翻译: 3.2. 从零开始实现线性回归 深入神经网络 pytorch
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译: 3.2. 从零开始实现线性回归 深入神经网络 pytorch相关的知识,希望对你有一定的参考价值。
既然您了解了线性回归背后的关键思想,我们就可以开始在代码中动手实现。在本节中,我们将从头开始实现整个方法,包括数据管道、模型、损失函数和小批量随机梯度下降优化器。虽然现代深度学习框架可以自动化几乎所有这些工作,但从头开始实施是确保您真正了解自己在做什么的唯一方法。此外,当需要自定义模型、定义我们自己的层或损失函数时,了解事情的幕后工作方式将证明是方便的。在本节中,我们将仅依赖张量和自动微分。之后,我们将介绍一个更简洁的实现,利用深度学习框架的花里胡哨。
%matplotlib inline
import random
import torch
from d2l import torch as d2l
3.2.1。生成数据集
为简单起见,我们将根据带有加性噪声的线性模型构建一个人工数据集。我们的任务将是使用我们数据集中包含的有限示例集来恢复该模型的参数。我们将保持数据低维,以便我们可以轻松地对其进行可视化。在下面的代码片段中,我们生成了一个包含 1000 个示例的数据集,每个示例包含从标准正态分布中采样的

def synthetic_data(w, b, num_examples): #@save
"""Generate y = Xw + b + noise."""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
请注意,其中的每一行都features包含一个二维数据示例,并且每一行都labels包含一个一维标签值(标量)。
print('features:', features[0],'\\nlabel:', labels[0])
features: tensor([ 0.6860, -0.3904])
label: tensor([6.8769])
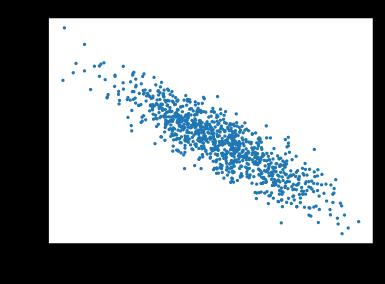
通过使用第二个特征和生成散点图,我们可以清楚地观察到两者之间的线性相关性。features[:, 1], labels
d2l.set_figsize()
# The semicolon is for displaying the plot only
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), 1);
3.2.2. 读取数据集
回想一下,训练模型包括对数据集进行多次传递,一次抓取一小批示例,并使用它们来更新我们的模型。由于此过程对于训练机器学习算法非常重要,因此值得定义一个实用函数来打乱数据集并以小批量访问它。
在下面的代码中,我们定义data_iter函数来演示此功能的一种可能实现。该函数采用批量大小、特征矩阵和标签向量,产生大小为 的小批量batch_size。每个小批量由特征和标签的元组组成。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# The examples are read at random, in no particular order
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
通常,请注意,我们希望使用合理大小的 minibatch 来利用 GPU 硬件,该硬件擅长并行化操作。因为每个示例都可以并行地通过我们的模型,并且每个示例的损失函数的梯度也可以并行获取,所以 GPU 允许我们处理数百个示例所花费的时间几乎不比处理一个示例所花费的时间多.
为了建立一些直觉,让我们阅读并打印第一批数据示例。每个小批量中特征的形状告诉我们小批量的大小和输入特征的数量。同样,我们的小批量标签将具有由 给出的形状batch_size。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\\n', y)
break
tensor([[ 6.0601e-01, -1.7352e-01],
[-1.4425e+00, 2.5488e-03],
[ 1.3511e+00, 8.1201e-01],
[ 9.5844e-01, 2.1861e+00],
[ 2.2073e+00, 1.3480e+00],
[ 5.4952e-01, 1.2803e+00],
[ 1.0107e+00, 5.0928e-01],
[-4.9667e-01, 5.5764e-01],
[-1.6612e+00, 1.2118e+00],
[ 2.5645e+00, 9.1055e-01]])
tensor([[ 5.9881],
[ 1.3177],
[ 4.1486],
[-1.3216],
[ 4.0401],
[ 0.9547],
[ 4.4913],
[ 1.3209],
[-3.2465],
[ 6.2422]])
当我们运行迭代时,我们连续获得不同的小批量,直到整个数据集都用完(试试这个)。虽然上面实现的迭代有利于教学目的,但效率低下,可能会让我们在实际问题上遇到麻烦。例如,它要求我们将所有数据加载到内存中并执行大量随机内存访问。在深度学习框架中实现的内置迭代器效率更高,它们可以处理存储在文件中的数据和通过数据流馈送的数据。
3.2.3 初始化模型参数
在我们开始通过小批量随机梯度下降优化模型参数之前,我们首先需要有一些参数。在下面的代码中,我们通过从均值为 0、标准差为 0.01 的正态分布中采样随机数来初始化权重,并将偏差设置为 0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
在初始化我们的参数之后,我们的下一个任务是更新它们,直到它们完全适合我们的数据。每次更新都需要获取我们的损失函数相对于参数的梯度。给定这个梯度,我们可以在可能减少损失的方向上更新每个参数。
由于没有人想明确地计算梯度(这很乏味且容易出错),我们使用 2.5 节中介绍的自动微分来计算梯度。
3.2.4。定义模型
接下来,我们必须定义我们的模型,将其输入和参数与其输出相关联。回想一下,为了计算线性模型的输出,我们简单地取输入特征的矩阵向量点积 X和模型权重w,并添加偏移量b到每个例子。请注意,下面Xw是一个向量并且b是一个标量。回忆一下第 2.1.3 节中描述的广播机制。当我们添加一个向量和一个标量时,标量被添加到向量的每个分量中。
def linreg(X, w, b): #@save
"""The linear regression model."""
return torch.matmul(X, w) + b
3.2.5 定义损失函数
由于更新我们的模型需要获取损失函数的梯度,我们应该首先定义损失函数。在这里,我们将使用第 3.1 节中描述的平方损失函数 。在实现中,我们需要将真实值y转换为预测值的形状 y_hat。以下函数返回的结果也将具有与 相同的形状y_hat。
def squared_loss(y_hat, y): #@save
"""Squared loss."""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
3.2.6。定义优化算法
正如我们在3.1 节中讨论的,线性回归有一个封闭形式的解决方案。然而,这不是一本关于线性回归的书:这是一本关于深度学习的书。由于本书介绍的其他模型都无法解析求解,因此我们将借此机会介绍您的第一个小批量随机梯度下降的工作示例。
在每一步,使用从我们的数据集中随机抽取的一个小批量,我们将估计损失相对于我们的参数的梯度。接下来,我们将在可能减少损失的方向上更新我们的参数。以下代码应用小批量随机梯度下降更新,给定一组参数、学习率和批量大小。更新步长的大小由学习率决定 lr。因为我们的损失是作为小批量示例的总和来计算的,所以我们通过批量大小 (· batch_size) 对步长进行归一化,因此典型步长的大小不会在很大程度上取决于我们对批量大小的选择。
def sgd(params, lr, batch_size): #@save
"""Minibatch stochastic gradient descent."""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
3.2.7。训练
现在我们已经准备好所有的部分,我们已经准备好实现主训练循环了。理解这段代码至关重要,因为在您的深度学习职业生涯中,您将一遍又一遍地看到几乎相同的训练循环。
在每次迭代中,我们将抓取一小批训练样本,并将它们传递给我们的模型以获得一组预测。计算损失后,我们开始反向传递网络,存储每个参数的梯度。最后,我们将调用优化算法sgd来更新模型参数。
总之,我们将执行以下循环:
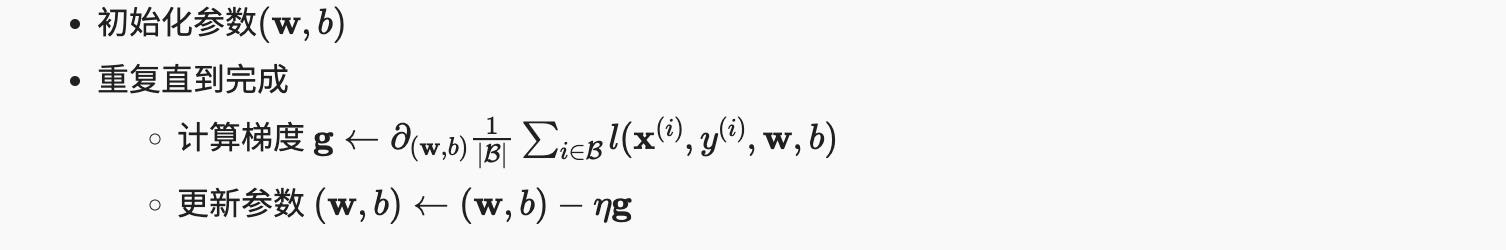
在每个epoch中,我们将遍历整个数据集(使用 data_iter函数),一旦通过训练数据集中的每个示例(假设示例的数量可以被批量大小整除)。时期数num_epochs和学习率lr都是超参数,我们在这里分别设置为 3 和 0.03。不幸的是,设置超参数很棘手,需要通过反复试验进行一些调整。我们暂时省略这些细节,但稍后在第 11 节中对其进行修改。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # Minibatch loss in `X` and `y`
# Compute gradient on `l` with respect to [`w`, `b`]
l.sum().backward()
sgd([w, b], lr, batch_size) # Update parameters using their gradient
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch epoch + 1, loss float(train_l.mean()):f')
epoch 1, loss 0.041512
epoch 2, loss 0.000157
epoch 3, loss 0.000050
在这种情况下,因为我们自己合成了数据集,所以我们准确地知道真正的参数是什么。因此,我们可以通过将真实参数与我们通过训练循环学到的参数进行比较来评估我们在训练中的成功。事实证明,他们彼此非常接近。
print(f'error in estimating w: true_w - w.reshape(true_w.shape)')
print(f'error in estimating b: true_b - b')
error in estimating w: tensor([ 0.0003, -0.0004], grad_fn=<SubBackward0>)
error in estimating b: tensor([0.0007], grad_fn=<RsubBackward1>)
请注意,我们不应该理所当然地认为我们能够完美地恢复参数。然而,在机器学习中,我们通常不太关心恢复真实的基础参数,而更关心导致高度准确预测的参数。幸运的是,即使在困难的优化问题上,随机梯度下降通常也能找到非常好的解决方案,部分原因在于,对于深度网络,存在许多导致高度准确预测的参数配置。
3.2.8 概括
-
我们看到了如何从头开始实现和优化深度网络,只使用张量和自动微分,而不需要定义层或花哨的优化器。
-
本节仅触及可能的表面。在接下来的部分中,我们将根据我们刚刚介绍的概念描述其他模型,并学习如何更简洁地实现它们。
3.2.9 练习
-
如果我们将权重初始化为零会发生什么。算法还能用吗?
-
假设您是Georg Simon Ohm,他试图在电压和电流之间建立一个模型。您可以使用自动微分来学习模型的参数吗?
-
您可以使用普朗克定律使用光谱能量密度来确定物体的温度吗?
-
如果要计算二阶导数,可能会遇到什么问题?你会如何修复它们?
-
为什么reshape函数中需要squared_loss 函数?
-
尝试使用不同的学习率来找出损失函数值下降的速度。
-
如果示例数不能除以批量大小,data_iter函数的行为会怎样?
参考
https://d2l.ai/chapter_linear-networks/linear-regression-scratch.html
以上是关于翻译: 3.2. 从零开始实现线性回归 深入神经网络 pytorch的主要内容,如果未能解决你的问题,请参考以下文章