flink table factory基础知识
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink table factory基础知识相关的知识,希望对你有一定的参考价值。
参考技术A 在flink中很多组件都是TableFactory的子类。比如序列化,反序列化,tableSinkFactory,tableSourceFactory. TableFactory是用来创建序列化,反序列器,tableSource和 tableSink的工厂。在flink框架中,TableFactory 的子类并不是程序员自己随心 new 出来的。flink的提供给程序员初始TableFactory的途径是通过属性去初始化。可以理解为首先flink会加载出所有的TableFactory子类实现,用户需要传递属性给flink,flink自动去查找出具有你对应属性的TableFactory,然后进行初始化,返回给程序员。所以在TableFactory 的源码中只有这2个方法,如下。
public interface TableFactory
Map requiredContext(); //定义这个TableFactory 必须要有哪些属性。
List supportedProperties(); //定义这个TableFactory 支持哪些属性
有了这2个方法。用户想要找到某个特定的或者自定义的TableFactory 实现,那就在传给flink的属性中必须要含有,必须属性,必须属性一个都不能少,不然找不到。除此之外你还可能会传很多其他属性。这些非必须属性,也不能瞎传,你不需要把supportedProperties的属性都传入,但是你传入的非必须属性必须是supportedProperties内。凡是报错说找不到TableFactory 的一定是某个环节被不满足,或者压根就没加载。如何加载请往下看。
trait BatchTableSourceFactory[T] extends TableFactory //用于创建批的TableSource
trait BatchTableSinkFactory[T] extends TableFactory //用于创建批的TableSink
trait StreamTableSourceFactory[T] extends TableFactory //用于创建流的TableSource
trait StreamTableSinkFactory[T] extends TableFactory //用于创建流的TableSink
TableSource、TableSink 是什么请查看
flink tableSource tableSink 基础知识 https://www.jianshu.com/p/036ca8d40cb9
public interface TableFormatFactory extends TableFactory //用于创建序列化和反序列化器
public interface SerializationSchemaFactory extends TableFormatFactory //用于创建序列化器
public interface DeserializationSchemaFactory extends TableFormatFactory //用于创建反序列化器
什么时候需要序列化,什么时候需要反序列化呢?从kafka中收到一条消息需要转换成table中的一行这需要将字节数组反序列成一个row。反过来,table中的一行需要sink到kafka需要将row序列化成一个字节数组。
这里以kafka为例看下StreamTableSourceFactory 和 StreamTableSinkFactory
public abstract class KafkaTableSourceSinkFactoryBase implements StreamTableSourceFactory , StreamTableSinkFactory
public MaprequiredContext() //Override TableFactory 的方法
public ListsupportedProperties() //Override TableFactory 的方法
//Override StreamTableSinkFactory中方法 创建TableSink
public StreamTableSink createStreamTableSink(Map properties)
//Override StreamTableSourceFactory中方法 创建TableSource
public StreamTableSource createStreamTableSource(Map properties)
在kafka中KafkaTableSourceSinkFactoryBase 把 StreamTableSourceFactory,StreamTableSinkFactory 一起实现了。我个人觉得还是分开了好。
我第一次跟踪源码是怎么创建TableFactory的时候非常困惑,在他选择TableFactory的时候感觉有一些莫名其妙。特别是自定的一个TableFactory压根就找不到。
1、首先对于自定义的TableFactory一定要在META-INF 下建 services 目录,在services 下创建的包路径org.apache.flink.table.factories.TableFactory的文件,文件写入自定义TableFactory的实现类的吧。比如在Kafka010TableSourceSinkFactory 对应的jar flink-connector-kafka-0.10_2.11-1.7.0.jar中可以看到如下图
2、寻找table创建ableSoure注册table
val tableSource:TableSoure = TableFactoryUtil.findAndCreateTableSource(tableEnv, this)
tableEnv.registerTableSource(name, tableSource)
3、寻找table创建tableSoure
4、查找tableFactory
def find[T](factoryClass:Class[T], propertyMap: JMap[String, String]):T =
findInternal(factoryClass, propertyMap, None)
从0到1Flink的成长之路(二十一)-Flink Table API 与 SQL
Flink Table API 与 SQL
ProcessFunction 函数
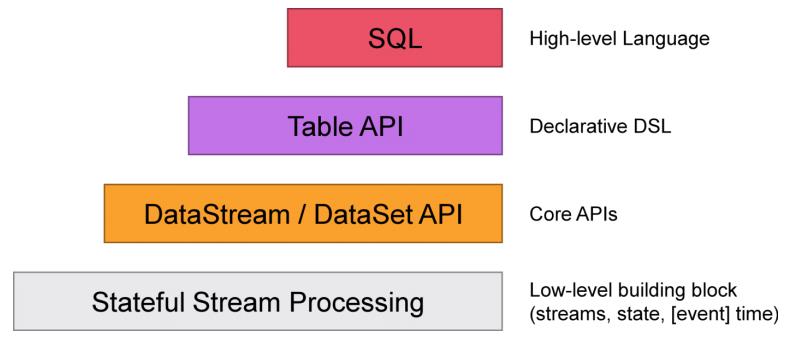
如下图,在常规的业务开发中,SQL、Table API、DataStream API比较常用,处于Low-level的Porcession相对用得较少,通过实战来熟悉处理函数(Process Function)。
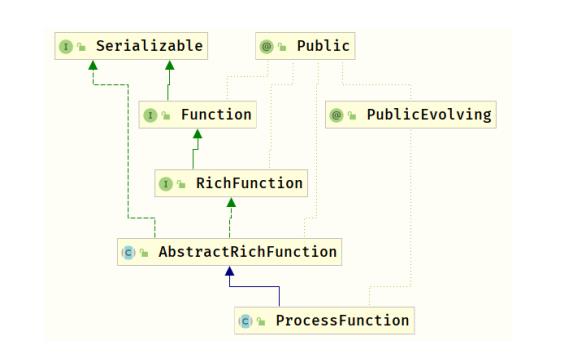
处理函数有很多种,最基础的应该ProcessFunction类,从它的类图可见有RichFunction的特性open、close,然后自己有两个重要的方法processElement和onTimer。实际项目中往往先对数据尽心keyBy分组,再进行聚合处理,查看KeyedProcessFunction类图:
案例演示:
package xx.xxxxxx.flink.process;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
/**
* 基于Flink提供ProcessFunction底层API实现:词频统计WordCount
* https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/process_function.html
*/
public class StreamProcessDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment() ;
env.setParallelism(1);
// 2. 数据源-source
DataStreamSource<String> lineStream = env.socketTextStream("node1.itcast.cn", 9999);
// 3. 数据转换
SingleOutputStreamOperator<Tuple2<String, Integer>> wordStream = lineStream
.filter(line -> null != line && line.trim().length() > 0)
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
for(String word: line.trim().toLowerCase().split("\\\\s+")){
out.collect(Tuple2.of(word, 1));
}
}
});
// TODO:调用process方法,对keyBy分组手KeyedStream进行聚合计算
SingleOutputStreamOperator<String> countStream = wordStream
.keyBy(0)
.process(new KeyedProcessFunction<Tuple, Tuple2<String, Integer>, String>() {
// 存储状态
private transient ValueState<Integer> countState ;
@Override
public void open(Configuration parameters) throws Exception {
// 初始化状态
countState = getRuntimeContext().getState(
new ValueStateDescriptor<Integer>("countState", Integer.class)
);
}
@Override
public void processElement(Tuple2<String, Integer> value,
Context ctx,
Collector<String> out) throws Exception {
// 获取当前State值
Integer currentValue = value.f1 ;
// 获取历史State值
Integer historyValue = countState.value();
// 判断是否第一次,如果是直接更新
if(null == historyValue){
countState.update(currentValue);
}else{
countState.update(currentValue + historyValue);
}
// 返回值
out.collect(value.f0 + " = " + countState.value());
}
});
// 4. 数据终端-sink
countStream.printToErr();
// 5. 触发执行-execute
env.execute(StreamProcessDemo.class.getSimpleName());
}
}
其中需要自己管理状态,使用ValueState存储,运行结果截图如下:
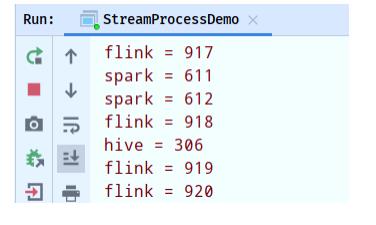
Table API & SQL 概述
table
tableApi
sql
为什么需要Table API & SQL?
当在使用Flink做流式和批式任务计算的时候,往往会想到几个问题:
- 需要熟悉两套API : DataStream/DataSet API,API有一定难度,开发人员无法集中精力到
具体业务的开发 - 需要有Java或Scala的开发经验
- Flink 同时支持批任务与流任务,如何做到API层的统一
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
Flink 已经拥有了强大的DataStream/DataSet API,满足流计算和批计算中的各种场景需求,但是关于以上几个问题,还需要提供一种关系型的API来实现Flink API层的流与批的统一,那么这就是Flink Table API & SQL。
Table API & SQL的特点
Flink之所以选择将 Table API & SQL 作为未来的核心 API,是因为其具有一些非常重要的特点:

- 声明式:属于设定式语言,用户只要表达清楚需求即可,不需要了解底层执行;
- 高性能:可优化,内置多种查询优化器,这些查询优化器可为SQL翻译出最优执行计划;
- 简单易学:易于理解,不同行业和领域的人都懂,学习成本较低;
- 标准稳定:语义遵循SQL标准,非常稳定,在数据库30多年的历史中SQL本身变化较少;
- 流批统一:可以做到API层面上流与批的统一,相同的SQL逻辑,既可流模式运行,也可批
模式运行,Flink底层Runtime本身就是一个流与批统一的引擎;
Table API& SQL 是一种关系型API,用户可以像操作MySQL数据库表一样的操作数据,而不需要写Java代码完成Flink function,更不需要手工的优化Java代码调优。另外,SQL作为一个非程序员可操作的语言,学习成本很低,如果一个系统提供SQL支持,将很容易被用户接受。
当然除了SQL的特性,因为Table API是在Flink中专门设计的,Table API还具有自身的特点:
- 表达方式的扩展性:可以为Table API开发很多便捷性功能,如:Row.flatten(), map等
- 功能的扩展性:可以为Table API扩展更多的功能,如:Iteration,flatAggregate 等新功能
- 编译检查:Table API支持Java和Scala语言开发,支持IDE中进行编译检查。
以上是关于flink table factory基础知识的主要内容,如果未能解决你的问题,请参考以下文章