知识分享:数据结构常用 7 种排序算法(无基数排序)
Posted 一起学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识分享:数据结构常用 7 种排序算法(无基数排序)相关的知识,希望对你有一定的参考价值。
为了让大家掌握多种排序方法的基本思想,本篇文章带着大家对数据结构的常用七大算法进行分析:包括直接插入排序、希尔排序、冒泡排序、快速排序、简单选择排序、堆排序、归并排序等,并能够用高级语言实现。
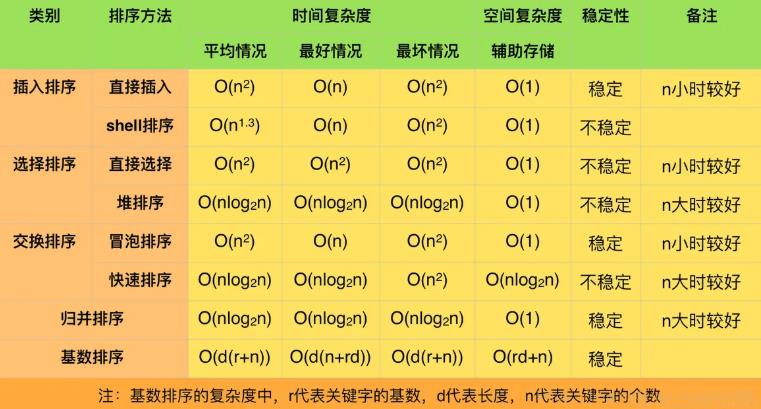
希望通过对这些算法效率的比较,加深对算法的理解。
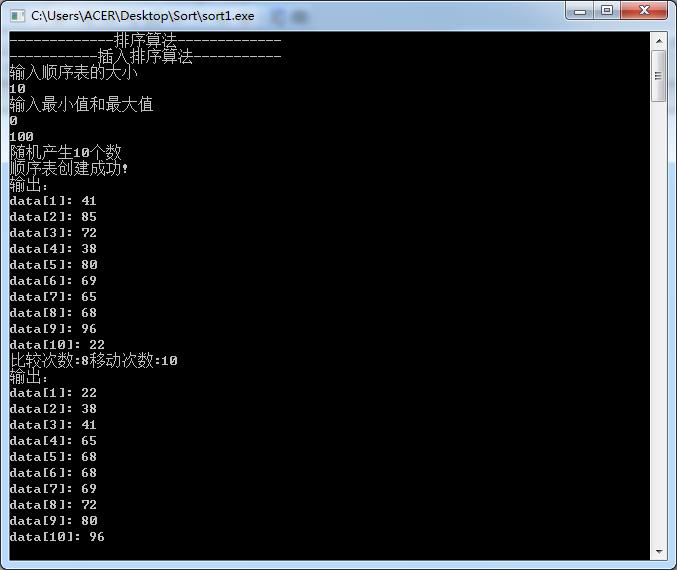
①插入排序
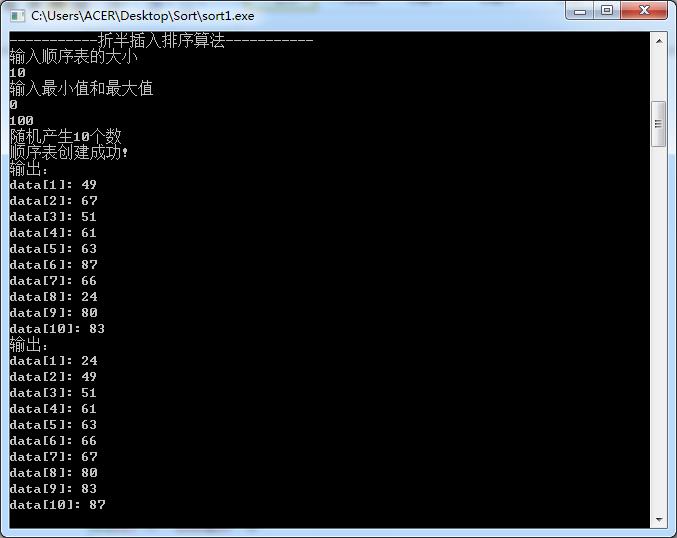
②折半插入排序
③选择排序
④起泡排序
⑤快速排序
⑥希尔排序
⑦堆排序
⑧归并排序
排序算法的分析图解:
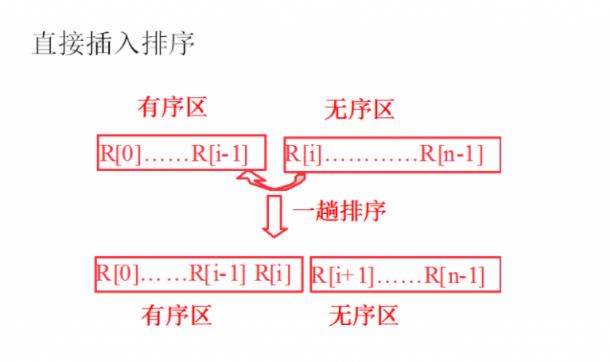

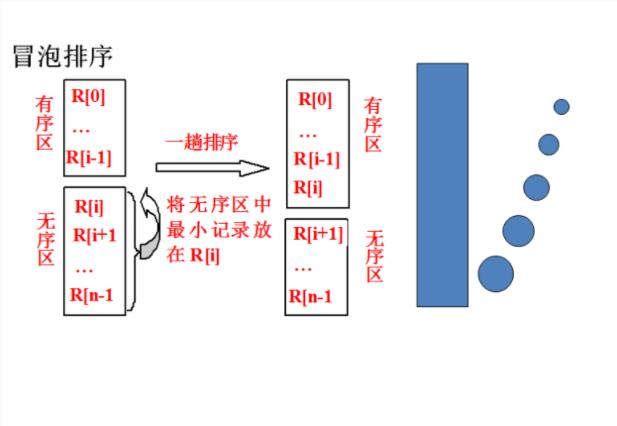
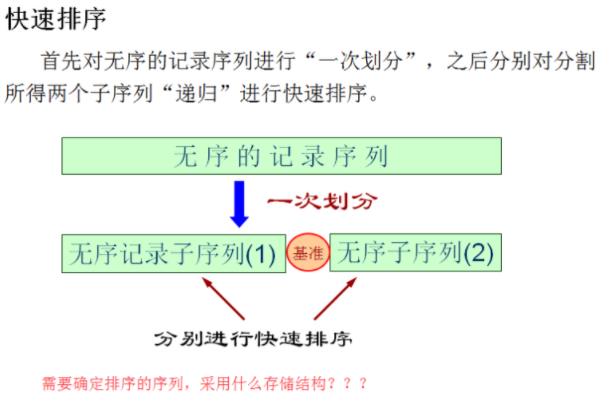

用随机数(介于1-100)产生10个待排序数据元素的关键字值)。
① 采用直接插入排序和希尔排序方法对上述待排数据进行排序并输出序后的有序序列;
② 采用冒泡排序、快速排序方法对上述待排数据进行排序并输出序后的有序序列;
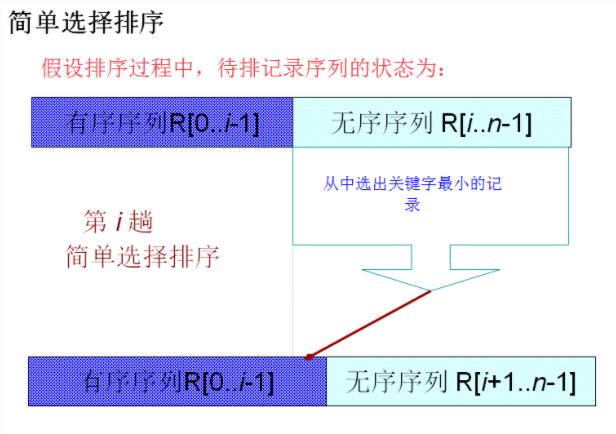
③ 采用简单选择排序、堆排序方法对上述待排数据进行排序并输出序后的有序序列;
④ 采用归并排序方法对上述待排数据进行排序并输出排序后的有序序列;
代码分析
头文件:
#include<cstdio>
#include<iostream>
#include<cstdlib>
#define MAXSIZE 100
using namespace std;
typedef int KeyType;
typedef int InfoType;
typedef struct
KeyType key;
InfoType otherinfo;
RedType;
typedef struct
RedType r[MAXSIZE+1];
int length;
SqList;①插入排序
void InsertSort(SqList &L)
int i,j,a=0,b=0;
for(i=1;i<=L.length;++i)
if(L.r[i].key<L.r[i-1].key)
L.r[0]=L.r[i];
L.r[i]=L.r[i-1];
a++;
for(j=i-2;L.r[0].key<L.r[j].key;--j)
L.r[j+1]=L.r[j];b++;
L.r[j+1]=L.r[0];
cout<<"比较次数:"<<a<<"移动次数:"<<b<<endl;
②折半插入排序
void BInsertSort(SqList &L)
int low,high,m;
for(int i=2;i<=L.length;++i)
L.r[0]=L.r[i];
low=1;high=i-1;
while(low<=high)
m=(low+high)/2;
if(L.r[0].key<L.r[m].key)high=m-1;
else low=m+1;
for(int j=i-1;j>=high+1;--j)
L.r[j+1]=L.r[j];
L.r[high+1]=L.r[0];
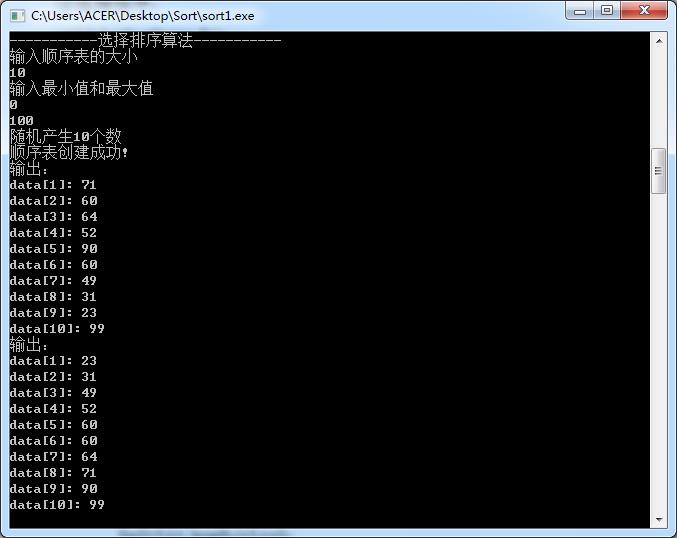
③选择排序
void SelectSort(SqList &L)
int j,k;
for(int i=1;i<=L.length;++i)
k=i;
for(j=i+1;j<=L.length;j++)
if(L.r[j].key<L.r[k].key)k=j;
if(k!=i)
L.r[0].key=L.r[i].key;
L.r[i].key=L.r[k].key;
L.r[k].key=L.r[0].key;
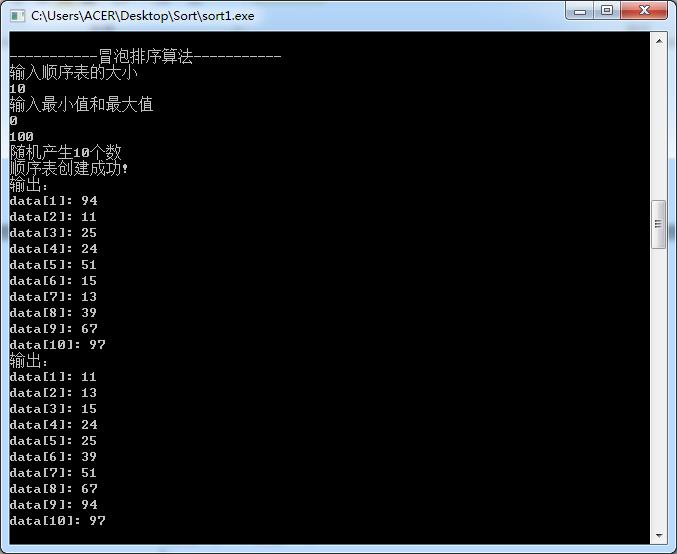
④起泡排序
void BubbleSort(SqList &L)
int i,j;
for(i=1;i<=L.length;++i)
for(j=1;j<L.length-i+1;++j)
if(L.r[j+1].key<L.r[j].key)
L.r[0].key=L.r[j].key;
L.r[j].key=L.r[j+1].key;
L.r[j+1].key=L.r[0].key;
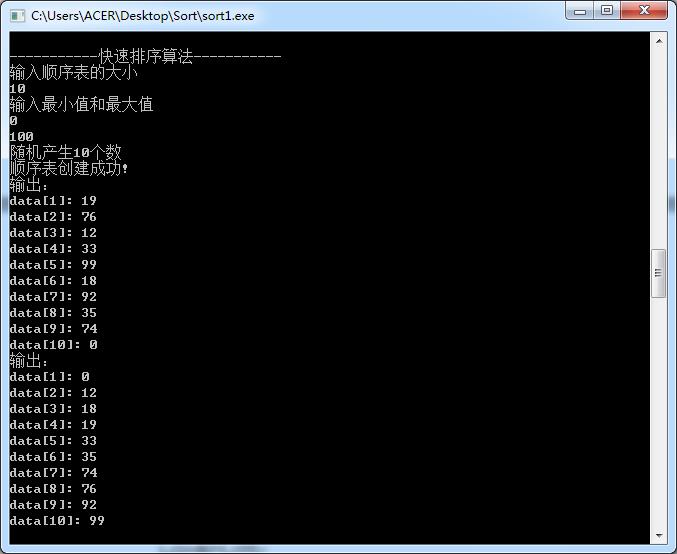
⑤快速排序
int Partition(SqList &L,int low,int high)
L.r[0]=L.r[low];
KeyType pivotkey=L.r[low].key;
while(low<high)
while(low<high&&L.r[high].key>=pivotkey)--high;
L.r[low]=L.r[high];
while(low<high&&L.r[low].key<=pivotkey)++low;
L.r[high]=L.r[low];
L.r[low]=L.r[0];
return low;
void QSort(SqList &L,int low,int high)
if(low<high)
int pivotloc=Partition(L,low,high);
QSort(L,low,pivotloc-1);
QSort(L,pivotloc+1,high);
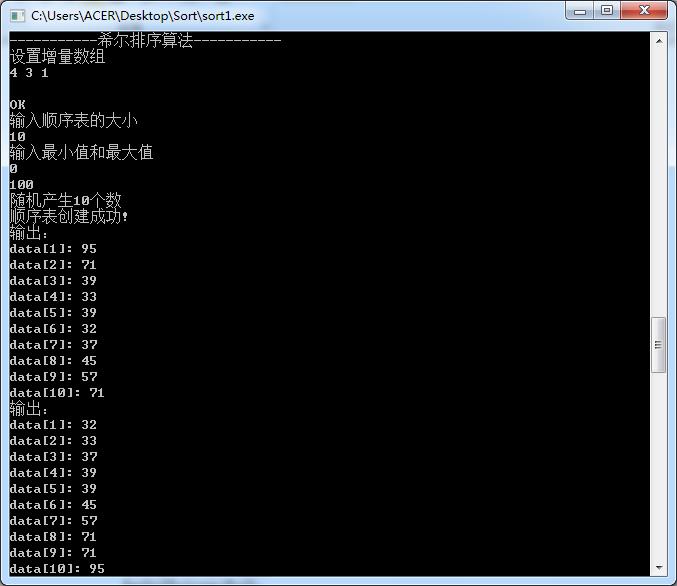
⑥希尔排序
void ShellInsert(SqList &L,int dk)
int i,j;
for(i=dk+1;i<=L.length;++i)
if(L.r[i].key<L.r[i-dk].key)L.r[0]=L.r[i];
for(j=i-dk;j>0&&L.r[0].key<L.r[j].key;j-=dk)
L.r[j+dk]=L.r[j];
L.r[j+dk]=L.r[0];
void ShellSort(SqList &L,int dlta[],int t)
for(int k=0;k<t;++k)
ShellInsert(L,dlta[k]);
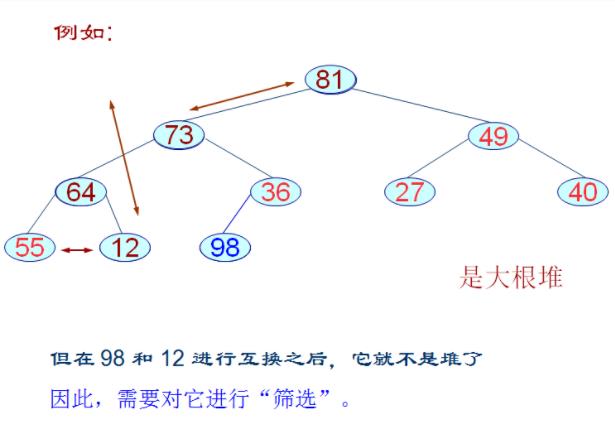
⑦堆排序
typedef SqList HeapType;
void HeapAdjust(HeapType &H,int s,int m)
RedType rc=H.r[s];int j;
for(j=2*s;j<=m;j*=2)
if(j<m&&H.r[j].key<H.r[j+1].key)++j;
if(!(rc.key<H.r[j].key))break;
H.r[s]=H.r[j];s=j;
H.r[s]=rc;
void HeapSort(HeapType &H)
int i;
RedType temp;
for(i=H.length/2;i>0;--i)
HeapAdjust(H,i,H.length);
for(i=H.length;i>1;--i)
temp=H.r[1];
H.r[1]=H.r[i];
H.r[i]=temp;
HeapAdjust(H,1,i-1);
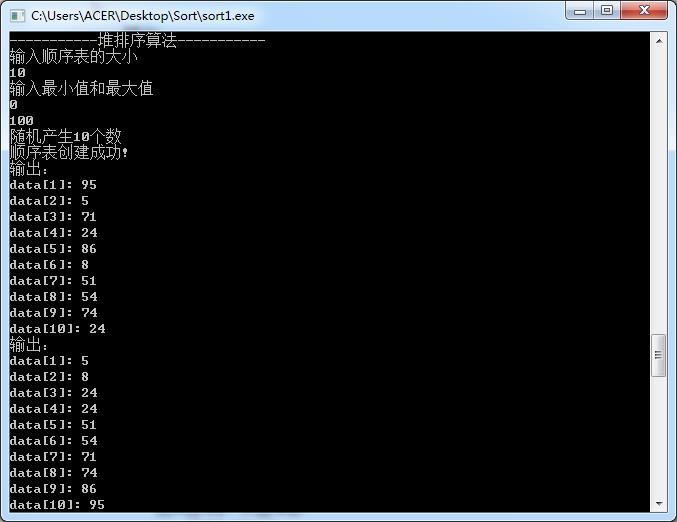
⑧归并排序
void Merge(RedType SR[],RedType &TR[],int i,int m,int n)
int j,k;
for(j=m+1,k=i;i<=m&&j<=n;++k)
if(SR[i].key<=SR[j].key)
TR[k]=SR[i++];
else
TR[k]=SR[j++];
int t;
if(i<=m)
for(t=i;t<=m;t++)
TR[k+t-i]=SR[t];
if(j<=n)
for(t=j;t<=m;t++)
TR[k+t-j]=SR[t];
void MSort(RedType SR[],RedType *TR1,int s,int t)
int m;
RedType TR2[MAXSIZE+1];
if(s==t)TR1[s]=SR[s];
else
m=(s+t)/2;
MSort(SR,TR2,s,m);
MSort(SR,TR2,m+1,t);
Merge(TR2,TR1,s,m,t);
void MergeSort(SqList &L)
MSort(L.r,L.r,1,L.length);
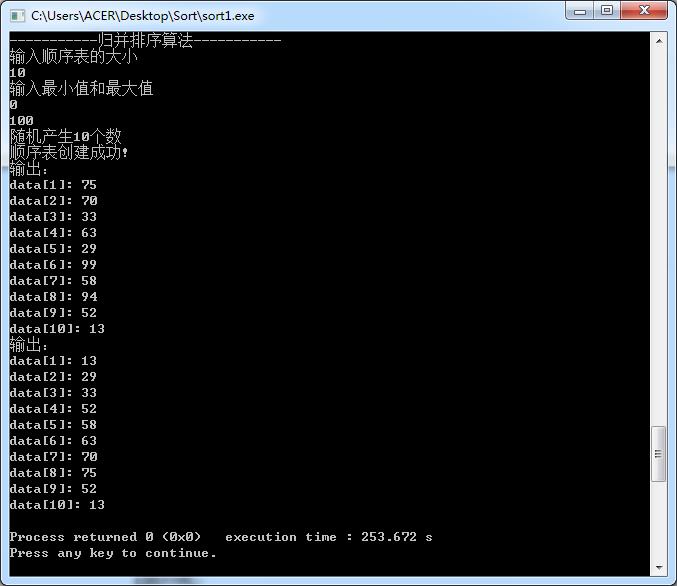
随机生成函数
void RandSqList(SqList &L)
int n,max,min;
printf("输入顺序表的大小\\n");
cin>>n;
printf("输入最小值和最大值\\n");
cin>>min>>max;
L.length=n;
printf("随机产生%d个数\\n",n);
for(int i=1;i<=L.length;++i)
L.r[i].key=rand()%(max-min+1);
L.r[i].key+=min;
printf("顺序表创建成功!\\n");
输出函数
void Output(SqList L)
printf("输出:\\n");
for(int i=1;i<=L.length;i++)
cout<<"data"<<"["<<i<<"]"<<": "<<L.r[i].key<<endl;
结论
(1)若n较小(例如n<50),可采用直接插入排序、冒泡排序或简单选择排序。如果记录中的数据较多,移动较费时的,应采取简单选择排序法。
(2)若记录的初始状态已经按关键码基本有序,则选用直接插入排序或冒泡排序法为宜。
(3)若n较大,则应采用改进排序方法,如快速排序、堆排序或归并排序法。这些排序算法的时间复杂度均为O(nlog2n),但就平均性能而言,快速排序被认为是目前基于比较记录关键码的内部排序中最好的排序方法,但遗憾的是,快速排序在最坏情况下的时间复杂度是O(n2),堆排序与归并排序的最坏情况时间复杂度仍为O(nlog2n)。堆排序和快速排序法都是不稳定的排序。若要求稳定排序,则可选用归并排序。
(4)基数排序可在O (d×n) 时间内完成对n个记录的排序,d是指单逻辑关键码的个数,一般远少于n。但基数排序只适用于字符串和整数这类有明显结构特征的关键码。
(5)前面讨论的排序算法,除基数排序外,都是在顺序存储上实现的。当记录本身的信息量很大时,为避免大量时间用在移动数据上,可以用链表作为存储结构。插入排序和归并排序都易在链表上实现,但有的排序方法,如快速排序和堆排序在链表上却很难实现。
写在最后:对于准备学习C/C++编程的小伙伴,如果你想更好的提升你的编程核心能力(内功)不妨从现在开始!
C语言C++编程学习交流圈子,QQ群:739386924【点击进入】微信公众号:C语言编程学习基地
整理分享(多年学习的源码、项目实战视频、项目笔记,基础入门教程)
欢迎转行和学习编程的伙伴,利用更多的资料学习成长比自己琢磨更快哦!
编程学习书籍分享:
编程学习视频分享:
以上是关于知识分享:数据结构常用 7 种排序算法(无基数排序)的主要内容,如果未能解决你的问题,请参考以下文章