云原生时代的到来,Hive会被替代吗
Posted BigDataToAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生时代的到来,Hive会被替代吗相关的知识,希望对你有一定的参考价值。
Apache Hive 在 2010 年作为 Hadoop 生态系统的一个组成部分突然出现,当时 Hadoop 是进行大数据分析的新颖且创新的方式。
Hive 所做的是为 Hadoop 实现了一个 SQL 接口。 它的架构包括两个主要服务:
- 查询引擎——负责 SQL 语句的执行。
- 一个 Metastore——负责将 HDFS 中的数据集合虚拟化为表。
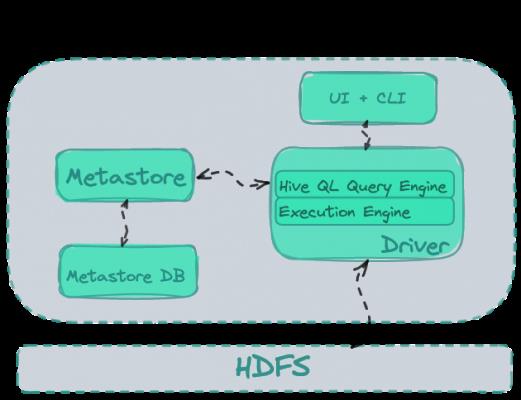
Hadoop 背后的概念是革命性的。 庞大的数据集存储在商品硬件集群上的分布式文件系统 (HDFS) 中。 计算作业使用 MapReduce 与数据并行执行。 这些任务的分配由 Yarn 管理。 主界面是一种编程语言,最初是 Java 或 Scala。
所有组件都在 Apache 基金会下开源并且可以免费使用。 多年来,这组技术一直是大规模分析的标准。
然而,这一堆栈被新技术一点一点地拆除了……
HDFS 让位于由 AWS S3 领导的对象存储。 MapReduce 已被 Spark 取代,随着时间的推移,它也减少了对 Hadoop 的依赖。 Yarn 正在被 Kubernetes 等技术所取代。 而 Hive 的查询引擎组件在性能和采用方面已经被 Presto/Trino 超越。
为了回答这个问题,让我们更深入地了解 Hive Metastore 目前提供的功能,以及已经出现的替代它的技术。
Hive Metastore 做什么
当新数据保存到对象存储时,我们通过从数据应用程序或编排工具的代码调用 Metastore API 将其注册到 Hive Metastore。这个声明阶段将对象存储中的一组对象映射到 Hive 公开的表。 注册的一部分包括指定文件中保存的表的架构,以及一些描述列的元数据。
以这种方式使用 Hive Metastore 提供了与以下相关的四个主要好处:
- 虚拟化
- 可发现性
- 模式演变
- 性能
虚拟化
使用 SQL 的数据分析师通常对对象存储及其访问模式的细节不感兴趣。
这种动态是使 Hive Metastore 在其他 Hadoop 组件被替换时不可替代的驱动力。 引入的每一项新技术都确保支持 Hive Metastore,以避免破坏依赖于 Hive 中定义的表对象的关键分析工作流。
可发现性
当暴露新数据并伴随更新时,Hive Metastore 自然成为对象存储中保存的所有集合的目录。 如果维护得当,这允许发现可用于查询的数据集。
此外,额外信息可以保存在元存储中,以提供有关数据的有用信息,例如其更新频率、谁拥有它等。
模式演变
随着时间的推移管理数据集的挑战之一是它们的可变性。 相对于描述其属性的现有列,记录可能会随着时间而改变。 或者属性集本身会随着时间而变化,从而导致表的架构发生变化。
上述注册过程为属于该表的每个附加数据文件提供了模式记录。 这意味着如果架构在某个时间点发生了更改,它将被记录在 Hive 元存储中。 访问数据时,可以使用适当的模式进行访问。
性能
由于 Hive Metastore 将表映射到底层对象,因此它允许根据对象存储支持的主键来表示分区。 分区的粒度可以由用户设置,如果分区平衡且数量合理,这种映射可以提高查询性能。
这通常被称为“分区修剪”,它允许查询引擎识别可以跳过的数据文件。
Hive 会在下一次革命中幸存吗?
没有直接替代 Metastore 的候选者,但如果一些现有趋势站稳脚跟并一起发挥作用,它可能会过时。
让我们来看看主要的继任者。
开源表格式
Iceberg、Hudi 和 Delta Lake 是该类别中的三个参与者。 每一个都是为了满足不同的需求而创建的,但随着时间的推移,它们都会收敛到涵盖允许的一组功能:
- 可变性(Hudi、Delta)
- 访问大表的效率(Iceberg)
- 模式实施和演变 (Delta)。
当使用支持这些格式的应用程序时,应用程序可以将数据视为一个表,而无需任何中间体。 并非生态系统中的所有应用程序都支持这些格式,并且在某些用例中使用它们会影响性能。
由于 Hive Metastore 是所有应用程序都支持的通用接口,因此使用开放表格式的组织仍然依赖 Hive 进行虚拟化和/或格式未涵盖的其他用例。
数据目录(Data Catalogs)
在过去一年多的时间里,我们目睹了数据工程领域领导者发布的 10 多个开源发现工具的热潮,这表明需要组织级别的数据目录。 这些新加入者加入了其他现有的商业数据目录产品,例如 Allation。
目录支持对象存储与当今使用的大多数数据库的映射。 如果可能,许多发现工具会利用 Hive Metastore 中已有的数据,否则会进入对象存储。 毫不奇怪,随着时间的推移,这些工具很适合替换 Hive Metastore 的编目功能。
可观察性工具
可观察性工具的主要目标是监控数据管道的运行质量和数据本身。 一些工具侧重于前者(例如 Databand),而另一些工具侧重于后者(Great Expectations 或 Monte Carlo)。 如果可观察性工具在整个数据生命周期中实现,它可以动态更新数据目录,并将 Hive Metastore 替换为目录。
结语
许多技术已经开始削弱 Hive 的功能。 但目前还没有一个足够成熟的,也没有就如何成功移除 Hive Metastore 的组合达成共识。
这并不意味着它应该或将继续成为数据架构的一部分。 事实上,它在可用性和性能方面都存在明显的缺陷。 值得注意的是 Hive Metastore:
- 难以安装和维护。
- 不是云原生架构,使托管服务实施复杂化。
- 受到关系数据库依赖的可伸缩性限制。
所有这些因素结合在一起,使我们预测 Hive Metastore 将无法在数据架构的下一次演变中幸存下来。 这不会自动发生——它需要在社区内部建立动力。 我们希望您与我们合作,共创美好未来!
参考自:https://lakefs.io/hive-metastore-why-its-still-here-and-what-can-replace-it/
以上是关于云原生时代的到来,Hive会被替代吗的主要内容,如果未能解决你的问题,请参考以下文章