STM32H7---高速缓存Cache
Posted Z小旋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了STM32H7---高速缓存Cache相关的知识,希望对你有一定的参考价值。
引言:
在使用STM32H7 跟F7系列芯片的时候经常看到第一句初始化就是
Cache_Enable(); //打开L1-Cache
//使能CPU的L1-Cache
void Cache_Enable(void)
SCB_EnableICache();//使能I-Cache
SCB_EnableDCache();//使能D-Cache
SCB->CACR|=1<<2; //强制D-Cache透写,如不开启,实际使用中可能遇到各种问题
但是关于他的讲解又是少之又少,很多也说的不清不楚的,所以今天我们来看下到底什么是STM32的Cache
1. Cache的基本概念和工作原理
1.1 什么是Cache
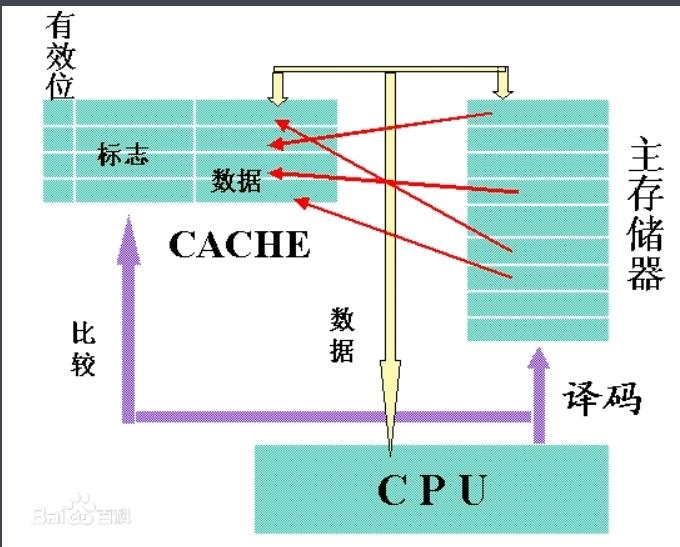
Cache存储器,为高速缓冲存储器,是位于CPU和主存储器DRAM(Dynamic Random Access Memory)之间,规模较小,但速度很高的存储器,通常由SRAM(Static Random Access Memory 静态存储器)组成。它是位于CPU与内存间的一种容量较小但速度很高的存储器
参看:
SRAM、DRAM及DDR FLASH ROM概念详解
1.2 为什么需要Cache
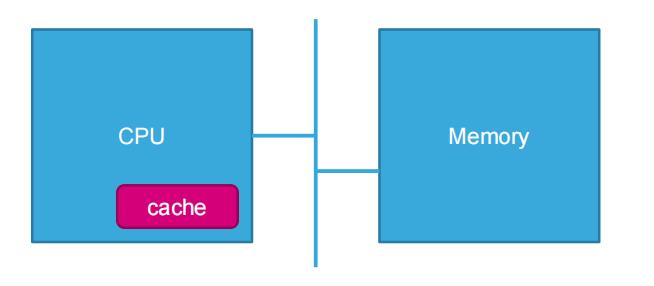
CPU的速度远高于内存,当CPU直接从内存中存取数据时要等待一定时间周期,而Cache则可以保存CPU刚用过或循环使用的一部分数据,如果CPU需要再次使用该部分数据时可从Cache中直接调用,这样就避免了重复存取数据,减少了CPU的等待时间,因而提高了系统的效率。
而在我们STM32处理器中,常用的F1微控制器的主频一般为几十 MHz,但是随着计数的发展,上百 MHz 主频的 MCU 已经很常见了。现在ST推出的 Cortex-M7 内核的F7跟H7 都达到了几百Mhz,采用 ST 最新40nm工艺的 STM32H7 已经可以跑到 480 MHz 了,
那我们可以想一下,CPU的运算速度在成倍提高,虽然微控制器的频率大幅提高了,可是一般作为主存储器使用的动态存储器(DRAM),其存储周期仅为几十 ns (频率:f=1/T=几十KHz)。和CPU的频率差了很多倍。那么,如果指令和数据都存放在DRAM中,DRAM的速度将会严重制约整个系统的性能。因此,高性能的微控制器会在主存储器和 CPU 之间增加高速缓冲存储器(Cache),目的是提高对存储器的平均访问速度,从而提高存储系统的性能。
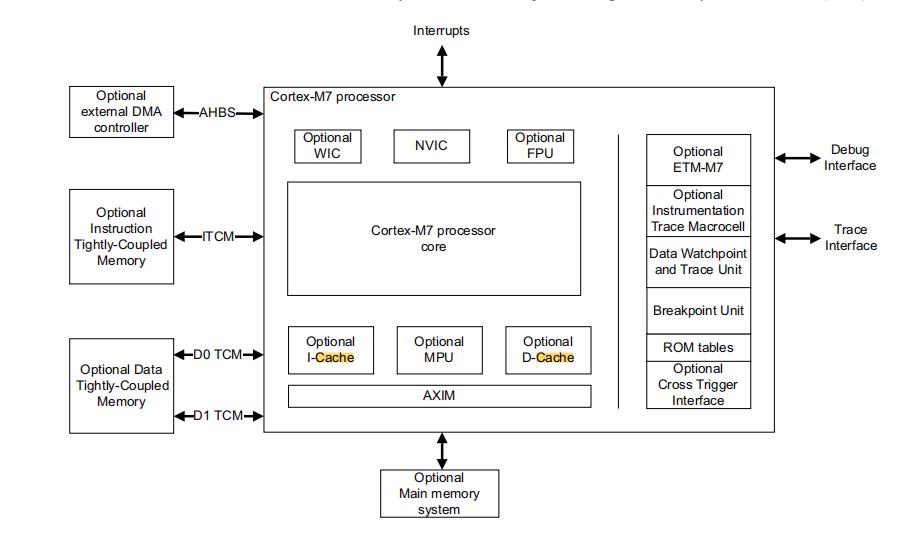
而对于我们的M7内核,可以看到内部是集成了Cache的
PS: 也就是说使用了M7内核的厂商,正常情况下都可以使用cache高速缓存,并不是STM32的独有
2. cache基础概念解释
也就是说,通过上面的两段,你可以明白什么是cache跟为什么需要cache(加快DRAM存储器跟CPU之间的访问速度) 那么我们再看下cache的分类:
Cache又分为L1Cache(一级缓存)和L2Cache(二级缓存),L1Cache主要是集成在CPU内部,而L2Cache集成在主板上或是CPU上
我们常用的就是L1Cache(一级缓存),一级缓存又分为数据部分D-Cache和指令部分I-Cache
2.2 I-Cache 和 D-Cache
如果一个存储系统中指令预取时使用的 cache 和数据读写时使用的 cache 是各自独立的,这是称系统使用了独立的 cache,反之则为统一的 cache。其中,用于指令预取的 cache 称为指令 cache(I-Cache),用于数据读写的 cache 称为数据 cache(D-Cache)。使用独立的 I-Cache 和 D-Cache,可以在同一个时钟周期中读取指令和数据。
Cortex-M7 架构为我们配备了独立的高速指令缓存(I-Cache)和高速数据缓存(D-Cache)。
我们通过下面几组图来让你有一个更直观的了解:
1.CPU运行指令,指令存储在外部存储中。从外部内存中获取指令需要的时间很久,CPU可能需要50-100ns来获得指令
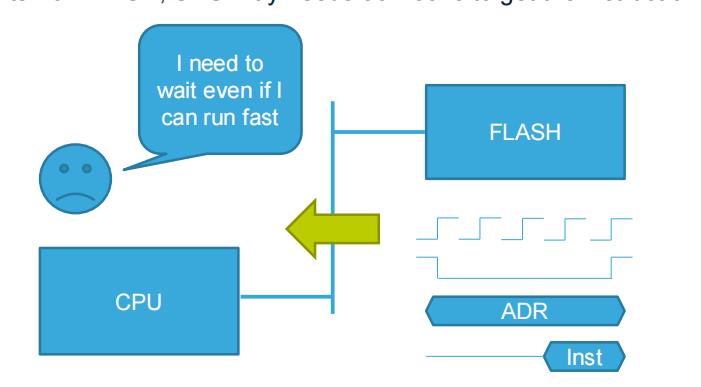
2.如果通过I-Cache,执行过的指令就会被存储,通过缓存存储已经执行的指令。D-cache存储已经被读取的数据。当再次需要相同的数据时,CPU可以在1个时钟周期内得到该指令。
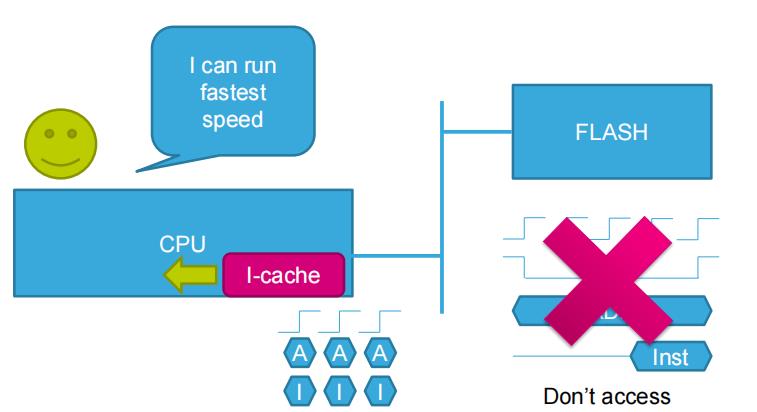
3. 数据存储在外部RAM中,如果CPU需要读取数据,从外部内存中获取数据需要花费很长时间。

4.如果指令在外部内存上(NORflash,SDRAM,QSPI等),I-cache缓存是有用的,数据先存到I-cache缓存,CPU直接访问I-cache,也就是外部内存的访问时间不是1个时钟。
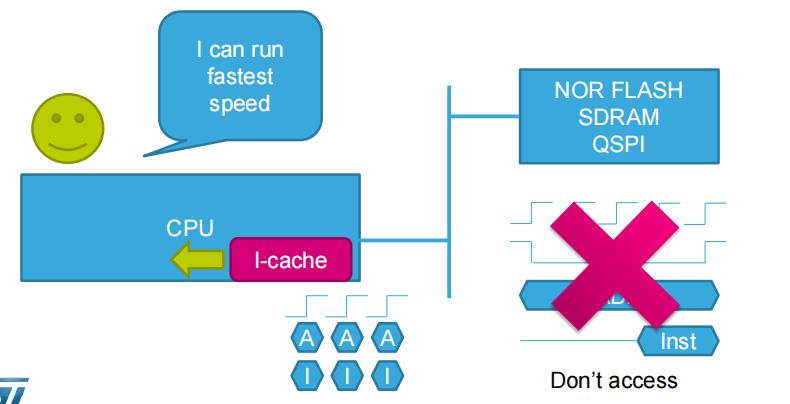
通过上面的 I-Cache 和 D-Cache,CPU就可以在同一个时钟周期中读取指令和数据。
2.2 时间局部性 和 空间局部性
对大量典型程序运行情况分析的结果表明,在较短的时间间隔内,程序产生的地址往往集中在存储空间的一个很小范围,这种现象称为程序访问的局部性。这种局部性可细分为时间局部性和空间局部性。时间局部性是指被访问的某个存储单元在一个较短的时间间隔很可能又被访问。空间的局部性是指访问的某个存储单元的临近单元在一个较短的时间间隔内很可能也被访问
时间局部性和空间局部性保证了系统采用 cache 后,通常性能都能得到很大的提高
2.3 块(cache line)
Cache line
Cache 与主存储器之间以块(cache line)为单位进行数据交换,Cache 在逻辑上被划分为若干 cache line,对应着一组存储器的位置。CPU 读取数据或者指令时,它同时将读取到的数据或者指令保存到一个 cache 块中。这样当 CPU 第2次需要读取相同的数据时,它可以从相应的 cache 块中得到相应的数据。
不同系统中,cache 的块大小也是不同的。通常 cache 的块大小为几个字节。当 CPU 从主存储器中读取一个字的数据时,它将会把主存储器中和 cache 块同样大小的数据读取到 cache 的一个块中。
2.4 Read-allocate 和 Write-allocate
根据不同的分配方式,可以把 cache 分为读操作分配(Read-allocate)cache 和写操作分配(Write-allocate)cache。
2.5 Cache Hit 和 Cache Miss
Cache命中(Cache Hit)——要访问的数据/指令已经存在缓存里;
Cache缺失(Cache Miss)——要访问的数据/指令不在缓存里;
如果发生 cache miss 并且 cache 存储未满,则在 cache 中设置一个位置,并把新的缓存数据存到这个位置。如果 cache 已满,则要通过 cache 替换策略进行 cache line 的替换,腾出空闲的位置后,再将新的缓存数据存到这个位置。
2.6 CPU 在 cache 中的访问过程
在 CPU 执行程序过程中,需要从内存取指令或写数据时,先检查 cache 中有没有要访问的信息,若有,就直接在 cache 中读写,而不用访问存储器。若没有,再从主存中把当前访问信息所在的一个一个主存块复制到 cache 中。因此,cache 中的内容是主存中部分内容的副本。下图展示了带 cache 的 CPU 执行一次访存操作的过程。
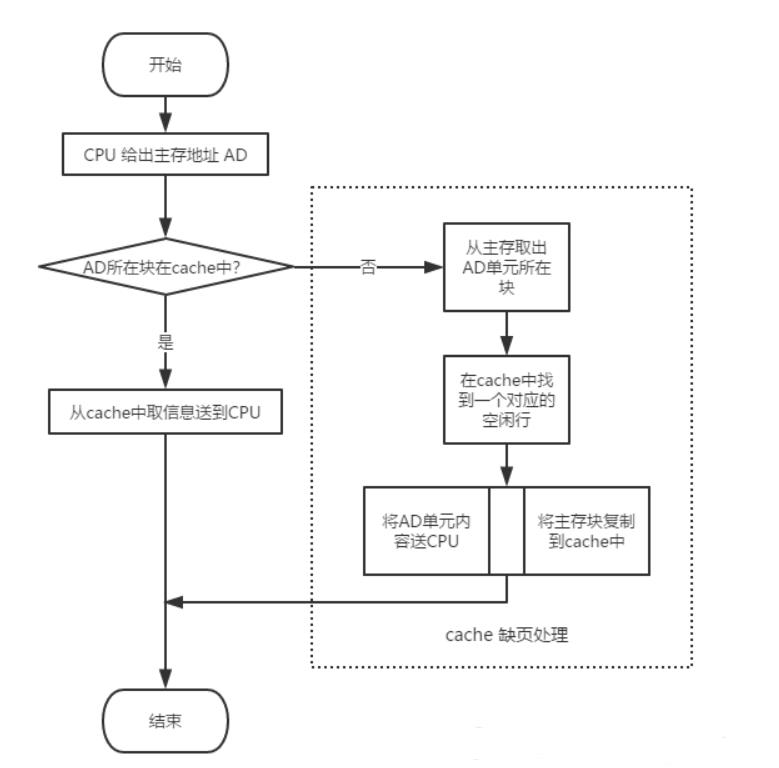
cache 是一种小容量高速缓冲存储器,由快速的 SRAM 组成,直接制作在 CPU 芯片内,速度较快,几乎与 CPU 处于同一个量级。在 CPU 和主存之间设置 cache,总是把主存中被频繁访问的活跃程序块和数据块复制到 cache 中。由于程序访问的局部性,大多数情况下,CPU 可以直接从 cache 中直接取得指令和数据,而不必访问慢速的主存。
如上图所示的访存过程中,需要判断所访问的信息是否在 cache 中。若 CPU 访问单元的主存块在 cache 中,则称 cache 命中(hit),命中的概率称为命中率 p (hit rate)。若不在 cache 中,则为不命中(miss),其概率为缺失率(miss rate)。命中时,CPU 在 cache 中直接存取信息,所用的时间开销就是 cache 的访问时间 Tc,称为命中时间。缺失时,需要从主存读取一个主存块送 cache,并同时将所需信息送 CPU,因此所用时间为主存访问时间 Tm,和 cache 访问时间 Tc 之和。通常把从主存读入一个主存块到 cache 的时间 Tm 称为缺页损失。
CPU 在 cache 和主存层次的平均访问时间为:
Ta = p * Tc + (1 - p) * (Tm + Tc) = Tc + (1 - p) * Tm
- 参考STM32社区内容
由于写操作分配 cache 增加了 cache 内容预取的次数,它增加了写操作的开销,所以想要充分发挥 Cache 的作用,就要保证有比较高的命中率(Cache Hit)但是由于程序时间和空间的局部性,,cache 的命中率可以达到很高,接近于 1。因此,虽然缺页损失所耗费的时间远远大于命中时间,但以最终的平均访问时间仍可大大减少。
2.7 cache 的映射方式
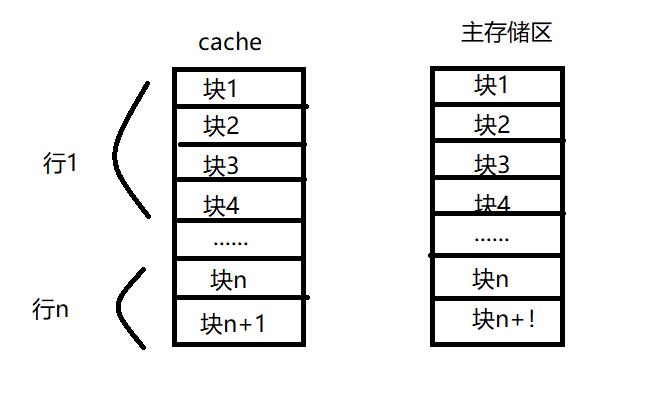
在 cache 存储系统中,把 cache 和主存储器都划分成相同大小的块。因此,主存地址可以由块号 B 和块内地址 W 两部分组成。同样,cache 的地址也可以由块号 b 和块内地址 w 两部分组成。
前面我们说到 在 cache 存储系统中,把 cache 和主存储器都划分成相同大小的块。然后cache又把这些块分成了一些行,每个行里都有一定数量的块,每个块可以存储主存储器某个块的地址
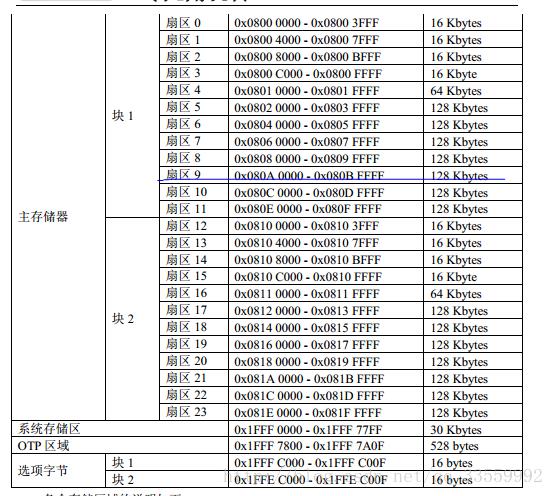
STM32F429 的内部 FLASH 包含主存储器、系统存储器、 OTP 区域以及选项字节区域,它们的地址分布及大小如下:
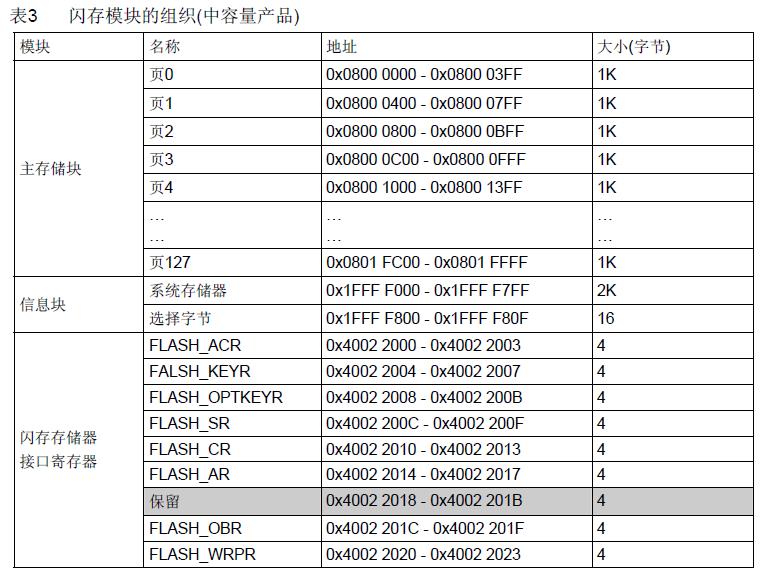
STM32F103的中容量内部 FLASH 包含主存储器、系统存储器、 OTP 区域以及选项字节区域,它们的地址分布及大小如下:
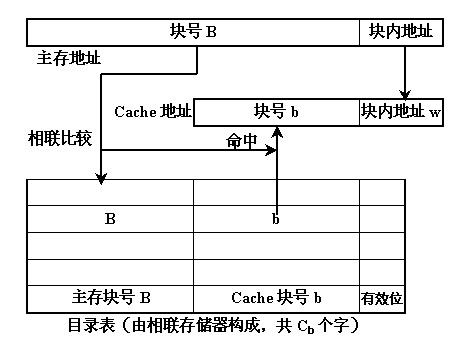
cache 行中的信息取自主存储器中的某个块。将主存块复制到 cache 行时,主存块和 cache 行之间必须遵循一定的映射规则。这样 CPU 在要访问某个主存单元时,可以依据映射规则到 cache 对应的行中查找要访问的信息,而不用在整个 cache 中查找。
根据不同的映射规则,主存块和 cache 行之间有以下三种映射方式。
- 直接映射(direct):每个主存块映射到 cache 的固定行中。
- 全相连映射(full associate):每个主存块映射到 cache 的任意行中。
- 组相连映射(set associate):每个主存块映射到 cache 的固定组的任意行中。
全相连(full-associative)方式
【区块划分】将主存与 Cache 划分成若干个大小相等的块(lines)。
【映射关系】主存中任意一块都可以映射到 Cache 中的任意一块的位置上。
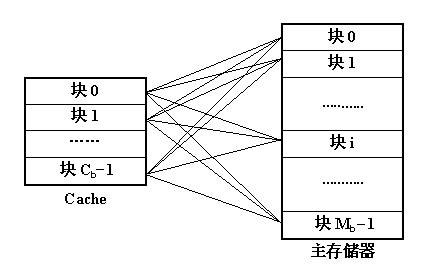
如果 Cache 的块容量为 Cb,主存的块容量为 Mb,则主存和 cache 之间的映射关系共有 Cb * Mb 种。如果采用目录来存放这些映射关系,则目录表的容量为 Cb。
【优缺点】
优点:访问灵活,命中率高,Cache 存储空间利用率高,冲突率低,只有 Cache 满时才会出现在冲突。
缺点:地址变换比较复杂,每次都要与全部内容比较,速度相对慢,成本高,因而应用少。
【地址组成】
主存:块号 + 块内地址
缓存:块号 + 块内地址
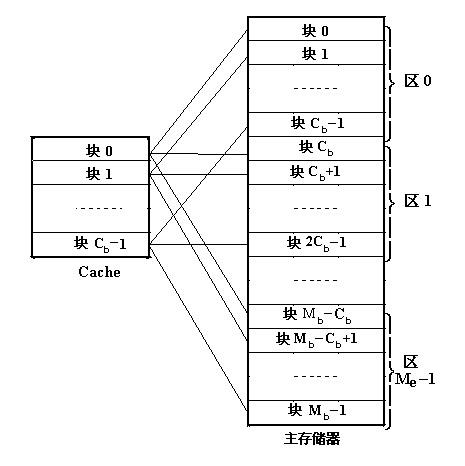
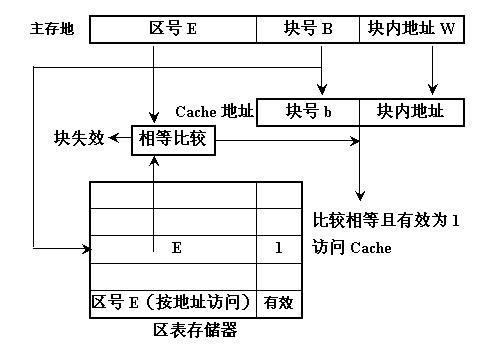
直接映射(direct-mapping)方式
【区块划分】
将主存根据 Cache 的大小分成若干分区(主存的大小为 Cache 的整数倍),Cache 分成若干个相等的块(lines),主存的每个分区也分成与 Cache 相等的块。
【映射关系】
主存中的每一个分区由于大小与 Cache 完全相同,可以与整个 Cache 相像,每个分区中的每一块正好与 Cache 的每一块配对。也就是说,主存中一块只能映射到 Cache 中的一个特定的块,编号不一致的块是不能相互映射的。
【优缺点】
优点:地址变换简单,只需检查区号是否相等即可,因而可以得到比较快的访问速度,硬件设备简单。
缺点:替换操作频繁,命中率比较低,每块相互对应,不够灵活。
【地址组成】
主存:区号 + 块号 + 块内地址
缓存:块号 + 块内地址
组相联(set-associative)方式
【区块划分】
主存:主存根据 Cache 大小划分成若干个区,每个区内划分成若干个组(sets),每个组再划分成若干个块(lines)。
Cache:划分成若干个组(sets),每个组划分成若干个块(lines)。
【映射关系】
从主存的组到 Cache 的组之间采用直接映射方式,当主存中的一组与 Cache 中的一组之间建立了直接映射关系之后,在两个对应的组内部采用全关联映射方式。
【优缺点】
融合了直接映射与全关联映射两种映射方式,结合了两者的优点。具体实现容易,命中率与全关联映射接近。
【地址组成】
主存:区号 + 组号 + 块号 + 块内地址
缓存:组号 + 块号 + 块内地址
目前绝大多数CPU都是采用组相联的 cache 映射方式 硬件更容易实现,又结合了前两种方式的优点。
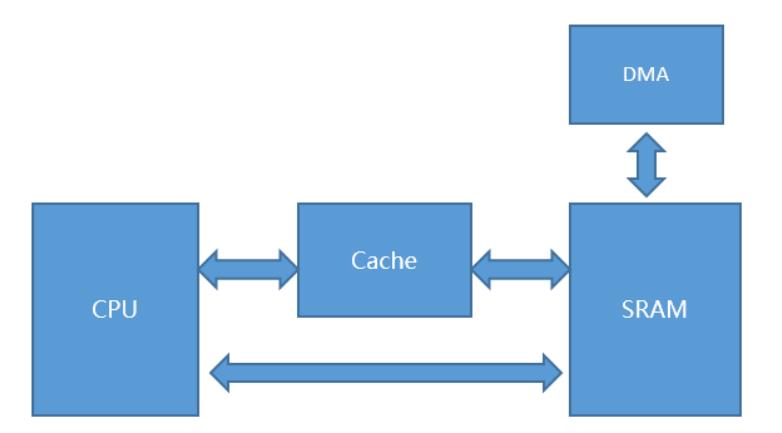
cache一致性问题
我们使用cache缓存(SRAM) 在享受便利性的同时也要注意下他的一些问题
比方说我们使用DMA外设到内存,DMA 写操作直接访问主存,更新主存中的数据,如果该数据已经包含在 cache 中,则 cache 中的数据将会比主存中对应的数据“老”,不会更新 cache 和写缓冲区中相应的内容,这样就可能造成数据的不一致。
如果是DMA从内存到外设, DMA 从主存中读取的数据已经包含在 cache 中,而且 cache 中对应的数据已经被更新,但是还没有更新到主存,这样 DMA 读到的将不是系统中最新的数据。
这章就先说这么多,关于H7的配置下篇再讲解


以上是关于STM32H7---高速缓存Cache的主要内容,如果未能解决你的问题,请参考以下文章