TensorRT 4是啥应用平台
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorRT 4是啥应用平台相关的知识,希望对你有一定的参考价值。
参考技术A- 01
根据老黄的介绍,TensorRT 4是一款应用平台,并且TensorRT 4应用平台是能够进行可编程的,大大给开发者带来了便利。
02据悉,利用TensorRT 4可编程平台来进行编程操作,就能够快捷地将已经训练好的神经网络快速部署到NVIDIA的GPU上,方便快捷。
03新版的TensorRT 4应用平台也同时能够支持INT8以及FP16精度运算,并且对于数据中心的功耗可以降低到70%。
04此外,NVIDIA还会和谷歌进行相关的深度合作,旨在要想TensorRT 4整合到现在AI开源框架中去,并且加速AI应用的推广实行。
TensorRT 模型加速 1-输入输出部署流程
前言
本文首先简要介绍 Tensor RT 的输入、输出以及部署流程,了解 Tensor RT 在部署模型中起到的作用。然后介绍 Tensor RT 模型导入流程,针对不同的深度学习框架,使用不同的方法导入模型。

一、TensorRT 简介
TensorRT 是NVIDIA 公司发布的一个高性能的深度学习推理加速框架,下面先看一下使用TensorRT的背景:
- 训练主要是获得层与层之间的权重参数,目的是为了获得一个性能优异的模型,关注点集中在模型的准确度、精度等指标。
- 推理(inference)则不一样,其没有了训练中的反向迭代过程,只是针对新的数据进行预测。相较于训练,推理的更关注的是部署简单、处理速度快、吞吐率高和资源消耗少。
作用:TensorRT优化深度学习模型结构,并提供高吞吐率和低延迟的推理部署。
应用:TensorRT可用于大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。
1.1 TensorRT的输入
在输入方面,TensorRT 支持所有常见的深度学习框架包括 Caffe、Tensorflow、Pytorch、MXNet、Paddle Paddle 等。
- 得到的网络模型需要导入到TensorRT,对于模型的导入方式,TensorRT 支持的导入方式包括 C++ API、Python API、NvCaffeParser 和 NvUffParser等
- 还可以借助中间转换工具ONNX,比如:先将模型由 Pytorch 保存的模型文件转换成ONNX模型,然后再将 ONNX 模型转换成 TensorRT推理引擎。后面再结合具体案例,详细分析。
1.2 TensorRT的输出
- 将模型导入TensorRT 以生成引擎(engine)文件,将 engine 文件序列化保存, 之后即可以方便快速地调用它来执行模型的加速推理。
- 输出方面,对于系统平台,TensorRT 支持 Linux x86、Linux aarch64、Android aarch64 和 QNX aarch64。
1.3 TensorRT部署流程
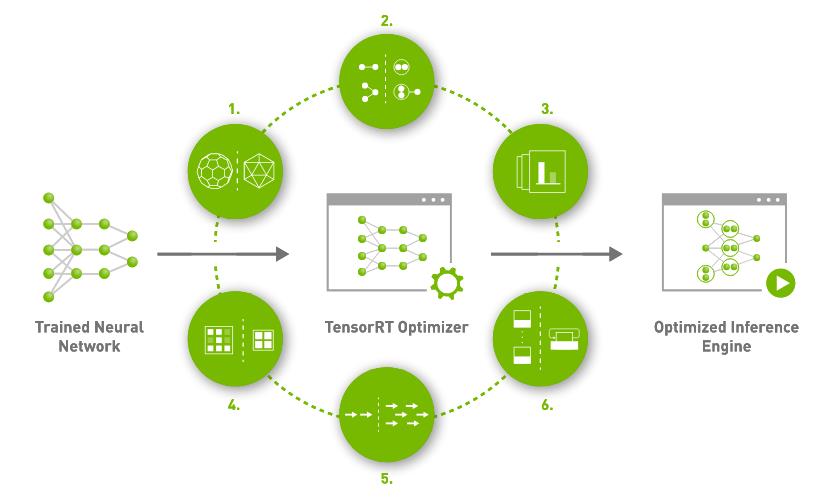
Tensor RT 的部署分为两个部分:(TensorRT部署流程如下图所示)
- 一是 优化训练好的模型并生成计算流图;
- 二是 部署计算流图。
二、模型导入
这里介绍Caffe框架、Tensorflow框架、Pytorch框架等,进行模型导入,重点分析一下Pytorch框架。
2.1 Tensorflow 框架
- 方法1:使用 uff python 接口将模型转成 uff 格式,之后使用 NvUffParser 导入。
- 方法2:使用 Freeze graph 来生成.Pb(protobuf)文件,之后使用convert-to-uff 工具将.pb 文件转化成 uff 格式,然后利用 NvUffParser 导入。
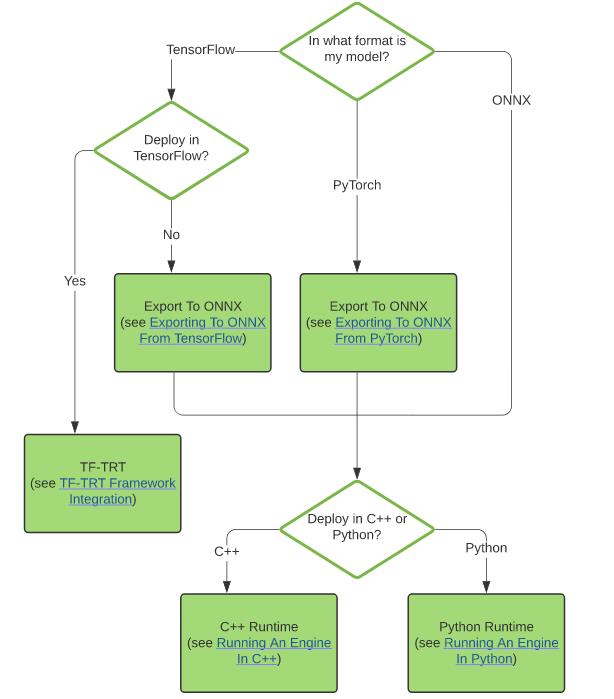
- 方法3:将Tensorflow 训练好的模型(xx.pb)进行 TensorRT 推理加速,需要先将模型由 Pytorch 保存的模型文件转换 成 ONNX 模型,然后再将 ONNX 模型转换成 TensorRT 推理引擎。处理流程如下图所示
2.2 Pytorch框架
为了将Pytorch训练好的模型(xx.pt)进行 TensorRT 推理加速,需要先将模型由 Pytorch 保存的模型文件转换 成 ONNX 模型,然后再将 ONNX 模型转换成 TensorRT 推理引擎。
A、Pytorch-ONNX 模型转换
ONNX(Open Neural Network Exchange,开放神经网络交换)模型格式是一种用于 表示深度学习模型的文件格式,可以使深度学习模型在不同框架之间相互转换。
- 目前 ONNX 支持应用于 :Pytorch、Caffe2、Tensorflow、MXNet、Microsoft CNTK 和 TensorRT 等深度学习框架
- ONNX组成:由可扩展计算图模型的定义、标准数据类型的定义和内置运算符的定义三 个部分组成。
- 与 Pytorch 模型不同,ONNX 格式的权重文件除了包含权重值外,还包含:神经网络中的网络流动信息、每层网络的输入输出信息以及一些辅助信息。
为得到 TensorRT 推理引擎,首先将经过网络训练得到的 Pytorch 模型转换成 ONNX 模型,然后进行 ONNX 模型的解析,最终生成用于加速的网络推理引擎(engine)。 Pytorch 模型转换生成 ONNX 模型的流程如下图所示。
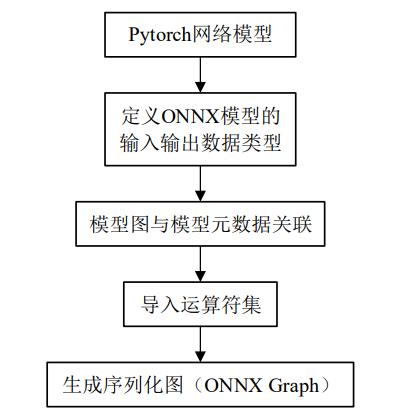
- 第一步定义 ONNX 模型的输入、输出数据类型;
- 第二步将模型图与模型元数据进行关联,模型图中含有可执行元素,模型元数据是一种特殊的数据类型,用于数据描述;
- 第三步先定义导入模型的运算符集, 再将运算符集导入相应的图(Graph)中;
- 第四步生成由元数据、模型参数列表、计算列表构成的序列化图(ONNX Graph)。
成功转换后,得到 ONNX 模型。
- 其中,PyTorch 中自带的 torch.onnx 模块。此模块包含将模型导出为 onnx IR 格式的函数。这些模型可以从 onnx 库加载,然后转换为可以在其他深度学习框架上运行的模型。
- 基本流程为:模型读取、参数设置、tensor 张量生成和模型转化。
- 其中关键的 export 函数为:torch. onnx. export()
B、ONNX-TensorRT 模型转换
创建并保存 engine 文件流程,如下图所示:
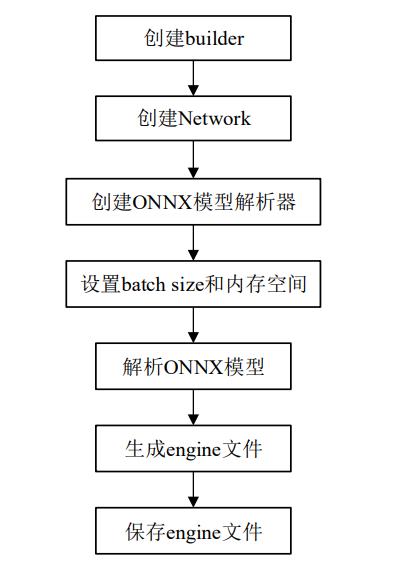
- 第一步创建 engine 类为构建器,engine 类是 TensorRT 中创建推理引擎所 用的函数,创建 engine 类为 nvinfer::IBuilder;
- 第二步使用 builder->createNetworkV2 创 建网络(Network);
- 第三步使用 nvonnxparser::createParser 创建 ONNX 模型的解析器;
- 第四步通过 builder->setMaxBatchSize 设置网络每个批次处理的图片数量,通过 builder->setMaxWorkspaceSize 设置内存空间以及通过 config->setFlag 设置推理时模型参 数的精度类型;
- 第五步通过解析器来解析 ONNX 模型;最后生成 engine 文件并保存。
2.3 Caffe框架
方法1:使用C++/Python API 导入模型,通过代码定义网络结构,并载入模型 weights 的方式导入。
方法2:使用 NvCaffeParser 导入模型,导入时输入网络结构 prototxt 文件及caffemodel 文件。
参考文献:
[1] 尹昱航. 基于特征融合的交通场景目标检测方法研究[D]. 大连:大连理工大学, 2021.
[2] 葛壮壮. 基于嵌入式 GPU 的交通灯及数字检测[D]. 四川:电子科技大学, 2020.
官网示例:
 https://developer.nvidia.com/zh-cn/blog/speeding-up-deep-learning-inference-using-tensorrt-updated/
https://developer.nvidia.com/zh-cn/blog/speeding-up-deep-learning-inference-using-tensorrt-updated/官方文档:
本文直供大家参考学习,谢谢!
以上是关于TensorRT 4是啥应用平台的主要内容,如果未能解决你的问题,请参考以下文章