是两个)。这个缓冲区可以位于系统内存或外部显示控制器中。
这个选项是有用的,例如,在低帧率时,撕裂是不可见的。
当必须防止撕裂时,显示中的刷新周期可以与传感器的定时信号同步(每个输入帧两个刷新周期):IPU从传感器接收垂直同步信号,并从它产生显示的同步信号。
38.4 功能描述
本节提供了块的完整功能描述。
38.4.1 IPU详细的框图
下图为IPU顶层框图。
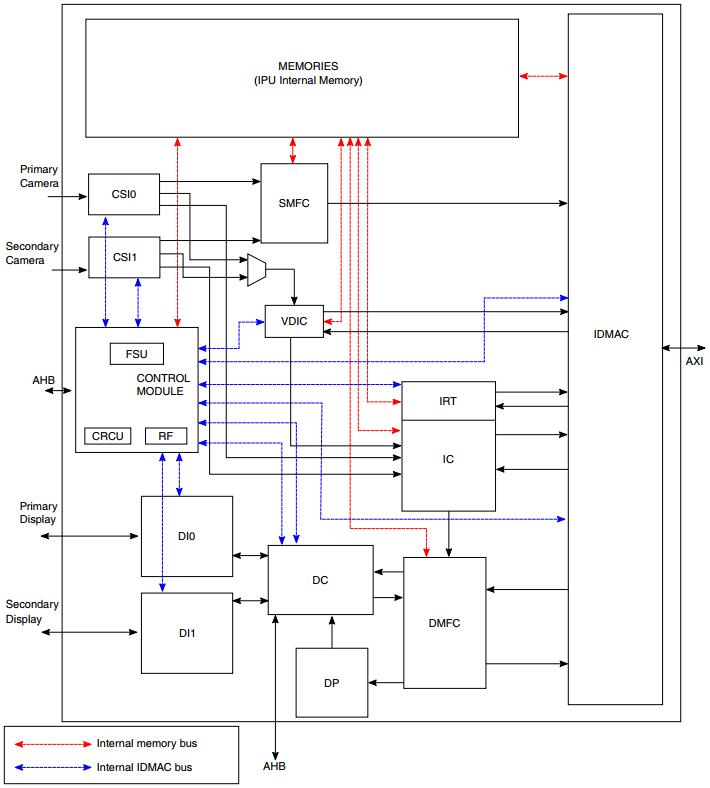
38.4.2 图像DMA控制器(IDMAC)
下图是IDMAC的框图。
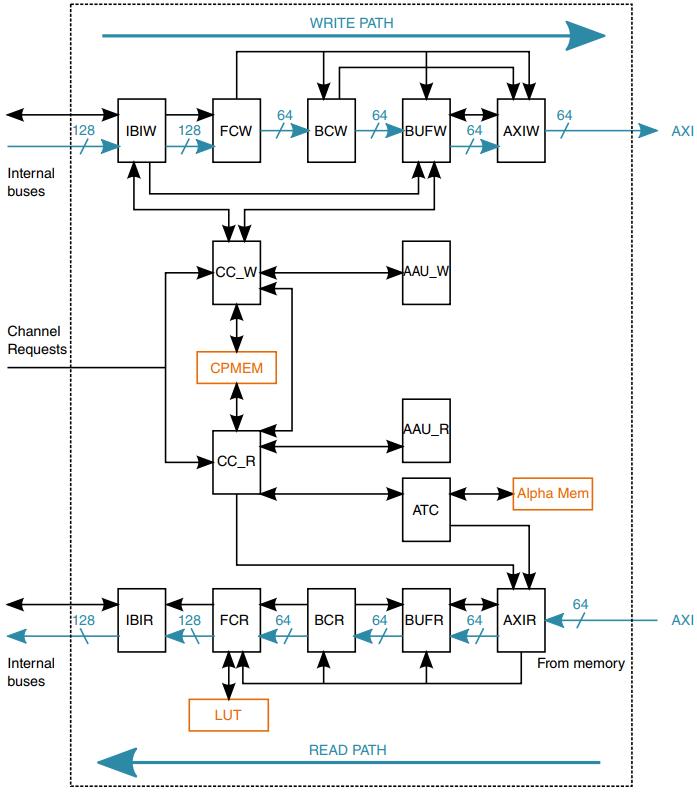
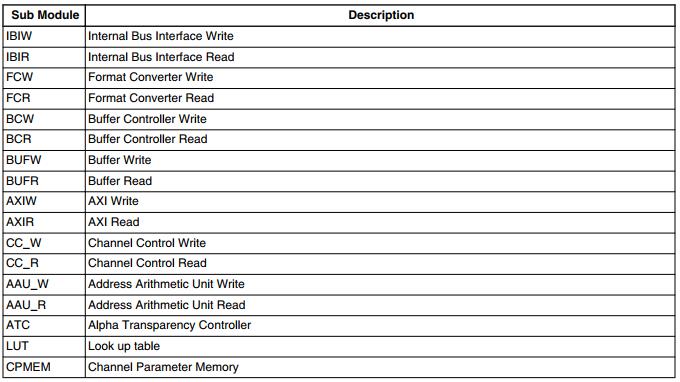
下表描述了IDMAC的子块术语表
38.4.2.1 IDMAC的通道
下表总结了IDMAC的通道。
内容太多,省略······
38.4.2.2 IBIW & IBIR - 内部总线接口写和读
内部总线接口处理IDMAC和IPU子模块之间的内部IPU协议通信。
IBIR处理执行从外部内存读取的通道。IBIW处理对外部内存执行写访问的通道。
38.4.2.3 FCW & FCR - 格式转换器写和读
IPU子模块只能处理以下格式。每个组件为8位: 
该像素可以以下列格式存储在存储器中。R/G/B表示这个分量可以是R或是G或是B;A是alpha分量的位置)。
38.4.2.4 Buffering units
缓冲单元(BUFW, BUFR)用于存储由不同编码颜色组成的数据。
38.4.2.4.1 处理实时信道
连接到IPU的AXI总线的内存控制器可以使用与每次突发相关联的AXI ID来区分实时和非实时通道。
为了做到这一点,用户必须根据内存控制器中的设置设置通道的ID,并根据其性质设置通道的优先级。缓冲区控制器(BCW/BCR)保存所有赢得仲裁的未决请求。但是,由于内存控制器可以区分IPU内部的实时通道和非实时通道,可能会出现由于IPU的队列中充满了非实时请求而导致实时请求被阻塞的情况。为了避免这种情况,用户可以限制队列中非实时请求的数量。
读请求队列最多可以处理8个请求。写请求队列最多可以处理6个请求。用户可以通过设置写请求的USED_BUFS_MAX_W和读请求的USED_BUFS_MAX_R来限制非实时请求的数量。限制请求数量的特性是通过设置读请求的USED_BUFS_EN_R位和写请求的USED_BUFS_EN_W位来启用的。
38.4.2.6 CC_W & CC_R - 通道控制写和读
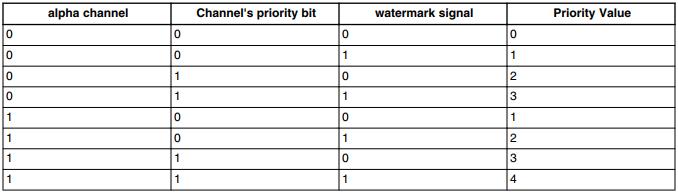
根据上述条件计算每个启用通道的优先级值。然后,CC单元以循环方式在具有相同优先级值的通道之间进行选择。
38.4.2.6.1 锁定仲裁并重新排序AXI爆发
通过发送连续地址的AXI突发可以提高整个系统的性能。这可以通过重新排序AXI突发来实现,访问属于同一通道的访问将一个接一个地发送。这可以通过控制相应通道的IDMAC_LOCK_#位来实现。
赢得仲裁的IDMAC请求将根据IDMAC_LOCK_#位的设置为下一次爆发提供服务。发出请求的块(在IPU上的DMFC)只在它的FIFO中有足够的空间来接受IDMAC_LOCK_#bit定义的突发数时才断言请求。IPU为提供实时屏幕刷新以同步显示的通道提供此功能(23,27,28)。此外,它还为可能产生非常短的AXI突发(IC和IRT)的信道提供了这种能力。
38.4.2.7 AAU_W & AAU_R - 地址算术单元写和读
AAU_R和AAU_W单元计算系统内存中要被IPU访问的地址。这些单位也计算爆发大小(BS)。地址计算是根据CPMEM中存储的参数完成的。
寻址参数与图像帧的关系如下表所示。
以字节为单位的系统内存地址计算如下:
ADDR = EBA + (XB + SX) * BPP + (YB + SY) * (SL + 1)
with 0 < XB <= FW and 0 < YB <= FH.
使用双缓冲时,EBA0为缓冲区0的基址,EBA1为缓冲区1的基址。IPU_CHA_CUR_BUF寄存器是一个状态寄存器。它包含指向所有IPU DMA通道的当前工作缓冲区的1位指针。完成当前缓冲区处理后,IPU自动切换指针。如果ARM平台是一个特定的双缓冲通道的数据源,它应该检查这个状态位,以知道什么是IPU当前缓冲区。ARM平台只允许在工作的DMA通道不使用缓冲区时写入缓冲区。当ARM平台填满缓冲区后,它必须在IPU_CHA_BUF0_RDY寄存器和IPU_CHA_BUF1_RDY寄存器中设置相应的位。如果需要,ARM平台只能通过写1来清除指针,而不能设置它。
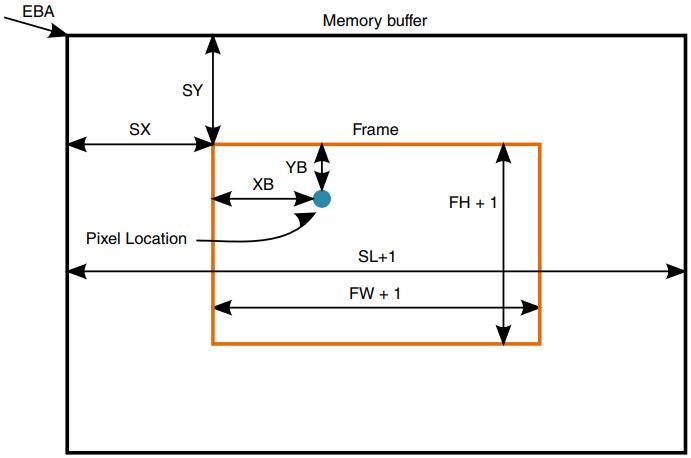
根据寻址方式计算XB和YB坐标。有两种寻址模式:2D模式和块模式
在2D模式下,像素数据逐行传输到内存中。使用2D模式有两种方式:从YB = 0开始,在YB <= FH结束(YB是递增的)或从YB = FH开始,在YB <= 0结束(YB是递减的)。第二个选项提供图像的垂直翻转。
在块模式下,帧被分成块。这对于旋转或后过滤是必需的,因为用于数据传输的顺序是逐块的。块传输的顺序是根据IDMAC信道参数存储器中的VF、HF和ROT位来确定的。块内的顺序是逐行的,其中块大小受块宽(BW)和块高(BH)参数的限制。BW和BH参数由IC旋转部分设置,不能通过通道参数内存进行配置。
通道控制负责地址计算流程。它从通道参数内存中获取通道参数,更新它们并控制地址算术单元。
38.4.2.7.1 滚动支持
自动显示一个变化的图像(动画)或移动的图像(滚动)是通过读取帧(从一个背景缓冲区)增量偏移是实现的。通过设置通道对应的SCE位来启用滚动功能。
滚动步长由通道对应的SDX和SDY参数控制,滚动方向由通道对应的SDRX和SDRY参数定义。要读取的最大滚动帧数由信道对应的SM参数定义。
当最后一个程序帧到达时(IDMAC的内部计数器到达SM), IDMAC可以执行以下操作之一(由SCC位控制):
返回第一帧,没有任何SW干预。返回点由SX0和SY0参数定义。
中断ARM平台,生成下一个内容。
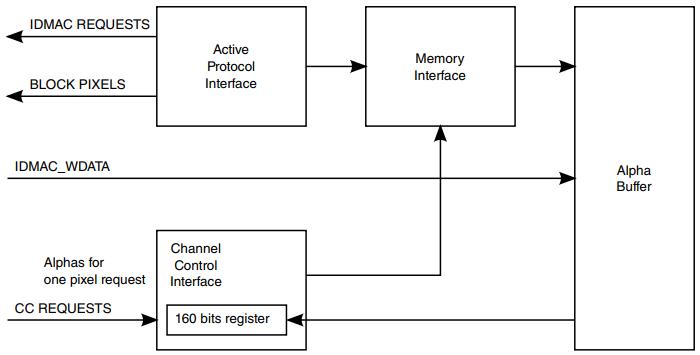
38.4.2.8 ATC - Alpha透明度控制器
Alpha透明度控制器(ATC)处理外部内存中的Alpha缓冲区,用于像素数据和Alpha数据位于单独的缓冲区(单独的Alpha模式)。
在这种情况下,IDMAC读取alpha数据和像素数据,将它们合并在一起,并向相关子模块提供一个包含alpha信息的像素。ATC的主要职能是:
生成alpha通道的请求,跟随来自模块的像素数据请求。
为每个通道维护一个内部alpha内存缓冲区。
当内存中没有足够的alpha时,ATC就会阻塞相应的像素通道。
当有像素通道请求时,ATC加载并将其alpha值累积到寄存器中。
ATC内存控制器可以管理8个通道的alphas。
ATC支持同步新帧在结束帧的错误之前。为了将通道配置为使用单独的alpha,除了CPMEM中的ALU位外,还应该设置通道的IDMAC_SEP_AL位相应的通道。
下图是ATC的方框图。
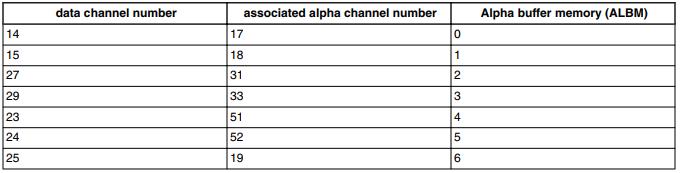
ATC alpha缓冲存储器可以容纳8个alpha缓冲。ATC内存中的缓冲区指针是根据CPMEM中的ALBM参数定义的。下表描述了数据通道、alpha通道和alpha缓冲区内存中的指针之间的关系。
alpha数据可以用来减少从内存中透明(alpha = 0)的像素读取。条件读取特性是由CPMEM中的CRE位启用的。
如果单个爆发像素的所有对应的alpha值都等于零,IDMAC将阻塞对外部存储器的访问,并向相应的通道提供所有为零的数据。通过这种方式可以防止对内存的某些访问,从而减少内存上的负载。
38.4.2.9 LUT - 查找表
当以编码像素格式工作时,从内存中读取的数据是根据给定的地址解码的像素值。在8位码的情况下,从内存中读取的数据是根据给定的地址解码的像素值。
4位码配置时,根据CPMEM中的DEC_SEL参数设置4位解码值的地址。
00 = addresses 0 to 15
01 = addresses 64 to 79
10 = addresses 128 to 143
11 = addresses 192 to 207
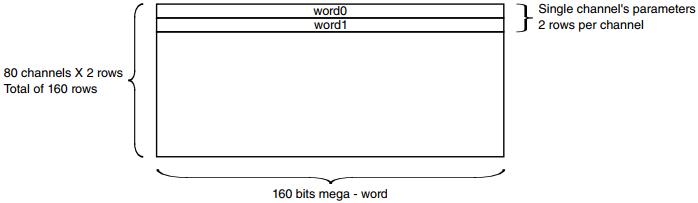
38.4.2.10 CPMEM - 通道参数内存
CPMEM保存每个IDMAC通道的配置参数。CPMEM可以保存80个通道的设置。
每个通道的设置都是由两个巨大的字定义的。每个巨大的字有160位宽。下图说明了CPMEM的结构。
每个IDMAC通道可以配置为两种不同的模式:
非交错模式,其中Y:U:V数据被组织在系统内存中的3个单独的缓冲区
交错模式,其中Y:U:V数据被组织在系统内存的单个缓冲区中
每个模式的参数及其组织方式都是不同的。IPU使用CPMEM字的像素格式选择(PFS)值来确定这些字应被解释为交错格式还是非交错格式。
注意:CPMEM是“内存映射”,可以通过控制模块(参见内存访问单元)由AHB总线访问。
各模式下的IDMAC参数及其组织形式如下表所示
38.4.2.11 IDMAC的操作模式
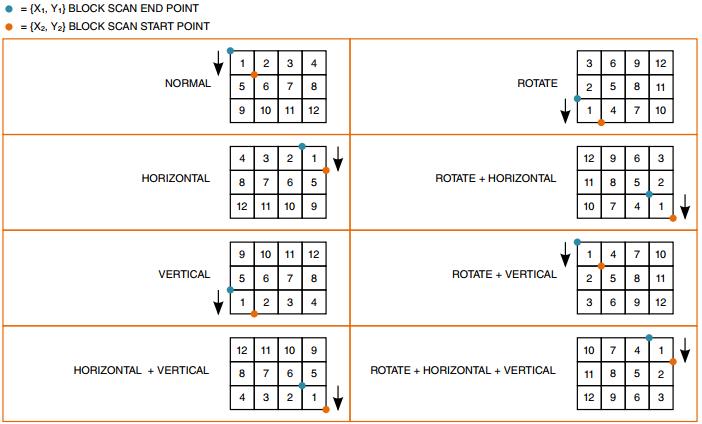
38.4.2.11.1 旋转模式
旋转由IDMAC和IC内部的旋转单元执行。
帧被分为8X8像素块。IC在一个块内重新排列像素。IDMAC对块进行了重新排序。根据CPMEM中的ROT、VF和HF参数进行排序。
下图说明了重新排序块的各种选项。
ROTATE表示设置了ROT位
HORIZONTAL表示设置了HF位
VERTICAL表示设置了VF位
38.4.2.11.2 Frame size
IPU支持多种非交错模式;帧高(FH)和帧宽(FW)。 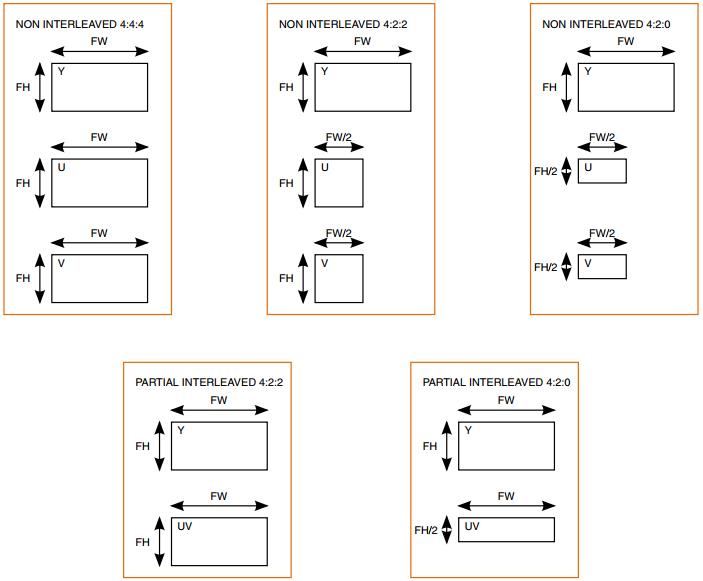
38.4.2.14 IDMAC's internal events
IDMAC的一些内部信号可以用于监视流的进程。这些比特可以通过软件进行轮询。这些位中的一些可以用来触发一个中断或SDMA事件。
以上是关于IPU(Image Processing Unit )的主要内容,如果未能解决你的问题,请参考以下文章