spark集群配置
Posted EsmeZhao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark集群配置相关的知识,希望对你有一定的参考价值。
目录
1.集群部署规划
表1-1 集群部署规划
| 主机名 | master | slave1 | slave2 |
| HDFS | NameNode | SecondaryNameNode DataNode | DataNode |
| YARN | NodeManage | ResourceManager NodeManager | |
| Spark | Master | Worker | Worker |
2.安装Spark
进入/export/software目录,将spark软件包导入该目录下。解压spark软件包 到/export/servers目录下,并重命名为spark。
[root@master ~]# cd /export/software/
[root@master software]# rz -be
[root@master software]# ls
apache-flume-1.8.0-bin.tar.gz kafka_2.11-1.0.2.tgz
apache-hive-1.2.1-bin.tar.gz redis-6.2.1.tar.gz
apache-zookeeper-3.5.9-bin.tar.gz spark-2.0.0-bin-without-hadoop.tgz
hadoop-2.6.4.tar.gz sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
hbase-1.2.0-bin.tar.gz zeppelin-0.8.2-bin-all.tgz
jdk-8u141-linux-x64.tar.gz
[root@master software]# tar -zxvf spark-2.0.0-bin-without-hadoop.tgz -C /export/servers/
[root@master software]# cd /export/servers/
[root@master servers]# mv spark-2.0.0-bin-without-hadoop spark3.文件配置
配置spark-env.sh。
[root@master servers]# cd spark/
[root@master spark]# cd conf/
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh export SPARK_DIST_CLASSPATH=$(/export/servers/hadoop-2.6.4/bin/hadoop classpath)
export HADOOP_CONF_DIR=/export/servers/hadoop-2.6.4/etc/hadoop
export SPARK_MASTER_IP=192.168.38.128
配置slaves文件。
[root@master conf]# vi slaves
slave1
slave2
该文件中写入哪个主机名,哪个主机就会存在worker节点。按照集群部署规划,slave1和slave2主机拥有worker,因此写入这两行内容。
配置Spark环境变量。将以下内容写入配置文件/etc/profile末尾,并source使之生效。
export SPARK_HOME=/export/servers/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
4. 分发文件
将spark远程发送到其他集群
[root@master conf]# cd /export/servers/
[root@master servers]# scp -r /export/servers/spark slave1:/export/servers/
[root@master servers]# scp -r /export/servers/spark slave2:/export/servers/5.启动集群
首先启动Hadoop集群。(命令省略)
启动Master节点。
[root@master ~]#start-master.sh启动Slave节点。
[root@master ~]#start-slaves.sh6.查看集群
集群进程与集群部署规划一致。
[root@master servers]# jps.sh
**********master**********
2807 Jps
2139 Master
1854 NameNode
**********slave1**********
1600 DataNode
2005 Worker
2470 Jps
1783 NodeManager
1705 SecondaryNameNode
**********slave2**********
1830 NodeManager
2232 Worker
1723 ResourceManager
1597 DataNode
2639 Jps
[root@master servers]#查看Spark页面
启动成功后,可以通过“host:port”的方式来访问Spark管理页面,例如:http://192.168.38.128:8080 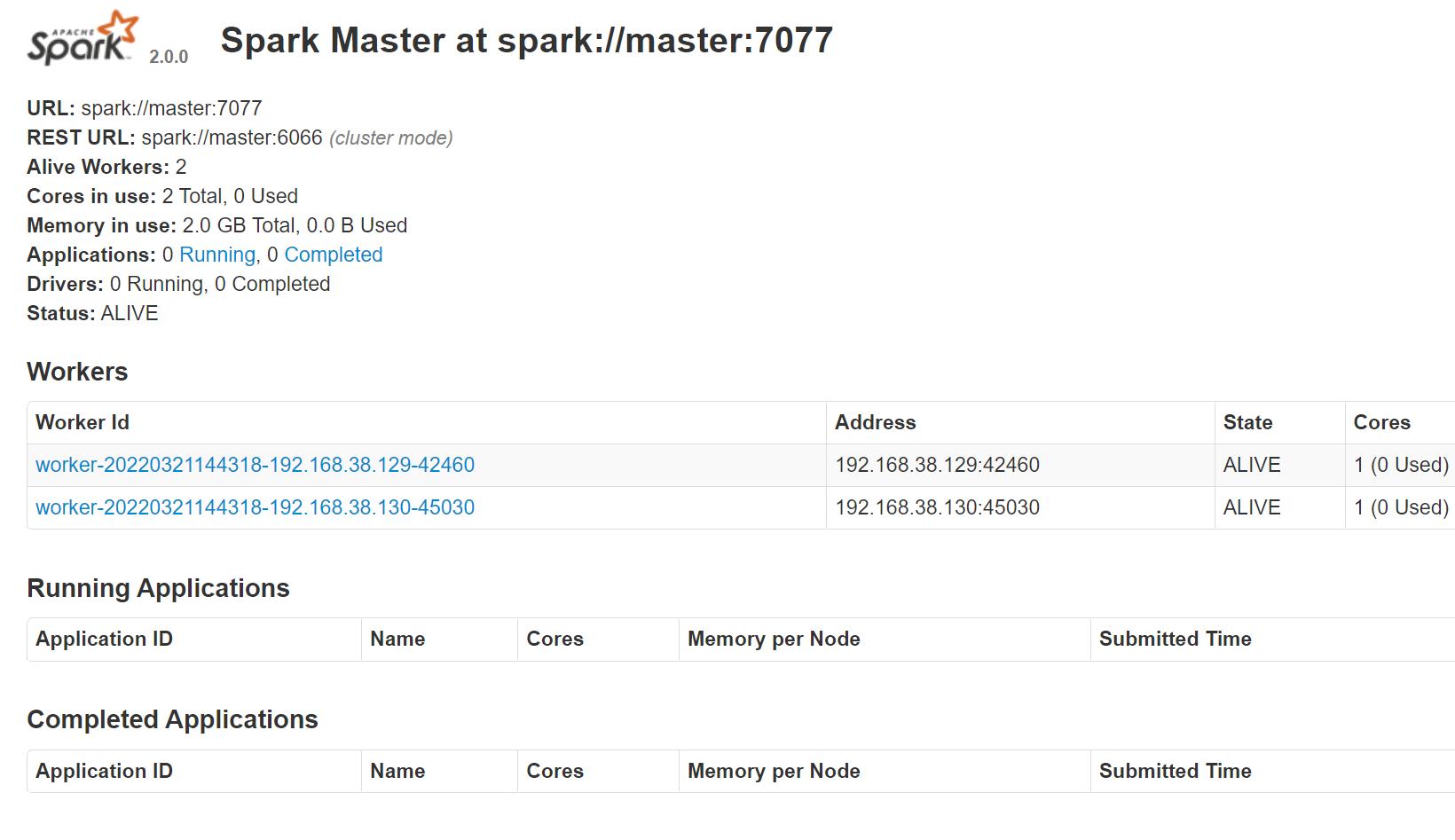
以上是关于spark集群配置的主要内容,如果未能解决你的问题,请参考以下文章