Rancher 和知乎超大规模多集群管理联合实践
Posted RancherLabs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Rancher 和知乎超大规模多集群管理联合实践相关的知识,希望对你有一定的参考价值。
源起
知乎是中文互联网高质量的问答社区,每天有上千万用户在知乎分享知识、经验和见解,找到自己的答案。为配合不同阶段的业务发展需求,知乎容器平台也在不断演进、提升,目前几乎所有的业务都运行在容器上。
这两年知乎开始使用 Rancher 管理 Kubernetes 集群,集群规模逐步达到近万节点。本文将介绍 Rancher 如何针对大规模集群进行性能调优,最终访问速度提升75%,达到页面访问体验可用的状态。
对于为什么会选择 Rancher 作为我们的容器管理平台,大致原因有以下几点:
- 我们的业务部署在国内多家公有云 Kubernetes 上,需要统一的平台来管理这些 Kubernetes 集群,而 Rancher 针对国内的公有云 Kubernetes 平台兼容性非常友好。
- Rancher 降低了 Kubernetes 集群的部署和使用门槛,我们可以借助 Rancher UI 轻松纳管和使用各个 Kubernetes 集群。不是很深入了解 Kubernetes 的研发同学也可以轻松创建 Deployment、Pod、PV 等资源。
- 我们可以借助 Rancher Pipeline 在内部实现 CI/CD,使研发专注于业务应用的开发。尽管 Rancher 团队告知 Pipeline 已经停止维护,但是它的简洁依然符合我们内部对 CI/CD 的定位。
- Rancher 的持续创新能力,还有围绕着 Kubernetes 进行了一系列的生态扩展及布局,比如:轻量级 Kubernetes 发行版 k3s、Kubernetes 的轻量级分布式块存储系统 Longhorn、基于 Kubernetes 的开源超融合基础设施 (HCI) Harvester、以及 Rancher 的下一代 Kubernetes 发行版 RKE2。跟随头部创新厂商,对团队的持续进步也是大有益处。
- Rancher 作为国际化的容器厂商,在国内有非常专业的研发团队,沟通交流非常便捷。很多问题都可以在 Rancher 中文社区中找到答案,对于开源且免费的平台来说,可以说是非常良心了。
迷局
起初,我们在使用 Rancher 管理中小规模集群时,RancherUI 提供的功能几乎可以满足我们所有的需求,并且 UI 也非常流畅。
但随着业务量的增加,集群规模不断的扩大,当我们扩大到使用一个 Rancher 管理近十个集群、近万节点和几十万 pod 时(单集群最大规模将近几千个节点和数十几万 pod),操作 Rancher UI 频繁会出现卡顿并且加载时间过长的问题,个别页面需要 20 多秒的时间才能完成加载。严重时可能会造成连接不到下游集群的情况,UI 提示“当前集群 Unavailable ,在 API 准备就绪前,直接与 API 交互功能不可用。”
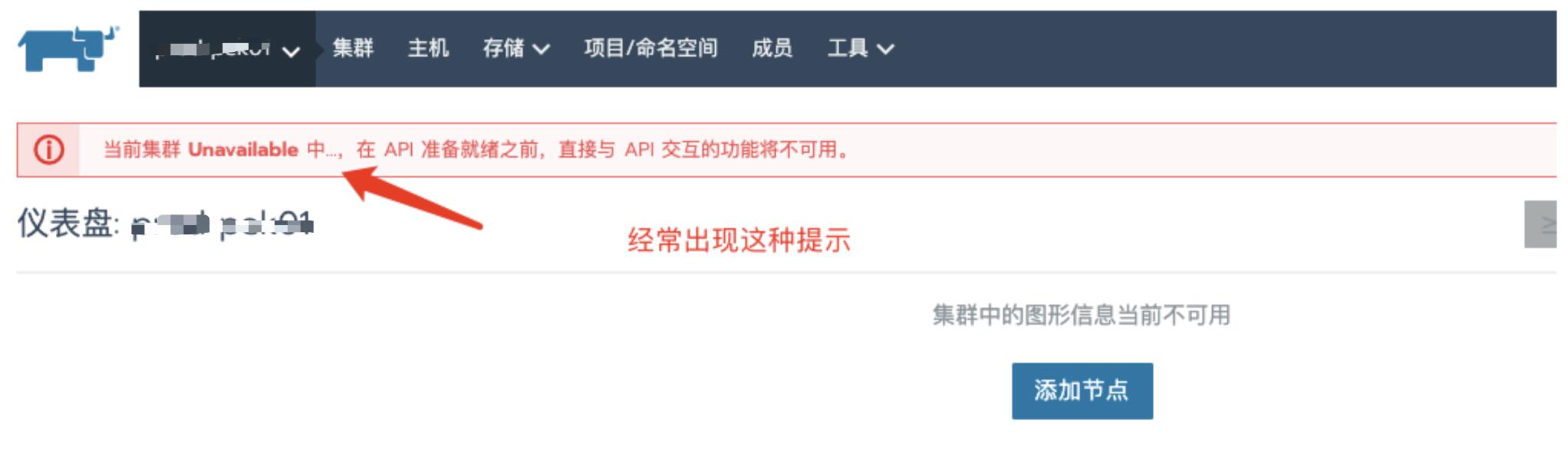
没错,我们碰到了 Rancher 的性能问题。尤其是超级管理员用户,登录时需要加载的数据量较大,基本上 UI 处于一种不可用的状态,下游集群也断连频繁。
破晓
从上面的现象来看,使用 Rancher 管理超大规模集群似乎遇到了性能问题,影响了使用体验。随后寻求 Rancher 本土技术团队帮忙,经过几次高效的线上会议沟通,基本找到根本原因:
-
虽然我们的集群数量不多,但是所有集群节点总量并不小。页面加载时,依赖node list 接口获取数据(此 node 为 Rancher 创建的一种特殊 CRD,它与实际下游集群的节点数有关),该接口处理时间较长,引起页面加载缓慢。
-
我们的下游集群中,主要以公有云的 Kubernetes 为主,这些集群通过导入方式纳管到 Rancher 中。这种纳管模式下,Rancher Server 通过与 cluster-agent 建立的Tunnel,访问下游集群的 Kube API,但是这里并非直接访问,而是走 Tunnel 到 Kubernetes Service IP 访问(如10.43.0.1:443)最终负载到多个 Kube-api server。通常这种模式并没有问题,但是由于我们的访问量和数据量都比较大,SVC IP 转发能力无法支撑,严重影响了通信效率。
经了解,如果要通过社区版解决该问题,操作会相当复杂。但企业版 Rancher 已经针对性能优化有了一套成熟的方案和策略,以下是 Rancher 工程师介绍的关于企业版和社区版 Rancher 的区别:
- 企业版和社区版 Rancher 针对查询资源最主要的区别在于:针对一些慢查询API,社区版是通过 Kubernetes API 读取数据,企业版通过 Cache 中读取。同时,支持多种下游集群的连接策略,从而提升和下游集群的管理效率。另外,企业版还对监控/日志/GPU/网络等基础设施能力有一定增强,并且对本土商业客户的 BUG 响应上会更快速。
- 出于国情需要,企业版是一种特殊的存在。海外客户基本只能订阅开源版本,本土客户可以额外享受企业版的特性,并且企业版是完全本土研发团队开发。秉承 SUSE Rancher 的开放理念,用户可以来去自如,企业版与开源版之间随意切换。
针对以上分析,我们经过权衡,决定暂时使用企业版对集群进行调优实践。
抉择
切换到企业版
首先我们从社区版 Rancher 切换到了企业版,企业版的迭代偏稳重一些,发版策略不会严格遵循开源版。好在我们使用的社区版有对应的企业版版本,并且支持从社区版平滑切换到企业版。基本上是无损切换,直接替换镜像即可,相当方便。
优化下游集群参数
Rancher工程师推荐了一些下游 Kubernetes 集群的参数优化方案,不过我们对自定义 RKE 集群使用不是很多且主要以公有云 Kubernetes 为主,这种下游集群组件参数的优化和实际的环境相关,这里只列出了一些比较常用的 kube-apiserver 参数作为参考:

内核调优
Rancher 团队也给我们提供了一些开源社区比较成熟的调优参数:kops/sysctls.go at master · kubernetes/kops · GitHub(https://github.com/kubernetes/kops/blob/master/nodeup/pkg/model/sysctls.go)
开启资源缓存
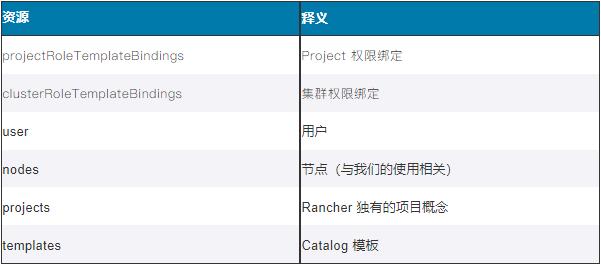
开启资源缓存后,一些涉及读取Local 集群数据的接口,将会走 Cache 模式,极大提升 API list-all 的性能,针对我们环境中节点数特别多的场景有明显效果。目前增加了缓存的资源如下:
集群连接模式
企业版中针对连接下游集群的方式进行了优化,并且支持多种连接下游集群的方式,企业版用户常用的连接策略包括:
-
策略一:默认配置
默认策略,就是不修改连接方式,沿用社区版连接下游集群的策略。
企业版中默认 Tunnel 中的 k8srest client 的 timeout 值为 60s,可以有效减少 heavy load 时下游集群数据查询的失败几率,性能提升有限,但是请求成功率会有很大提升。
-
策略二:优化 Tunnel链路
默认情况下,通过 Tunnel 使用下游集群的 Kubernetes API Service(如10.43.0.1)进行通信。如果自建集群的外部,有一个性能更好的 Kubernetes API LB,可以将连接下游集群的apiEndpoint 改为 LB 入口地址,这样可以通过 Kubernetes API LB 分担压力,提升连接下游集群的速度。
-
策略三:直接和 Tunnel 双链路
启用直连和 Tunnel 双链路模式之前,需要确保下游集群有一个从 Rancher Server 网络直接可达的 apiEndpoint(参考策略二)。优化后,Rancher API 中针对下游集群请求的 v3 接口走直连,其余还是走Tunnel,这样可以有效分散流量,避免大量数据都在 Tunnel 中传输。相对策略二,性能进一步得到提升,但是比较依赖基础网络规划。
最终,我们选择了 “策略二” 去连接下游集群,因为我们有一个性能强大的KubernetesAPI LB。当切换连接下游集群的链路会出现短暂的下游集群不可达的情况,但不会影响下游集群的业务运行。
硕果
首先,Rancher 企业版 UI 对于我们团队来说十分方便,左侧导航栏可以轻松找到各种功能,适合国人的使用习惯。可能是我们从事基础设施管理的缘故,对这种极简UI 风格可以说是非常喜欢。
其次,通过上述策略优化后,提升了 Dial Kubernetes API 时的 Timeout,最终几乎看不到因超时导致的请求失败。另外,使用下游集群的 Kube api-server 的 LB Endpoint 作为请求目标,下游集群断联现象已经消失,堪称从村道换成了高速公路。**此外,支持部分接口通过缓存快速检索,尤其对于 Node 资源,从20+ 秒的响应时间缩短至不到 5 秒。其他比较重要的接口也进行了比对,平均速度提升了大概 75% 以上。
在 Rancher 企业版中,用户可以通过优化下游集群的参数、设置连接下游集群的策略、开启缓存等方式来大幅度优化集群性能,进而轻松管理大规模集群。从上述实践可以看到,只要合理的做好调优和规划,即便是像知乎这样超大规模的集群,也能和小规模集群有一样的使用体验。
本文撰写时,Rancher 本土团队正在对企业版性能做二次调优,据说可以从 UI 角度管理单个 Project/NS 中万级的 workload,基本上完全能覆盖我们的使用极限了。期待我们和 Rancher 再次合作,然后给大家奉上新的性能实践分享。
如果你也有管理大规模集群的使用场景或需求,可以通过中文官网(https://www.rancher.cn)联系 SUSE Rancher,来为你的集群保驾护航!
以上是关于Rancher 和知乎超大规模多集群管理联合实践的主要内容,如果未能解决你的问题,请参考以下文章
Rancher开源Fleet:业界首个海量K8S集群管理项目
知乎技术分享:从单机到2000万QPS并发的Redis高性能缓存实践之路